【学习笔记】C/C++教程 - 面向对象的程序设计语言
1、程序结构
1.1 编写代码
// 预处理命令 #include 引入头文件 stdio.h
#include 1.2 编译执行
关联知识点:30、命令行参数
- 打开文本编辑器,编写程序代码,保存文件为
hello.c - 打开命令提示符,进入文件目录,键入以下命令并回车:
gcc hello.c
- 如果代码中没有错误,命令提示符会跳到下一行,并生成
a.out可执行文件,键入以下命令并回车:
./a.out
请确保您的路径中已包含gcc编译器,并确保在包含源文件hello.c的目录中运行它
- 如果是多个源码文件,例如
test1.c、test2.c,编译方法如下:
gcc test1.c test2.c -o main.out
./main.out
2、基本语法
- 令牌(Token):C 程序由各种令牌组成,包括关键字、标识符、常量、字符串值、符号等。
- 分号:语句结束符,每个语句必须以
;结束。 - 注释:
//单行注释
/*
多行
注释
*/
- 标识符:标识符以
A-Z或a-z或_开始,以字母/下划线/数字结束,不允许出现标点符号,大小写敏感。 - 关键字:不能作为常量名、变量名或其他标识符名称
| 关键字 | 说明 |
|---|---|
| auto | 声明自动变量 |
| break | 跳出当前循环 |
| case | 开关语句分支 |
| char | 声明字符型变量或函数返回值类型 |
| const | 定义常量(变量被 const 修饰后,它的值不能再被改变) |
| continue | 结束当前循环,开始下一轮循环 |
| default | 开关语句中的"其它"分支 |
| do | 循环语句的循环体 |
| double | 声明双精度浮点型变量或函数返回值类型 |
| else | 条件语句否定分支(与 if 连用) |
| enum | 声明枚举类型 |
| extern | 声明变量或函数是在其它文件或本文件的其他位置定义 |
| float | 声明浮点型变量或函数返回值类型 |
| for | 一种循环语句 |
| goto | 无条件跳转语句 |
| if | 条件语句 |
| int | 声明整型变量或函数 |
| long | 声明长整型变量或函数返回值类型 |
| register | 声明寄存器变量 |
| return | 子程序返回语句(可以带参数,也可不带参数) |
| short | 声明短整型变量或函数 |
| signed | 声明有符号类型变量或函数 |
| sizeof | 计算数据类型或变量长度(即所占字节数) |
| static | 声明静态变量 |
| struct | 声明结构体类型 |
| switch | 用于开关语句 |
| typedef | 用以给数据类型取别名 |
| unsigned | 声明无符号类型变量或函数 |
| union | 声明共用体类型 |
| void | 声明函数无返回值或无参数,声明无类型指针 |
| volatile | 说明变量在程序执行中可被隐含地改变 |
| while | 循环语句的循环条件 |
| C99 新增关键字: | |
| _Bool | ? |
| _Complex | ? |
| _Imaginary | ? |
| inline | ? |
| restrict | ? |
| C11 新增关键字: | |
| _Alignas | ? |
| _Alignof | ? |
| _Atomic | ? |
| _Generic | ? |
| _Noreturn | ? |
| _Static_assert | ? |
| _Thread_local | ? |
3、数据类型
3.1 数据类型
3.1.1 基本数据类型
关联知识点:21、输入 & 输出
| 整数类型 | 关键字 | 存储大小 | 值范围 |
|---|---|---|---|
| 字符型 | char | 1 字节 | 128 ~ 127 0 ~ 255 |
| 短整型 | short | 2 字节 | -32,768 ~ 32,767 |
| 整型 | int | 2 字节 4 字节 |
-32,768 ~ 32,767 -2,147,483,648 ~ 2,147,483,647 |
| 长整型 | long | 4 字节 | -2,147,483,648 ~ 2,147,483,647 |
| 长长整型 | long long | ? | ? |
| 整型修饰 | 关键字 | 说明 | 储值范围 |
|---|---|---|---|
| 无符号 | unsigned | char默认无符号 加在类型前声明无符号 |
有符号类型的2倍 |
| 有符号 | signed | float、double总是有符号 默认声明的整型变量有符号 |
| 浮点类型 | 关键字 | 存储大小 | 值范围 | 精度 |
|---|---|---|---|---|
| 单精度浮点型 | float | 4 字节 | 1.2E-38 ~ 3.4E+38 | 6 位 |
| 双精度浮点型 | double | 8 字节 | 2.3E-308 ~ 1.7E+308 | 15 位 |
| 长精度浮点型 | long double | 16 字节 | 3.4E-4932 ~ 1.1E+4932 | 19 位 |
#include 3.1.2 void 类型
表示没有值的数据类型,通常用于:
- 函数返回为空:不返回值的函数的返回类型为空,例如
void exit (int status); - 函数参数为空:不带参数的函数可以接受一个 void,例如
int rand(void); - 指向 void 的指针:可以转换为任何数据类型,例如
void *malloc( size_t size );。
3.2 类型转换
关联知识点:25.1 显式转换
- 隐式类型转换:在表达式中自动发生的,无需进行任何明确的指令或函数调用;通常是将一种较小的类型自动转换为较大的类型;可能会导致数据精度丢失或数据截断。
- 显式类型转换:需要使用强制类型转换运算符,将一个数据类型的值强制转换为另一种数据类型的值;在必要时对数据类型进行更精确的控制;可能会导致数据丢失或截断。
int i = 10;
float f = 3.14;
double d = i + f; // 隐式将int类型转换为double类型
double d = 3.14159;
int i = (int)d; // 显式将double类型转换为int类型
3、数据类型(C++)
3.1 数据类型
| 类型 | 关键字 | 占用内存 | 值范围 |
|---|---|---|---|
| 布尔型 | bool | 1 个字节 | 0 或 1 |
| 字符型 | char | 1 个字节 | -128 到 127 或者 0 到 255 |
| unsigned char | 1 个字节 | 0 到 255 | |
| signed char | 1 个字节 | -128 到 127 | |
| 整型 | int | 4 个字节 | -2147483648 到 2147483647 |
| unsigned int | 4 个字节 | 0 到 4294967295 | |
| signed int | 4 个字节 | -2147483648 到 2147483647 | |
| short int | 2 个字节 | -32768 到 32767 | |
| unsigned short int | 2 个字节 | 0 到 65,535 | |
| signed short int | 2 个字节 | -32768 到 32767 | |
| long int | 8 个字节 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 | |
| signed long int | 8 个字节 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 | |
| unsigned long int | 8 个字节 | 0 到 18,446,744,073,709,551,615 | |
| 浮点型 | float | 4 个字节 | 精度型占4个字节(32位)内存空间,+/- 3.4e +/- 38 (~7 个数字) |
| 双浮点型 | double | 8 个字节 | 双精度型占8 个字节(64位)内存空间,+/- 1.7e +/- 308 (~15 个数字) |
| long double | 16 个字节 | 长双精度型 16 个字节(128位)内存空间,可提供18-19位有效数字。 | |
| 宽字符型 | wchar_t | 2 或 4 个字节 | 1 个宽字符 |
| 无类型 | void |
#include::max)() << "\t最小值:" << (numeric_limits::min)() << endl;
cout << "type: \t\t" << "************size**************"<< endl;
return 0;
}
3.2 typedef 声明
typedef type newname; // 使用 typedef 为一个已有的类型取一个新的名字
typedef int feet;
feet distance;
3.3 枚举类型
C++中的一种派生数据类型,它是由用户定义的若干枚举常量的集合;如果一个变量只有几种可能的值,可以定义为枚举类型。
enum 枚举名 {
标识符[=整型常数],
标识符[=整型常数],
...
标识符[=整型常数]
} 枚举变量;
enum color { red, green, blue } c; // 0, 1, 2
c = blue;
enum color { red, green=5, blue }; // 0, 5, 6
// 第一个元素值默认为0
// 若指定某个元素的值,则后续元素的值依次+1,之前的元素不受影响
3.4 类型转换
类型转换是将一个数据类型的值转换为另一种数据类型的值。
3.4.1 静态转换(Static Cast)
强制转换,通常用于比较类型相似的对象之间的转换。
静态转换不进行任何运行时类型检查,因此可能会导致运行时错误
int i = 10;
float f = static_cast<float>(i); // 静态将int类型转换为float类型
3.4.2 动态转换(Dynamic Cast)
将一个基类指针或引用转换为派生类指针或引用。
动态转换在运行时进行类型检查,如果不能进行转换则返回空指针或引发异常
class Base {};
class Derived : public Base {};
Base* ptr_base = new Derived;
Derived* ptr_derived = dynamic_cast<Derived*>(ptr_base); // 将基类指针转换为派生类指针
3.4.3 常量转换(Const Cast)
将 const 类型的对象转换为非 const 类型的对象,且只能用于 const 属性,不能改变对象的类型。
const int i = 10;
int& r = const_cast<int&>(i); // 常量转换,将const int转换为int
3.4.4 重新解释转换(Reinterpret Cast)
将一个数据类型的值重新解释为另一个数据类型的值,通常用于在不同的数据类型之间进行转换。
重新解释转换不进行任何类型检查,因此可能会导致未定义的行为
int i = 10;
float f = reinterpret_cast<float&>(i); // 重新解释将int类型转换为float类型
4、变量
4.1 变量定义
变量的名称必须以A-Z或a-z或_开头,大小写敏感。
| 基本变量类型 | 描述 |
|---|---|
| char | 通常是一个字节(八位), 这是一个整数类型 |
| int | 整型,4 个字节,取值范围 -2147483648 到 2147483647 |
| float | 单精度浮点值,格式:1位符号,8位指数,23位小数 |
| double | 双精度浮点值,格式:1位符号,11位指数,52位小数 |
| void | 表示类型的缺失 |
//定义变量
int i, j, k;
char c, ch;
float f, salary;
double d;
//定义变量并初始化值
int d = 3, f = 5;
byte z = 22;
char x = 'x';
//带有静态存储持续时间的变量会被隐式初始化为 NULL
4.2 变量声明
- 需要建立存储空间的:在声明的时候就已经建立了存储空间
int i; //声明,也是定义
- 不需要建立存储空间的:使用
extern关键字声明变量名而不定义它,其中变量可以在别的文件中定义
extern int i; //声明,不是定义
除非有extern关键字,否则都是变量的定义
//变量在头部就已经被声明,但是定义与初始化在主函数内
#include 4.3 左值和右值
- 左值(lvalue):指向内存位置的表达式,可以出现在赋值号的左边或右边。
- 右值(rvalue):存储在内存中某些地址的数值,不能对其进行赋值,只能出现在赋值号的右边。
变量是左值,因此可以出现在赋值号的左边。
数值型的字面值是右值,因此不能被赋值,不能出现在赋值号的左边。
5、常量
5.1 常量类型
5.1.1 整数常量
十进制、八进制或十六进制的常量。
| 前缀基数 | 表示 | 后缀(不可重复) | 实例 |
|---|---|---|---|
| 0 | 八进制 | 八进制数字 U、L 大小写任意组合 |
0213 |
| 十进制 | 十进制数字 U、L 大小写任意组合 |
85 30ul |
|
| 0x 0X |
十六进制 | 十六进制数字 U、L 大小写任意组合 |
0xFeeL 0x4b |
// 整数常量可以带有一个后缀表示数据类型
int myInt = 10;
long myLong = 100000L;
unsigned int myUnsignedInt = 10U;
5.1.2 浮点常量
由整数部分、小数点、小数部分和指数部分组成。
| 格式 | 要求 | 实例 |
|---|---|---|
| 小数形式 | 整数+小数 | 3.14159 |
| 指数形式 | 小数点+指数 带符号的指数用 e 或 E 引入 |
314159E-5L |
// 浮点数常量可以带有一个后缀表示数据类型
float myFloat = 3.14f;
double myDouble = 3.14159;
5.1.3 字符常量
一个普通的字符、转义序列或通用的字符,括在单引号’…'中。
| 转义序列 | 含义 |
|---|---|
| \\ | \ 字符 |
| \' | ' 字符 |
| \" | " 字符 |
| \? | ? 字符 |
| \a | 警报铃声 |
| \b | 退格键 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \ooo | 一到三位的八进制数 |
| \xhh . . . | 一个或多个数字的十六进制数 |
printf("Hello\tWorld\n\n"); // 输出 Hello World
// 字符常量的 ASCII 值可以通过强制类型转换转换为整数值
char myChar = 'a';
int myAsciiValue = (int) myChar; // 将 myChar 转换为 ASCII 值 97
5.1.4 字符串常量
包含字符和转义序列,括在双引号"…"中,可以分行。 关联知识点:16、字符串
// 字符串常量在内存中以 null 终止符 \0 结尾
char myString[] = "Hello, world!"; // 系统对字符串常量自动添加'\0'
// 定义一个不可更改的全局字符串常量
const char product_name[] = "The program version 3";
// 将字符串常量定义为局部变量(const char * 指针变量)
int main() {
const char *s1 = "world";
printf("Hello %s\n", s1);
return 0;
}
5.2 定义常量
常量又叫做字面量,可以是任何的基本数据类型,常量的值在定义后不能进行修改,可以直接在代码中使用,也可以通过定义常量来使用。
【好习惯】把常量定义为大写字母形式!
5.2.1 #define 预处理指令
关联知识点:23.1 预处理器
#include 5.2.2 const 关键字
#include 6、存储类
定义变量/函数的存储位置、生命周期和作用域,存储类修饰符加在类型之前。
6.1 auto 存储类
所有局部变量默认为 auto ,它们在函数开始时被创建,在函数结束时被销毁。
{
int mount;
auto int month; // auto 只能修饰函数内的局部变量
}
6.2 register 存储类
定义存储在寄存器中的局部变量,变量的最大尺寸等于寄存器的大小,在需要频繁访问的变量上使用 register 可以提高程序的运行速度,但是它不能直接取地址,也不能应用一元的 ‘&’ 运算符。
{
register int miles;
}
// register 变量不一定存储在寄存器中,取决于硬件和实现的限制
6.3 static 存储类
| 修饰 | 说明 |
|---|---|
| 局部变量 | 在程序的生命周期内保持局部变量,可跨函数调用 变量值只初始化一次,之后调用不会重置,而是累计运行 |
| 全局变量 | 限制作用域在声明它的文件内,可以被文件内任何函数调用 |
#include 6.4 extern 存储类
定义在其他文件中声明的全局变量或函数,不会为变量分配任何存储空间,仅提供一个全局变量的引用,通常用于两个或多个文件共享相同的全局变量或函数。
// 第一个文件 main.c
#include // 第二个文件 support.c
#include 7、运算符
7.1 运算符类型
7.1.1 算术运算符
| 运算符 | 描述 | 设A=10、B=20 |
|---|---|---|
| + | 把两个操作数相加 | A + B 将得到 30 |
| - | 从第一个操作数中减去第二个操作数 | A - B 将得到 -10 |
| * | 把两个操作数相乘 | A * B 将得到 200 |
| / | 分子除以分母 | B / A 将得到 2 |
| % | 取模运算符,整除后的余数 | B % A 将得到 0 |
| ++ | 自增运算符,整数值增加 1 | A++ 将得到 11 |
| -- | 自减运算符,整数值减少 1 | A-- 将得到 9 |
int c, a;
a = 10;
c = a++; // 先赋值c=a=10,后运算a=a++=11
a = 10;
c = a--; // 先赋值c=a=10,后运算a=a--=9
a = 10;
c = ++a; // 先运算a=a++=11,后赋值c=a=11
a = 10;
c = --a; // 先运算a=a--=9,后赋值c=a=9
7.1.2 关系运算符
| 运算符 | 描述 | 设A=10、B=20 |
|---|---|---|
| == | 两个操作数的值相等则条件为真 | (A == B) 为假 |
| != | 两个操作数的值不相等则条件为真 | (A != B) 为真 |
| > | 左操作数的值大于右操作数的值则条件为真 | (A > B) 为假 |
| < | 左操作数的值小于右操作数的值则条件为真 | (A < B) 为真 |
| >= | 左操作数的值≥右操作数的值则条件为真 | (A >= B) 为假 |
| <= | 左操作数的值≤右操作数的值则条件为真 | (A <= B) 为真 |
7.1.3 逻辑运算符
| 运算符 | 描述 | 设A=1、B=0 |
|---|---|---|
| && | 逻辑与运算符(两个操作数都非零则条件为真) | (A && B) 为假 |
| || | 逻辑或运算符(两个操作数任意非零则条件为真) | (A || B) 为真 |
| ! | 逻辑非运算符(逆转操作数的真假逻辑状态) | !(A && B) 为真 |
7.1.4 位运算符
| 运算符 | 描述 | 设A=60、B=13,得 |
|---|---|---|
| & | 二进制位"与"运算(仅当1&1=1) 0&0=0; 0&1=0; 1&0=0; 1&1=1; |
A & B == 12 60 → 00111100
13 → 00001101
————————
12 ← 00001100 |
| | | 二进制位"或"运算(仅当0|0=0) 0|0=0; 0|1=1; 1|0=1; 1|1=1; |
A | B == 61 60 → 00111100
13 → 00001101
————————
61 ← 00111101 |
| ^ | 二进制位"异或"运算(相同为0,相异为1) 0^0=0; 0^1=1; 1^0=1; 1^1=0; |
A ^ B == 49 60 → 00111100
13 → 00001101
————————
49 ← 00110001 |
| ~ | 二进制位"取反"运算(二进制数的补码形式) ~A=-(A+1) |
~A == -61 |
| << | 二进制“左移”运算(按位左移,右边补0) | A << 2 == 240 |
| >> | 二进制“右移”运算(按位右移,正数左补0、负数左补1) | A >> 2 == 15 |
※进制转换的方法:
- 十进制→二进制:短除法,将所有0、1从上到下连起来从右至左摆放,不够八位数的左边补0
2 | 60 ‾ \underline{\text{60}} 60 2 | 13 ‾ \underline{\text{13}} 13
2 | 30 ‾ \underline{\text{30}} 30 ······ 0 2 | 6 ‾ \underline{\text{6}} 6 ······ 1
2 | 15 ‾ \underline{\text{15}} 15 ······ 0 2 | 3 ‾ \underline{\text{3}} 3 ······ 0
2 | 7 ‾ \underline{\text{7}} 7 ······ 1 1 ······ 1
2 | 3 ‾ \underline{\text{3}} 3 ······ 1
1 ······ 1
60 → 00111100 13 → 00001101
- 二进制→十进制:从右至左每个数字依次乘以 2 n − 1 2^{n-1} 2n−1,将乘积相加
0 0 0 0 1 1 0 1
x 2 7 2^7 27 x 2 6 2^6 26 x 2 5 2^5 25 x 2 4 2^4 24 x 2 3 2^3 23 x 2 2 2^2 22 x 2 1 2^1 21 x 2 0 2^0 20
—————————————————
0 + 0 + 0 + 0 + 8 + 4 + 0 + 1 = 13
- 二进制取反:使用补码来表示二进制数,最高位为符号位,0正、1负
① 正数取反(补码=原码)
60 → 00111100 ————→ 11000011 ———→ 10111101 → -61
正数 原码/补码 按位取反 负数 取补码 负数原码
② 负数取反(补码=原码符号位不变+剩余位取反+1)
-60 → 10111100 → 11000100 ————→ 00111011 → 59
负数 原码 补码 按位取反 正数补码/原码
7.1.5 赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | C = A + B |
| += | 加且赋值运算符 | C += A → C = C + A |
| -= | 减且赋值运算符 | C -= A → C = C - A |
| *= | 乘且赋值运算符 | C *= A → C = C * A |
| /= | 除且赋值运算符 | C /= A → C = C / A |
| %= | 求模且赋值运算符 | C %= A → C = C % A |
| <<= | 左移且赋值运算符 | C <<= 2 → C = C << 2 |
| >>= | 右移且赋值运算符 | C >>= 2 → C = C >> 2 |
| &= | 按位与且赋值运算符 | C &= 2 → C = C & 2 |
| ^= | 按位异或且赋值运算符 | C ^= 2 → C = C ^ 2 |
| |= | 按位或且赋值运算符 | C |= 2 → C = C | 2 |
7.1.6 杂项运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| sizeof() | 返回变量的字节大小 | sizeof(a) 将返回 4(a 是整数) |
| & | 返回变量的地址 | &a; 将给出变量的实际地址 |
| * | 指向一个变量 | *a; 将指向一个变量 |
| ? : | 条件表达式 | 如果条件为真 ? 则值为 X : 否则值为 Y |
7.2 运算符优先级
| 优先级 | 类别 | 运算符 |
|---|---|---|
| 1 | 后缀 | () [] -> . ++ – |
| 2 | 一元 | + - ! ~ ++ – (type)* & sizeof |
| 3 | 乘除 | * / % |
| 4 | 加减 | + - |
| 5 | 移位 | << >> |
| 6 | 关系 | < <= > >= |
| 7 | 相等 | == != |
| 8 | 位与 AND | & |
| 9 | 位异或 XOR | ^ |
| 10 | 位或 OR | | |
| 11 | 逻辑与 AND | && |
| 12 | 逻辑或 OR | || |
| 13 | 条件 | ? : |
| 14 | 赋值 | = += -= *= /= %= >>= <<= &= ^= |= |
| 15 | 逗号 | , |
8、判断
0 / null 假定为 false,其他非零和非空的值假定为 true。
| 语句 | 描述 |
|---|---|
if()... |
一个 if 语句由一个布尔表达式后跟一个或多个语句组成 |
if()...else... |
if 语句后可跟一个 else 语句,在布尔表达式为假时执行 |
switch()... |
一个 switch 语句允许测试一个变量等于多个值时的情况 |
... ? ... : ... |
条件运算符 ? :,可以用来替代 if…else 语句 |
9、循环
循环语句允许我们多次执行一个语句或语句组。
- 循环类型
| 循环类型 | 描述 |
|---|---|
while()... |
在执行循环主体之前测试条件,当条件为真时重复语句 |
for()... |
多次执行一个语句序列,简化管理循环变量的代码 |
do...while() |
在循环主体结尾测试条件,当条件为真时重复语句 |
- 循环控制语句
| 控制语句 | 描述 |
|---|---|
break; |
跳过循环或 switch 语句,程序流将继续执行下一条语句 |
continue; |
立刻停止本次循环迭代,重新开始下次循环迭代 |
goto ...; |
将控制转移到被标记的语句(不建议使用) |
- 无限循环:如果条件永远不为假,则循环将变成无限循环
#include 10、函数
C 标准库提供了大量的程序可以调用的内置函数
10.1 函数声明
函数声明告诉编译器函数名称及如何调用函数,函数的实际主体可以单独定义。
return_type function_name( params );
// return_type - 函数返回的值的数据类型(void不返回值)
// function_name - 函数的实际名称,和参数列表一起构成了函数签名
// params - 函数向参数传递的值称为实际参数,包括类型、顺序、数量
int max(int num1, int num2);
int max(int, int); // 参数的类型是必需的,参数的名称可不填
char * strcat(const char *s, int c); // 返回值为指针的函数
// 调用其他文件的函数时,必须在当前文件顶部声明函数
10.2 函数定义
在 C 语言中,函数由一个函数头和一个函数主体组成。
return_type function_name( params )
{
// 函数主体包含一组定义函数执行任务的语句
...body...
}
/* 定义函数返回一个整型值 */
int max(int num1, int num2)
{
int result;
if (num1 > num2) {
result = num1;
} else {
result = num2;
}
return result;
}
10.3 调用传参
函数声明接受参数值的变量称为形式参数,进入函数时创建,退出函数时销毁;调用函数时,传递所需参数,如果函数返回一个值,则可以存储返回值。
实参:可以是常量、变量、表达式、函数等任意类型
形参:只能是变量,且在被定义的函数中必须指定形参的类型
10.3.1 传值调用(默认)
把参数的实际值复制给函数的形式参数,修改函数内的形式参数不会影响实际参数。
#include 10.3.2 引用调用
形参为指向实参地址的指针,对形参的操作即对实参本身的操作,传递指针可以让多个函数访问指针所引用的对象,而不用全局声明。
关联知识点:14.5 传递指针给函数
#include 11、作用域规则
11.1 变量作用域
-
局部变量:在某个函数或块的内部声明的变量,只能被内部的语句使用。
-
全局变量:定义在函数外部(程序顶部),可以被程序内任何函数访问。
-
形式参数:相当于该函数内的局部变量。
#include
- 全局变量保存在内存的全局存储区中,占用静态的存储单元
- 局部变量保存在栈中,只有在函数被调用时才动态地分配存储单元
11.2 初始化变量
定义局部变量时,必须手动对其初始化;定义全局变量时,系统会自动初始化。
【好习惯】正确地初始化变量,否则有时候程序可能会产生意想不到的结果,因为未初始化的变量会导致一些在内存位置中已经可用的垃圾值!
| 数据类型 | 初始化默认值 |
|---|---|
| int | 0 |
| char | ‘\0’ |
| float | 0 |
| double | 0 |
| pointer | NULL |
#include 12、数组
数组用来存储连续内存位置的数据,往往被认为是一系列相同类型的变量。
12.1 一维数组
12.1.1 声明数组
type arrayName[arraySize]; // 一维数组
// type - 任意有效的 C 数据类型
// arraySize - 一个大于零的整数常量
double balance[10];
12.1.2 初始化数组
double balance[5] = {1000.0, 2.0, 3.4, 7.0, 50.0};
// {}中元素数量不能大于[]中指定的长度
double balance[] = {1000.0, 2.0, 3.4, 7.0, 50.0};
// 若不填[]长度,则数组长度为初始化时{}中的元素数量
balance[4] = 50.0; // 为数组中某个元素赋值
12.1.3 访问数组元素
double salary = balance[9]; // 通过索引对数组进行访问
#include 12.2 二维数组
一维数组的列表,一个带有 x 行和 y 列的表格。
type arrayName[x][y];
// type - 任意有效的 C 数据类型
// arrayName - 一个有效的 C 标识符
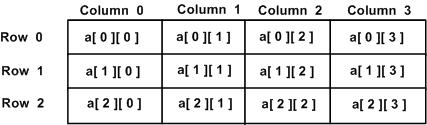
// 数组中的每个元素使用形式为 arr[ i , j ] 的元素名称来标识
int x[3][2];
// 初始化二维数组:为每行指定值
int a[3][3] = {
{0, 1, 2, 3} , /* 初始化索引号为 0 的行 */
{4, 5, 6, 7} , /* 初始化索引号为 1 的行 */
{8, 9, 10, 11} /* 初始化索引号为 2 的行 */
};
int a[3][4] = {0,1,2,3,4,5,6,7,8,9,10,11}; // 内部嵌套的括号
// 访问二维数组元素:数组的行索引和列索引
int val = a[2][5];
12.3 传递数组给函数
在函数中传递一个数组作为参数,必须声明函数形式参数。
// 方式1:形式参数是一个指向数组的指针
void myFunction(int *param) { ... }
// 方式2:形式参数是一个已定义大小的数组
void myFunction(int param[10]) { ... }
// 方式3:形式参数是一个未定义大小的数组
void myFunction(int param[]) { ... }
#include 12.4 从函数返回数组
C 语言不允许返回一个完整的数组作为函数的参数,但可以通过指定不带索引的数组名来返回一个指向数组的指针。
关联知识点:14.6 从函数返回指针
#include 12.5 指向数组的指针
数组名是一个指向数组中第一个元素的常量指针。
// 声明数组后,数组名 balance 即是一个指向 balance[0] 的指针
double balance[10];
double *p;
p = balance; // 赋值数组内第一个元素的地址
// p = &balance[0];
*(balance + 4) // 访问 balance[4] 数据
*(p + 0) // 赋值后可通过 *p 访问数组元素
// 一旦我们有了 p 中的地址,*p 将给出存储在 p 中相应地址的值
13、枚举
一种基本数据类型,用于定义一组具有离散值的常量。
13.1 声明枚举类型
使用 enum 关键字定义枚举类型,每个枚举常量可以用一个标识符来表示,也可以指定一个整数值,如果没有指定则默认从 0 开始递增。
enum 枚举名 {枚举元素1, 枚举元素2, ……};
enum DAY { MON=1, TUE, WED, THU, FRI }; // 1,2,3,4,5
enum season { spring, summer=3, autumn, winter }; // 0,3,4,5
// 第一个元素值默认为0
// 若指定某个元素的值,则后续元素的值依次+1,之前的元素不受影响
13.2 定义枚举变量
13.2.1 定义变量
// 方式1:先定义枚举类型DAY,再定义枚举变量day
enum DAY
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
};
enum DAY day;
// 方式2:定义枚举类型DAY的同时定义枚举变量day
enum DAY
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
} day;
// 方式3:省略枚举名称,直接定义枚举变量day
enum
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
} day;
13.2.2 遍历枚举
枚举类型被当作 int 或 unsigned int 处理,C 语言无法遍历枚举类型,但连续的枚举类型可以实现有条件的遍历。
#include 13.3 将整数转换为枚举
#include 14、指针
14.1 指针变量
14.1.1 声明
指针也就是内存地址,指针变量是用来存放内存地址的变量。
type *var_name;
// type - 指针的基类型,必须是一个有效的 C 数据类型
// * - 指定一个变量是指针
// var_name - 指针变量的名称
int *ip; /* 一个整型的指针 */
double *dp; /* 一个 double 型的指针 */
float *fp; /* 一个浮点型的指针 */
char *ch; /* 一个字符型的指针 */
// 所有数据类型对应指针的值都是一个代表内存地址的长的十六进制数
// 不同数据类型的指针所指向的变量或常量的数据类型不同
14.1.2 赋值&访问
每一个变量的内存位置都定义了可使用 & 运算符访问的地址,使用 * 运算符来返回位于操作数所指定地址的变量的值。
#include 14.1.3 空指针
赋值为 NULL 的指针,一个定义在标准库中的值为零的常量。
【好习惯】在变量声明的时候,如果没有确切的地址可以赋值,为指针变量赋一个 NULL 值!
int *ptr = NULL; // ptr 的地址是 0x0
// 内存地址 0 表明该指针不指向一个可访问的内存位置
14.2 指针的运算
14.2.1 算术运算
C 指针是一个用数值表示的地址,可以进行 ++、–、+、- 运算。
#include 14.2.2 关系运算
指针可以用关系运算符 ==、<、> 进行大小比较。
#include 14.3 指针数组
int *ptr[n]; // ptr 中每个元素都是一个指向 int 值的指针
// ptr[] - 声明为一个数组
// n - 指定数组的长度
#include 14.4 指向指针的指针
一种多级间接寻址的形式,或者说是一个指针链,第一个指针包含了第二个指针的地址,第二个指针指向包含实际值的位置。

#include 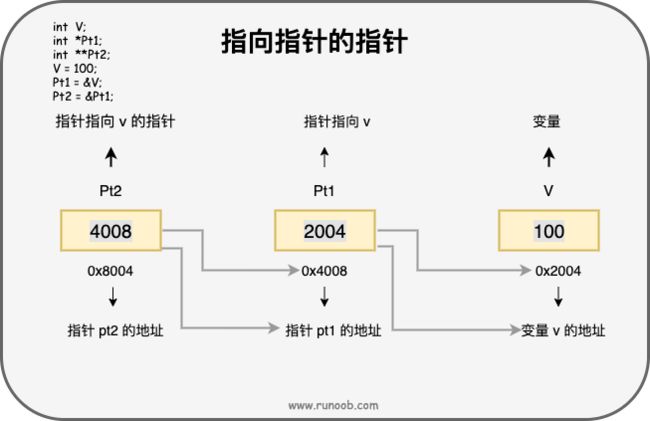
14.5 传递指针给函数
#include 14.6 从函数返回指针
// 声明一个返回指针的函数
int * myFunction() { ... }
#include ※指针形式的含义总结:
int var = 10; // var -(整型)变量,值为10 // &var - var的存储地址 int *poi; poi = &var; // *poi -(指向整型)指针,值为var(10) // poi - 指针变量,值为&var(var的存储地址,地址信息固定大小4byte) // &poi - poi的存储地址 int *poi_new; poi_new = poi + 5; // = &var + (5 x sizeof(int)) // = var的存储地址 + 5个整型存储大小 // = 从var的地址向后移动20个字节所在的地址 // = 第6个int变量的地址(假设var在第1个) /* 以下以一个数组空间为例 */ int arr[] = {2, 0, 2, 3}; *poi = arr; // arr - 数组的首元素arr[0],值为2 poi_new = *poi + 1; // == poi[0] + 1 // = arr[0] + 1 // = 2 + 1 // = 3 poi_new = *(poi + 1); // == poi[1] // = *(&arr[0] + (1 x sizeof(int))) // = *(&arr[1]) // = arr[1] // = 0
14、引用(C++)
引用变量是一个别名,是某个已存在变量的另一个名字。一旦把引用初始化为某个变量,就可以使用该引用名称或变量名称来指向变量。
14.1 引用 vs 指针
| 引用 | 指针 |
|---|---|
| 不存在空引用,必须链接到一块合法的内存 | 可以是空指针 |
| 必须在创建时被初始化 | 可以在任何时间被初始化 |
| 一旦初始化,就不能再指向另一个对象 | 可以在任何时候指向另一个对象 |
14.2 创建引用
把变量名称当作变量附属在内存位置中的标签,引用则是其第二个标签
// 通过原始变量名称或引用来访问变量的内容
int i = 17;
int& r = i; // r 是一个初始化为 i 的整型引用
#include 14.3 函数与引用
14.3.1 把引用作为参数(=传递指针给函数)
#include 14.3.2 把引用作为返回值
引用替代指针,当函数返回一个引用时,则返回一个指向返回值的隐式指针。
#include 15、函数指针与回调函数
15.1 函数指针
函数指针是指向函数的指针变量,可以像一般函数一样调用函数、传递参数。
// 声明一个指向同样参数、返回值的函数指针类型
typedef int (*fun_ptr)(int,int);
#include 15.2 回调函数
函数指针可以作为某个函数的参数来使用,被参数调用的函数称为回调函数。
#include 16、字符串
使用空字符 \0 结尾的一维字符数组,空字符(Null character, NUL)又称结束符,是一个数值为 0 的控制字符,转义为 \0 用于标记字符串的结束。
// 声明和初始化一个 RUNOOB 字符串
char site[7] = {'R', 'U', 'N', 'O', 'O', 'B', '\0'};
char site[] = "RUNOOB";
// C 编译器会在初始化数组时,自动把 \0 放在字符串的末尾
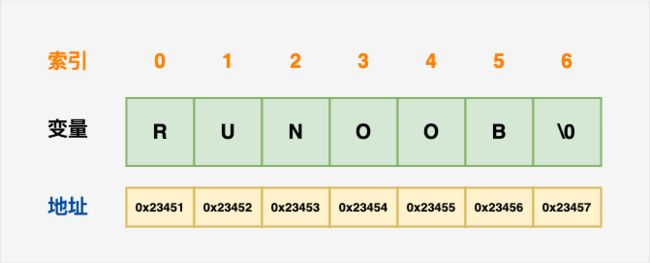
| 函数 | 返回 | 含义 | 描述 |
|---|---|---|---|
strcpy(s1, s2); |
s1=s2 | Copy | 复制字符串 s2 到字符串 s1 |
strcat(s1, s2); |
s1+s2 | Catenate | 连接字符串 s2 到字符串 s1 的末尾 |
strlen(s1); |
int | Length | 返回字符串 s1 的长度 |
strcmp(s1, s2); |
0 负数 正数 |
Compare | 比较两个字符串并返回整数: 如果 s1 == s2 ,则返回 0 如果 s1<s2,则返回负数 如果 s1>s2,则返回正数 |
strchr(s1, ch); |
*char | Char | 返回一个指针,指向字符串 s1 中字符 ch 的第一次出现的位置 |
strstr(s1, s2); |
*string | String | 返回一个指针,指向字符串 s1 中字符串 s2 的第一次出现的位置 |
17、结构体
允许用户自定义数据类型,存储不同类型的数据项,结构体中的数据成员可以是基本数据类型,也可以是其他结构体类型、指针类型等。
17.1 定义结构
17.1.1 定义格式
结构体定义由关键字 struct 和结构体名(自定义)组成。
// 定义一个包含多个成员的新的数据类型
struct tag {
definition A;
definition B;
...
} variables;
// tag - 结构体标签
// definition - 标准的变量定义,比如 int i;
// variables - 指定一个或多个结构变量,定义在结构的末尾
17.1.2 定义方式
关联知识点:20、别名
// 方式1:不命名标签,直接声明变量
struct
{
int a;
char b;
double c;
} s1; // s1 与 t1, t2[20], *t3 是完全不同的数据类型,不可相互赋值
// 方式2:命名标签,但不声明变量,另外用标签声明新的结构体变量
struct SIMPLE
{
int a;
char b;
double c;
};
struct SIMPLE t1, t2[20], *t3; // 声明 SIMPLE 类型的变量
// 方式3:用 typedef 给结构体命名,作为类型声明新的结构体变量
typedef struct
{
int a;
char b;
double c;
} Simple2;
Simple2 u1, u2[20], *u3; // 用 Simple2 作为类型声明新的结构体变量
17.1.3 结构类型
// 结构1:声明包含其他的结构体
struct COMPLEX
{
char string[100];
struct SIMPLE a;
};
// 结构2:声明包含指向自己类型的指针
struct NODE
{
char string[100];
struct NODE *next_node;
};
// 如果两个结构体互相包含,则需要对其中一个结构体进行不完整声明
struct B; // 对结构体B进行不完整声明
struct A
{
struct B *partner; //结构体A中包含指向结构体B的指针
...
};
struct B // 在A声明完后,B也随之进行声明
{
struct A *partner; // 结构体B中包含指向结构体A的指针
...
};
17.2 结构体变量的初始化
#include 17.3 访问结构成员
使用成员访问运算符 . 访问结构的成员。
#include 17.4 结构作为函数参数
可以把结构作为函数参数,传参方式与其他类型的变量或指针类似。
关联知识点:10.3 调用传参
#include 17.5 指向结构的指针
可以定义指向结构的指针,方式与定义指向其他类型变量的指针相似。
关联知识点:14、指针
struct Books *struct_pointer; // * 定义指向结构的指针
struct_pointer = &Book1; // & 在指针变量中存储结构变量的地址
struct_pointer->title; // -> 使用指针访问结构的成员
#include 18、共用体
在相同的内存位置存储不同的数据类型,可以定义一个带有多成员的共用体,但只能有一个成员带有值。
关联知识点:17、结构体
18.1 定义共用体
使用 union 语句定义共用体,方式与定义结构类似。
// 定义一个新的数据类型,带有多个成员
union tag
{
definition A;
definition B;
...
} variables;
// tag - 共同体标签
// definition - 标准的变量定义,比如 int i;
// variables - 指定一个或多个结构变量,定义在结构的末尾
// 定义一个共同体 Data
union Data
{
// 成员可以是任何内置或自定义的数据类型
int i;
float f;
char str[20]; // 共同体占用内存 ≥ 最大成员占用内存
};
// 声明 Data 类型的变量,可以存储一个整数、或浮点数、或字符串
union Data data;
18.2 访问共用体成员
使用成员访问运算符 . 访问共用体的成员,同一时间只能有一个成员带有值。
#include 19、位域
有些信息在存储时不需要占用一个完整的字节,而只需占几个或一个二进制位,为了节省存储空间和处理简便,C 语言提供了"位域"或"位段"的数据结构。
关联知识点:17、结构体
19.1 位域的定义
把一个字节的二进位划为几个不同的区域,每个区域有域名和位数,就可以把几个不同的对象用一个字节的二进制位域来表示;如果一个字节所剩空间不够存放另一位域时,则会从下一单元起存放该位域。
// 定义一个位域结构
struct tag
{
// 带有预定义宽度的变量被称为位域,可以存储多于 1 位的数
type realm_var1 : width;
type realm_var2 : width;
...
};
// type - 只能是 int、unsigned int、signed int 三种类型
// realm_var - 位域(变量)的名称
// width - 位域的宽度,不能超过所属数据类型的长度
// 定义宽度为 3 位的位域变量来存储 0~7 的值(8 的二进制 1000 有4位)
struct
{
unsigned int age : 3; // 不可使用超过 3 位的值,否则编译器警告
} Age;
// 使用无名位域表示从下一单元开始存放
struct bs{
unsigned a:4; // a 占第一字节的 4 位
unsigned :4; // 空域,不能使用(0000)
unsigned b:4; // b 从第二字节开始占用 4 位
unsigned c:4; // c 占用 4 位
}
// 位域在本质上就是一种结构类型,不过其成员是按二进位分配的
19.2 位域的使用
#include 20、别名
为内置的或自定义的数据类型取一个新的名字,可代替使用,通常为大写字母。
20.1 typedef 关键字
// 为 unsigned char 定义别名 BYTE,可代替其进行编译
typedef unsigned char BYTE;
BYTE b1, b2;
#include 20.2 #define 预处理指令
关联知识点:23.1 预处理器
#include 21、输入 & 输出
C 语言把所有的设备都当作文件,所以设备被处理的方式与文件相同。
| 标准文件 | 文件指针(访问文件的方式) | 设备 |
|---|---|---|
| 标准输入 | stdin | 键盘 |
| 标准输出 | stdout | 屏幕 |
| 标准错误 | stderr | 用户屏幕 |
| 函数 | 说明 |
|---|---|
int getchar(void) |
从标准输入 stdin 获取一个字符,转换为 int 返回读取的字符 |
int putchar(int char) |
把 char 指定的字符写入到标准输出 stdout ,转换为 int 返回该字符 |
char *gets(char *str) |
从标准输入 stdin 读取一行,并把它存储在 str 字符串中,返回 str |
int puts(const char *str) |
把字符串 str 加一个换行符输出到 stdout,返回一个非负值 |
int scanf(const char *format, ...) |
从标准输入流 stdin 读取输入,并根据提供的 format 来浏览输入 |
int printf(const char *format, ...) |
把输出写入到标准输出流 stdout ,并根据提供的 format 产生输出 |
#include - format 格式:
%[flags][width][.precision][length]specifier
| 规定符 | 说明 |
|---|---|
%d |
十进制有符号整数 |
%u |
十进制无符号整数 |
%f |
浮点数 |
%s |
字符串 |
%c |
单个字符 |
%p |
指针的值 |
%e |
指数形式的浮点数 |
%x %X |
无符号以十六进制表示的整数 |
%o |
无符号以八进制表示的整数 |
%g |
把输出的值按照 %e 或者 %f 类型中输出长度较小的方式输出 |
%p |
输出地址符 |
%lu |
32位无符号整数 |
%llu |
64位无符号整数 |
%% |
输出百分号字符本身 |
%-10s |
左对齐并占用宽度为 10 的字符串 |
%5.2f |
右对齐并占用宽度为 5,保留两位小数的浮点数 |
%#x |
输出带有 0x 前缀的十六进制数 |
21、基本的输入输出(C++)
C++ 的 I/O 发生在流中,流是字节序列。
- 输入操作:字节流从设备(键盘、磁盘驱动器、网络连接等)流向内存
- 输出操作:字节流从内存流向设备(显示屏、磁盘驱动器、网络连接等)
21.1 I/O 库头文件
| 头文件 | 函数和描述 |
|---|---|
| 该文件定义了 cin、cout、cerr 和 clog 对象,分别对应于标准输入流、标准输出流、非缓冲标准错误流和缓冲标准错误流。 | |
| 该文件通过所谓的参数化的流操纵器(比如 setw 和 setprecision),来声明对执行标准化 I/O 有用的服务。 | |
| 该文件为用户控制的文件处理声明服务。我们将在文件和流的相关章节讨论它的细节。 |
21.2 标准输出流(cout)
预定义的对象 cout 是 iostream 类的一个实例,与流插入运算符 << 结合使用;cout 对象"连接"到标准输出设备(显示屏)。
#include 21.3 标准输入流(cin)
预定义的对象 cin 是 iostream 类的一个实例,与流提取运算符 >> 结合使用;cin 对象附属到标准输入设备(键盘)。
#include 21.4 标准错误流(cerr)
预定义的对象 cerr 是 iostream 类的一个实例,与流插入运算符 << 结合使用;cerr 对象附属到标准输出设备(显示屏),但是 cerr 对象是非缓冲的,且每个流插入到 cerr 都会立即输出。
#include 21.5 标准日志流(clog)
预定义的对象 clog 是 iostream 类的一个实例,与流插入运算符 << 结合使用;clog 对象附属到标准输出设备(显示屏),但 clog 对象是缓冲的(每个流插入 clog 都会先存储在缓冲区,直到缓冲填满或者缓冲区刷新时才会输出)。
#include 【好习惯】使用 cerr 流来显示错误消息,其他的消息使用 clog 流输出!
22、文件读写
一个文件,无论它是文本文件还是二进制文件,都是代表了一系列的字节,C 语言提供了访问顶层的函数,和底层(OS)调用来处理存储设备上的文件。
fopen()- 使用给定的模式 mode 打开 filename 所指向的文件
FILE *fopen(const char *filename, const char *mode);
// filename - 字符串,表示要打开的文件名称
// mode - 字符串,表示文件的访问模式,可以是以下表格中的值
| 访问模式 | 二进制 | 描述 |
|---|---|---|
r |
"rb" |
打开一个已有的文本文件,允许读取文件 |
w |
"wb" |
打开一个文本文件,截断为零长度,从文件的开头重新写入;如果文件不存在,则会创建一个新文件 |
a |
"ab" |
打开一个文本文件,以追加模式写入文件;如果文件不存在,则会创建一个新文件 |
r+ |
"rb+" "r+b" |
打开一个文本文件,允许读写文件 |
w+ |
"wb+" "w+b" |
打开一个文本文件,截断为零长度,重新读写文件;如果文件不存在,则会创建一个新文件 |
a+ |
"ab+" "a+b" |
打开一个文本文件,从文件的开头开始读取,或者以追加模式写入;如果文件不存在,则会创建一个新文件 |
fclose()- 关闭流 stream,刷新所有的缓冲区
int fclose(FILE *stream);
// stream - 指向 FILE 对象的指针,该 FILE 对象指定了要被关闭的流
fputc()- 把参数 char 字符写入到流 stream 中,并把位置标识符往前移动
int fputc(int char, FILE *stream);
// char - 要被写入的字符,该字符以其对应的 int 值进行传递
// stream - 指向 FILE 对象的指针,该 FILE 对象标识了要被写入字符的流
fprintf()- 发送格式化输出到流 stream 中
int fprintf(FILE *stream, const char *format, ...);
// stream - 指向 FILE 对象的指针,该 FILE 对象标识了流
// format - 格式化字符串,包含嵌入的 format 标签
fgetc()- 从指定的流 stream 获取下一个字符,并把位置标识符往前移动
int fgetc(FILE *stream);
// stream - 指向 FILE 对象的指针,该 FILE 对象标识了要执行操作的流
fgets()- 从指定的流 stream 获取下一个字符,并把位置标识符往前移动
char *fgets(char *str, int n, FILE *stream);
// str - 指向一个字符数组的指针,该数组存储了要读取的字符串
// n - 要读取的最大字符数(包括\0),通常是使用以 str 传递的数组长度
// stream - 指向 FILE 对象的指针,该 FILE 对象标识了要读取字符的流
fscanf()- 从流 stream 读取格式化输入
int fscanf(FILE *stream, const char *format, ...);
// stream - 指向 FILE 对象的指针,该 FILE 对象标识了流
// format - 格式化字符串,包含空格字符、非空格字符和 format 说明符
fread()- 从给定流 stream 读取数据到 ptr 所指向的数组中
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
// ptr - 指向带有最小尺寸 size*nmemb 字节的内存块的指针
// size - 要读取的每个元素的大小,以字节为单位
// nmemb - 元素的个数,每个元素的大小为 size 字节
// stream - 指向 FILE 对象的指针,该 FILE 对象指定了一个输入流
fwrite()- 把 ptr 所指向的数组中的数据写入到给定流 stream 中
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
// ptr - 指向要被写入的元素数组的指针
// size - 要被写入的每个元素的大小,以字节为单位
// nmemb - 元素的个数,每个元素的大小为 size 字节
// stream - 指向 FILE 对象的指针,该 FILE 对象指定了一个输出流
22、文件和流(C++)
从文件读取流和向文件写入流。
| 数据类型 | 描述 |
|---|---|
ofstream |
输出文件流,用于创建文件并向文件写入信息 |
ifstream |
输入文件流,用于从文件读取信息 |
fstream |
文件流,可以创建文件,向文件写入信息,并从文件读取信息 |
22.1 打开文件
open()- fstream、ifstream 和 ofstream 对象的一个成员
void open(const char *filename, ios::openmode mode);
// *filename - 指定要打开的文件的名称和位置
// mode - 定义文件被打开的模式
| 模式标志 | 描述 |
|---|---|
ios::app |
追加模式,所有写入都追加到文件末尾 |
ios::ate |
文件打开后定位到文件末尾 |
ios::in |
打开文件用于读取 |
ios::out |
打开文件用于写入 |
ios::trunc |
如果该文件已经存在,其内容将在打开文件之前被截断,即把文件长度设为 0 |
/* 以写入模式打开文件,并希望截断文件,以防文件已存在 */
ofstream outfile;
outfile.open("file.dat", ios::out | ios::trunc );
/* 打开一个文件用于读写 */
ifstream afile;
afile.open("file.dat", ios::out | ios::in );
22.2 关闭文件
程序终止时会自动刷新所有流,释放所有分配的内存,并关闭所有打开的文件。
【好习惯】在程序终止前主动关闭所有打开的文件!
close()- fstream、ifstream 和 ofstream 对象的一个成员
void close();
22.3 读取 & 写入
- 使用 ofstream 或 fstream 对象和流插入运算符
<<向文件写入信息 - 使用 ifstream 或 fstream 对象和流提取运算符
>>从文件读取信息
#include 22.4 文件位置指针
文件位置指针是一个整数值,指定了从文件的起始位置到指针所在位置的字节数。
seekg()/seekp()- 第一个参数通常是长整型;第二个参数指定查找方向:ios::beg(默认的,从流的开头开始定位)、 ios::cur(从流的当前位置开始定位)、 ios::end(从流的末尾开始定位)
// 定位到 fileObject 的第 n 个字节(假设是 ios::beg)
fileObject.seekg( n );
// 把文件的读指针从 fileObject 当前位置向后移 n 个字节
fileObject.seekg( n, ios::cur );
// 把文件的读指针从 fileObject 末尾往回移 n 个字节
fileObject.seekg( n, ios::end );
// 定位到 fileObject 的末尾
fileObject.seekg( 0, ios::end );
23、预处理器
23.1 预处理器
预处理器只是一个文本替换工具,指示编译器在实际编译之前完成所需的预处理,所有的预处理器命令都以 # 开头,从第一行开始书写。
| 指令 | 描述 |
|---|---|
| #define | 定义宏 |
| #include | 包含一个源代码文件 |
| #undef | 取消已定义的宏 |
| #ifdef | 如果宏已经定义,则返回真 |
| #ifndef | 如果宏没有定义,则返回真 |
| #if | 如果给定条件为真,则编译下面代码 |
| #else | #if 的替代方案 |
| #elif | 如果前面的 #if 给定条件不为真,当前条件为真,则编译下面代码 |
| #endif | 结束一个 #if……#else 条件编译块 |
| #error | 当遇到标准错误时,输出错误消息 |
| #pragma | 使用标准化方法,向编译器发布特殊的命令到编译器中 |
#include 23.2 预定义宏
ANSI C 定义了许多宏,可以直接使用,但是不能修改这些预定义的宏。
| 宏 | 描述 |
|---|---|
| __DATE__ | 当前日期,一个以 "MMM DD YYYY" 格式表示的字符常量。 |
| __TIME__ | 当前时间,一个以 "HH:MM:SS" 格式表示的字符常量。 |
| __FILE__ | 这会包含当前文件名,一个字符串常量。 |
| __LINE__ | 这会包含当前行号,一个十进制常量。 |
| __STDC__ | 当编译器以 ANSI 标准编译时,则定义为 1。 |
#include 23.3 预处理器运算符
| 运算符 | 说明 |
|---|---|
\ |
宏延续运算符:使一个太长的宏在一个单行延续下去 |
# |
字符串常量化运算符:把一个宏的参数转换为字符串常量 |
## |
标记粘贴运算符:合并两个参数,将两个独立的标记合并为一个标记 |
defined() |
defined 运算符:判断一个标识符是否已经使用 #define 定义过 |
#include 23.4 参数化的宏
#include 24、头文件
头文件是扩展名为 .h 的文件,包含了 C 函数声明和宏定义,被多个源文件引用共享,包含程序员编写的头文件和编译器自带的头文件。
【好习惯】建议把所有的常量、宏、系统全局变量和函数原型写在头文件中,在需要的时候随时引用这些头文件!
- 引用头文件的语法:使用
#include指令引用系统或用户头文件
// 使用包装器 #ifndef 包裹头文件引用,防止重复处理报错
#ifndef HEADER_FILE
#define HEADER_FILE
#include - 引用头文件的操作:使用
#include指令浏览指定的文件作为输入
#include "header.h" // 在当前位置插入 header.h 文件内容
- 有条件引用:从多个不同的头文件中选择一个引用到程序中
// 预处理器使用宏来定义头文件的名称,查找所有匹配宏扩展名称的文件
#define SYSTEM_H "system_1.h"
...
#include SYSTEM_H
25、强制类型转换
25.1 显式转换
把变量值显式地从一种类型转换为另一种数据类型。
【好习惯】只要有需要类型转换的时候都用上强制类型转换运算符!
(type_name) expression
#include 25.2 整数提升
把小于 int 或 unsigned int 的整数类型转换为 int 或 unsigned int 的过程。
#include 25.3 常用的算术转换
隐式地把值强制转换为相同的类型,不适用于赋值运算符、逻辑运算符( &&、||)。编译器首先执行整数提升,如果操作数类型不同,则转换为下列层次中出现的最高层次的类型:
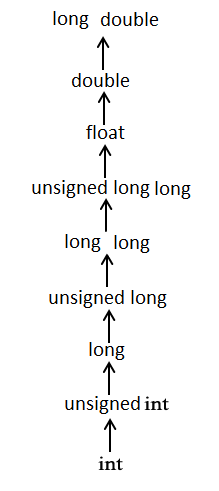
#include 26、错误处理
发生错误时,程序返回 1 或 NULL,同时会设置一个错误代码 errno(头文件 errno.h ),可以通过检查返回值,然后根据返回值决定采取哪种适当的动作。
【好习惯】在程序初始化时,把 errno 设置为 0,表示程序中没有错误!
26.1 errno 与函数
errno- 系统调用的全局变量,表示在函数调用期间发生了错误
extern int errno;
perror()- 把一个描述性错误消息输出到标准错误 stderr 文件流
void perror(const char *str);
// str - 字符串,包含了一个自定义消息,将显示在原本的错误消息之前
strerror()- 搜索错误号 errnum,返回一个指向错误消息字符串的指针
char *strerror(int errnum);
// errnum - 错误号,通常是 errno
#include 26.2 除法错误 & 退出状态
程序正常退出时会带有状态值 EXIT_SUCCESS(0),如果程序中存在错误,退出程序时会带有状态值 EXIT_FAILURE(-1)。
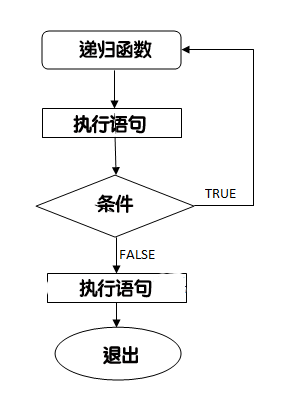
#include 27、递归
在函数的定义中使用函数自身的方法。
【好习惯】定义一个从函数退出的条件,否则会进入死循环!
void recursion()
{
statements;
... ... ...
recursion(); /* 函数调用自身 */
... ... ...
}
int main()
{
recursion();
}
#include 28、可变参数
允许定义一个函数,能根据具体的需求接受可变数量的参数。
- 定义一个函数,最后一个参数为省略号,省略号前面可以设置自定义参数:
int func_name(int arg1, ...);
// int - 要传递的可变参数的总数
// ... - 可变参数列表
- 在函数定义中创建一个 va_list 类型(在 stdarg.h 头文件中定义)的变量:
va_list valist;
- 使用 int 参数和
va_start()宏来初始化 va_list 变量为一个参数列表:
// 初始化 ap 变量,必须在 va_arg 和 va_end 之前被调用
void va_start(va_list ap, last_arg);
// ap - va_list 类型的对象,存储 va_arg 获取额外参数时必需的信息
// last_arg - 可变参数列表之前的最后一个参数
- 使用
va_arg()宏和 va_list 变量来访问参数列表中的每个项:
// 检索函数参数列表中类型为 type 的下一个参数
type va_arg(va_list ap, type);
// ap - va_list 类型的对象,存储了有关额外参数和检索状态的信息
// type - 类型名称,作为扩展自该宏的表达式的类型来使用
- 使用宏
va_end()来清理赋予 va_list 变量的内存:
// 允许使用 va_start 宏的带有可变参数的函数返回,将 ap 置为 NULL
void va_end(va_list ap);
// ap - 之前由同一函数中的 va_start 初始化的 va_list 对象
#include 29、内存管理
内存通过指针变量来管理,它存储了内存地址,可以指向任何数据类型的变量。
关联知识点:7.1 运算符类型
| 函数或运算符 | 描述 |
|---|---|
void *malloc(int num); |
分配一块指定大小的内存空间,值是未知的 |
void *calloc(int num, int size); |
分配 num 个长度为 size 的内存空间,都初始化为 0 |
void *realloc(void *ptr, int newsize); |
重新分配 ptr 所指向的内存,扩展到 newsize 大小 |
void free(void *ptr); |
释放 ptr 所指向的之前动态分配的内存空间 |
void *memcpy(void *str1, const void *str2, int n); |
从存储区 str2 复制 n 个字节到存储区 str1 |
void *memmove(void *str1, const void *str2, int n); |
从 str2 复制 n 个字符到 str1,可处理重叠的内存区域 |
sizeof() |
获取数据类型或变量的字节大小 |
* |
获取指针所指向的内存地址或变量值 |
& |
获取变量的内存地址 |
-> |
使用指针访问结构的成员 |
-
动态分配内存:如果预先不知道需要存储的文本长度,需要定义一个指针,指向未定义所需内存大小的字符,后续再根据需求来分配内存。
-
重新调整内存大小和释放内存:当程序退出时,操作系统会自动释放所有分配给程序的内存,但在不需要内存时,都应该主动调用函数 free() 来释放内存,或者通过调用函数 realloc() 来增加或减少已分配的内存块的大小。
#include 29、动态内存(C++)
C++ 程序中的内存分为两个部分:
- 栈:在函数内部声明的所有变量都将占用栈内存
- 堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存
29.1 new 和 delete 运算符
有时候无法提前预知需要多少内存来存储某个变量中的信息,可以使用 new 运算符为给定类型的变量在运行时分配堆内的内存,并返回所分配的空间地址;若不再需要动态分配的内存空间,可以使用 delete 运算符删除之前分配的内存。
【好习惯】尽量不使用 malloc() 函数,new 不仅分配了内存还创建了对象
new dataType; // dataType - 任意内置的或用户自定义的数据类型
delete dataType; // 释放 dataType 所指向的内存
#include 29.2 数组的动态内存分配
/* 一维数组 */
int *array = new int[m]; // 动态分配数组空间,长度为m
delete [] array; // 删除 array 所指向的数组,释放内存
/* 二维数组 */
int **array;
array = new int*[m]; // 数组第一维长度为 m(指针)
for( int i=0; i<m; i++ )
{
array[i] = new int[n]; // 数组第二维长度为 n(变量)
}
for( int i=0; i<m; i++ )
{
delete [] array[i]; // 释放单位空间
}
delete [] array; // 释放数组空间
/* 三维数组 */
int ***array;
array = new int**[m]; // 数组第一维长度为 m(指针指针)
for( int i=0; i<m; i++ )
{
array[i] = new int*[n]; // 数组第二维长度为 n(指针)
for( int j=0; j<n; j++ )
{
array[i][j] = new int[h]; // 数组第三维长度为 h(变量)
}
}
for( int i=0; i<m; i++ )
{
for( int j=0; j<n; j++ )
{
delete[] array[i][j]; // 释放三维空间
}
delete[] array[i]; // 释放二维空间
}
delete[] array; // 释放数组空间
29.3 对象的动态内存分配
#include 30、命令行参数
如果想从外部控制程序,可以从命令行传值,这些值称为命令行参数。
int main(int argc, char *argv[]) { }
// argc - 命令行传入参数的个数(程序名称+参数列表)
// argv[] - 指针数组(程序名称+参数列表),指向命令行传递的每个参数
#include - 使用参数编译并执行代码:
# 使用一个参数编译
$./a.out testing
# 使用多个参数编译(空格分隔)
$./a.out testing1 testing2
$./a.out "t1 t2" testing3 # 若参数本身有空格,则放在引号内
# 不使用参数编译
$./a.out
31、排序算法
31.1 冒泡排序
重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序(如从大到小、首字母从A到Z)错误就把他们交换过来。

#include 31.2 选择排序
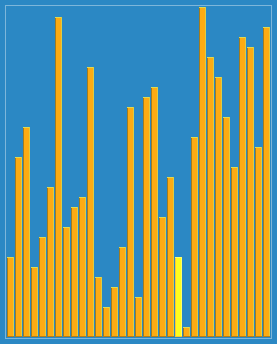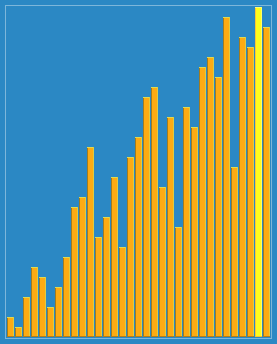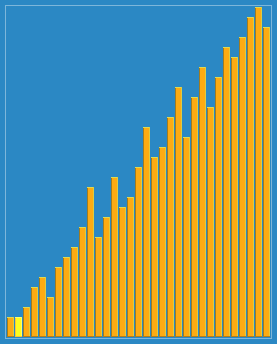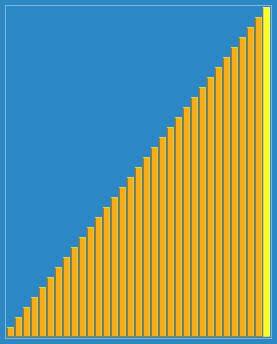
在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,再从剩余未排序元素中继续寻找最小(大)元素,依次存放。

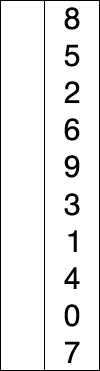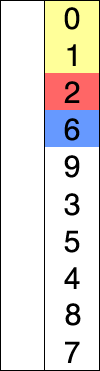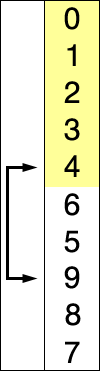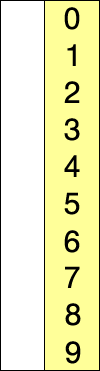
void selection_sort(int a[], int len)
{
int i,j,temp;
for (i = 0 ; i < len - 1 ; i++)
{
int min = i; // 记录最小值,第一个元素默认最小
for (j = i + 1; j < len; j++) // 访问未排序的元素
{
if (a[j] < a[min]) // 找到目前最小值
{
min = j; // 记录最小值
}
}
if(min != i)
{
temp=a[min]; // 交换两个变量
a[min]=a[i];
a[i]=temp;
}
/* swap(&a[min], &a[i]); */ // 使用自定义函数交換
}
}
/*
void swap(int *a,int *b) // 交换两个变量
{
int temp = *a;
*a = *b;
*b = temp;
}
*/
31.3 插入排序
构建有序序列,在已排序序列中从后向前扫描,把已排序元素逐步向后挪位,为未排序数据找到相应位置并插入,通常采用in-place排序。

void insertion_sort(int arr[], int len){
int i,j,temp;
for (i=1;i<len;i++){
temp = arr[i];
for (j=i;j>0 && arr[j-1]>temp;j--)
arr[j] = arr[j-1];
arr[j] = temp;
}
}
31.4 希尔排序
也称递减增量排序算法,是非稳定排序算法,是插入排序的一种更高效的改进版本。
void shell_sort(int arr[], int len) {
int gap, i, j;
int temp;
for (gap = len >> 1; gap > 0; gap = gap >> 1)
for (i = gap; i < len; i++) {
temp = arr[i];
for (j = i - gap; j >= 0 && arr[j] > temp; j -= gap)
arr[j + gap] = arr[j];
arr[j + gap] = temp;
}
}
31.5 归并排序
把数据分为两段,从两段中逐个选最小的元素移入新数据段的末尾,可从上到下或从下到上进行。


// 迭代法
int min(int x, int y) {
return x < y ? x : y;
}
void merge_sort(int arr[], int len) {
int* a = arr;
int* b = (int*) malloc(len * sizeof(int));
int seg, start;
for (seg = 1; seg < len; seg += seg) {
for (start = 0; start < len; start += seg + seg) {
int low = start, mid = min(start + seg, len), high = min(start + seg + seg, len);
int k = low;
int start1 = low, end1 = mid;
int start2 = mid, end2 = high;
while (start1 < end1 && start2 < end2)
b[k++] = a[start1] < a[start2] ? a[start1++] : a[start2++];
while (start1 < end1)
b[k++] = a[start1++];
while (start2 < end2)
b[k++] = a[start2++];
}
int* temp = a;
a = b;
b = temp;
}
if (a != arr) {
int i;
for (i = 0; i < len; i++)
b[i] = a[i];
b = a;
}
free(b);
}
// 递归法
void merge_sort_recursive(int arr[], int reg[], int start, int end) {
if (start >= end)
return;
int len = end - start, mid = (len >> 1) + start;
int start1 = start, end1 = mid;
int start2 = mid + 1, end2 = end;
merge_sort_recursive(arr, reg, start1, end1);
merge_sort_recursive(arr, reg, start2, end2);
int k = start;
while (start1 <= end1 && start2 <= end2)
reg[k++] = arr[start1] < arr[start2] ? arr[start1++] : arr[start2++];
while (start1 <= end1)
reg[k++] = arr[start1++];
while (start2 <= end2)
reg[k++] = arr[start2++];
for (k = start; k <= end; k++)
arr[k] = reg[k];
}
void merge_sort(int arr[], const int len) {
int reg[len];
merge_sort_recursive(arr, reg, 0, len - 1);
}
31.6 快速排序
在区间中随机挑选一个元素作基准,将小于基准的元素放在基准之前,大于基准的元素放在基准之后,再分别对小数区与大数区进行排序。

// 迭代法
typedef struct _Range {
int start, end;
} Range;
Range new_Range(int s, int e) {
Range r;
r.start = s;
r.end = e;
return r;
}
void swap(int *x, int *y) {
int t = *x;
*x = *y;
*y = t;
}
void quick_sort(int arr[], const int len) {
if (len <= 0)
return; // 避免len等於負值時引發段錯誤(Segment Fault)
// r[]模擬列表,p為數量,r[p++]為push,r[--p]為pop且取得元素
Range r[len];
int p = 0;
r[p++] = new_Range(0, len - 1);
while (p) {
Range range = r[--p];
if (range.start >= range.end)
continue;
int mid = arr[(range.start + range.end) / 2]; // 選取中間點為基準點
int left = range.start, right = range.end;
do
{
while (arr[left] < mid) ++left; // 檢測基準點左側是否符合要求
while (arr[right] > mid) --right; //檢測基準點右側是否符合要求
if (left <= right)
{
swap(&arr[left],&arr[right]);
left++;right--; // 移動指針以繼續
}
} while (left <= right);
if (range.start < right) r[p++] = new_Range(range.start, right);
if (range.end > left) r[p++] = new_Range(left, range.end);
}
}
// 递归法
void swap(int *x, int *y) {
int t = *x;
*x = *y;
*y = t;
}
void quick_sort_recursive(int arr[], int start, int end) {
if (start >= end)
return;
int mid = arr[end];
int left = start, right = end - 1;
while (left < right) {
while (arr[left] < mid && left < right)
left++;
while (arr[right] >= mid && left < right)
right--;
swap(&arr[left], &arr[right]);
}
if (arr[left] >= arr[end])
swap(&arr[left], &arr[end]);
else
left++;
if (left)
quick_sort_recursive(arr, start, left - 1);
quick_sort_recursive(arr, left + 1, end);
}
void quick_sort(int arr[], int len) {
quick_sort_recursive(arr, 0, len - 1);
}