通过Python提取pdf中的文字
通过Python的pdfplumber库提取pdf中的文字
- 背景
- 安装
-
- pdfplumber
-
- 提取PDF文字
- 提取PDF表格
- PyPDF2
-
- 分割pdf
- 合并PDF
- pdf旋转
- PDF加密解密
-
- 加密
- 解密
- 加水印
背景
参加了chatglm的金融大模型挑战赛,提供的数据集是各个公司不同年份的年报(.pdf),需要一款工具对其进行内容的提取。
给大家介绍最常用的两个库 「pdfplumber」、「pypdf2」。
「pdfplumber:」
pdfplumber库按页处理 pdf ,获取页面文字,提取表格等操作。
学习文档:pdfplumber
「pypdf2:」
PyPDF2 是一个纯 Python PDF 库,可以读取文档信息(标题,作者等)、写入、分割、合并PDF文档,它还可以对pdf文档进行添加水印、加密解密等。
官方文档:pypdf2
安装
pip install pdfplumber
pip install pypdf2
pdfplumber
提取PDF文字
import pdfplumber
local = 'C:/Users/Downloads/'
with pdfplumber.open(local+"2020-01-21__江苏安靠智能输电工程科技股份有限公司__300617__安靠智电__2019年__年度报告.pdf") as pdf:
page01 = pdf.pages[0] # 指定页码
num_pages = len(pdf.pages) #页码总数
print(num_pages)
for page_num in range(num_pages): #提取所有页
page = pdf.pages[page_num]
text = page.extract_text() #提取文本
print(text)
txt_file = open("C:/Users/test.txt", mode='a', encoding='utf-8')
txt_file.write(text)# 提取所有pdf文字并写入文本中

![]()
提取PDF表格
import pdfplumber
from openpyxl import Workbook #保存表格,需要安装openpyxl
local = 'C:/Users/Downloads/'
with pdfplumber.open(local+"2020-01-21__江苏安靠智能输电工程科技股份有限公司__300617__安靠智电__2019年__年度报告.pdf") as pdf:
page01 = pdf.pages[8] # 指定页码
table1 = page01.extract_table() # 提取单个表格
# table2 = page01.extract_tables()#提取多个表格
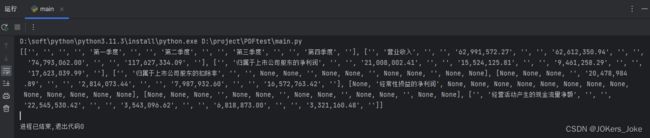
print(table1)
workbook = Workbook()
sheet = workbook.active
for row in table1:
sheet.append(row)
workbook.save(filename="C:/Users/人力资源部岗位编制.xlsx")
![]()
PyPDF2
PyPDF2 中有两个最常用的类(已更新为最新pypdf2,即3.0.1):PdfReader和PdfWriter,在最新的分别用于读取 PDF 和写入 PDF。其中PdfReader传入参数可以是一个打开的文件对象,也可以是表示文件路径的字符串。而PdfWriter则必须传入一个以写方式打开的文件对象。
分割pdf
from PyPDF2 import PdfReader, PdfWriter
file_reader = PdfReader("C:/Users/Downloads/2020-01-21__江苏安靠智能输电工程科技股份有限公司__300617__安靠智电__2019年__年度报告.pdf")
# len(file_reader.pages) 获取总页数
for page in range(len(file_reader.pages)):
# 实例化对象
file_writer = PdfWriter()
# 将遍历的每一页添加到实例化对象中
file_writer.add_page(file_reader.pages[page])
with open("C:/Users/{}.pdf".format(page),'wb') as out:
file_writer.write(out)
合并PDF
将上述分割的pdf合并成一个文件
from PyPDF2 import PdfReader, PdfWriter
file_writer = PdfWriter()
for page in range(311):
# 循环读取需要合并pdf文件
file_reader = PdfReader("C:/Users/{}.pdf".format(page))
# 遍历每个pdf的每一页
for page in range(len(file_reader.pages)):
# 写入实例化对象中
file_writer.add_page(file_reader.pages[page])
with open("C:/Users/合并.pdf",'wb') as out:
file_writer.write(out)
![]()
pdf旋转
from PyPDF2 import PdfReader, PdfWriter
file_reader = PdfReader("C:/Users/Downloads/2020-01-21__江苏安靠智能输电工程科技股份有限公司__300617__安靠智电__2019年__年度报告.pdf")
file_writer = PdfWriter()
page = file_reader.pages[0].rotate(90) # 第1页顺时针旋转90度
file_writer.add_page(page) # 写入
page = file_reader.pages[1].rotate(-90) # 第2页逆时针旋转90度
file_writer.add_page(page) # 写入
with open("C:/Users/旋转.pdf",'wb') as out:
file_writer.write(out)

PDF加密解密
加密
from PyPDF2 import PdfReader, PdfWriter
file_reader = PdfReader("C:/Users/Downloads/2020-01-21__江苏安靠智能输电工程科技股份有限公司__300617__安靠智电__2019年__年度报告.pdf")
file_writer = PdfWriter()
for page in range(len(file_reader.pages)):
file_writer.add_page(file_reader.pages[page])
file_writer.encrypt('123456') # 设置密码
with open("C:/Users/加密后.pdf",'wb') as out:
file_writer.write(out)

解密
from PyPDF2 import PdfReader, PdfWriter
file_reader = PdfReader("C:/Users/加密后.pdf")
file_reader.decrypt('123456')
file_writer = PdfWriter()
for page in range(len(file_reader.pages)):
file_writer.add_page(file_reader.pages[page])
with open("C:/Users/解密后.pdf",'wb') as out:
file_writer.write(out)
加水印
首先准备一个水印文档,可以用空白word添加图片或者文字转成pdf文件。

from PyPDF2 import PdfReader, PdfWriter
sy = PdfReader("C:/Users/Desktop/新建文件夹/水印.pdf")# 导⼊包含⼀个⽔印的pdf⽂件,只要有⼀⻚即可
mark_page = sy.pages[0] # 水印所在的页数
# 读取添加水印的文件
file_reader = PdfReader("C:/Users/311.pdf")
file_writer = PdfWriter()# 创建⼀个writer对象,⼀会⼉⽤来写新⽣成的pdf
# 逐⻚读取pdf内的内容
for page in range(len(file_reader.pages)):
# 读取需要添加水印每一页pdf
source_page = file_reader.pages[page]
source_page.merge_page(mark_page) # 将当前⻚与⽔印⻚合并
file_writer.add_page(source_page) # 将当前⻚加⼊到待写⼊区域
# 将全部合并完的pdf保存到⽂件
with open("C:/Users/添加水印后.pdf",'wb') as out:
file_writer.write(out)
