ElasticSearch之HTTP索引操作和文档操作
文章目录
- 1. 核心概念及数据格式
-
- 1.1 索引( Index)
- 1.2 类型( Type)
- 1.3 文档( Document)
- 1.4 字段( Field)
- 1.5 映射( Mapping)
- 1.6 分片( Shards)
- 1.7 副本( Replicas)
- 1.8 分配( Allocation)
- 1.9 数据格式
- 2. HTTP操作
-
- 2.1 索引操作
-
- 2.1.1 创建索引
- 2.1.2 查看所有索引
- 2.1.3 查看单个索引
- 2.1.4 删除索引
- 2.2 文档操作
-
- 2.2.1 创建文档
- 2.2.2 查看文档
- 2.2.3 修改文档
- 2.2.4 修改字段
- 2.2.5 删除文档
- 2.2.6 条件删除文档
- 2.2.7 查询文档中所有数据
1. 核心概念及数据格式
1.1 索引( Index)
一个索引就是一个拥有相似特征的文档的集合。
比如,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母),并且当需要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
能搜索的数据必须索引,好处是可以提高查询速度。
1.2 类型( Type)
在一个索引中,可以定义一种或多种类型。一个类型是索引的一个逻辑上的分类/分区。通常,会为具有一组共同字段的文档定义一个类型。ES不同的版本,类型发生了不同的变化。
| 版本 | Type |
|---|---|
| 5.x | 支持多种type |
| 6.x | 只能有一种type |
| 7.x | 默认不再支持自定义索引类型(默认类型为:_doc) |
1.3 文档( Document)
一个文档是一个可被索引的基础信息单元,也就是一条数据。
文档以JSON格式来表示。在一个index/type里面,可以存储任意多的文档。
1.4 字段( Field)
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。
1.5 映射( Mapping)
mapping是对处理数据的方式和规则做一些限制,如:某个字段的数据类型、默认值、分析器、是否被索引等。
1.6 分片( Shards)
一个索引可以存储超出单个节点硬件限制的大量数据。
比如,一个具有10亿文档数据的索引占据1TB的磁盘空间,而任一节点都可能没有这样大的磁盘空间。或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,每一份就称之为分片。在创建一个索引时,可以指定想要的分片数量。每个分片本身也是一个功能完善并且独立的“索引“,这个“索引”可以被放置到集群中的任何节点上。
分片很重要,主要有两方面的原因:
- 允许水平分割 / 扩展内容容量。
- 允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合和搜索请求,是完全由Elasticsearch管理的,对于作为用户来说,这些都是透明的,无需过分关心。
一个 Elasticsearch索引是分片的集合。当 Elasticsearch在索引中搜索的时候,会发送查询到每一个属于索引的分片,然后合并每个分片的结果到一个全局的结果集。
1.7 副本( Replicas)
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
复制分片之所以重要,有两个主要原因:
- 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(
original/primary)分片置于同一节点上是非常重要的。 - 扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。
分片和复制的数量可以在索引创建时指定。在索引创建之后,可以在任何时候动态地改变复制的数量,但是事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片1个主分片和1个复制,这意味着,如果集群中至少有两个节点,索引将会有1个主分片和另外1个复制分片(1个完全拷贝),这样的话每个索引总共就有2个分片,需要根据索引需要确定分片个数。
1.8 分配( Allocation)
将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。这个过程是由master节点完成的。
1.9 数据格式
Elasticsearch是面向文档型数据库,一条数据在ElasticSearch中就是一个文档,为了方便理解,可以将 Elasticsearch里存储文档数据和关系型数据库MySQL存储数据的概念进行一个类比。
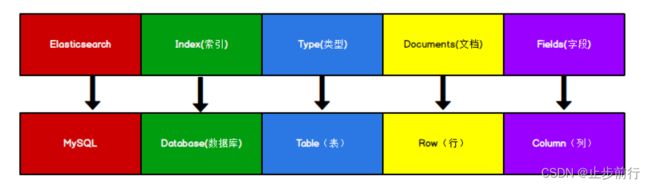
Elasticsearch里的 Index可以看做一个库,而Types相当于表, Documents则相当于表的行。这里Types的概念已经被逐渐弱化, Elasticsearch 6.X中,一个 index下已经只能包含一个type,Elasticsearch 7.X 中 , Type的概念已经被删除了。
2. HTTP操作
2.1 索引操作
对比关系型数据库,索引就等同于数据库
2.1.1 创建索引
在Postman 中,向 ES服务器发 PUT请求: http://127.0.0.1:9200/scorpios

{
"acknowledged": true, # 响应结果
"shards_acknowledged": true, # 分片结果
"index": "scorpios" # 索引名称
}
注意:创建索引库的分片数默认 1 片,在 7.0.0 之前的 Elasticsearch 版本中,默认 5 片
如果重复添加索引,会返回错误信息,put操作具有幂等性,每次操作都必须返回同一结果
2.1.2 查看所有索引
在Postman中,向 ES服务器发 GET请求:http://127.0.0.1:9200/_cat/indices?v
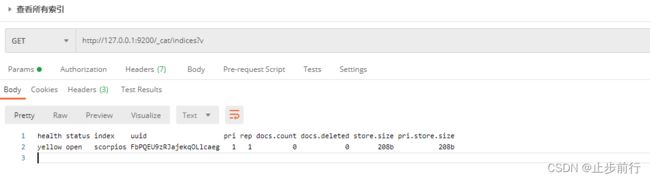
这里请求路径中的_cat表示查看的意思, indices表示索引,所以整体含义就是查看当前ES服务器中的所有索引,就好像MySQL中的show tables的感觉
| 表头 | 含义 |
|---|---|
| health | 当前服务器健康状态:green(集群完整)、yellow(单点正常、集群不完整)、red(单点不正常) |
| status | 索引打开、关闭状态 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
2.1.3 查看单个索引
在Postman中,向 ES服务器发 GET请求:http://127.0.0.1:9200/scorpios
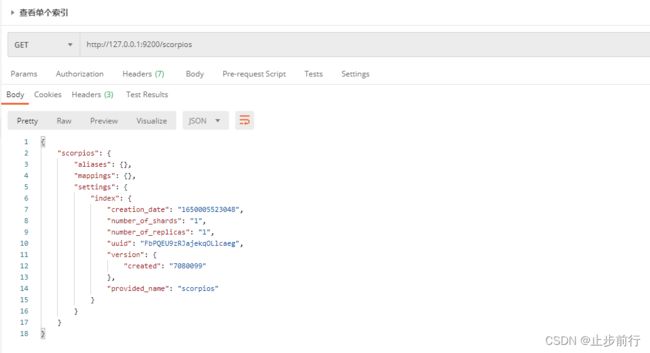
{
"scorpios": { # 索引名
"aliases": {}, # 别名
"mappings": {}, #映射
"settings": { #设置
"index": { #设置-索引
"creation_date": "1650005523048", # 设置-索引-创建时间
"number_of_shards": "1", # 设置-索引-主分片数量
"number_of_replicas": "1", # 设置-索引-副分片数量
"uuid": "FbPQEU9zRJajekqOLlcaeg", # 设置-索引-唯一标识
"version": { # 设置-索引-版本
"created": "7080099"
},
"provided_name": "scorpios" # 设置-索引-名称
}
}
}
}
查看索引向ES服务器发送的请求路径和创建索引是一致的,但是 HTTP方法不一致。
2.1.4 删除索引
在Postman中,向 ES 服务器发 DELETE请求:http://127.0.0.1:9200/scorpios
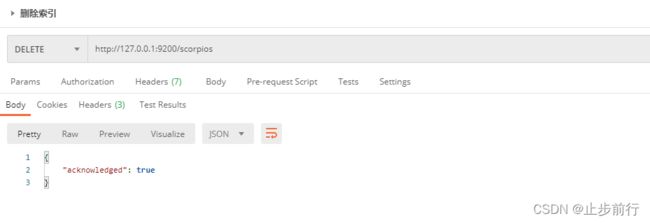
再次访问索引时,服务器返回响应:索引不存在
2.2 文档操作
对比关系型数据库,文档就等同于行
2.2.1 创建文档
索引已经创建好了,接下来创建文档,并添加数据。这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON格式。
在Postman中,向 ES服务器发 POST请求:http://127.0.0.1:9200/scorpios/_doc
此处如果索引没有创建,直接创建文档,也是可以的,会默认把索引也创建好
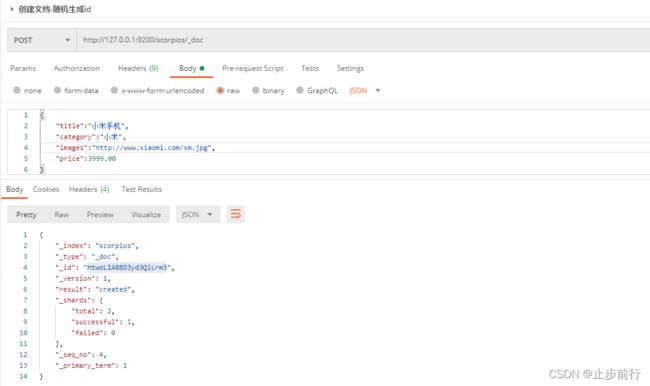
{
"_index": "scorpios", # 索引
"_type": "_doc", # 类型-文档
"_id": "htwoLIABBD3yd3QiLrm3", # 唯一标识,可以类比为mysql中的主键,随机生成
"_version": 1, # 版本
"result": "created", # 结果,created表示创建成功
"_shards": { # 分片
"total": 2, # 分片-总数
"successful": 1, # 分片-成功
"failed": 0 # 分片-失败
},
"_seq_no": 4,
"_primary_term": 1
}
此处发送请求的方式必须为POST,不能是 PUT,否则会发生错误。
此处需要注意:如果增加数据时明确数据主键,那么请求方式也可以为PUT。
只需要记住put操作具有幂等性。
上面的数据创建后,由于没有指定数据唯一性标识(ID),默认情况下 ES服务器会随机生成一个 。如果想要自定义唯一性标识,需要在创建时指定:http://127.0.0.1:9200/scorpios/_doc/1
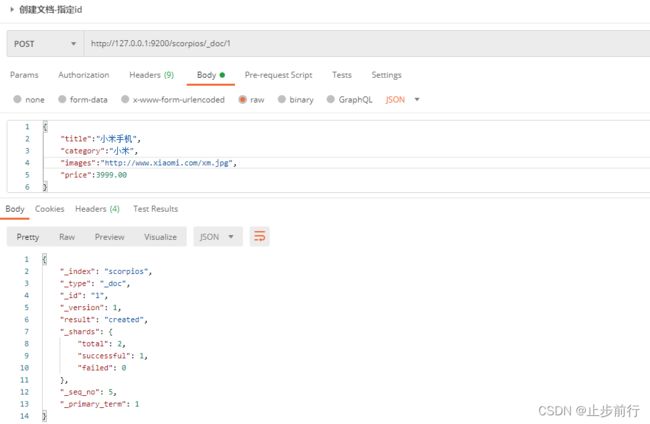
2.2.2 查看文档
查看文档时,需要指明文档的唯一性标识,类似于MySQL中数据的主键查询
在Postman中,向 ES服务器发 GET请求:http://127.0.0.1:9200/scorpios/_doc/1
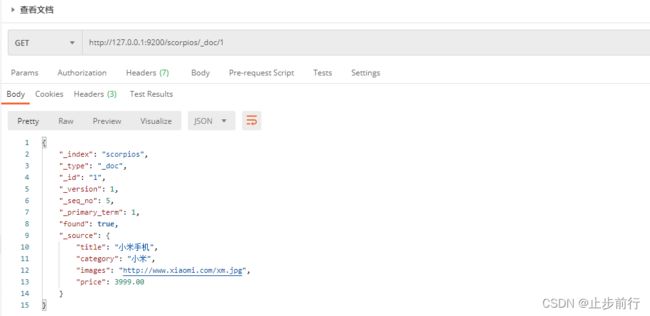
{
"_index": "scorpios", # 索引
"_type": "_doc", # 文档类型
"_id": "1",
"_version": 1,
"_seq_no": 5,
"_primary_term": 1,
"found": true, # 查询结果,true表示查找到,false表示未查找到
"_source": { # 文档源信息
"title": "小米手机",
"category": "小米",
"images": "http://www.xiaomi.com/xm.jpg",
"price": 3999.00
}
}
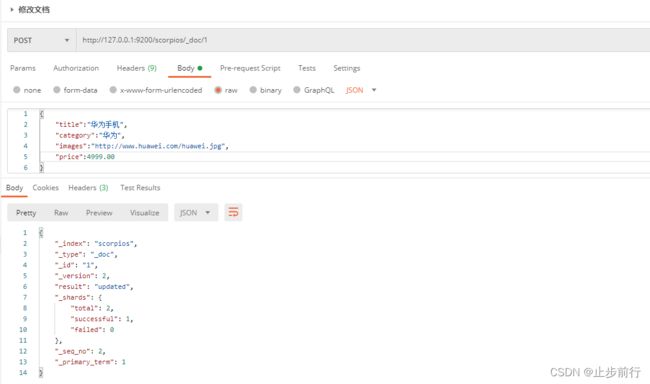
2.2.3 修改文档
和新增文档一样,输入相同的URL 地址请求,如果请求体变化,会将原有的数据内容覆盖
在Postman中,向 ES服 务器发 POST请求:http://127.0.0.1:9200/scorpios/_doc/1
{
"_index": "scorpios",
"_type": "_doc",
"_id": "1",
"_version": 2, # 版本
"result": "updated", # 结果 updated表示数据被更新
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
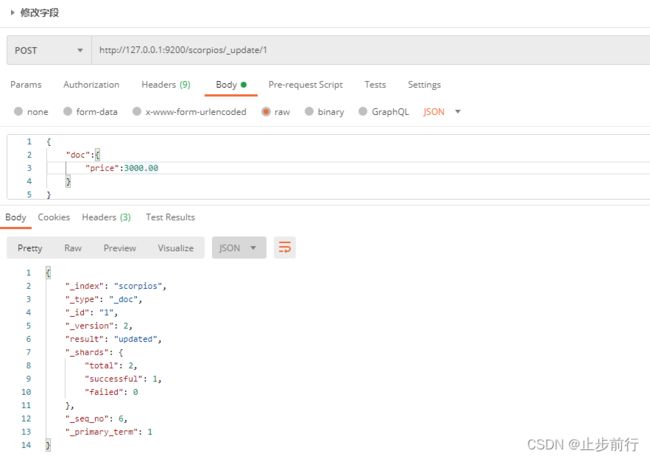
2.2.4 修改字段
修改数据时,也可以只修改某一给条数据的局部信息
在Postman中,向 ES服务器发 POST请求:http://127.0.0.1:9200/scorpios/_update/1
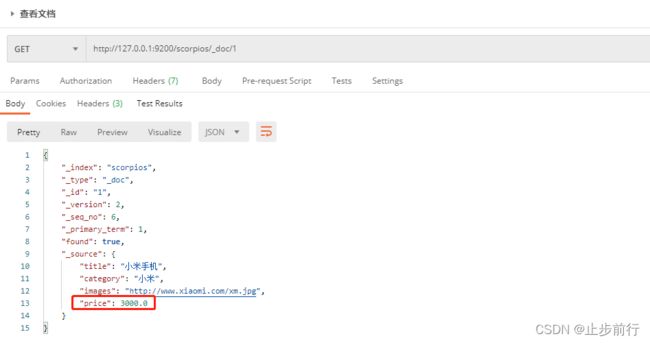
然后再根据唯一性标识,查询文档数据,文档数据已经更新
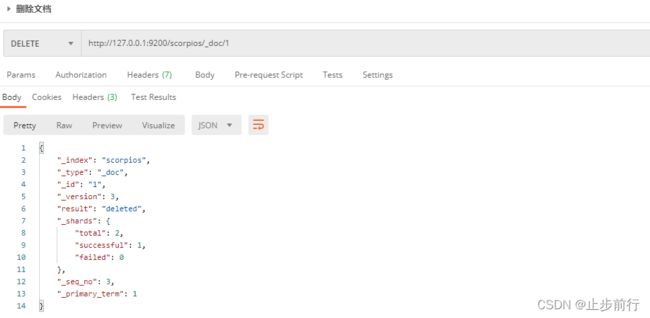
2.2.5 删除文档
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
在Postman中,向 ES服务器发 DELETE请求:http://127.0.0.1:9200/scorpios/_doc/1
{
"_index": "scorpios",
"_type": "_doc",
"_id": "1",
"_version": 3, # 版本,对数据的操作,都会更新版本
"result": "deleted", # 结果,deleted表示数据被标记为删除
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}
2.2.6 条件删除文档
一般删除数据都是根据文档的唯一性标识进行删除,实际操作时,也可以根据条件对多条数据进行删除,首先分别增加多条数据。
向ES服务器发 POST请求:http://127.0.0.1:9200/scorpios/_delete_by_query
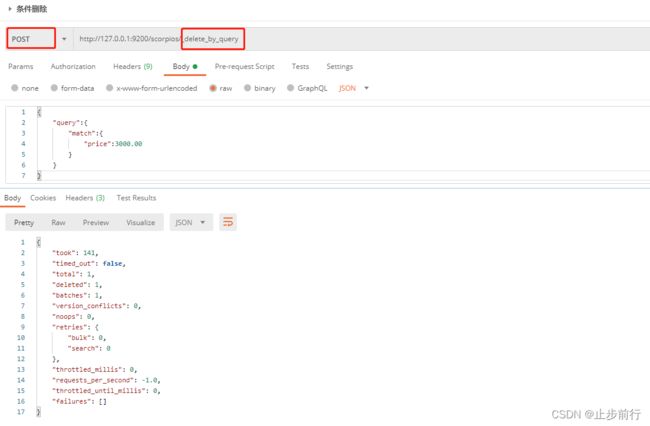
{
"took": 141, # 耗时
"timed_out": false, # 是否超时
"total": 1, # 总数
"deleted": 1, # 删除数量
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1.0,
"throttled_until_millis": 0,
"failures": []
}
注意:条件删除是发Post请求
2.2.7 查询文档中所有数据
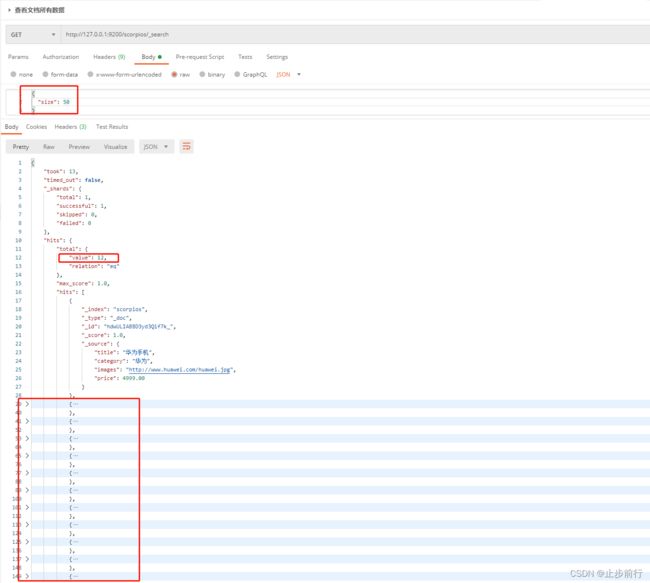
在Postman中,向 ES服务器发 GET请求:http://127.0.0.1:9200/scorpios/_search。此方式只能查询出10条数据
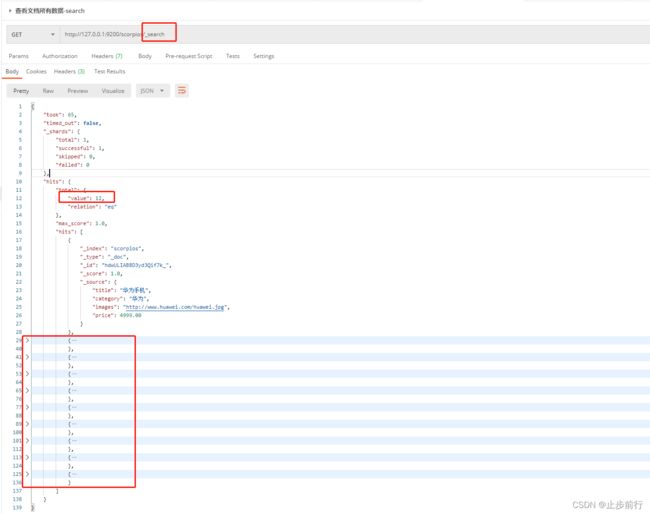
可以在上面请求中加入查询参数来查询所有数据。