机器学习+模式识别学习总结(四)——决策树
一、定义及介绍
1、分类决策树模型是一种描述对实例进行分类的树形结构,由结点+有向边组成。结点分为内部结点(表示一个特征/属性)和叶结点(表示一个类)。【树的总结构包括:根结点、非叶子结点、叶子结点、分支】
2、if-then规则:从根结点到叶结点的每一条路径构建一条规则,路径上内部结点的特征对应规则的条件,叶结点的类对应着规则的结论。if-then规则集合的重要性质:互斥且完备。这个规则的意识也就是从根结点出发,最终都有且只有一条路径到达某一个具体的叶结点,并且不会出现实例无法分类的情况。
3、决策树学习目标:根据训练数据集构建决策树模型,使决策树模型能正确分类,且有较好的泛化能力。
4、决策树学习本质:从训练数据集中归纳分类规则,找到特征与标签的之间的分类规则。
5、决策树的损失函数:通常是正则化的极大似然函数。一般采用启发式方法,即局部最优,选择当前条件下最优的特征作为划分规则。
6、不同阶段的决策树:
(1)训练阶段:用给定的数据集构建决策树。
(2)测试阶段:从根节点开始,按决策树的分类属性逐层往下划分,直到叶节点,最后得到分类结果。
7、概念介绍:
(1)熵:是随机变量不确定性的度量。熵越大,不确定性越大。随机变量的熵:
![]() ,
,
由公式可知,随机变量 的熵只与其概率有关,即只取决于其分布,与其取值无关。
的熵只与其概率有关,即只取决于其分布,与其取值无关。
(2)条件熵:已知随机变量的条件下,随机变量 不确定性的度量。公式表示为:
不确定性的度量。公式表示为:
![]() 。
。
当熵和条件熵中的概率由数据估计得到时,对应得到经验熵/条件熵。
(3)信息增益:得知特征的信息而使类的信息不确定性减少的程度。公式表示为:
![]() ,
,
理解为:由于特征 的选取而使得对训练数据集
的选取而使得对训练数据集 进行分类的不确定性减少的程度。信息增益也就是熵减少的程度。
进行分类的不确定性减少的程度。信息增益也就是熵减少的程度。
二、构建决策树(构建决策树是递归选择最优特征的过程,也是对特征空间进行划分的过程。)
决策树的学习算法包括:特征选择、决策树生成、决策树剪枝。下面就这三个部分进行叙述:
(一)特征选择和决策树生成:决定用哪个特征来划分特征空间,并基于某个特征选择算法生成决策树。不同的决策树生成算法有不同的特征选择规则,常用准则为信息增益/信息增益比。
1、ID3算法:以信息增益准则选择特征。原则就是选取某个特征后,使得剩下的数据集的熵减小的程度最大/熵减少得最多/剩下的数据集越纯,越好分。
Step A: 计算D的经验熵,![]()
Step B: 计算特征A对D的经验条件熵,
Step C: 用经验熵减去经验条件熵计算信息增益,![]()
2、C4.5算法:以信息增益比准则选择特征。因为以信息增益作为划分训练集的特征的话,存在偏向于选择取值较多的特征的问题(因为按信息增益原则来说,这个取值较多的特征增添了数据集的“混乱程度”,选择这个特征可以降低数据集的混乱程度,使得信息增益最大,剩下的待分类数据集越纯。
信息增益比:![]() ,其中
,其中![]() ,
, 为特征的取值个数。
为特征的取值个数。
3、CART决策树:以基尼系数准则选择特征,当用于回归时用平方误差最小准则。假设决策树是二叉树,内部结点特征取值为“是”和“否”,则基尼系数:
![]() ,
,
其中基尼指数,
![]()
直观来看,Gini(p)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率。因此,Gini(p)越小,则数据集D的纯度越高。
(二)决策树剪枝
1、剪枝:若决策树在学习时过多地考虑如何提高对训练数据的正确分类,会构建出过于复杂的决策从而导致过拟合。这时就要对该决策树进行剪枝:从已生成的决策树上裁掉一些子树或结点,并将其根结点或父结点作为新的叶结点。剪枝的目的不是为了最小化损失函数,剪枝的目的是为了达到一个更好的泛化能力。
2、损失函数:剪枝往往通过极小化决策树整体的损失函数实现的。决策树的损失函数为:
![]() ,
,
其中![]() 表示叶结点
表示叶结点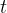 含有的样本个数,
含有的样本个数,![]() 表示叶结点个数,
表示叶结点个数,
其中经验熵:
![]() ,
,
记![]() ,
,
则有:
![]() ,
,
关于公式的理解,我们知道经验熵![]() 表示该叶结点的混乱程度,考虑到整棵树的所有叶结点,以及每个叶结点中的样例个数不同,可以采用
表示该叶结点的混乱程度,考虑到整棵树的所有叶结点,以及每个叶结点中的样例个数不同,可以采用![]() 衡量模型对训练集的整体分类误差。但是若只用
衡量模型对训练集的整体分类误差。但是若只用![]() 来作为优化目标函数,模型就会对每一个分支尽可能划分到最细,来使得每一个叶结点的经验熵都为0,以此使得
来作为优化目标函数,模型就会对每一个分支尽可能划分到最细,来使得每一个叶结点的经验熵都为0,以此使得![]() 为0,这样最终导致模型的过拟合。思考:如果模型分到最细,那么模型会很复杂,一定会包含很多分支很多子树,如果能够给损失函数加上一个与模型复杂度有关的惩罚项,把模型的复杂度考虑进去,是不是就可以解决这个过拟合问题了呢?而对于一棵树来说,叶结点数越多就越复杂,因此可以用叶结点数衡量一棵树的复杂度,再通过
为0,这样最终导致模型的过拟合。思考:如果模型分到最细,那么模型会很复杂,一定会包含很多分支很多子树,如果能够给损失函数加上一个与模型复杂度有关的惩罚项,把模型的复杂度考虑进去,是不是就可以解决这个过拟合问题了呢?而对于一棵树来说,叶结点数越多就越复杂,因此可以用叶结点数衡量一棵树的复杂度,再通过 “惩罚系数”来决定复杂度和整体误差之间的影响程度,就得到了
“惩罚系数”来决定复杂度和整体误差之间的影响程度,就得到了![]() 。可知,较大的会对树的叶结点树进行较大程度的“惩罚”,从而得到较简单的模型, 相反,较小的会得到较复杂的模型。
。可知,较大的会对树的叶结点树进行较大程度的“惩罚”,从而得到较简单的模型, 相反,较小的会得到较复杂的模型。
3、两种剪枝策略
(1)预剪枝:
在构造决策树的过程中,先对每个结点在划分前进行估计,若果当前结点的划分不能带来决策树模型泛华性能的提升,则不对当前结点进行划分并且将当前结点标记为叶结点。
(2)后剪枝:
先从训练集生成一颗完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来泛化性能提升,则将该子树替换为叶结点。
两种策略的对比:
①后剪枝决策树通常比预剪枝决策树保留了更多的分支;
②后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树;
③后剪枝决策树训练时间开销比未剪枝决策树和预剪枝决策树都要大的多。
参考:
https://blog.csdn.net/am290333566/article/details/81187562
https://blog.csdn.net/u012328159/article/details/79285214