《计算机网络:自顶向下的方法》课后习题_第二章
计算机网络:自顶向下方法–课后习题
第二章
P1.
- a. 错。文本和图像是通过不同的URL请求的,应该对应4个请求报文。
- b. 对。HTTP提供持续连接。
- c. 错。非持续连接时,客户发送一个请求报文,服务器做出相应后就关闭了。
- d. 错。相应报文中的Date指的是服务器将相应内容封装好准备发送的时间。(接近于客户受到相应的时间)
- e. 错。304类型的响应就是空报文体,告诉客户:访问的资源是最新的。
P2.
SMS(短消息服务)是一种允许通过蜂窝网络在移动电话之间发送和接收文本消息的技术。一条短信可以包含140字节的数据,它支持国际语言。消息的最大大小可以是160个7位字符、140个8位字符或70个16位字符。短信通过ss# 7协议的移动应用部分(MAP)实现,短信协议由3GPP TS 23.040和3GPP TS 23.041定义。此外,MMS(多媒体消息服务)扩展了原始文本消息的功能,并支持发送照片、较长的文本消息和其他内容。
iMessage是苹果公司开发的一种即时通讯服务。iMessage支持通过移动数据网络或WiFi发送到iOS设备和mac上的文本、照片、音频或视频。苹果的iMessage是基于专有的二进制协议APNs(苹果推送通知服务)。
WhatsApp Messenger是一种即时通讯服务,支持许多移动平台,如iOS、Android、手机和黑莓。WhatsApp用户可以通过蜂窝数据网络或WiFi相互发送无限制的图片、文本、音频或视频。WhatsApp使用XMPP协议(可扩展消息传递和到场协议)。
- iMessage和WhatsApp与SMS不同,因为它们使用数据计划(data plan)来发送消息,并且在TCP/IP网络上工作,但SMS使用的是我们从无线运营商购买的短信计划。此外,iMessage和WhatsApp支持发送照片、视频、文件等,而原来的短信只能发送文本信息。最后,iMessage和WhatsApp可以通过WiFi运行,但SMS不能。
P3.
- 需要应用层的DNS协议来找到对应的IP地址,DNS寻址过程中会使用运输层的UDP协议来传递信息。当客户获取到IP地址后,就会基于HTTP协议访问目的IP的资源,这个过程运输层使用的TCP协议。
P4.
- a.
http://gaia.cs.umass.edu/cs453/index.html - b.
HTTP/1.1 - c. 持续连接
- d. 通过该报文无法识别
- e.
Mozilla/5.0;服务器需要浏览器类型信息来将同一对象的不同版本发送给不同类型的浏览器
P5.
- a. 可以;
Tue, 07 Mar 2008 12:39:45GMT - b.
Sat, 10 Dec2005 18:27:46GMT - c.
3874bit - d. 前五个字节:
;同意持续连接
P6.
HTTP1.1规范
a) 都可以。客户端或服务器在连接头字段中标识Connection: close,即可通知对方关闭连接。
b) HTTP不提供任何的加密服务。
c) 使用持久连接的客户端应该限制它们与给定服务器的同时连接的数量。单用户客户端不应该与任何服务器或代理保持超过2个连接。
d) 是的。当服务器决定关闭“空闲”连接时,客户机可能已经开始发送新的请求。从服务器的角度来看,连接在空闲时被关闭,但从客户端的角度来看,请求正在进行。
P7.
-
经过 R T T 1 + R T T 2 + ⋯ + R T T n RTT_1 + RTT_2 + ⋯ + RTT_n RTT1+RTT2+⋯+RTTn 时间获取到了目标IP地址后,就需要消耗 R T T 0 RTT_0 RTT0 的时间来建立TCP握手连接,然后又需要 R T T 0 RTT_0 RTT0 的时间来建立TCP数据连接。
-
对象传输时间为0,所以一共耗时: 2 R T T 0 + R T T 1 + R T T 2 + ⋯ + R T T n 2RTT_0 +RTT_1 +RTT_2 +⋯+ RTT_n 2RTT0+RTT1+RTT2+⋯+RTTn
P8.
注意!这里是引用了8个小对象,不是只请求8个小对象,所以原来的页面要算进去的。
-
a. R T T 1 + ⋯ + R T T n + 2 R T T 0 + 8 × 2 R T T 0 RTT_1 +⋯+ RTT_n + 2RTT_0 + 8 \times 2RTT_0 RTT1+⋯+RTTn+2RTT0+8×2RTT0
-
b. R T T 1 + ⋯ + R T T n + 2 R T T 0 + 2 × 2 R T T 0 RTT_1 + ⋯ + RTT_n + 2RTT_0 + 2 \times 2RTT_0 RTT1+⋯+RTTn+2RTT0+2×2RTT0
-
c.
- 使用管道的持久连接。这是HTTP的默认模式:$RTT_1 + ⋯ + RTT_n + 2RTT_0 + RTT_0 $
- 非管道的持久连接,没有并行连接: R T T 1 + ⋯ + R T T n + 2 R T T 0 + 8 R T T 0 RTT_1 + ⋯ + RTT_n + 2RTT_0 + 8RTT_0 RTT1+⋯+RTTn+2RTT0+8RTT0
管道连接(HTTP Pipelining)其实是把多个HTTP请求放到一个TCP连接中一一发送,而在发送过程中不需要等待服务器对前一个请求的响应。
P9.
-
a.
-
接入链路通过15Mbps速度发送一个对象的时间是: Δ = L R = 850 , 000 ( b i t s ) 15 , 000 , 000 ( b i t s / s e c ) = 0.0567 ( s e c ) Δ = \frac{L}{R} = \frac{850,000(bits)}{ 15,000,000(bits/sec)} = 0.0567(sec) Δ=RL=15,000,000(bits/sec)850,000(bits)=0.0567(sec)
-
平均到达率: Δ β = 16 ( r e q u e s t s / s e c ) × 0.0567 ( s e c ) = 0.907 \Delta\beta=16(requests/sec) \times 0.0567(sec)=0.907 Δβ=16(requests/sec)×0.0567(sec)=0.907
注意!这里的平均到达率不是指请求最终能到达多少,而是指的流量强度。所以 Δ β Δβ Δβ 接近1时,分母接近0,平均相应时间无限大。
流量强度的公式: I = δ × L R I = \frac{\delta\times L}{R} I=Rδ×L , δ \delta δ 为请求量。
-
代入公式:
Δ ( 1 − Δ β ) \frac{\Delta}{(1-\Delta\beta)} (1−Δβ)Δ得到发送一个对象的平均时间为: 0.0567 ( s e c ) ( 1 − 0.907 ) ≈ 0.6 ( s e c ) \frac{0.0567(sec)} {( 1 − 0.907 )} \approx 0.6(sec) (1−0.907)0.0567(sec)≈0.6(sec)由于初始服务器每个请求的平均处理时间为3秒,所以总的平均响应时间为 0.6 + 3 = 3.6 ( s e c ) 0.6 + 3 = 3.6(sec) 0.6+3=3.6(sec)。
-
-
b.
-
由于 40 40 40% 的请求被高速以太网立刻返回,因此接入链路上的流量强度降低了 40 40 40% ,可以得出 Δ β ( I ) = δ × 0.6 × L R 0.0567 × 16 × 0.6 = 0.54432 \Delta\beta (I) = \frac{\delta \times 0.6 \times L}{R}0.0567\times16\times0.6=0.54432 Δβ(I)=Rδ×0.6×L0.0567×16×0.6=0.54432
因此,发送一个对象的平均时间为: Δ = 1 1 − I × L R = 0.0567 ( s e c ) 1 − 0.54432 = 0.12 ( s e c ) \Delta = \frac{1}{1-I}\times \frac{L}{R} = \frac{0.0567(sec)}{1-0.54432}=0.12(sec) Δ=1−I1×RL=1−0.544320.0567(sec)=0.12(sec)
-
如果缓存满足要求,响应时间大约为 0 0 0,接入链路的时间为 Δ = 850 , 000 ( b i t s ) ÷ 100 , 000 , 000 ( b i t s / s e c ) = 0.0085 ( s e c ) \Delta=850,000(bits)\div100,000,000(bits/sec)=0.0085(sec) Δ=850,000(bits)÷100,000,000(bits/sec)=0.0085(sec);
缓存未命中的平均响应时间为 0.12 ( s e c ) + 3 ( s e c ) = 3.12 ( s e c ) 0.12(sec)+3(sec)= 3.12(sec) 0.12(sec)+3(sec)=3.12(sec) .
-
总的响应时间为: 0.4 ( s e c ) × 0.0085 ( s e c ) + 0.6 × 3.12 ( s e c ) = 1.8754 ( s e c ) 0.4(sec)\times0.0085(sec)+0.6\times3.12(sec)=1.8754(sec) 0.4(sec)×0.0085(sec)+0.6×3.12(sec)=1.8754(sec)
-
P10.
控制分组:连接建立,连接确认的分组
10米短链路,忽略其传播时延。从图中可以看出,下载一个对象需要 t 1 = 3 × 200 ( b i t ) 150 ( b i t ) + 100 ( k b i t ) 150 ( b i t ) t_1 = 3 \times\frac{200(bit)}{150(bit)}+\frac{100(kbit)}{150(bit)} t1=3×150(bit)200(bit)+150(bit)100(kbit) 的时间, 如果是非持续并行下载,则需要考虑将链路分为10等分,由于是并行,所以只需要算一个就可以。
- 带有并行连接的非持续连接的并行下载:
200 ( b ) 150 ( b p s ) × 3 + 1 0 5 ( b ) 150 ( b p s ) + 200 ( b ) 150 ( b p s ) 10 × 3 + 1 0 5 ( b ) 150 ( b p s ) 10 = 7377.3 ( s e c ) \frac{200(b)}{150(bps)} \times 3 + \frac{10^5(b)}{150(bps)} + \frac{200(b)}{\frac{150(bps)} {10}} \times 3 + \frac{10^5(b)}{\frac{150(bps)}{10}} = 7377.3(sec) 150(bps)200(b)×3+150(bps)105(b)+10150(bps)200(b)×3+10150(bps)105(b)=7377.3(sec)
如果是持续性连接,在图中我们可以看出第一个对象仍旧需要 t 1 t_1 t1 的时间,但是后续请求的十个对象无需建立连接,因为用的是持续连接,直接发送请求报文即可,故后面请求的对象需要的时间为: 10 × ( 200 ( b i t ) 150 ( b i t ) + 100 ( k b i t ) 150 ( b i t ) ) 10 \times (\frac{200(bit)}{150(bit)}+\frac{100(kbit)}{150(bit)}) 10×(150(bit)200(bit)+150(bit)100(kbit))。
- 持续连接:
200 ( b ) 150 ( b p s ) × 3 + 1 0 5 ( b ) 150 ( b p s ) + 10 × ( 200 ( b ) 150 ( b p s ) + 1 0 5 ( b ) 150 ( b p s ) ) = 7351 ( s e c ) \frac{200(b)}{150(bps)} \times 3 + \frac{10^5(b)}{150(bps)} + 10 \times (\frac{200(b)}{150(bps)} + \frac{10^5(b)}{150(bps)}) = 7351(sec) 150(bps)200(b)×3+150(bps)105(b)+10×(150(bps)200(b)+150(bps)105(b))=7351(sec)
两种方式产生的效益差不了多少,主要是因为链路带宽太小。
P11.
- a. 是的,因为Bob有更多的连接,他可以获得更大的链路带宽份额。
- b. 是的,Bob仍然需要执行并行下载。否则他得到的带宽将少于其他四个用户。
P12.
from socket import *
serverPort=12000
serverSocket=socket(AF_INET,SOCK_STREAM)
serverSocket.bind(('',serverPort))
serverSocket.listen(1)
while 1:
connectionSocket, addr = serverSocket.accept()
sentence = connectionSocket.recv(1024).decode()
print('From Server:', sentence, '\n')
serverSocket.close()
P13.
- SMTP中的
MAIL FROM指的是来自SMTP客户端的消息,它标识发送给SMTP服务器的邮件的发送方。 - 邮件消息本身的
From不是SMTP消息,而是邮件消息正文中的一行。
P14.
- SMTP使用一个点
.来标识报文体的结束。 - HTTP使用头部属性
Content-Length来记录报文的长度。 - 不能,因为HTTP的报文体中可以是图片、视频等等二进制数据,不能以ASCII符号
.结束,相比,SMTP的报文体只能是7位ASCII字符。
P15.
MTA代表邮件传输代理。主机将消息发送到MTA。然后该消息遵循一系列MTA到达接收者的邮件阅读器。我们看到此垃圾邮件遵循一系列MTA。诚实的MTA应该报告收到消息的位置。请注意,在此消息中,asusus-4b96([58.88.21.177])没有报告它从何处收到电子邮件。既然我们假设只有发起者是不诚实的,那么asusus-4b96([58.88.21.177])一定是发起者。
P16.
UIDL是唯一识别码列表(unique-ID listing)的缩写。当一个POP3客户端发出一个UIDL命令,服务器返回存储在用户邮箱里的所有邮件的唯一标识码。这个命令对下载并保留方式有用。通过保留上次收取的邮件的列表信息,客户能够使用UIDL来确定在服务器上的哪些邮件是被阅读过的。
P17.
- a.
list
+OK 3 14907
1 9125
2 3406
3 2376
.
retr 1
blah blah ...
..........blah
.
dele 1
+OK core mail
quit
+OK core mail
- b.
list
+OK 2 5782
2 3406
3 2376
.
retr 2
blah blah ...
..........blah
.
quit
+OK core mail
- c.
list
+OK 2 5782
2 3406
3 2376
.
retr 3
blah blah ...
..........blah
.
retr 2
blah blah ...
..........blah
.
quit
+OK core mail
P18.
-
a.
whois(读作“Who is”,非缩写)是用来查询域名的IP以及所有者等信息的传输协议。简单说,whois就是一个用来查询域名是否已经被注册,以及注册域名的详细信息的数据库(如域名所有人、域名注册商)。通过whois来实现对域名信息的查询。早期的whois查询多以命令列接口存在,但是现在出现了一些网页接口简化的线上查询工具,可以一次向不同的数据库查询。网页接口的查询工具仍然依赖whois协议向服务器发送查询请求,命令列接口的工具仍然被系统管理员广泛使用。whois通常使用TCP协议43端口。每个域名/IP的whois信息由对应的管理机构保存。 -
b. dns8.hichina.com,dns7.hichina.com
-
c.
-
C:\Users\asus>nslookup -qt=ns www.baidu.com 服务器: UnKnown Address: * 非权威应答: www.baidu.com canonical name = www.a.shifen.com a.shifen.com primary name server = ns1.a.shifen.com responsible mail addr = baidu_dns_master.baidu.com serial = 2202210005 refresh = 5 (5 secs) retry = 5 (5 secs) expire = 2592000 (30 days) default TTL = 3600 (1 hour) -
C:\Users\asus>nslookup -qt=A www.baidu.com 服务器: UnKnown Address: * 非权威应答: 名称: www.a.shifen.com Addresses: 14.215.177.38 14.215.177.39 Aliases: www.baidu.com -
C:\Users\asus>nslookup -qt=MX www.baidu.com 服务器: UnKnown Address: * 非权威应答: www.baidu.com canonical name = www.a.shifen.com a.shifen.com primary name server = ns1.a.shifen.com responsible mail addr = baidu_dns_master.baidu.com serial = 2202210005 refresh = 5 (5 secs) retry = 5 (5 secs) expire = 2592000 (30 days) default TTL = 3600 (1 hour) -
总结:
www.baidu.com有多个IP地址。
-
-
d. 见上
-
**e. ** 略
-
f. 攻击者可以使用whois数据库和nslookup工具来确定目标机构的IP地址范围、DNS服务器地址等 。
-
g. whois 是用来查询域名的IP以及所有者等信息的传输协议,简单说,whois就是一个用来查询域名是否已经被注册,以及注册域名的详细信息的数据库(如域名所有人、域名注册商)。通过whois来实现对域名信息的查询。 同时, 在用户受到网络攻击时,通过分析攻击数据包的源地址,受害者可以使用whois获取有关攻击所来自的域的信息,并可能通知原始域的管理员。
P19.
-
a. 以下是 gaia.cs.umass.edu 的查询委托链路:首先查询根服务器,然后总是选择第一个服务器,最后就可以查到 gaia.cs.umass.edu 的 IP 地址 。
# dig +norecurse @a.root-servers.net any gaia.cs.umass.edu ... ;; AUTHORITY SECTION: edu. 172800 IN NS f.edu-servers.net. edu. 172800 IN NS a.edu-servers.net. edu. 172800 IN NS g.edu-servers.net. edu. 172800 IN NS l.edu-servers.net. edu. 172800 IN NS c.edu-servers.net. edu. 172800 IN NS d.edu-servers.net. ... # dig +norecurse @f.edu-servers.net any gaia.cs.umass.edu ... ;; AUTHORITY SECTION: umass.edu. 172800 IN NS ns1.umass.edu. umass.edu. 172800 IN NS ns3.umass.edu. umass.edu. 172800 IN NS ns2.umass.edu. ... # dig +norecurse @ns1.umass.edu any gaia.cs.umass.edu ... ;; ANSWER SECTION: gaia.cs.umass.edu. 21600 IN MX 0 barramail.cs.umass.edu. gaia.cs.umass.edu. 21600 IN A 128.119.245.12 ... -
b. 查询 google.com 时的链路,类似的:
- a.edu-servers.net
- a.gtld-servers.net
- ns2.google.com
P20.
- 我们可以定期对本地DNS服务器中的DNS缓存进行快照。在DNS缓存中出现最频繁的Web服务器是最流行的服务器。这是因为如果更多的用户对Web服务器感兴趣,那么用户就会更频繁地发送该服务器的DNS请求。因此,该Web服务器将更频繁地出现在DNS缓存中。
P21.
- 是的,我们可以使用
dig在本地DNS服务器中查询该网站例如,dig cnn.com将返回查找cnn.com的查询时间。如果cnn.com在几秒钟前刚刚被访问,那么cnn.com的一个条目缓存在本地DNS缓存中,因此查询时间为 0 m s e c 0 msec 0msec 。否则,查询时间会很长。
P22.
-
客户-服务器:
与u无关.
t = m a x { N F u s , F d i } t = max\left\{\frac{NF}{u_s}, \frac{F}{d_i}\right\} t=max{usNF,diF}N t 10 7680s 100 51200s 1000 512000s 随着客户端的增多,服务器的分发时间会随着客户端的增加而增加。
-
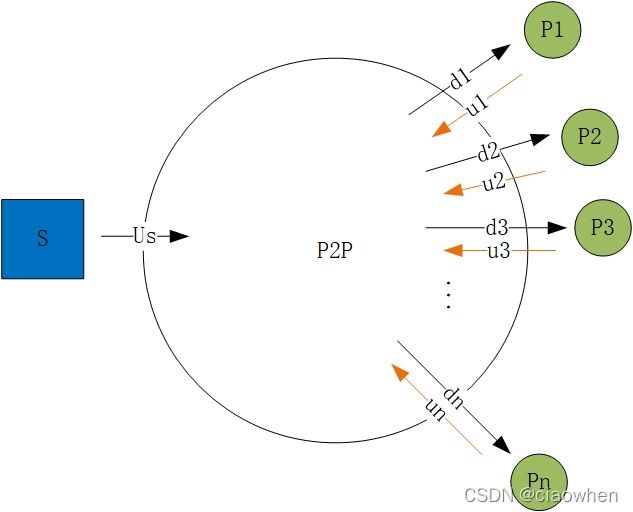
P2P:
t = m a x { F u s , F d i , N F ( u s + N u ) } t = max\left\{\frac{F}{u_s},\frac{F}{d_i},\frac{NF}{(u_s+Nu)}\right\} t=max{usF,diF,(us+Nu)NF}t N 10 100 1000 u 300kps 7680s 25600s 46454s 700kps 7680s 15300s 21041s 2Mbps 7680s 7680s 7680s 随着peer节点上载能力的增加,节省的时间会越来越多。
P23.
- a. 服务器向每个客户端并行发送文件,此速率为 u s N \frac{u_s}{N} Nus,因为 u s N ≤ d m i n \frac{u_s}{N} \leq d_{min} Nus≤dmin,所以客户端也以该速率下载。则每个客户端接收完文件的时间为 F u s N = N F u s \frac{F}{\frac{u_s}{N}} = \frac{NF}{u_s} NusF=usNF .
- b. 仍然考虑服务器向每个客户端并行发送文件,以 d m i n d_{min} dmin 为速率,因为 u s N ≥ d m i n \frac{u_s}{N}\geq d_{min} Nus≥dmin,所以 u s ≥ N d m i n u_s \geq Nd_{min} us≥Ndmin,故服务器可以承受此速率,各服务器以 d m i n d_{min} dmin 为下载速率,故接收时间为 $\frac{F}{d_{min}} $ .
- c.
- 当 u s N ≤ d m i n \frac{u_s}{N} \leq d_{min} Nus≤dmin 时:
N u s ≥ 1 d m i n \frac{N}{u_s} \geq \frac{1}{d_{min}} usN≥dmin1 ,
N F u s ≥ F d m i n \frac{NF}{u_s} \geq \frac{F}{d_{min}} usNF≥dminF ,
此时 t = N F u s = m a x { N F u s , F d m i n } t = \frac{NF}{u_s} = max\left\{\frac{NF}{u_s}, \frac{F}{d_{min}} \right\} t=usNF=max{usNF,dminF} . - 当 u s N ≥ d m i n \frac{u_s}{N} \geq d_{min} Nus≥dmin 时:
N u s ≤ 1 d m i n \frac{N}{u_s} \leq \frac{1}{d_{min}} usN≤dmin1 ,
N F u s ≤ F d m i n \frac{NF}{u_s} \leq \frac{F}{d_{min}} usNF≤dminF ,
此时 t = F d m i n = m a x { N F u s , F d m i n } t = \frac{F}{d_{min}} = max\left\{\frac{NF}{u_s}, \frac{F}{d_{min}} \right\} t=dminF=max{usNF,dminF} . - 因此:得出最小分发时间为 m a x { N F u s , F d m i n } max\left\{\frac{NF}{u_s}, \frac{F}{d_{min}} \right\} max{usNF,dminF} .
- 当 u s N ≤ d m i n \frac{u_s}{N} \leq d_{min} Nus≤dmin 时:
P24:
P2P: D P 2 P ≥ m a x { F U S , F d m i n , N F U S + ∑ i = 1 N u i } D_{P2P} \geq max \left\{ \frac{F}{U_S}, \frac{F}{d_{min}}, \frac{NF}{U_S+\sum_{i=1}^{N}u_i}\right\} DP2P≥max{USF,dminF,US+∑i=1NuiNF}.
-
a. U s ≤ U s + U N Us \leq \frac{U_s+U}{N} Us≤NUs+U,其中 U = u 1 + u 2 + u 3 + . . . + u n U = u_1+u_2+u_3+...+u_n U=u1+u2+u3+...+un,定义一个具有 F U S \frac{F}{U_S} USF 的分发方案。
按照客户上载带宽占整个上载带宽总和的比值来划分服务器的上载带宽 ,也就是按照客户端上载的能力来进行划分服务器的上载带宽。
从服务器角度来看,整个获得的上载加在一起不能超过 U s U_s Us;从客户端角度来看,向其他节点提供服务的"吐出"要符合当前节点的上载带宽,下载带宽也要符合当前节点的下载带宽。也就是说从入和出的角度来看是否符合他的上行带宽和下行带宽,如果符合这种分发方案就是可行的。
①从对等方上载来看
( N − 1 ) × U i U × U s ≤ U i (N-1)\times \frac{U_i}{U} \times U_s \leq U_i (N−1)×UUi×Us≤Ui, 其中 U i U × U s \frac{U_i}{U} \times U_s UUi×Us 为当前节点能够为其他节点提供的上载能力,即为其他 N − 1 N-1 N−1 个节点提供服务的上载带宽小于等于当前节点的上载带宽。
②从服务器上载来看
∑ i = 1 N r i = ∑ i = 1 N U i U × U s = U s \sum_{i=1}^{N}r_i = \sum_{i=1}^{N} \frac{U_i}{U}\times U_s = U_s ∑i=1Nri=∑i=1NUUi×Us=Us.
③从客户端下载来看,由于 d m i n d_{min} dmin 很大,所以客户端的下载带宽不会成为瓶颈。
最后可以得到分发时间为 F U s \frac{F}{U_s} UsF.
-
b. U s ≥ U s + U N Us \geq \frac{U_s+U}{N} Us≥NUs+U,其中 U = u 1 + u 2 + u 3 + . . . + u n U = u_1+u_2+u_3+...+u_n U=u1+u2+u3+...+un,定义一个具有 N F U s + ∑ i = 1 N u i \frac{NF}{U_s+\sum_{i=1}^{N}u_i} Us+∑i=1NuiNF 的分发方案。
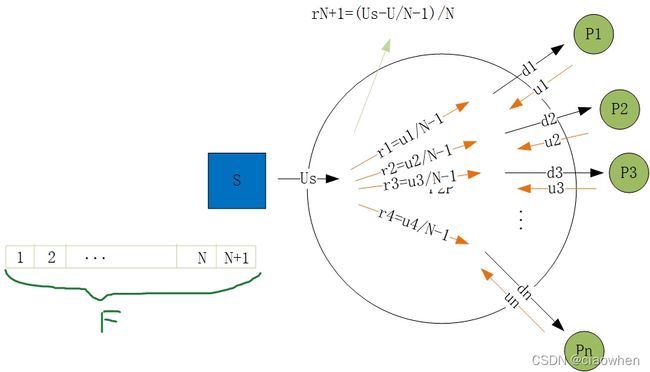
从服务器来看
r 1 + r 2 + . . . + r N + N × r N + 1 = U N − 1 + N × U s − U N − 1 N = U s r_1+r_2+...+r_N+N \times r_N+1 = \frac{U}{N-1} + N\times \frac{U_s - \frac{U}{N-1}}{N} = U_s r1+r2+...+rN+N×rN+1=N−1U+N×NUs−N−1U=Us
从peer来看
U N − 1 + U s − U N − 1 N = U s + U N \frac{U}{N-1} + \frac{U_s - \frac{U}{N-1}}{N} = \frac{U_s+U}{N} N−1U+NUs−N−1U=NUs+U
得 F U s + U N = F N U s + U \frac{F}{\frac{U_s+U}{N}} = \frac{FN}{U_s+U} NUs+UF=Us+UFN.
P25:
- 覆盖网络中有 N N N 个节点。有 N ( N − 1 ) 2 \frac{N(N−1)}{2} 2N(N−1) 条边。
P26:
- a. 是的。他的第一个说法是可能的,只要有足够多的同行在群体中停留足够长的时间。Bob总是可以通过其他同行的主动联系接收数据。
- b. 他的第二个说法也是正确的**。他可以在每个主机上运行一个客户机,让每个客户机“免费运行”。并将从不同主机收集的数据块合并到一个文件中。他甚至可以编写一个小的调度程序,让不同的主机请求文件的不同块。这实际上是P2P网络中的一种
Sybil攻击。
P27:
- a. N N N 个文件,假设我们对视频版本和音频版本按质量和速率的降序进行一对一匹配 。
- b. 需要 2 N 2N 2N 个。
P28:
- a. 如果您首先运行
TCPClient,那么客户机将尝试与不存在的服务器进程建立TCP连接。将不会建立TCP连接。 - b.
UDPClient不与服务器建立TCP连接。因此,如果您首先运行UDPClient,然后运行UDPServer,然后在键盘上键入一些输入,那么一切都可以正常工作。 - c. 如果您使用不同的端口号,那么客户端将尝试与错误的进程或不存在的进程建立TCP连接。会发生错误。
P29:
- 在原始程序中,
UDPClient在创建套接字时未指定端口号。 在这种情况下,代码允许底层操作系统选择端口号。 使用附加行,当执行UDPClient时,将创建一个端口号为5432的UDP套接字。UDPServer需要知道客户端端口号,以便它可以将数据包发送回正确的客户端套接字。 看一下UDPServer,我们看到客户端端口号没有“硬连线”到服务器代码中; 相反,UDPServer通过解析从客户端接收的数据报来确定客户端端口号。 因此UDP服务器将使用任何客户端端口号,包括5432.因此不需要修改UDPServer。
P30:
- 是的,您可以配置多个浏览器以同时打开多个到Web站点的连接。这样做的好处是可以更快地下载文件。缺点是您可能会占用带宽,从而大大减慢共享相同物理链接的其他用户的下载速度。
P31:
- 对于像远程登录(telnet和ssh)这样的应用程序,面向字节流的协议是非常自然的,因为应用程序中没有消息边界的概念。当用户键入字符时,我们只需将该字符放入
TCP连接在其他应用程序中,我们可能会发送一系列在它们之间具有固有边界的消息。 - 例如,当一个SMTP邮件服务器向另一个SMTP邮件服务器发送多个电子邮件消息时。由于
TCP没有指示边界的机制,应用程序必须自己添加指示,以便应用程序的接收端能够区分消息。 - 如果每条消息都被放到一个不同的
UDP段中,接收端就可以这样做在应用程序的发送端不添加任何指示的情况下区分各种消息。
P32:
- 要创建web服务器,我们需要在主机上运行web服务器软件。许多供应商销售网络服务器软件。然而,目前最流行的web服务器软件是
Apache,它是开源的并且是免费的。多年来,开源社区对它进行了高度优化 。