【CVPR 2023】 All are Worth Words: A ViT Backbone for Diffusion Models
All are Worth Words: A ViT Backbone for Diffusion Models, CVPR 2023
论文:https://arxiv.org/abs/2209.12152
代码:https://github.com/baofff/U-ViT
解读:U-ViT: A ViT Backbone for Diffusion Models - 知乎 (zhihu.com)
All are Worth Words : A ViT Backbone for Diffusion Models_通街市密人有的博客-CSDN博客
摘要
文中首次使用U-Net建模score-based model (即diffusion model),后续DDPM ,ADM ,Imagen 等许多工作对U-Net进行了一系列改进。目前,绝大多数扩散概率模型的论文依然使用U-Net作为主干网络。
ViT在各种视觉任务中显示出了前景,而基于CNN的U-Net在扩散模型中仍然占主导地位。论文设计了一种简单通用的基于ViT的架构(命名为U-ViT),用于使用扩散模型生成图像。U-ViT的特征是将包括时间、条件和噪声图像块在内的所有输入视为令牌,并在浅层和深层之间使用长跳跃连接。本文在无条件和类条件图像生成以及文本到图像生成任务中评估U-ViT,其中U-ViT即使不优于类似大小的基于CNN的U-Net,也具有可比性。特别是,在生成模型的训练过程中,在没有访问大型外部数据集的方法中,具有U-ViT的潜在扩散模型在ImageNet 256×256上的类条件图像生成中实现了2.29的FID得分,在MS-COCO上的文本到图像生成中达到了5.48的FID得分。实验结果表明,对于基于扩散的图像建模,长跳跃连接是至关重要的,而基于CNN的U-Net中的下采样和上采样算子并不总是必要的。
U-ViT网络结构
网络结构
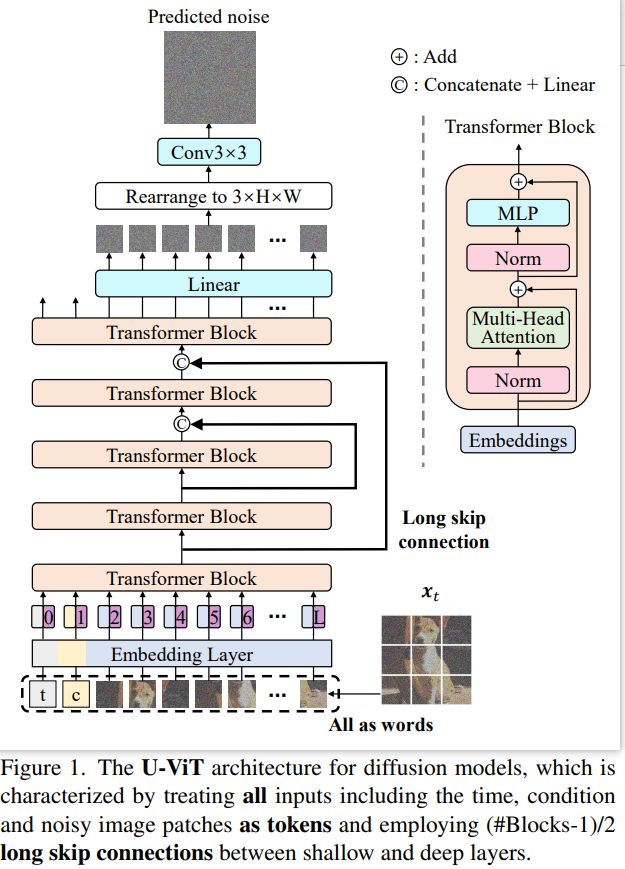
U-ViT是图像生成中扩散模型的一个简单通用的主干,延续了ViT的方法,将带噪图片划分为多个patch之后,将时间t,条件c,和图像patch视作token输入到Transformer block,同时在网络浅层和深层之间引入long skip connection,可选地在输出之前添加一个3×3卷积块。
网络细节
对U-ViT中的关键因素进行了系统的实证研究。在CIFAR10[36]上进行消融,在10K生成的样本上每50K训练迭代评估FID得分,并确定默认实现细节。

The way to combine the long skip branch
组合长跳跃分支的方法。直观上理解,扩散概率模型中的噪声预测网络是像素级别的预测任务,对low-level feature敏感,long skip connection为连接low-level feature提供了快捷方式,所以有助于网络的训练。 对于网络主分支的特征![]() 和来自long skip connection的特征
和来自long skip connection的特征 ![]() ,其中B为batch_size,L为token 数目,D为每一个token的长度。作者探究了以下5种融合
,其中B为batch_size,L为token 数目,D为每一个token的长度。作者探究了以下5种融合 ![]() 的方式。
的方式。
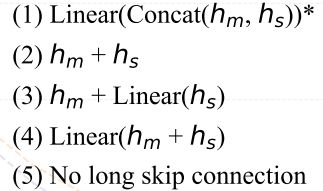
long skip connection对于图像生成的FID分数是至关重要的。第(1)种方式最好。

The way to feed the time into the network
将时间输入网络的方式。考虑了两种将t输入网络的方法。
(1) 将其视为令牌token,如图1所示。
(2) 将层归一化后的时间合并到transformer块中,类似于U-Net中使用的自适应组归一化。
将时间视为令牌的第一种方式比AdaLN表现得更好。

The way to add an extra convolutional block after the transformer
在transformer块之后添加额外卷积块的方法。考虑两种方法在transformer块之后添加额外的卷积块。
(1) 在线性投影后添加一个3×3卷积块,将标记嵌入映射到图像块,如图1所示。
(2) 在该线性投影之前添加一个3×3卷积块,该块需要首先将令牌嵌入的1D序列![]() 重新排列为形状为
重新排列为形状为 ![]() 的2D特征,其中P是patch大小。
的2D特征,其中P是patch大小。
(3) 与丢弃额外卷积块的情况进行比较。
在线性投影后添加3×3卷积块的第一种方法的性能略好于其他两种选择。

Variants of the patch embedding
patch嵌入的变体。考虑了patch嵌入的两种变体。
(1) 原始patch嵌入采用线性投影,将patch映射到令牌嵌入。
(2)使用3×3卷积块的堆栈,然后是1×1卷积块,将图像映射到令牌嵌入。
原始的patch嵌入表现更好。

Variants of the position embedding
位置嵌入的变体。考虑位置嵌入的两种变体。
(1) 在原始ViT中提出的一维可学习位置嵌入,本文的默认设置。
(2) 二维正弦位置嵌入,它是通过级联位置(i,j)处的patch的i和j的正弦嵌入而获得的。
一维可学习位置嵌入表现更好。
深度、宽度和patch大小的影响
通过研究深度(即层数)、宽度(即隐藏层大小D)和patch大小对CIFAR10的影响,展示了U-ViT的缩放性。随着深度(即层数)从9增加到13,性能有所提高。尽管如此,UViT并没有像50K训练迭代中的17次那样从更大的深度中获益。类似地,将宽度(即隐藏层大小)从256增加到512可以提高性能,并且进一步增加到768不会带来增益;将patch大小从8减小到2提高了性能,并且进一步减小到1不会带来增益。请注意,要获得良好的性能,需要像2这样的小patch大小。假设这是因为扩散模型中的噪声预测任务是低级别的,需要小patch,不同于高级别的任务(例如分类)。由于使用小的patch大小对于高分辨率图像来说是昂贵的,首先将它们转换为低维潜在表示[54],并使用U-ViT对这些潜在表示进行建模。
实验
设置
数据集。对于无条件学习,考虑包含50K训练图像的CIFAR10和包含162770张人脸训练图像的CelebA 64×64。对于类条件学习,考虑64×64、256×256和512×512分辨率的ImageNet[12],它包含来自1K个不同类的1281167个训练图像。对于文本到图像学习,我们考虑256×256分辨率的MS-COCO[40],其中包含82783个训练图像和40504个验证图像。每张图片都有5个图像标注。
高分辨率图像生成。对于256×256和512×512分辨率的图像,遵循潜在扩散模型(LDM)。首先使用Stable Diffusion2[54]提供的预训练图像自编码器,将它们分别转换为32×32和64×64分辨率的潜在表示。然后,使用所提出的U-ViT对这些潜在的表示进行建模。
文本到图像学习。在MS-COCO上,使用稳定扩散之后的CLIP文本编码器将离散文本转换为嵌入序列。然后将这些嵌入作为令牌序列馈送到U-ViT中。
训练。使用AdamW优化器,所有数据集的权重衰减为0.3。对大多数数据集使用2e-4的学习率,除ImageNet 64×64使用3e-4。在CIFAR10和CelebA 64×64上训练了500K次迭代,批量大小为128。在ImageNet 64×64和ImageNet 256×256上训练300K迭代,在ImageNet 512* 512上训练500K迭代,批量大小为1024。在batchsize=256的MS-COCO上训练1M次迭代。
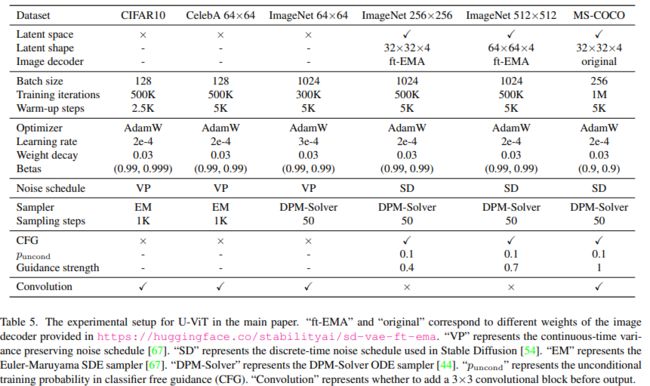
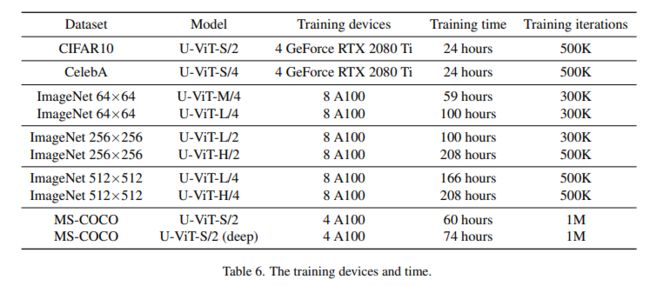
U-ViT配置变体

无条件和类条件图像生成
将U-ViT与基于U-Net的先验扩散模型进行了比较。还与GenViT进行了比较,后者是一种较小的ViT,不使用长跳跃连接,并包含了标准化层之前的时间。如表1所示,U-ViT在无条件CIFAR10和CelebA 64×64上与U-Net相当,同时性能远优于GenViT。

表3进一步表明,在使用相同采样器的不同采样步骤下,U-ViT优于LDM。请注意,U-ViT也优于VQ-Diffusion,后者是一种离散扩散模型[1],采用transformer作为主干。

在图4中,在ImageNet 256×256和ImageNet 512×512上提供了选定的样本,在其他数据集上提供了随机样本,这些样本具有良好的质量和清晰的语义。
MS-COCO上的文本到图像生成
在标准基准数据集MS-COCO上评估了用于文本到图像生成的U-ViT。
如表4所示,U-ViT-S在生成模型的训练过程中,在不访问大型外部数据集的情况下,已经在方法中实现了最先进的FID。通过将层数从13层进一步增加到17层,U-ViT-S(Deep)甚至可以实现5.48的更好FID。
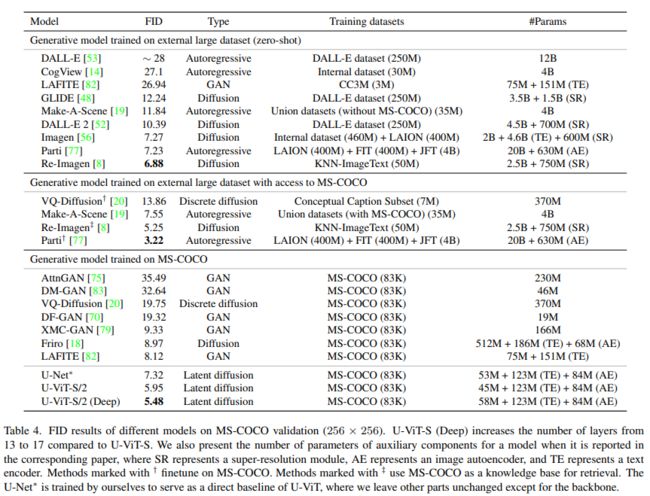
图6显示了使用相同随机种子生成的U-Net和U-ViT样本,以进行公平比较。发现U-ViT生成了更多高质量的样本,同时语义与文本匹配得更好。例如,给定文本“棒球运动员向球挥动球棒”,U-Net既不会生成球棒也不会生成球。相比之下,我们的U-ViT-S生成的球具有更少的参数,而我们的U-ViT-S(Deep)进一步生成击球。我们假设这是因为文本和图像在U-ViT的每一层都有交互,这比只在跨越注意力层交互的U-Net更频繁。