NLP项目:维基百科文章爬虫和分类【02】 - 语料库转换管道

一、说明
我的NLP项目在维基百科条目上下载、处理和应用机器学习算法。相关上一篇文章中,展示了项目大纲,并建立了它的基础。首先,一个 Wikipedia 爬网程序对象,它按名称搜索文章,提取标题、类别、内容和相关页面,并将文章存储为纯文本文件。其次,一个语料库对象,它处理完整的文章集,允许方便地访问单个文件,并提供全局数据,如单个令牌的数量。
二、背景介绍
在本文中,我将继续展示如何创建一个NLP项目,以从其机器学习领域对不同的维基百科文章进行分类。你将了解如何创建自定义 SciKit Learn 管道,该管道使用 NLTK 进行标记化、词干提取和矢量化,然后应用贝叶斯模型来应用分类。所有代码也可以在Jupyter Notebook中看到。
本文的技术背景是 Python v3.11 和几个附加库,最重要的是 pandas v2.0.1、scikit-learn v1.2.2 和 nltk v3.8.1。所有示例也应该适用于较新的版本。
2.1 需求和使用的 Python 库
请务必阅读并运行上一篇文章的要求,以便有一个 Jupyter 笔记本来运行所有代码示例。
对于本文,需要以下库:这些步骤中的每一个都将成为管道对象的一部分,管道对象是读取、预处理、矢量化和聚类文本的顺序过程。我们将在此项目中使用以下 Python 库和对象:
pandas
DataFrame用于存储文本、标记和矢量的对象
sk-learn
Pipeline对象实现处理步骤链BaseEstimator并生成表示管道步骤的自定义类TransformerMixin
NLTK
- PlaintextCorpusReader 用于可遍历对象,可访问文档、提供标记化方法并计算有关所有文件的统计信息
- sent_tokenizer 和 word_tokenizer 用于生成令牌
- 减少标记的stopword列表
2.2 SciKit Learn Pipeline
为了便于获得一致的结果和轻松定制,SciKit Learn 提供了 Pipeline 对象。该对象是一系列转换器、实现拟合fit和transform变换方法的对象以及实现拟合fit方法的最终估计器。执行管道对象意味着调用每个转换器来修改数据,然后将最终的估计器(机器学习算法)应用于此数据。管道对象公开其参数,以便可以更改超参数,甚至可以跳过整个管道步骤。
我们将使用此概念来构建一个管道,该管道开始创建语料库对象,然后预处理文本,然后提供矢量化,最后提供聚类或分类算法。为了突出本文的范围,我将在下一篇文章中仅解释转换器步骤,并接近聚类和分类。
三、管道准备
让我们从大局开始。最终的管道对象将按如下方式实现:
pipeline = Pipeline([
('corpus', WikipediaCorpus()),
('preprocess', TextPreprocessor()),
('tokenizer', Tokenizer()),
('encoder', OneHotEncoder())
])然后,此管道从一个空的 Pandas 数据帧对象开始,随后将数据添加到该对象,即我们实现如下所示的数据帧对象:

对于上述每个步骤,我们将使用自定义类,该类从推荐的 ScitKit Learn 基类继承方法。
from sklearn.base import BaseEstimator, TransformerMixin
from nltk.tokenize import sent_tokenize, word_tokenize
class SciKitTransformer(BaseEstimator, TransformerMixin):
def fit(self, X=None, y=None):
return self
def transform(self, X=None):
return self让我们开始实现。
3.1 管道步骤 1:创建语料库
第一步是重用上一篇文章中解释的 Wikipedia 语料库对象,并将其包装在基类中,并提供两个 DataFrame 列 title 和 raw。在标题列中,我们存储除 .txt 扩展名之外的文件名。在原始列中,我们存储文件的完整内容。
此转换使用列表推导式和 NLTK 语料库读取器的内置方法。
class WikipediaCorpus(PlaintextCorpusReader):
def __init__(self, root_path):
PlaintextCorpusReader.__init__(self, root_path, r'.*')
class WikipediaCorpus(SciKitTransformer):
def __init__(self, root_path=''):
self.root_path = root_path
self.corpus = WikipediaReader(self.root_path)
def transform(self, X=None):
X = pd.DataFrame().from_dict({
'title': [filename.replace('.txt', '') for filename in self.corpus.fileids()],
'raw': [self.corpus.raw(doc) for doc in corpus.fileids()]
})
return X3.2 管道步骤 2:文本预处理
在 NLP 应用程序中,通常会检查原始文本中不需要的符号,或者可以删除的停用词,甚至应用词干提取和词形还原。
对于维基百科的文章,我决定将文本分成句子和标记,而不是标记转换,最后将它们重新组合在一起。转换如下:
- 删除所有停用词
- 删除所有非ASCII字母,非数字标记
- 仅保留 .,以及用于序列分隔
,;. - 使用单个空格删除所有出现的多个空格
这是 TextPreprocessor 的完整实现。 DataFrame 对象使用 Pandas apply 方法预处理的新列进行扩展。
class TextPreprocessor(SciKitTransformer):
def __init__(self, root_path=''):
self.root_path = root_path
self.corpus = WikipediaReader(self.root_path)
self.tokenizer = word_tokenize
def preprocess(self, text):
preprocessed = ''
for sent in sent_tokenize(text):
if not len(sent) <= 3:
text = ' '.join([word for word in word_tokenize(sent) if not word in stopwords.words("english")])
text = re.sub('[^A-Za-z0-9,;\.]+', ' ', text)
text = re.sub(r'\s+', ' ', text)
# preserve text tokens
text = re.sub(r'\s\.', '.', text)
text = re.sub(r'\s,', ',', text)
text = re.sub(r'\s;', ';', text)
# remove all non character, non number chars
preprocessed += ' '+ text.strip()
return preprocessed
def transform(self, X):
X['preprocessed'] = X['raw'].apply(lambda text: self.preprocess(text))
return X3.3 管道步骤 3-标记化
现在,使用与之前相同的 NLT word_tokenizer 对预处理后的文本进行再次标记化,但可以使用不同的标记化器实现进行交换。
和以前一样,通过在预处理列上使用 apply 来扩展 DataFrame,添加一个新列 tokens。
class TextTokenizer(SciKitTransformer):
def preprocess(self, text):
return [token.lower() for token in word_tokenize(text)]
def transform(self, X):
X['tokens'] = X['preprocessed'].apply(lambda text: self.preprocess(text))
return X3.4 管道步骤 4:编码器
对标记化文本进行编码是矢量化的先导。为了使本文保持重点,我将提供一种相当简单的编码方法,该方法计算所有文本的完整词汇表,并对特定文章中出现的所有单词进行独热编码。词汇表的基础是错误的:我使用精炼标记列表作为输入,但也可以使用NLTK-CorpusReader对象中的vocab方法。
class OneHotEncoder(SciKitTransformer):
def encode(self, token_series, tokens):
one_hot = {}
for _, token_list in token_series.items():
for token in token_list:
one_hot[token] = 0
for token in tokens:
one_hot[token] = 1
return one_hot
def transform(self, X):
token_list = X['tokens']
X['one-hot-encoding'] = X['tokens'].apply(lambda tokens: self.encode(token_list, tokens))
return X这种编码非常昂贵,因为每次运行的完整词汇表都是从头开始构建的——这可以在未来的版本中改进。
四、完整的源代码
以下是完整的示例:
import numpy as np
import pandas as pd
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
from sklearn.base import TransformerMixin
from sklearn.pipeline import Pipeline
from nltk.corpus.reader.plaintext import CategorizedPlaintextCorpusReader
from nltk.tokenize.stanford import StanfordTokenizer
class WikipediaPlaintextCorpus(PlaintextCorpusReader):
def __init__(self, root_path):
PlaintextCorpusReader.__init__(self, root_path, r'.*')
class SciKitTransformer(BaseEstimator, TransformerMixin):
def fit(self, X=None, y=None):
return self
def transform(self, X=None):
return self
class WikipediaCorpus(SciKitTransformer):
def __init__(self, root_path=''):
self.root_path = root_path
self.wiki_corpus = WikipediaPlaintextCorpus(self.root_path)
def transform(self, X=None):
X = pd.DataFrame().from_dict({
'title': [filename.replace('.txt', '') for filename in self.wiki_corpus.fileids()],
'raw': [self.wiki_corpus.raw(doc) for doc in corpus.fileids()]
})
return X
class TextPreprocessor(SciKitTransformer):
def __init__(self, root_path=''):
self.root_path = root_path
self.corpus = WikipediaPlaintextCorpus(self.root_path)
def preprocess(self, text):
preprocessed = ''
for sent in sent_tokenize(text):
text = ' '.join([word for word in word_tokenize(sent) if not word in stopwords.words("english")])
text = re.sub('[^A-Za-z0-9,;\.]+', ' ', text)
text = re.sub(r'\s+', ' ', text)
# preserve text tokens
text = re.sub(r'\s\.', '.', text)
text = re.sub(r'\s,', ',', text)
text = re.sub(r'\s;', ';', text)
# remove all non character, non number chars
preprocessed += ' '+ text.strip()
return preprocessed
def transform(self, X):
X['preprocessed'] = X['raw'].apply(lambda text: self.preprocess(text))
return X
class TextTokenizer(SciKitTransformer):
def preprocess(self, text):
return [token.lower() for token in word_tokenize(text)]
def transform(self, X):
X['tokens'] = X['preprocessed'].apply(lambda text: self.preprocess(text))
return X
class OneHotEncoder(SciKitTransformer):
def encode(self, token_series, tokens):
one_hot = {}
for _, token_list in token_series.items():
for token in token_list:
one_hot[token] = 0
for token in tokens:
one_hot[token] = 1
return one_hot
def transform(self, X):
token_list = X['tokens']
X['one-hot-encoding'] = X['tokens'].apply(lambda tokens: self.encode(token_list, tokens))
return X
corpus = WikipediaPlaintextCorpus('articles2')
pipeline = Pipeline([
('corpus', WikipediaCorpus(root_path='./articles2')),
('preprocess', TextPreprocessor(root_path='./articles2')),
('tokenizer', TextTokenizer()),
('encoder', OneHotEncoder())
])管道对象在 Jupyter 笔记本中呈现如下:
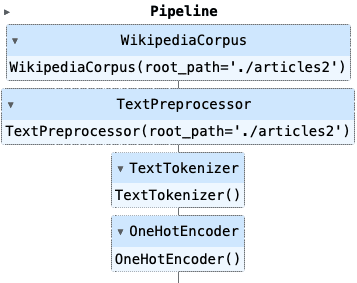
五、结论
SciKit Learn Pipeline 对象提供了一种将多个转换和机器学习模型堆叠在一起的便捷方法。所有相关的超参数都可以公开并配置以获得可重复的结果。在本文中,您学习了如何通过四个步骤为 Wikipedia 文章创建文本处理管道:a) WikipediaCorpus 用于访问纯文本文件和全局统计信息(例如单词出现次数),b) TextPreprocessor 用于从文本中删除符号和停用词,c) TextTokenizer从预处理的文本创建标记,d) OneHotEncoder 提供简单的统计,总语料库词汇中的单词出现在特定文章中。下一篇文章将继续如何将标记和编码转换为数值向量表示。
参考资料:塞巴斯蒂安