《深度探索c++对象模型》第二章:构造函数
2.1 Default Constructor的建构操作
常见的两个误解:
1、任何类如果没有定义默认构造函数,编译器就会合成一个出来(错误)
2、编译器合成出来的默认构造函数会明确设定类里面的每一个数据成员的默认值,也就是会帮类里所有数据成员都初始化(错误)
编译器会合成默认构造函数的四种情况
情况一、类A的数据成员里有类B的对象,且类B有构造函数
如果类A没有构造函数,那么编译器就会合成一个默认构造函数。例子:
class Foo{
public:
Foo(){};
Foo(int a);
//...
};
class Bar{
public:
Foo foo; //注意是组合(内含),不是继承
char *str;
};
Bar bar; //Bar::foo必须在此处初始化
这种情况下编译器会为类Bar合成一个默认构造函数,这个默认构造函数含有必要的代码,能够调用类Foo的构造函数来初始化Bar::foo,但它并不产生任何代码来初始化Bar::str。因为将Bar::foo初始化是编译器的责任,而将Bar::str初始化时程序员的责任。被合成的默认构造函数可能是这样的(为了简化讨论,下面的这些例子都省略掉了隐含的this指针):
//Bar默认构造函数可能是这样的:
inline
Bar::Bar(){
//c++伪代码
foo.Foo::Foo();
}
被合成的默认构造函数只满足编译器的需要,而不是程序的需要,为了让这个程序片段能够正确执行,字符指针str也需要被初始化。
假设程序员提供了构造函数,初始化了字符指针str:
Bar::Bar(){str=0;} //程序员提供了显式的构造函数
str初始化了,但是对象foo还未初始化,但是构造函数已经被明确定义出来了,编译器没法合成第二个,此时编译器会扩展这个构造函数,在程序员写的代码前调用类Foo的构造函数初始化foo:
//扩展后的构造函数可能是这样的
//c++伪代码
Bar::Bar(){
foo.Foo()::Foo(); //附加的代码
str=0; //程序员的代码
}
假如现在有多个类Foo,Foo1,Foo2,而类Bar中依次含有这些类的对象,那么在合成Bar的默认构造函数或者扩展构造函数都是与上面的类似,按照这些对象的声明顺序依次调用他们的构造函数。
情况二、类A继承类B,且类B有构造函数
这种情况与第一种情况类似。
如果类A没有构造函数,那么编译器就会合成一个默认构造函数,这个默认构造函数会调用类B的构造函数。如果是多重继承,则根据声明的次序依次调用基类的构造函数。
如果类A有构造函数(一个或者多个),但是这些构造函数里面没有调用类B的构造函数,那么编译器会扩展这些构造函数,在程序员的代码前调用类B的构造函数。如果是多重继承,则根据声明的次序依次调用基类的构造函数。如果同时存在着情况一,会先调用基类的构造函数,再调用数据成员里面其他类的对象的构造函数(即构造函数调用优先情况二,其次情况一)。
情况三、带有一个虚函数的类
分两种情况,都需要合成默认构造函数:
1、类声明(或继承)一个虚函数
2、类派生自一个继承串链,其中有一个或以上的虚基类
不管哪种情况,由于缺乏显式的构造函数,编译器会详细记录合成一个默认构造函数的必要信息,例子:
class Widget{
public:
virtual void flip()=0;
//...
};
void flip(const Widget &widget){ widget.flip(); }
//假设Bell和Whistle都派生自Widget
void foo(){
Bell b;
Whistle w;
flip(b); //调用的是Bell::flip()
flip(w); //调用的是Whistle::flip()
}
编译期间会发生下面两个扩展操作:
1、一个虚函数表(vtbl)会被编译器产生出来,里面放置类的虚函数的地址
2、在每一个对象中,一个额外的虚函数表指针(vptr)会被编译器合成出来,里面存储着类的虚函数表(vtbl)的地址。
此外,widget.flip()的虚拟引发操作会被重新改写:
//原来:widget.flip(),现在转换成:
(*widget.vptr[1])(&widget) //第一章提到索引0存放着type_info object
// &widget代表要交给“实际被调用的某个flip()函数实体”的this指针
为了让这个虚拟函数的多态机制生效,编译器必须为每一个Widget(或其派生类)的对象的虚函数表指针vptr设定初始值,放置适当的虚函数表地址。编译器会生成或者扩展构造函数,以便正确地初始化每一个对象的vptr。
情况四、带有虚基类的类
class X { public: int i;};
class A:public virtual X { public:int j;};
class B:public virtual X { public:double d;};
class C:public A,public B { public:int k;};
//无法在编译期决定出pa->X::i的位置
void foo(const A* pa){ pa->i=1024;}
foo(new A);
foo(new C);
在这段程序中,编译器无法确定pa指向哪个对象,也就无法确定在这个对象里虚基类X的位置,也就无法确定在这个对象里虚基类X::i的位置。cfront编译器的做法是在派生类对象中安插一个指针,这个指针指向虚基类,所有经由引用或者指针来存取虚基类的操作都可以通过这个指针完成。foo可以被改写成:
void foo(const A* pa){ p->__vbcx->i=1024;}//其中__vbcX表示编译器生成的指针,指向虚基类X
生成这个指针就是在构造函数里完成的,如果没有构造函数,就合成一个默认构造函数执行这个操作,如果有构造函数,那就扩展构造函数执行这个操作。虚基类的情况,不同编译器的做法不一样,但是共同点都是确认虚基类在每一个派生类对象里的位置,并将这个操作写入默认构造函数或者扩展构造函数。
2.2 拷贝构造函数的建构操作
三种可能调用拷贝构造函数的情况:
注意情况3不是一定会调用拷贝构造函数,详见2.3节。
1、明确地以一个对象的内容作为另一个对象的初值
calss X{...};
X x;
X xx=x; //明确地以一个对象的内容作为另一个对象的初值
2、对象通过值传递作为函数参数
extern void foo(X x);
void bar(){
X xx;
foo(xx); //xx通过值传递作为函数foo的参数
}
3、函数return回一个对象
X foo_bar(){
X xx;
return xx;
}
编译器会合成默认拷贝构造函数的四种情况
按照书中的说法,如果一个类没有展现出“bitwise copy semantics”(逐位拷贝语义学),那么编译器就会为其合成默认拷贝构造函数或者扩展拷贝构造函数。与与上一小节合成默认构造函数的四种情况类似:
1、类A的数据成员里有类B的对象,且类B有拷贝构造函数
(不论类B的拷贝构函数是被程序员显示声明还是编译器自动合成的)
2、类A继承类B,且类B有拷贝构造函数
(不论类B的拷贝构函数是被程序员显示声明还是编译器自动合成的)
上述两种情况与上一小节合成默认构造函数类似,编译器必须将成员中其他类或者基类的拷贝构造函数的调用操作插入到合成的默认拷贝构造函数或者扩展已有的拷贝构造函数中。
3、当类声明了一个或者多个虚函数时
上一节提到,只要有一个类声明了一个或者多个虚函数时,编译期间会发生下面两个扩展操作:
1、一个虚函数表(vtbl)会被编译器产生出来,里面放置类的虚函数的地址
2、在每一个对象中,一个额外的虚函数表指针(vptr)会被编译器合成出来,里面存储着类的虚函数表(vtbl)的地址。
拷贝构造函数在初始化对象时,也要正确地设定虚函数表指针(vptr)的值
class ZooAnimal{
public:
ZooAnimal(){};
virtual ~ZooAnimal();
//...
virtual void animate();
virtual void draw();
private:
//ZooAnimal的animate()和draw()所需要的数据
};
class Bear:public ZooAnimal{
public:
Bear();
void animate(); //虽未写明是virtual,但它其实是virtual
void draw(); //虽未写明是virtual,但它其实是virtual
virtual void dance()
private:
//Bear的animate(),draw()和dance()所需要的数据
};
Bear yogi;
Bear winnie=yogi;
yogi会被Bear的构造函数初始化,编译器会自动扩展Bear的构造函数,将yogi的虚函数表指针(vptr)设定指向类Bear的虚函数表(vtbl),虚函数表是属于某个类的,不是属于某个对象的。因此,直接把yogi的vptr的值拷贝给winnie的vptr是安全的。
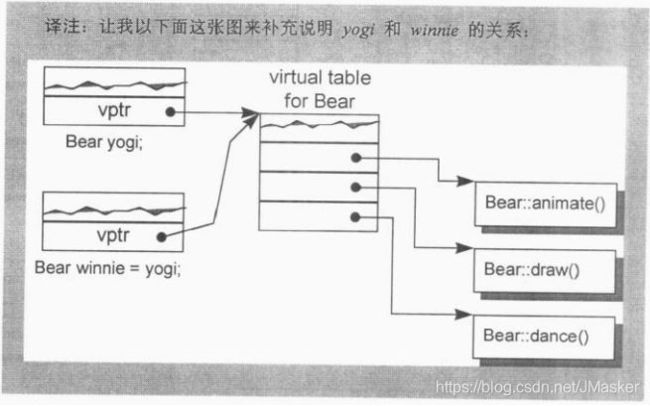
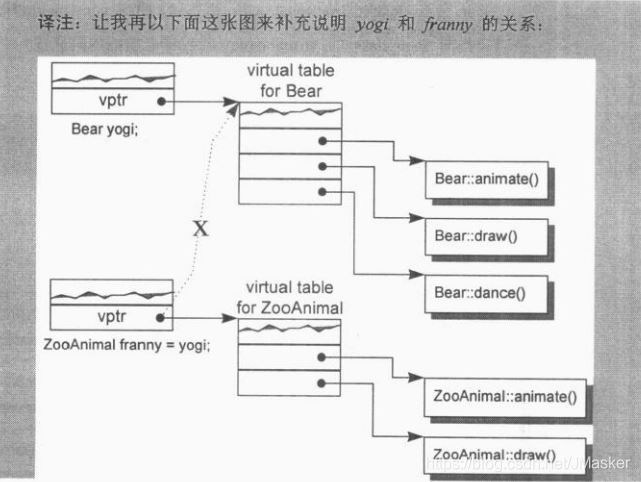
当基类对象用派生对象的内容做初始化时,也必须保证vptr的复制操作是安全的,例如:
ZooAnimal franny = yogi; //会发生切割(sliced)
franny的vptr不可以被设定指向Bear的虚函数表vtbl,(但是如果yogi的vptr被直接"bitwise copy"(逐位拷贝)的话,就会导致此结果)。所以合成出来的默认拷贝构造函数或者扩展显式声明的拷贝构造函数会明确设定franny的vptr指向ZooAnimal的虚函数表vtbl,而不是直接从右手边的对象yogi中将其vptr的值拷贝过来。
void draw(const ZooAnimal &zoey){ zoey.draw();}
void foo(){
//实际上franny只含有了yogi中ZooAnimal subobject的部分,Bear的部分在初始化时已经被切割了
//如果franny被声明为一个引用或者指针时,那么经过franny调用的draw()才会是Bear的实体
ZooAnimal franny=yogi;//franny的vptr指向的是ZooAnimal的虚函数表而非Bear的虚函数表
draw(yogi); //调用Bear::draw()
draw(franny); //调用ZooAnimal::draw()
}
4、当类派生自一个继承串链,其中有一个或多个虚基类时
略,3.4节对虚基类有更详细的讨论
2.3 程序转化语义学
明确的初始化操作
X x0;
void foo_bar(){
X x1(x0);
X x2=x0;
X x3=X(x0);
}
上面对x1,x2,x3的定义都显式地以x0来初始化。必要的程序转化有两个阶段:
1、重写每一个定义,其中的初始化操作会被剥除(严谨的C++用词中,定义是指“占用内存”的行为)
2、类的拷贝构造函数调用操作会被安插进去
//可能的程序转换,c++伪代码
void foo_bar(){
//上述的阶段1
X x1; //重写定义,初始化操作被剥除
X x2;
X x3;
//上述的阶段2
x1.X::X(x0); //编译器安插类X的拷贝构造函数 X::X(const X& xx)
x2.X::X(x0);
x3.X::X(x0);
}
函数参数传递的初始化
void foo(X x0);
//调用foo函数
X xx;
foo(xx);
一种实现的策略是生成一个临时对象,然后将这个对象交给函数:
//上面调用的程序可能转换成:
//c++伪代码
X __temp0; //编译器生成的临时对象
__temp0.X::X(xx); //调用拷贝构造函数,用xx初始化__temp0
foo(__temp0); //重写函数调用操作,使用这个临时对象
此外,foo函数的声明也要改写成引用传递,不然生不生成临时对象都是一样,转换了半天还是通过值传递,只不过从xx变成了__temp0,还是没有变化
void foo(X& x0);
在foo函数调用完后,X的析构函数会执行用来释放临时对象__temp0
另一种实现策略是以“拷贝建构”的方式把实际参数直接建构在其应该的位置上(生成一个局部对象),该位置视函数活动范围的不同记录于程序堆栈中,在函数返回之前,局部对象的类的析构函数如果有定义的话会执行。
返回值的初始化
X bar(){
X xx; //xx是一个局部对象
//...
return xx;
}
bar()的返回值是如何从局部对象xx中拷贝过来的?在cfront中的解决方法是一个双阶段转化:
1、在函数的参数列表加一个类对象的引用,这个就是返回值。而函数并不真正返回值
2、在return指令前安插一个拷贝构造函数调用操作,用将要返回的对象初始化第一步中的引用
//可能的转换(c++伪代码):
void bar(X& _result){ //注意函数返回值类型被修改成void,参数列表增加了X的引用类型
X xx;
xx.X::X(); //编译器产生的代码,调用X的构造函数
//...
__result.X::X(xx); //编译器产生的代码,调用X的拷贝构造函数,用xx初始化__result
return; //不返回值,__result就是调用者想要的值
}
调用bar函数的操作也会被转化:
//原本的调用操作:
X xx=bar();
//可能的转化操作:
X xx;//注意,这里编译器不用安插代码来调用X的构造函数来构造xx,因为xx会在bar里通过拷贝构造函数来构造
bar(xx);
//同样,如果程序声明了一个函数指针:
X (*pf)();
pf=bar;
//也需要进行转化:
void (*pf)(X&);
pf=bar;
在编译层面做优化(NVR优化)
NVR(Name Return Value)优化:
//程序代码:
X bar(){
X xx;
//...
return xx;
}
//程序代码可能转化成:
void bar(X& _result){
X xx; //1 堆栈中要预留xx的存储空间
xx.X::X(); //2 编译器产生的代码,调用X的构造函数
//...
__result.X::X(xx); //3 编译器产生的代码,调用X的拷贝构造函数,用xx初始化__result
//4 编译器产生的代码,调用X的析构函数析构xx
//5 堆栈中回收xx的内存
return;
}
//优化后可能转化成:
void bar(X& __result){
__result.X::X(); //构造函数被调用
//...
return;
}
通过上面两段转化后的代码可以发现,优化前后的操作数量明显不同,对效率的改善确实有效。
书中还提到cfront中程序员必须给class X定义拷贝构造函数才能触发NRV优化,不然还是按照最初的较慢的方式执行(经过试验其他编译器,NVR优化和拷贝构造函数是否定义没关系)
NVR的缺点:
1、编译器NVR优化对程序员是不可见的,程序员不知道编译器优没有优化,特别是程序复杂的时候
2、本来程序调用拷贝构造函数,再调用析构函数,这两个操作是对称的,如果编译器进行了NVR优化,那么和程序员期待的调用是不一样的,打破了这种对称性。
2.4构造函数的初始化列表
必须使用初始化列表的四种情况:
1、当初始化一个引用成员时
2、当初始化一个const成员时
3、当调用一个基类的构造函数,而它拥有一组参数时
4、当调用一个成员对象的类的构造函数,而它拥有一组参数时
使用初始化列表会发生什么?
//程序员代码
class Word{
String _name;
int _cnt;
public:
Word(){
_name=0; //这里没错,但是效率不高,因为会产生一个临时的String对象
_cnt=0;
}
};
//构造函数可能的内部扩展结果(c++伪码):
Word::Word(){
_name.String::String(); //调用String的构造函数
String temp=String(0); //产生临时的对象
_name.String::operator=(temp);//"memberwise"(逐成员地)地拷贝_name,String里含有int和char*
temp.String::~String(); //摧毁临时对象
_cnt=0;
}
更有效率的构造函数:
//程序员代码
Word::Word():_name(0){
_cnt=0;
}
//可能的扩展代码(c++伪码)
Word::Word( /* 这里有个隐式的this指针传递进来作为参数 */){
_name.String::String(0); //调用String(int)构造函数
_cnt=0;
}
注意,初始化列表会按照成员在类里的声明次序在构造函数内安插初始化操作(而并不是按照初始化列表里的排列次序),并且在任何程序员的代码之前。
class X{
int i;
int j;
public:
//这里因为在类X里先声明i,再声明j,在构造函数里会按照声明的次序先初始化i,再初始化j
//可是这里的初始化列表用j初始化i,而j还没有初值,所以i(j)的结果导致i的值无法预知。
X(int val):j(val),i(j){} //错误,而且这个bug不容易观察出来
};
//一种比较好的方式:
X::X(int val):j(val){
i=j;//注意,初始化列表的安插初始化操作在任何程序员的代码之前,所以先初始化j,再初始化i
}
假设xfoo()是类X的一个成员函数,下面这种情况也是可以的(但是不推荐,最好别这样用)
//程序员代码
X::x(int val):i( xfoo(val) ),j(val){}
//扩展的代码(c++伪码):
X::X( /* 隐式的this指针 */,int val){
i=this->xfoo(val);
j=val;
}