机器学习实践入门(四):pytorch框架初探
本文参考自深蓝学院课程,所记录笔记,仅供自学记录使用
pytorch框架初探
- 深度学习框架Pytorch简介
-
- 目前流行的深度学习框架
- pytorch 的优势
-
- 简单,与numpy 语法类似
- pytorch只需设计前向传播过程,反向传播过程中梯度自动计算。
- 动态图,方便调试
- pytorch 的基本组成元素
-
- tensor
- 基本运算
-
- Tensor(requires_grad=True) <==>Variable
- nn
- pytorch构建神经网络
-
- Pytorch—数据准备
-
- why use Dataset Dataload?
- How use?
- 案例(MINST)
- module—神经网络
-
- 以LeNet为例
- 以AlexNet为例
- 以上两种网络实现方式对比
- 保存模型
- 学习率
深度学习框架Pytorch简介
目前流行的深度学习框架

目前流行的就是tensorflow(google)、以及pytorch(facebook)
目前深度学习主要用于 音(音频信号处理) 图 (CV)语(NLP)
音频方面:kaldi 、pytroch 用的较多
CV:pytorch 越来越多
NLP: tensorflow和pytorch
Caffe(之前是UC Berkeley的一个大佬写的) 升级到了 Caffe2 ,主要用于工业等领域
torch (主要基于C lua 等语言 )升级到了 pytorch
在Pytorch 1.0的时候,把Caffe2和torch进行合并
pytorch 的优势
简单,与numpy 语法类似
NumPy(Numerical Python的缩写)是一个开源的Python科学计算库。使用NumPy,就可以很自然地使用数组和矩阵
NumPy包含很多实用的数学函数,涵盖线性代数运算、傅里叶变换和随机数生成等功能。

可以看到以上两端代码分别用numpy与pytorch 实现反向传播过程,但是pytorch更简洁
pytorch只需设计前向传播过程,反向传播过程中梯度自动计算。
对于每一个中间数据,记录其产生的方式,用于反向传播中计算梯度
pytorch 存储数据的数据格式非常特殊,采用以下结构存储数据,这种数据格式会将数据是怎样产生的记录下来,下次反向传播的时候会自动记录。

动态图,方便调试
- PyTorch动态构建神经网络,执行到代码位置, 才开始构建这句代码所描述的网络节点, 然后把这一节点挂在计算图上。 可以让用户在动态改变神经网络时,不产生任何滞后和开销。它直观, 精简, 极度灵活。 缺点也非常明显,那就是运行效率和开销。
- Tensorflow、Caffe都采用静态构建方式。用户需要先构建神经网络结构,然后在给定的结构上填入数据,再进行一次又一次的运行。能够对预先定义的网络进行多种优化处理,从而运行的更高效。但缺点也非常明显,即不够灵活,而且被优化后的网络,对用户不友好,调试时难以轻松知道程序的状态, 而且一旦用户想要根据计算的状态,动态的修改神经网络结构,那么实现起来会非常困难。
- PyTorch这一工具的定位: 帮助科研人员和工程师, 快速探索和调整模型, 快速构建实验,更适合从0到1的创新工作, 而静态图Tensorflow,更适合已经有了模型, 我们要运用到某些高强度的训练和测试的应用环境下。更适合工业应用。
pytorch 的基本组成元素
- Tensor: 基本数据单元,多维数组(相当于其他编程语言中的基本数据类型,int double等等,只有数据)
- Variable:等同于带有梯度的Tensor(除了数据,加了梯度)
- nn: 卷积、池化、激活函数等层的实现
- Module: 网络结构,包含一系列Tensor和nn的计算过程
Pytorch > = 0.4版本中,将Variable与Tensor合并
Tensor:x = torch.ones(2, 2, requires_grad=False)
Variable:x = torch.ones(2, 2, requires_grad=True)
根据是否需要梯度,数据的存储格式将变成如下两种

tensor
tensor 用于网络基本的数据单元,
用于生成网络输入、输出、参数、中间变量等等
p 初始化:
torch.tensor((k*k*k…), dtype=torch.float)
torch.from_numpy(**)
torch.zero((k*k*k…)) # 初始化元素为0
torch.eye(k) # 初始化对角矩阵
torch.ones((k*k*k…)) # 初始化元素为1
torch.rand(k*k*k…) #随机初始化[0,1]
torch.randn(k*k*k…) #随机初始化, 0-均值 1-方差
data.cuda() #cpu转gp
以下是tonsor 对应的数据类型(和 numpy 的dtype 差不多)

基本运算
加减乘除:逐点操作
矩阵乘:data1.mm(data2)
数据维度:size(), reshape(), view(), squeeze, unsqueeze
转置:transpose,permute
实例
import torch
aa=torch.ones(3,3);
print(aa)
aa.requires_grad # 查看默认是否带梯度,不带
torch.__version__ # 因为 版本大于 0.4, tensor和grad 合并了
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
'1.12.1'
aa=torch.ones(3,3,requires_grad=True)
print(aa.grad)# 由于这里还没有反向传播的过程所以还是 none,还没启动
print(aa.requires_grad)
print(aa.type()) # 查看类型
aa=aa.int() # 转成int型 和nunmpy操作差不多
print(aa.type())
aa= aa.cuda() # 将数据转到 gpu上,需要安装gpu版本的 pytorch ctrl shift + P
print(aa.type())
None
True
torch.FloatTensor
torch.IntTensor
torch.cuda.IntTensor
print(aa.size())
# 3*3 -> 1*3*3
aa=aa.unsqueeze(0) # 在零度插一维
print(aa.size())
# 1*3*3 -> 1*3*1*3
aa=aa.unsqueeze(2)
print(aa.size())
aa=aa.squeeze() #将默认是一维的去除,算是维度上的一种压缩
print(aa.size())
torch.Size([3, 3])
torch.Size([1, 3, 3])
torch.Size([1, 3, 1, 3])
torch.Size([3, 3])
很多函数不用死记硬背仅需在 pytorch.doc 中查找即可
特别要注意搜索的时候,因为pytorch 很多版本的函数略有不同,用法也不同,所以搜索前先选择pytorch的版本。

Tensor(requires_grad=True) <==>Variable
举例
产生一个带梯度的 tensor ,也即 Variable
x=torch.ones(2,2,requires_grad=True)
print(x)
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
y=x+2
z=y**2
out=z.mean()
print(y)
print(z)
print(out)
tensor([[3., 3.],
[3., 3.]], grad_fn=)
tensor([[9., 9.],
[9., 9.]], grad_fn=)
tensor(9., grad_fn=)
可以看到,后面显示了一个 grad_fn 这个元素,这其实就是前面图例中的creator,它记录了这个变量是怎样产生的,方便后续反向传播时利用。
out.backward() # 反向传播
print(x.grad)
tensor([[1.5000, 1.5000],
[1.5000, 1.5000]])
这个1.5 是怎么来的呢,可以试着计算看看。

如果想打印 y的梯度会报错,这是因为,pytorch 为了节省内存只会计算“叶子节点”梯度,
如果实在想要计算 y的梯度,只需在定义y时在下面添加一句,这会保留梯度
y.retain_grad()
nn
nn 是 pytorch使用之前的 tensor等基本元素实现 神经网络的过程。
利用nn能够轻易的实现 神经网络中基本的一些层,比如卷积层,池化层,激活层等
创建方式
- 方式一(Module):
• torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True) • torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False) • torch.nn.AvePool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False) • torch.nn.ReLU(inplace=False) • torch.nn.Sequential() - 方式二(Function):
• torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
• torch.nn.functional.relu(input, inplace=False) - 区别
• Function一般只定义一个操作,因为其无法保存参数,因此适用于激活函数、pooling等操作;Module是保存了参数,因此适合于定义一层,如线性层,
卷积层,也适用于定义一个网络
• Function需要定义三个方法:init, forward, backward(需要自己写求导公式);Module:只需定义__init__和forward,而backward的计算由自动
求导机制构成
• Module是由一系列Function组成,因此其在forward的过程中,Function和Variable组成了计算图,在backward时,只需调用Function的backward就得到结果,因此Module不需要再定义backward。
• Module不仅包括了Function,还包括了对应的参数,以及其他函数与变量,这是Function所不具备的
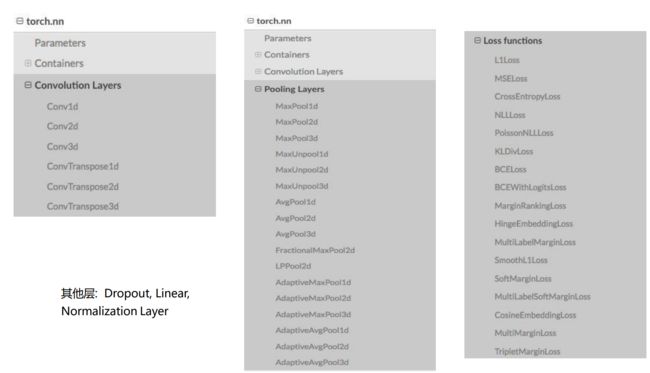
这里展示了torch.nn 中其他层
pytorch构建神经网络
由于pytorch已经为我们准备好了计算反向传播的过程,所以不必再写复杂的反向传播过程

具体来说,准备些的东西只需要:
- 准备数据:Dataset+DataLoader
- 网络设计:torch.nn.module
- 损失函数:torch.nn.CrossEntropyLoss, torch.nn.MSELoss
- 参数更新:torch.optim
optimizer = optim.SGD(net.parameters(), lr=args.lr, momentum=0.9, weight_decay=1e-4)
Pytorch—数据准备
why use Dataset Dataload?
• 可以快速、提前提取数据到内存中
• 提供框架,只需写核心函数
• 提供多种数据曾广支持
以一个例子介绍传统训练的大致流程
(以下代码不能运行,只是简单介绍)
import torch
N, D_in, H, D_out = 64, 1000, 100, 10
# 首先定义网络的输入,以及网络输出对应的标签
x = torch.randn((N, D_in), requires_grad=True)
y = torch.randn((N, D_out), requires_grad=False)
## 定义网络结构
model = torch.nn.Sequential(torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out))
## 定义损失函数(这里相当于欧氏距离)
loss_fn = torch.nn.MSELoss(reduction='sum')
learning_rate = 1e-4
# 模型训练过程
for t in range(500):
# 进入训练
y_pred = model(x)
# 计算损失
loss = loss_fn(y_pred, y)
print(loss)
# 计算梯度
model.zero_grad()
loss.backward()
# 更新参数
for param in model.parameters():
param.data -= learning_rate * param.grad.data
训练时,数据非常占内存,如果用for循环以循环的方式不停的读取,那么将会非常耗时间
可以通过pytorch的Dataset+DataLoader的方式提前把数据存入内存/显存当中。
How use?
class MyDataset(data.Dataset):
def __init__(self, dataname, transform=None):
# 初始化:数据位置、输入大小
def __getitem__(self, index):
# 提取一对数据
def __len__(self):
# 总共提取的个数
def collate_fn(self, batch):
# 包装成pytorch 网络输入
dataset = MyDataset()
dataloader = torch.utils.data.DataLoader(dataset, batch_size=8,\
shuffle=False, num_workers=1)
for epoch in range(max_epoch):
for idx, (data, lebel) in enumerate(dataloader):
...
dataset类里面有几个关键的子函数,
1、_init_
初始化函数
2、 _getitem_
比较关键,用于提取出数据对
此外还要接收index参数
3、_len_ 总共提取的数据个数,一共多少对
4、_collate_fn
因为一般提取数据都是numpy的格式,训练时需要转成torch格式,
此外,一般训练是按照一个batch 一个batch的训练,而 _getitem_ 提取的都是数据对,所以还要进行一定程度的拼接
这些子函数完成之后就可以利用自己的Dataset类创建实例,然后将实例送到DataLoader 当中,DataLoader 读取到内存中(一般Dataset需要自己重写,DataLoader可以直接调用系统的)
案例(MINST)
注:以下只摘录了代码的部分
class MNIST(data.Dataset):
## 初始化函数
def __init__(self, root, train=True, transform=None, target_transform=None, download=False):
# 数据存放位置
self.root = os.path.expanduser(root)
# 数据增广用的什么方式?
self.transform = transform
self.target_transform = target_transform
self.train = train # training set or test set
# 如果本地没有数据是否需要下载
if download:
self.download()
if not self._check_exists():
raise RuntimeError('Dataset not found.' +
' You can use download=True to download it')
if self.train:
data_file = self.training_file
else:
data_file = self.test_file
# 读取数据以及对应的标签
self.data, self.targets = torch.load(os.path.join(self.processed_folder, data_file))
## 获取数据对
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
img, target = self.data[index], int(self.targets[index])
# doing this so that it is consistent with all other datasets
# to return a PIL Image
# 这里显示把数据转成了numpy矩阵 又转成了图像,作用主要进行数据增广 具体方式可以在调用中看到,一是将数据转成Tensor 形式,而是将数据归一化,
img = Image.fromarray(img.numpy(), mode='L')
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
def __len__(self):
return len(self.data)
module—神经网络
-
Module 是 pytorch 提供的一个基类,每次我们要 搭建 自己的神经网络的时候都要继承这个类
-
主要函数:
• def init(self): #初始化网络所用的神经网络层
• def forward(self, x): #网络的前向过程
• def backward(self, x): #自动计算 -
实例展示(lenet,vgg,resnet)
以LeNet为例
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
# 卷积 、池化 激活
x = F.relu(F.max_pool2d(self.conv1(x), 2))
# 卷积 池化 激活
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
# 将N*C*H*W 转成二维 N*CHW
x = x.view(-1, 320)
# 全连接层 # NC
x = F.relu(self.fc1(x))
# dropout层帮助网络正则化
x = F.dropout(x, training=self.training)
# 全连接层
# N*10
x = self.fc2(x)
# 输出经过softmax
return F.log_softmax(x, dim=1)
以AlexNet为例
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
__all__ = ['AlexNet', 'alexnet']
model_urls = {
'alexnet': 'https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth',
}
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
# 下面调用了组件函数,Sequential,相当于答下面这些曾合并成了一个函数来表示
self.features = nn.Sequential(
#
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
def alexnet(pretrained=False, **kwargs):
r"""AlexNet model architecture from the
`"One weird trick..." `_ paper.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = AlexNet(**kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['alexnet']))
return model
以上两种网络实现方式对比
会发现LeNet的激活函数(relu)是调用 nn.functional 来创建的,
AlexNet 的激活函数是使用nn module 来实现
如果是调用 nn 来实现,需要在初始中进行定义,对其中详细的参数进行定义
nn.ReLU(inplace=True),
如果是调用 nn.functional
就可以直接直接使用
x = F.relu(self.fc1(x))
保存模型
一般保存成字典的形式
torch.save()
学习率
见官方文档,
torch.optim.lr_scheduler
其中最常用 stepLR