Background
这篇文章想解决的问题是复杂场景的布局生成
1. 复杂场景可以理解为由较小的“原子”构成,生成一个好的布局需要对这些原子之间的关系有非常好的理解。
2. 引言中提到了认知科学的概念,对于一个场景有“感知”和“理解”,感知是浅层的,理解是深层的,比如天空在地的上方,马不会骑车。在合成场景中,有两个关键因素即 layout 和 appearance,只有这两个因素都好生成的场景才好。(说了一大堆造了一个setting,最后开源的代码还是合成二维的布局,3D的代码(partnet, 3d-front)不开源,COCO的代码有问题,这是允许的吗?...)
3. 引出了layout重要性之后,作者表示一个场景的layout可以用一个无序的几何“原子”集合来表示。原子可以是什么?primitives can be bounding boxes from discrete classes such as ‘text’, ‘image’, or ‘caption’, and in case of 3D objects, primitives can be 3D occupancy grids of parts of the object such as ‘arm’, ‘leg’, or ‘back’ in case of chairs.
4. 作者提到他们的模型是自回归的,能够从前面的原子的信息预测下一个原子的属性。
Motivation
这篇文章和我们分享的上一篇论文一样,也不是对于某一个缺陷的改进,研究动机就是在多个领域(3D,2D)生成Layout。
Contribution
1. 我们提出了LayoutTransformer,简单但有效。可以自回归地生成新的布局,补全部分布局,以及计算现有布局的(likelihood)?(这是什么)
2. 我们对布局元素的不同属性分别建模,这允许注意力模块更容易集中到关键属性上面去。
3. 我有一个激动人心的发现,我们的模型或许可以成为语义表征任务的代理任务。
4. 多个数据集上实验效果好
Related Works
Grains: Generative re-cursive autoencoders for indoor scenes.
Fast and flexible indoor scene synthesis via deep convolutional generative models.
Planit: Planning and instantiating indoor scenes with relation graph and spatial prior networks.
Deep convolutional priors for indoor scene synthesis.
上面这四个文献是做室内房间布局的俯视图的,他们的输入是房间布局图片,和我们的差距比较大。
Approach
一个Layout是一个全连接的图,每个node对应一个原子,都有结构或语义信息与之相连,这种结构或予以信息可以投影成特征向量。除此之外每个node都有几何信息,几何信息表示为[x, y, w, h]的bbox。他们将原子的语义属性和几何属性都映射到一个相同的维度,然后在开头加上
序列:
,
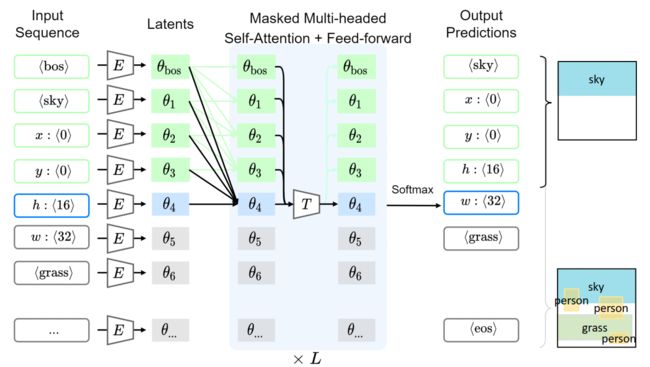
Results
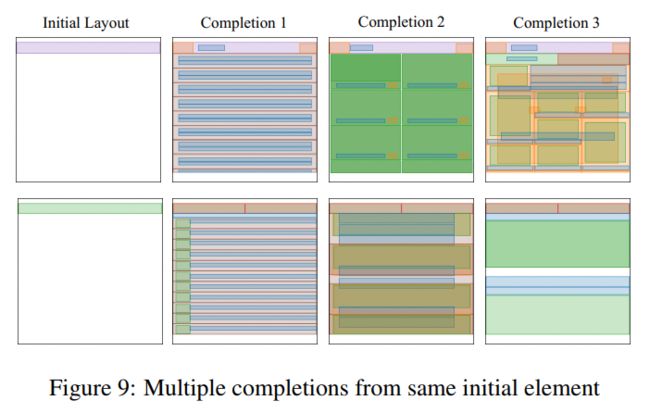
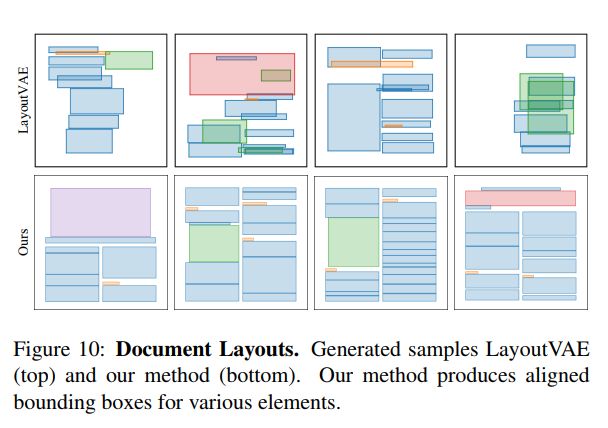
硬伤还是有的,从结果里面可以看到,出现了非常明显的重复模式。。当然重建可能是不错的,但是随机生成新的layout还是问题很大。
我的观点
我认为这篇文章的创新点一个是使用了自注意力模块,一个是做了很多个场景的实验。但是致命的缺陷就是这个自回归的重复模式,真正的布局绝对是不会长这样的。