利用Python提取PDF文件中的文本信息
如何利用Python提取PDF文件中的文本信息
日常工作中我们经常会用到pdf格式的文件,大多数情况下是浏览或者编辑pdf信息,但有时候需要提取pdf中的文本,如果是单个文件的话还可以通过复制粘贴来直接将文本信息复制出来,但如果是要提取成本上千个pdf文件中的文本信息,有没有什么比较快捷的方式可以实现自动化提取呢?作为一个python爱好者,答案当然是想办法通过python代码实现pdf文本信息的批量自动化提取,这里介绍以下五个pdf操作库:PyPDF2, Textract, tika, pdfPlumber, pdfMiner,本文主要参考这个博客撰写而成:How to Extract Text from PDF
一、PyPDF2
推荐程度:★★★
pypi官网地址:PyPDF2
安装方法:pip install PyPDF2
工具包简介:
- 可以提取pdf内文档信息(标题、作者、…)
- 可以分割、合并pdf
- 可以对pdf文件进行加密或解密
- …
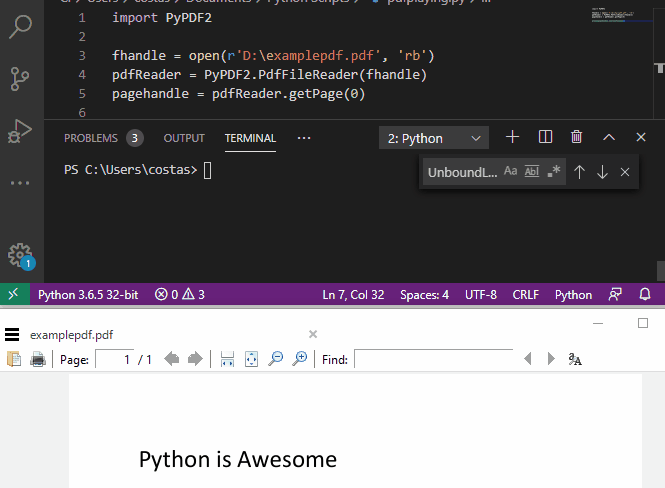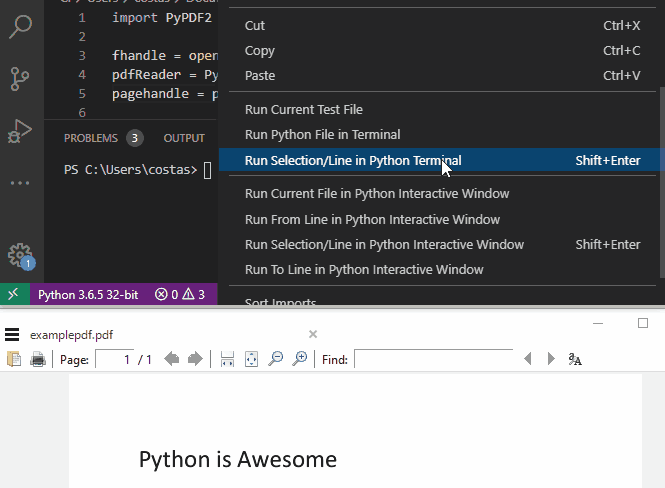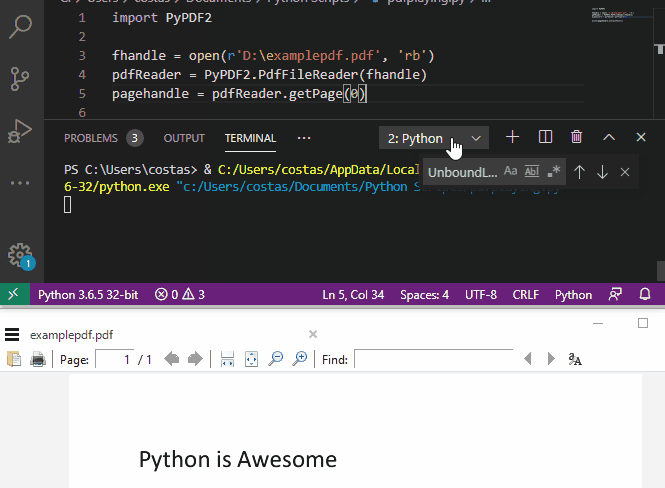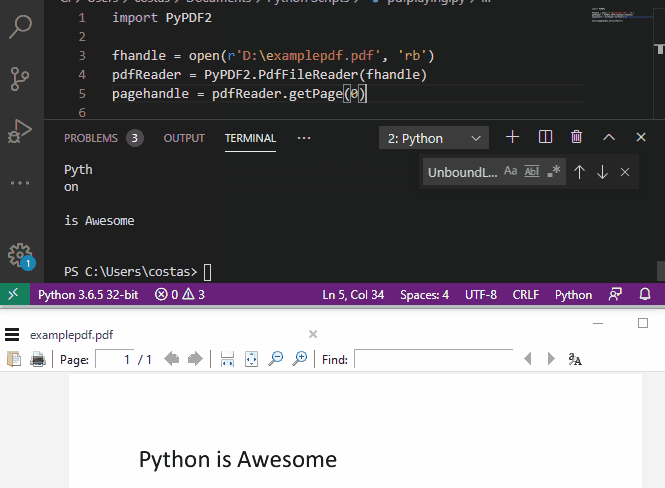
这个库的优点是安装简便,但是虽然可以准确提取出文件内的文本信息,但会把一行文本内的每个单词打断成多行,甚至把完整的单词也切割开来,识别精度不是很高。
代码示例:
import PyPDF2
fhandle = open(r'D:\examplepdf.pdf', 'rb')
pdfReader = PyPDF2.PdfFileReader(fhandle)
pagehandle = pdfReader.getPage(0)
print(pagehandle.extractText())
二、textract
推荐程度:不推荐
pypi官网地址:textract
安装方法:pip install textract
工具包简介:
- 可以轻松提取提取任何文档中的文字
虽然官方号称可以轻松提取任何文件的文本信息,但经过实测,目前这个库存在严重的bug,在python3.7环境下提取任何pdf文件都会报错。
代码示例:
# some python file
import textract
text = textract.process("path/to/file.extension")
三、Apache Tika
推荐程度:★★
pypi官网地址:tika
安装方法:pip install tika
工具包简介:
- Apache Tika库的Python端口
- 由于tika-python会在后台启动tika rest服务器,系统需安装Java 7+ 版本才能正常使用这个库
这个库最大的问题是需要依赖Java环境使用,配置比较麻烦,并且即使配置好环境,还是有可能没法获得文本解析结果。
![]()
代码示例:
from tika import parser
file = "D:\\440000201900BD8P6M.pdf"
file_data = parser.from_file(file)
text = file_data['content']
print(text)
四、pdfPlumber
推荐程度:★★★★★
pypi官网地址:pdfPlumber
安装方法:pip install pdfplumber
工具包简介:
- 可以为pdf文件插入文本字符、矩形和行的详细信息
- 对于非扫描格式pdf解析效果最佳
- 基于pdfminer.six构建
这个库安装简单,不容易出幺蛾子,使用方式也简单明了,pdf文本提取精度非常高,强烈推荐!!!

代码示例:
import pdfplumber
with pdfplumber.open(r'D:\examplepdf.pdf') as pdf:
first_page = pdf.pages[0]
print(first_page.extract_text())
五、pdfminer
推荐程度:★★★★
pypi官网地址:pdfminer
安装方法:pip install pdfplumber
工具包简介:
- 支持 PDF-1.7
- 可以获取文本的提取位置以及其他布局信息
- 可将pdf转换为其他格式(HTML/XML)
- 支持基本的加密方式(RC4 and AES)
- 支持多种字体类型(Type1, TrueType, Type3, and CID)
官方说明很详细,但是使用起来略微有些复杂,需要仔细看示例代码才好上手,不过文本提取精度也相当不错!
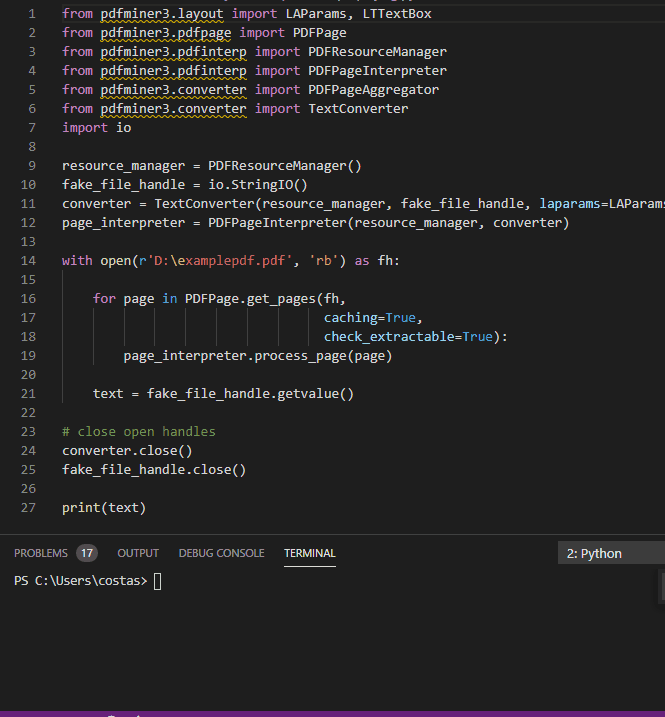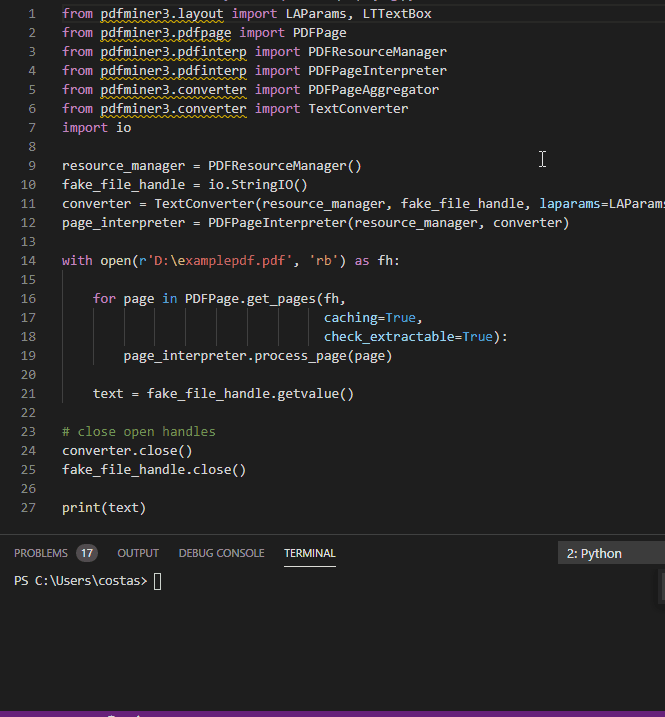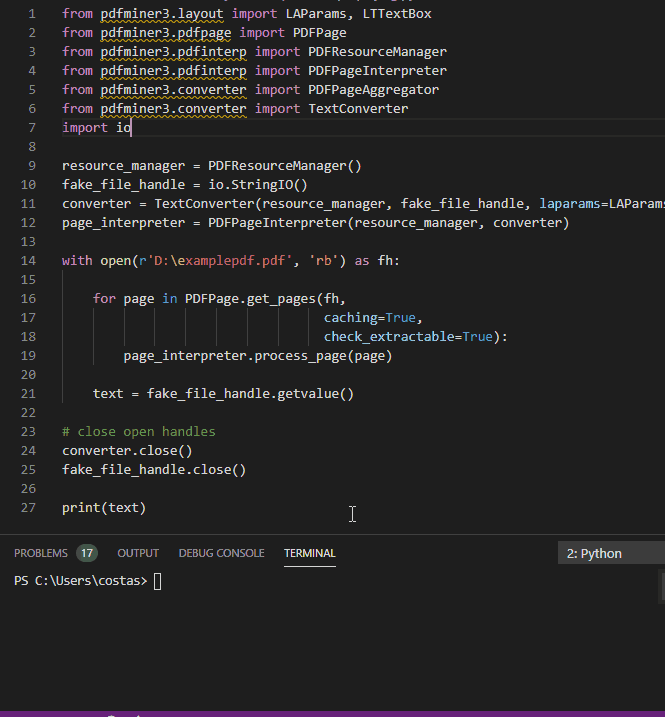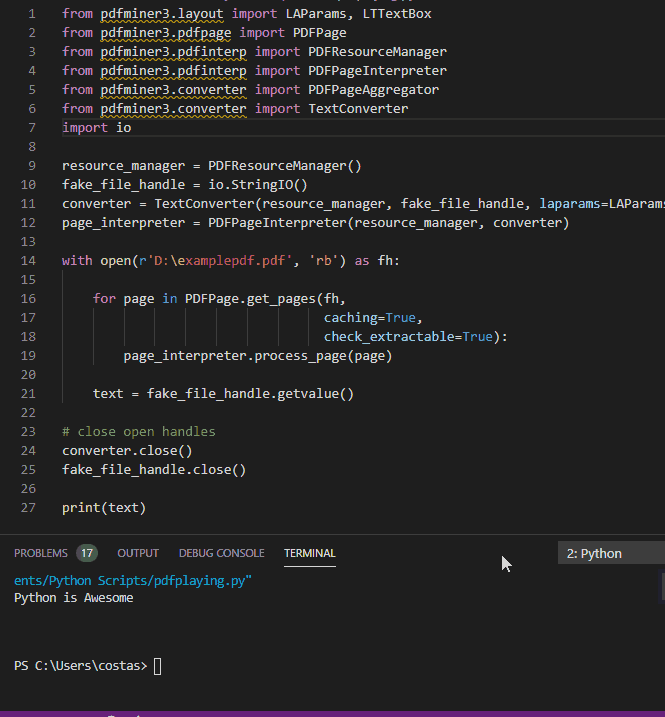
代码示例:
from pdfminer3.layout import LAParams, LTTextBox
from pdfminer3.pdfpage import PDFPage
from pdfminer3.pdfinterp import PDFResourceManager
from pdfminer3.pdfinterp import PDFPageInterpreter
from pdfminer3.converter import PDFPageAggregator
from pdfminer3.converter import TextConverter
import io
resource_manager = PDFResourceManager()
fake_file_handle = io.StringIO()
converter = TextConverter(resource_manager, fake_file_handle, laparams=LAParams())
page_interpreter = PDFPageInterpreter(resource_manager, converter)
with open('/path/to/file.pdf', 'rb') as fh:
for page in PDFPage.get_pages(fh,
caching=True,
check_extractable=True):
page_interpreter.process_page(page)
text = fake_file_handle.getvalue()
# close open handles
converter.close()
fake_file_handle.close()
print(text)
总结
当前用于解析操作pdf的python包已经有相当之多,本文只是列出了其中比较有代表性的五种,在实际使用中首推pdfPlumber,安装简便,上手也比较容易,其次是pdfminer,虽然学习成本高一点,但pdf操作功能相当齐全。总之,只要能较为熟练的掌握其中一种工具包,在某些需要操作大量pdf的情况下,应该可以极大提升工作效率。