orchestrator常见问题汇总
目录
1 OC无法自动进行主库故障恢复
现象
问题原因
2 如何确定实例的数据中心问题描述:
原因分析:
解决:
3 切换之后变为两个集群
问题描述:
原因分析:
如何解决:
4 oc web控制台进行认证登录
原因
解决
5 显示IP地址
6 钩子脚本执行报错
7 自动发现域名和IP的实例
8 域名如何查看
9 常见页面警告或错误
① ErrantGTIDStructureWarning
② 短时间多次切换会被阻塞
A DeadMaster on 10.79.23.45:5306 is blocked due to a previous recovery
1 OC无法自动进行主库故障恢复
现象
主库宕机后,oc没有自动进行恢复
问题原因
1 默认配置文件中设置了匹配规则 ,只有被匹配的主机名才能进行故障恢复,所以该参数需要设置为 "*"
"RecoverMasterClusterFilters": [
".*"
],
"RecoverIntermediateMasterClusterFilters": [
".*"
],
2 另外确保web 控制台的全局恢复是打开的
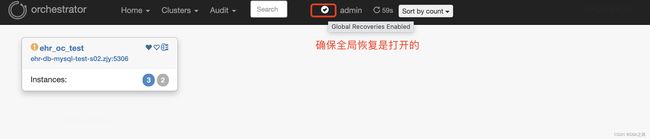
3 另外配置文件中还有许多发现,恢复的忽略规则(Ignore) 这些参数也是需要注意的
2 如何确定实例的数据中心问题描述:
页面不显示实例的DataCenter名称
原因分析:
select @@hostname; 可以查询出实例所在服务器的主机名
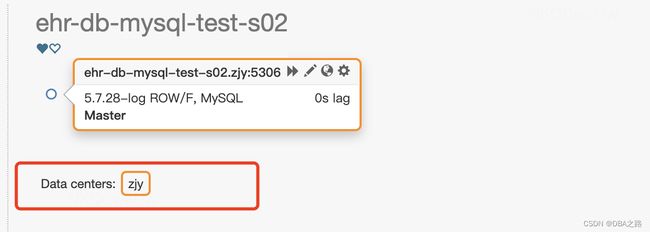
ehr-db-mysql-test-s02.zjy 主机名的命名规则:是以数据中心为后缀
所以数据中心的查询SQL为: select SUBSTRING_INDEX(@@hostname,'.', -1);
解决:
增加参数参数 DetectDataCenterQuery
"DetectDataCenterQuery" : "SELECT SUBSTRING_INDEX(@@hostname, '.', -1)",
重启oc 后显示数据中心
3 切换之后变为两个集群
问题描述:
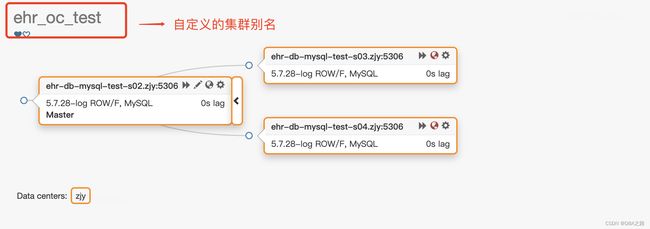
在S02故障后 选本属于同一集群的实例变为两个集群。

原因分析:
这个问题是因为取集群名称的规则导致。
默认的取集群名称的规则为参数决定 ,默认为取主实例 主机名 ,然后按分隔符"."之前的第一段字符为集群别名,这样在集群主库宕机后,新提升的从库的服务器名称为了新的集群名,宕机的主库成为单独的一个集群。
这样在修复集群拓扑时就很不方便,无法通过拖拽的方式将宕机实例重新加入集群。
"DetectClusterAliasQuery": "SELECT SUBSTRING_INDEX(@@hostname, '.', 1)",
如何解决:
在被管理目标集群 主实例中创建库表,将所需的元数据信息写入实例中。
|
|
然后修改参数
"DetectClusterAliasQuery": "SELECT cluster_name FROM orchestrator.cluster",
修改之后集群别名还是没有改变 查看日志发现以下报错 : 账号缺少别要的权限
2023-09-04 16:42:11 ERROR ReadTopologyInstance(ehr-db-mysql-test-s02.zjy:5306) DetectClusterAliasQuery: Error 1142: SELECT command denied to user 'orchestrator'@'ehr-db-mysql-test-s02.zjy' for table 'cluster'
2023-09-04 16:42:23 ERROR ReadTopologyInstance(ehr-db-mysql-test-s03.zjy:5306) DetectClusterAliasQuery: Error 1142: SELECT command denied to user 'orchestrator'@'ehr-db-mysql-test-s02.zjy.diditaxi.com' for table 'cluster'
账号添加权限
grant select on orchestrator.* to 'orchestrator'@'10.79.23.%';
这样就可以显示自定义的集群别名了。
4 oc web控制台进行认证登录
原因
不设置账号密码 非常不安全,其他内网人员得到连接后也可以随意修改集群拓扑,风险非常高。
解决
进行认证登录
修改以下参数
"AuthenticationMethod": "basic",
"HTTPAuthUser": "admin",
"HTTPAuthPassword": "dba@admin",
这样再访问控制台的时候就需要账号密码 比较安全
5 显示IP地址
由于LVS的后端的RS为IP地址,如果直接显示主机名,LVS的接口方法将无法工作。
被发现的从库也是显示主机名称
解决方式一:
修改参数
"HostnameResolveMethod": "default",
"MySQLHostnameResolveMethod": "@@hostname",
HostnameResolveMethod 默认值为default ,不会显示IP ,修改为none
MySQLHostnameResolveMethod 默认值
解决方式二
设置MySQL参数
skip_name_resolve=on
注意 : 这两种方式都需要重启。
6 钩子脚本执行报错
只传入脚本中用到的参数,不要多传入。多传入参数脚本会报错。
7 自动发现域名和IP的实例
8 域名如何查看

9 常见页面警告或错误
① ErrantGTIDStructureWarning
原因
从库的GTID集合比主库的多
处理
② 短时间多次切换会被阻塞
A DeadMaster on 10.79.23.45:5306 is blocked due to a previous recovery
RecoveryPeriodBlockMinutes int // (supported for backwards compatibility but please use newer `RecoveryPeriodBlockSeconds` instead) The time for which an instance's recovery is kept "active", so as to avoid concurrent recoveries on same instance as well as flapping
RecoveryPeriodBlockSeconds int // (overrides `RecoveryPeriodBlockMinutes`) The time for which an instance's recovery is kept "active", so as to avoid concurrent recoveries on same instance as well as flapping