Apache Ranger的安装及部署
一.Apache Ranger简介
Apache ranger是一个Hadoop集群权限框架,提供操作、监控、管理复杂的数据权限,它提供一个集中的管理机制,管理基于yarn的Hadoop生态圈的所有数据权限。
Apache Ranger可以对Hadoop生态的组件如Hive,Hbase进行细粒度的数据访问控制。通过操作Ranger控制台,管理员可以轻松的通过配置策略来控制用户访问HDFS文件夹、HDFS文件、数据库、表、字段权限。这些策略可以为不同的用户和组来设置,同时权限可与hadoop无缝对接。[1]
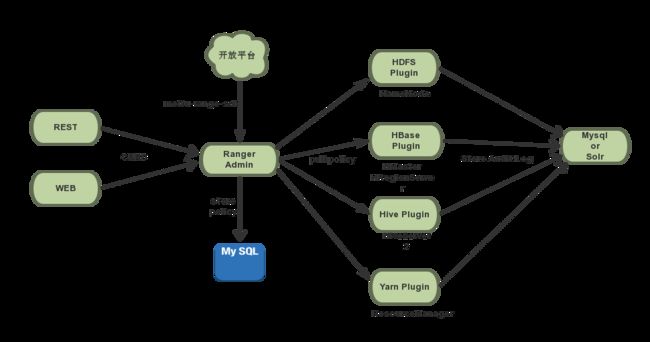
二 Apache Ranger 架构
Apache Ranger架构遵循Admin+Plugin的机构模式,Ranger-Admin以RESTFUL形式提供策略的增删改查接口,同时内置一个Web管理页面。
Plugin低侵入性接入组件中, 以内嵌的方式,并入到各系统执行流程中,定期从RangerAdmin拉取策略,根据策略执行访问决策树(产生的日志记录在组件中),并且记录访问审计.
各插件中的控制节点不同,则安装节点也不一样
| 插件名称 | 安装节点 |
|---|---|
| Hdfs-Plugin | NameNode |
| Hbase-Plugin | HMaster+HRegionServer |
| Hive-Plugin | HiveServer2 |
| Yarn-Plugin | ResourceManager |
三 权限模型
访问权限主要定义了”用户-资源-权限“这三者间的关系,Apache Ranger基于策略来抽象这种关系,进而延伸出自己的权限模型。”用户-资源-权限”的含义详解:
-
用户
由User或Group来表达,User代表访问资源的用户,Group代表用户所属的用户组。
-
资源
不同的组件对应的业务资源是不一样的,比如
- HDFS的FilePath
- HBase的Table,Column-family,Column
- Hive的Database,Table,Column
- Yarn的对应的是Queue
-
权限
由(AllowACL, DenyACL)来表达,类似白名单和黑名单机制,AllowACL用来描述允许访问的情况,DenyACL用来描述拒绝访问的情况,不同的组件对应的权限也是不一样的。插件 权限项 Hdfs Read Write Execute Hbase Read Write Create Admin Hive Select Create Update Drop Alter Index Lock Read Write All Yarn submit-app admin-queue
四 权限实现
Ranger-Admin职责:
- 管理员对于各服务策略进行规划,分配相应的资源给相应的用户或组,存储在db中
Service Plugin职责:
- 定期从RangerAdmin拉取策略
- 根据策略执行访问决策树
- 实时记录访问审计
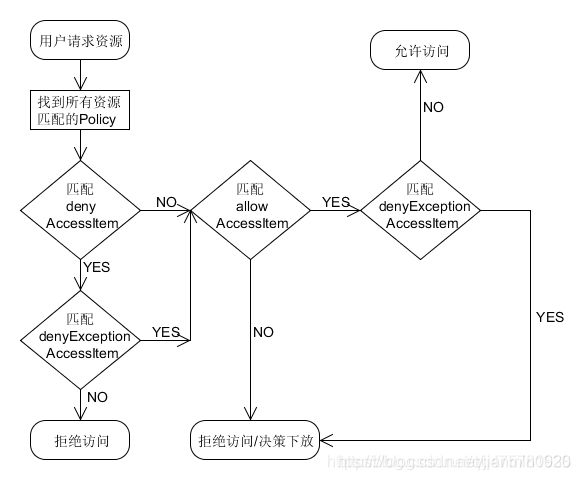
策略执行过程:
[2]
策略优先级:
- 黑名单优先级高于白名单
- 黑名单排除优先级高于黑名单
- 白名单排除优先级高于白名单
决策下放:
如果没有policy能决策访问,一般情况是认为没有权限拒绝访问,然而Ranger还可以选择将决策下放给系统自身的访问控制层
组件集成插件接口
| service | Extensible Interface | Ranger Implement Class |
|---|---|---|
| HDFS | org.apache.hadoop.hdfs.server.namenode.INodeAttributeProvider | org.apache.ranger.authorization.hadoop.RangerHdfsAuthorizer |
| HBASE | org.apache.hadoop.hbase.protobuf.generated.AccessControlProtos.AccessControlService.Interface | org.apache.ranger.authorization.hbase.RangerAuthorizationCoprocessor |
| Hive | org.apache.hadoop.hive.ql.security.authorization.plugin.HiveAuthorizerFactory | org.apache.ranger.authorization.hive.authorizer.RangerHiveAuthorizerFactory |
| YARN | org.apache.hadoop.yarn.security.YarnAuthorizationProvider | org.apache.ranger.authorization.yarn.authorizer.RangerYarnAuthorize |
五 安装(伪分布式环境下安装)
1.确保本机已经安装好了JDK/Maven/Hadoop/Mysql,并配置了环境变量
2.GitHub上下载tar包至本地,并上传至Centos系统中的某个目录中,例如/opt/software
下载地址:https://github.com/apache/ranger
注意一点:下载之前先确认Ranger和其他Apache生态中的组件的相关支持关系,尽可能选择第二波批次更新的版本
也有一些博文提到是通过git的方式获取编译文件,本人亲测,也是可行的
3.解压文件至目录中,进入目录下(例如:cd ranger-2.0,),后执行编译操作,命令为mvn clean compile package assembly:assembly install
注意:(1)编译过程较为漫长,考虑到网络限制等因素,不建议直接在生产环境中的服务器中编译,考虑自行通过VM搭建环境
(2)如果编译过程中出现依赖包确实的问题,多次执行步骤三的命令,无法打包,可以将命令替换为 mvn clear compile install
4. 编译完成后,在本级目录下找到target目录,里面可以找到相应的tar包和zip包

5.将ranger-*-admin.tar.gz包解压至指定的目录中,同时,解压ranger-*-usersync.tar包至指定的目录中,解压 ranger-*-hdfs.tar.gz至指定的目录中
6.修改项目目录下(/opt/install/ranger-2.0.0-admin)的install.properties文件,具体信息可参考如下:
DB_FLAVOR=MYSQL
SQL_CONNECTOR_JAR=/usr/share/java/mysql-connector-java.jar
db_root_user=root
db_root_password=123456
db_host=localhost
db_name=ranger
db_user=root
db_password=123456
rangerAdmin_password=a12345678
rangerTagsync_password=a12345678
rangerUsersync_password=a12345678
keyadmin_password=a12345678
audit_solr_urls=http://*.*.*.*:6083/solr/ranger_audits
policymgr_external_url=http://****:6080
unix_user=hadoop
unix_user_pwd=123456
unix_group=hadoop
修改完毕后,确认mysql中已经 新建了名称为ranger的数据库
7.后执行setup.sh,完成后在/user/bin会出现ranger-admin的文件,在系统任意位置执行ranger-admin start命令,指定后进程名称为EmbeddedServer
8.在本地浏览器中输入 http://主机名或者主机Ip:6080,输入账号 admin 密码 a12345678进入系统中
PS:如果进入不了,则坚持防火墙是否关闭,
如果一直提示无法连接数据库,则查一下mysql服务是否开启
如果仍然无法访问,则进入日志目录下,查看启动信息,目录为/opt/install/ranger-2.0.0-admin/ews/logs
9.ranger整合solr记录审计日志
进入/opt/install/ranger-2.0.0-admin/contrib/solr_for_audit_setup目录下,修改install.properties文件,
JAVA_HOME=/opt/install/jdk1.8.0_251
SOLR_INSTALL_FOLDER=/opt/install/solr-8.6.1
SOLR_RANGER_PORT=6083
SOLR_DEPLOYMENT=standalone
SOLR_RANGER_DATA_FOLDER=/opt/install/solr-8.6.1/ranger_audit_server/data
10 官网上下载solr-8.6.1,并且解压文件至/opt/install/solr-8.6.1
11 返回ranger-*.admin的项目根目录下,再次执行setup.sh命令
12 执行完毕后,在solr的文件下出现ranger_audit_server文件夹,进入该文件中找到install_notes.txt,查看文件,找到如下内容,因此启动solr,必须通过以下命令来实现
To start Solr run: /opt/install/solr-8.6.1/ranger_audit_server/scripts/start_solr.sh
To stop Solr run: /opt/install/solr-8.6.1/ranger_audit_server/scripts/stop_solr.sh
13.为了同步Linux中的用户信息,必须借助usersync的组件,解压和ranger-admin一样,修改install.properties
ranger_base_dir = /opt/install/ranger-2.0.0-usersync
POLICY_MGR_URL =http://****:6080
unix_user=hadoop
unix_group=hadoop
rangerUsersync_password=a12345678
完成以上信息后,执行setup.sh,后再执行ranger-usersync-services.sh 命令,如果出现进程名为UnixAuthenticationService的进程,则说明启动成功
14 hdfs的插件安装
14.1进入解压后的目录,编辑install.properties,具体信息如下:
POLICY_MGR_URL=http://*.*.*.*:6080
NameNodeURL=hdfs://*.*.*.*:9000
REPOSITORY_NAME=hadoopdev
COMPONENT_INSTALL_DIR_NAME=/opt/install/hadoop-3.2.1
CUSTOM_USER=hadoop
CUSTOM_GROUP=hadoop
14.2 将同级下的lib文件复制hdfs的lib包下,例如/opt/install/hadoop-3.2.1/share/hadoop/hdfs/lib,也有博文通过软连接的方式,考虑到版本变更的问题,个人不大建议
14.3 复制完成后,进入hadoop的sbin目录下执行start-all.sh命令,后在本hadoop的环境的目录下/etc/hadoop的hdfs-site.xml中生成如下内容
六 插件验证
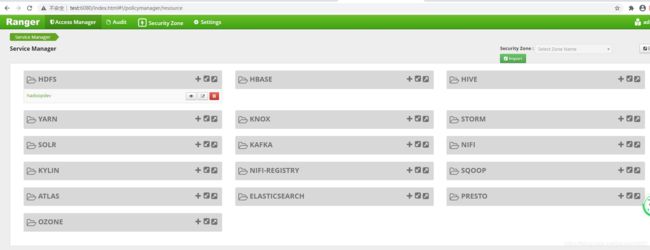
1.添加hdfs服务
进入ranger的WebUI页面中,分别输入账号和密码,进入如下的页面,点击hdfs的右上角加号,
其中service_name必须与install.properties中的仓库名称保持一致
用户名和账号,保持与环境一致
namenodeurl的地址必须与hadoop中的服务地址保持一致
添加完毕,点击test connection,测试是否连接成功
完成后,点击add
2. 服务添加完毕后,再添加策略,点击服务名称,后点击右上角的add policy,进入页面如下
policy-name:自己定义
Resource Path:添加控制的路径和文件名
再添加允许条件和排除条件

3. 添加完毕后,进入/etc/ranger/hadoopdev/policycache,查看最新的策略json文件
4. ranger对于root用户是做条件排除的,因此必须切换相应的用户,同时,文件的所属也需要进行调整,其中文件的所属组和所属用户名,具体命令如下
./hdfs dfs -chgrp -R hadoop /test
./hdfs dfs -chown -R hadoop /test
5.读写和查看的命令,可参考如下:
echo "Hello World" | hdfs dfs -appendToFile - /test/aa.txt
./hdfs dfs -cat /test/aa.txt
其他hdfs命令,可以参考其他文章
如出现拒绝的提示,查阅策略,如能匹配上,则说明策略生效
备注:[1]摘抄自 开源中国 https://www.oschina.net/p/apache+ranger?hmsr=aladdin1e1
[2]摘抄自 CSDN https://blog.csdn.net/qq475781638/article/details/90247153