Spark_on_k8s开发说明文档
Spark on k8s架构图

提交任务的方式


spark-submit介绍
提交机制:
① Spark创建一个Spark Driver 运行在一个 Kubernetes pod容器里;
② Spark Driver 再去创建 executors (in Kubernetes pods),并去与这些executors进行通信,然后执行application code;
③ 任务完成后,executor pods 终止运行并被清理掉;而 driver 所在的pod会仍以 **“completed”**状态存活,直到最终垃圾回收或者手动清除。
**Note:**处于completed状态时的driver pod,它不会使用任何的计算资源或是说内存资源。
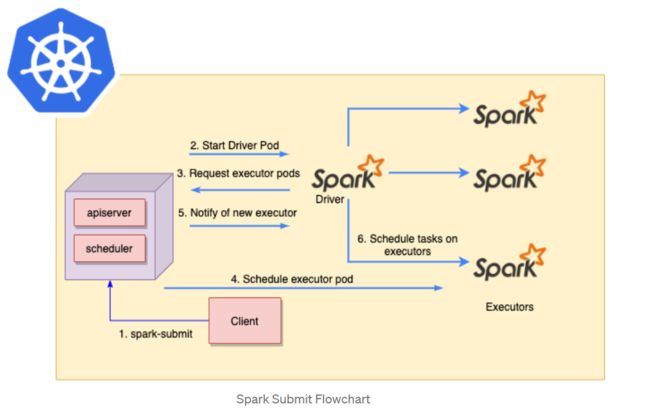
Spark Submit can be used to submit a Spark Application directly to a Kubernetes cluster. The flow would be as follows:
- Spark Submit is sent from a client to the Kubernetes API server in the master node.
- Kubernetes will schedule a new Spark Driver pod.
- Spark Driver pod will communicate with Kubernetes to request Spark executor pods.
- The new executor pods will be scheduled by Kubernetes.
- Once the new executor pods are running, Kubernetes will notify Spark Driver pod that new Spark executor pods are ready.
- Spark Driver pod will schedule tasks on the new Spark executor pods.
其中,步骤2启动Driver Pod后,Driver Pod在driver模式下里面的内容基本就是把arg参数传递给/bin/spark-submit,然后指定以client模式再次启动一个SparkSubmit进程。执行–class 参数后面的类(即,测试中的org.apache.spark.examples.SparkPi)
spark-on-k8s Operator介绍
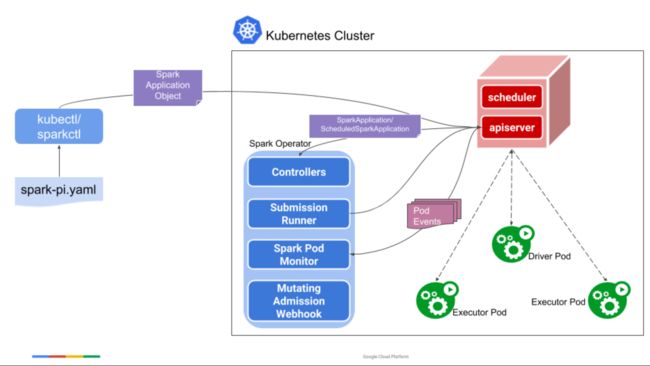
Spark Operator的主要组件如下:
1、SparkApplication Controller : 用于监控并相应SparkApplication的相关对象的创建、更新和删除事件;
**2、Submission Runner:**用于接收Controller的提交指令,并通过spark-submit 来提交Spark作业到K8S集群并创建Driver Pod,driver正常运行之后将启动Executor Pod;
**3、Spark Pod Monitor:**实时监控Spark作业相关Pod(Driver、Executor)的运行状态,并将这些状态信息同步到Controller ;
**4、Mutating Admission Webhook:**可选模块,但是在Spark Operator中基本上所有的有关Spark pod在Kubernetes上的定制化功能都需要使用到该模块,因此建议将enableWebhook这个选项设置为true。
5、sparkctl: 基于Spark Operator的情况下可以不再使用kubectl来管理Spark作业了,而是采用Spark Operator专用的作业管理工具sparkctl,该工具功能较kubectl功能更为强大、方便易用。
其中,Controller是作为Spark Operator的核心组件,用于控制和处理pod以及应用运行的状态变化。
依赖管理

Yarn提供一个全局的spark版本,包括python的版本,全局的包的依赖,缺少环境隔离。而k8s是完全的环境隔离,每一个应用可以跑在完全不同的环境、版本等。Yarn的包管理方案是上传依赖包到HDFS。K8s的包管理方案是自己管理镜像仓库,将依赖包打入image中,支持包依赖管理,将包上传到 OSS/HDFS,区分不同级别任务,混合使用以上两种模式。
使用spark on k8s的优缺点

基础镜像



集群管理

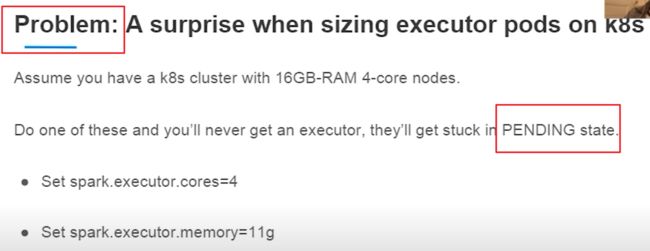
Sizing your pods
problem&solution 1

10% capacity for daemonsets: for networking or monitoring
Scaling your pods
problem & solution 1


problem & solution 2




发现该Executor’要死了,把他的东西都挪到另一个上去

Using spot pods

任务提交实测
1、前提条件
根据自身所要使用的spark版本查询Spark On K8s官方文档,满足其Prerequisites中的条件。
例如,所测的Spark 2.4.0 版本:
- spark version >= 2.3
- Kubenertes cluster version >= 1.6
- 测试对集群权限 kubectl auth can-i
- 集群配置 Kubernetes DNS .
Note:更新Kubernetes Cluster
1、从现有集群更新,每次更新只能跳过一个大版本(from 1.23.x to 1.24.x)或者是在一个大版本内更新(from 1.24.x to 1.24.y,x < y)【具体更新流程查阅https://kubernetes.io/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/ 】
2、直接删除原本集群,重新部署。
2、镜像准备
Kubernetes要求用户准备好能够部署在pod中的container的镜像。从Spark2.3开始,可以借助内置的DockerFile来实现此要求,用户也可以根据该DockerFile文件添加自己的需求实现自定义。
**例子:**构建镜像
./bin/docker-image-tool.sh -r raaiiid57 -t my-tag build
./bin/docker-image-tool.sh -r raaiiid57 -t my-tag push
push之后可以在dockerhub上查看到自己提交的镜像;
-r:仓库名
-t:标签名
3、Cluster 模式下提交
bin/spark-submit \
--master k8s://https://ip:port \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=raaiiid57/spark:v1.0 \
--conf spark.executor.request.cores=3400M \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=default \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar
–master k8s://kubectl cluster-info查询
–conf spark.executor.request.cores=3400M (控制每个Executor可以使用的cores,一般部署节点cores的85%,过多会导致driver pod 一直处于Pending状态);
4、任务报错调试
① 获取日志
kubectl -n=
若配置了DashBoard,也可直接查看到该日志内容
② 获取Driver Web UI界面
$ kubectl port-forward
然后,通过访问http://localhost:4040即可访问到Spark Driver UI
③ Debugging
获取基本信息
$ kubectl describe pod
获取详细的运行时错误
$ kubectl logs
问题记录
kubectl describe pod [podID]
kubectl logs [podID]
1、spark-submit命令行提交时,不要有任何多余的空格
格式应该如下:
bin/spark-submit \
--master k8s://https://ip:port \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=raaiiid57/spark:v1.0 \
--conf spark.executor.request.cores=3400M \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=default \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar
2、 WARN WatchConnectionManager:185 - Exec Failure: HTTP 403, Status: 403 - java.net.ProtocolException: Expected HTTP 101 response but was ‘403 Forbidden’
在构建容器的DockerFile中添加kubernetes-client-4.2.2.jar,删除原有的kubernetes-client-3.0.0.jar
RUN rm $SPARK_HOME/jars/kubernetes-client-3.0.0.jar
ADD https://repo1.maven.org/maven2/io/fabric8/kubernetes-client/4.4.2/kubernetes-client-4.4.2.jar $SPARK_HOME/jars
3、Exception in thread “main” java.lang.NoSuchMethodError: io.fabric8.kubernetes.api.model.AuthInfo.getExec()Lio/fabric8/kubernetes/api/model/ExecConfig;
**原因:**存在相关jar包版本不匹配,移除了kubernetes-client-3.0.0.jar 引进kubernetes-client-4.2.2.jar,恢复jar包即可;
在解决上面问题2的时候,错误的将kubernetes-client-3.0.0.jar放到了宿主机环境下的spark jar包文件夹中,导致执行spark-submit时出现了有方法找不到的问题,恢复原来jar包内容即可(即删除错误加入宿主机环境中的kubernetes-client-4.2.2.jar,放回kubernetes-client-3.0.0.jar)
4、Error initializing SparkContext.org.apache.spark.SparkException: External scheduler cannot be instantiated
kubectl create clusterrolebinding default --clusterrole=edit --serviceaccount=default:default --namespace=default
kubectl create serviceaccount spark
kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=default:spark --namespace=default
spark-submit --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark
kubectl delete serviceaccount [name]
kubectl delete clusterrolebinding [name]
[name] 可用 kubectl get 资源类型 来查询;
serviceaccount spark
kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=default:spark --namespace=default
spark-submit --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark
```SHELL
kubectl delete serviceaccount [name]
kubectl delete clusterrolebinding [name]
[name] 可用 kubectl get 资源类型 来查询;