语义分割,实例分割,全景分割梳理
语义分割(semantic segmentation)
实例分割(instance segmentation)
全景分割(Panoptic Segmentation)
下面基于《Panoptic Segmentation 》这篇论文进行这几个概念的梳理
论文链接:https://openaccess.thecvf.com/content_CVPR_2019/papers/Kirillov_Panoptic_Segmentation_CVPR_2019_paper.pdf
论文提出并研究了一个称之为全景分割(Panoptic Segmentation,PS)的任务。全景分割统一了语义分割(为每个像素分配一个类标签)和实例分割(检测和分割每个对象实例)这两个典型的不同任务
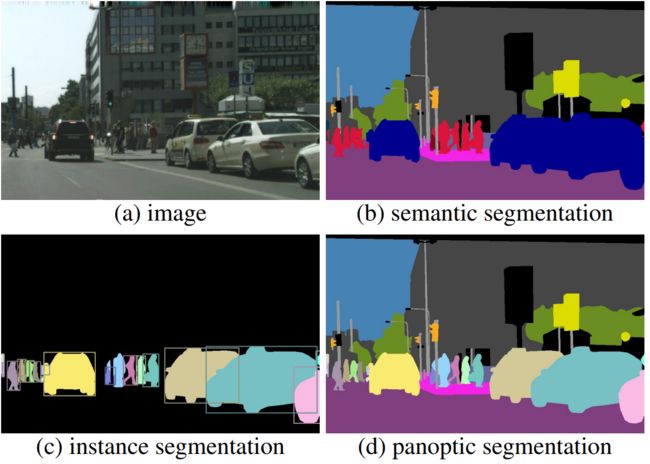
Figure 1. 给定图像(a);标签如(b)为语义分割(每个像素的类别标签);标签如(c) 实例分割(每个对象掩码和类别标签);标签如(d)提议的全景分割任务(每像素类别+实例标签);全景分割任务:(1) 包括stuff和thing的类别;(2) 使用简单但通用的格式;(3) 为所有类别引入统一的评估指标。全景分割概括了语义分割和实例分割,我们期待统一的任务将带来新的挑战,并促成创新的新方法。
上图中thing指代诸如人、动物、工具之类的可数对象,stuff是指具有相似纹理或材料的无定形区域,例如草、天空、道路。
(1)语义分割与实例分割区别联系
总的而言,目前的分割任务主要有两种: 语义分割和实例分割。
语义分割是对图像中的每个像素都划分出对应的类别,即实现像素级别的分类; 而类的具体对象,即为实例,
语义分割和实例分割的区别又是什么
语义分割会为图像中的每个像素分配一个类别,但是同一类别之间的对象不会区分。而实例分割,只对特定的物体进行分类。这看起来与目标检测相似,不同的是目标检测输出目标的边界框和类别,实例分割输出的是目标的Mask和类别。
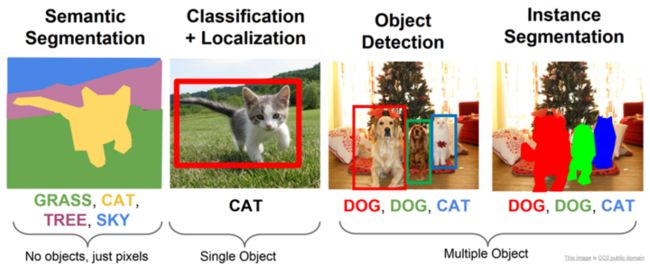
语义分割、分类和定位、目标检测和实例分割的比较
(2)语义分割与实例分割经典网络
1.语义分割
<1>全卷积网络FCN https://arxiv.org/pdf/1411.4038.pdf
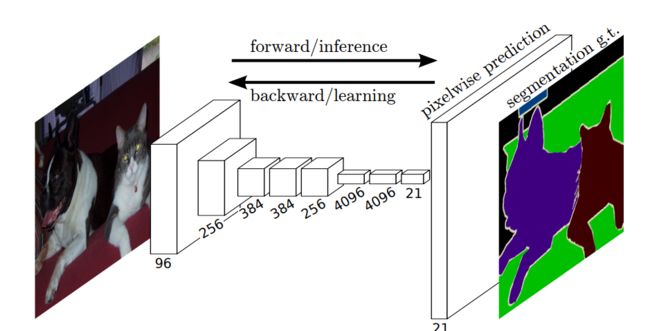
全卷积网络可以有效地学习,使每个像素的任务,如语义分割密集的预测。
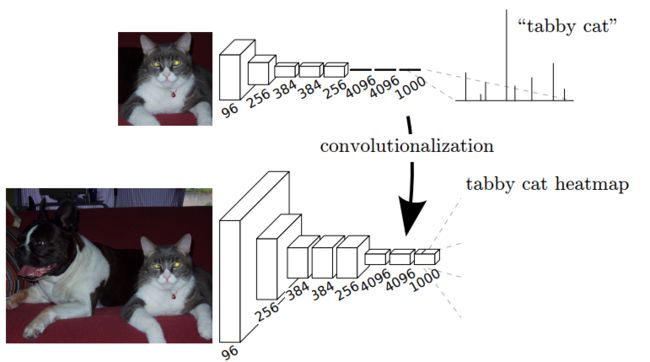
将全连接层转换为卷积层使分类网能够输出热力图。增加层和空间损耗(如上图所示)为端到端密集学习提供了一个高效的机器。
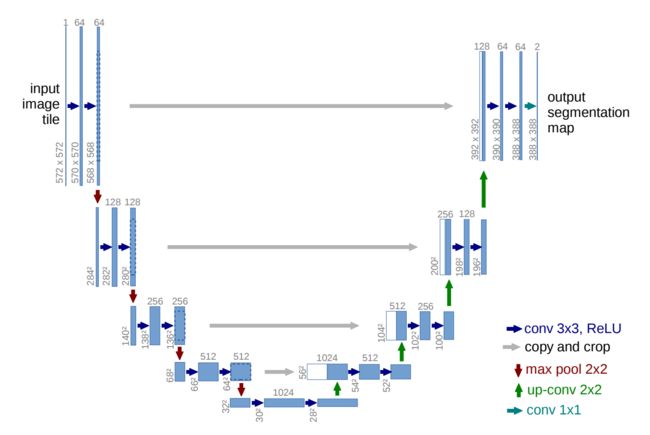
<2>U-Net https://arxiv.org/pdf/1505.04597.pdf
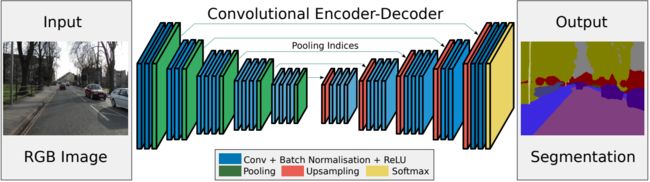
<3>SegNethttps://browse.arxiv.org/pdf/1511.00561.pdf
<4>空洞卷积Dilated Convolutionshttps://browse.arxiv.org/pdf/1511.07122.pdf

<5>DeepLab v1-v3+
v1:https://browse.arxiv.org/pdf/1412.7062v3.pdf
v2:https://browse.arxiv.org/pdf/1606.00915.pdf
v3:https://browse.arxiv.org/pdf/1706.05587.pdf
v3+:https://browse.arxiv.org/pdf/1802.02611.pdf

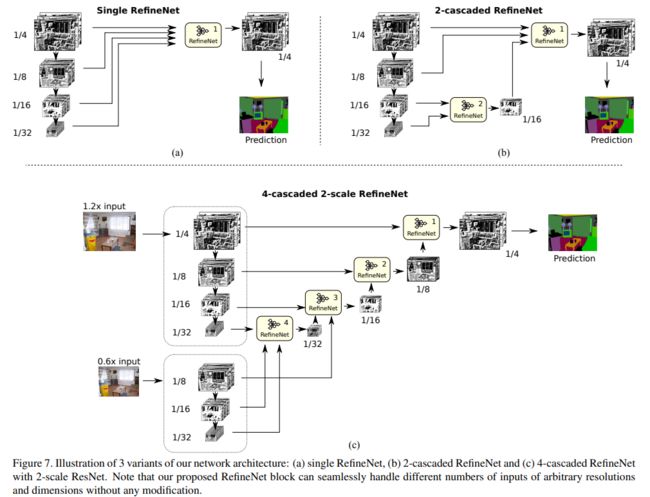
<6>RefineNethttps://browse.arxiv.org/pdf/1611.06612.pdf
<7>PSPNet(Pyramid Scene Parsing Network)https://browse.arxiv.org/pdf/1612.01105.pdf
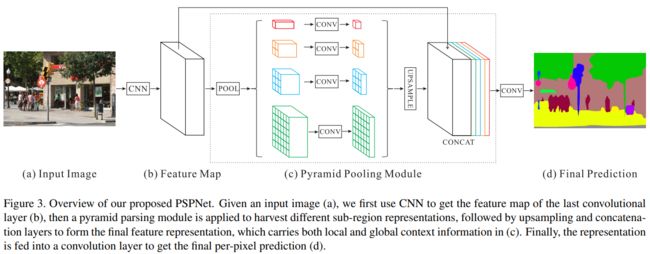
2.实例分割
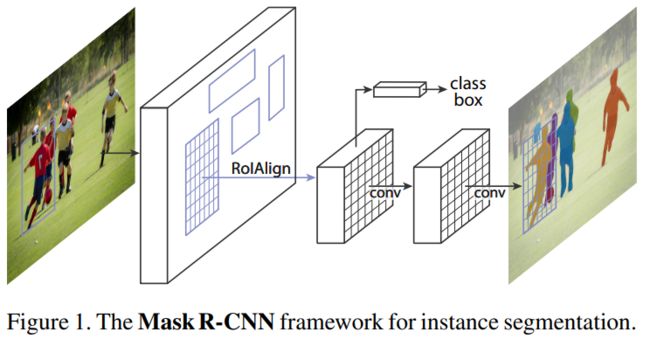
<1>两阶段Mask R-CNNhttps://browse.arxiv.org/pdf/1703.06870.pdf
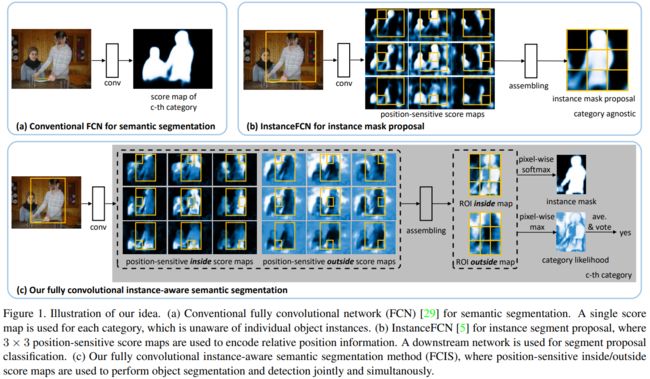
<2>Instance-sensitive FCNhttps://browse.arxiv.org/pdf/1603.08678.pdf

<3>FCIShttps://browse.arxiv.org/pdf/1611.07709.pdf
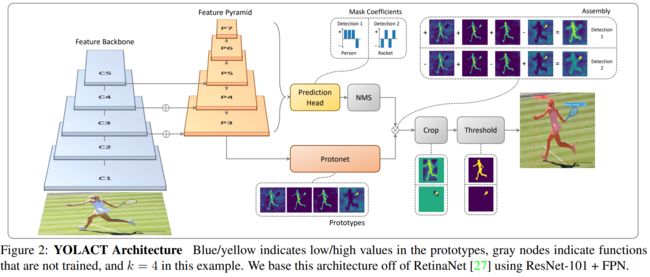
<4>YOLACT: Real-time Instance Segmentationhttps://browse.arxiv.org/pdf/1904.02689v2.pdf
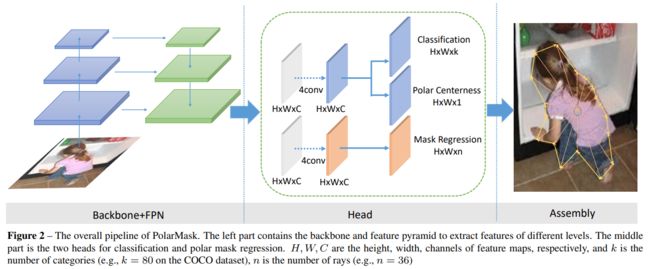
<5>PolarMaskhttps://browse.arxiv.org/pdf/1909.13226.pdf
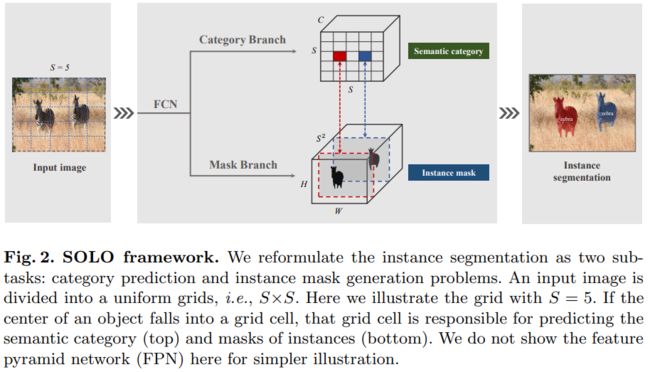
<6>SOLO: Segmenting Objects by Locationshttps://browse.arxiv.org/pdf/1912.04488.pdf
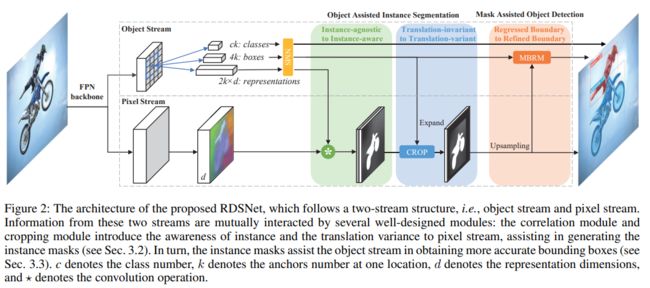
<7>RDSNethttps://browse.arxiv.org/pdf/1912.05070.pdf
<8>PointRendhttps://browse.arxiv.org/pdf/1912.08193.pdf

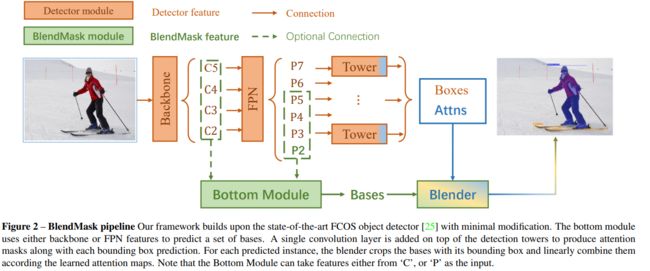
<9>BlendMaskhttps://browse.arxiv.org/pdf/2001.00309.pdf