All are Worth Words : A ViT Backbone for Diffusion Models
All are Worth Words: A ViT Backbone for Diffusion Models—CVPR2023

论文地址:https://arxiv.org/abs/2209.12152
项目地址:https://github.com/baofff/U-ViT
Abstract
视觉transformer(ViT)在各种视觉任务中显示出了前景,而基于卷积神经网络(CNN)的U-Net在扩散模型中仍然占主导地位。我们设计了一种简单通用的基于ViT的架构(命名为U-ViT),用于使用扩散模型生成图像。U-ViT的特征是将包括时间、条件和噪声图像块在内的所有输入视为令牌,并在浅层和深层之间使用长跳跃连接。我们在无条件和类条件图像生成以及文本到图像生成任务中评估U-ViT,其中U-ViT即使不优于类似大小的基于CNN的U-Net,也具有可比性。特别是,在生成模型的训练过程中,在没有访问大型外部数据集的方法中,具有U-ViT的潜在扩散模型在ImageNet 256×256上的类条件图像生成中实现了2.29的FID得分,在MS-COCO上的文本到图像生成中达到了5.48的FID得分。
我们的结果表明,对于基于扩散的图像建模,长跳跃连接是至关重要的,而基于CNN的U-Net中的下采样和上采样算子并不总是必要的。我们相信U-ViT可以为未来对扩散模型中骨干的研究提供见解,并在大规模跨模态数据集上进行有竞争力的生成建模。
1. Introduction
扩散模型[25,62,67]是最近出现的用于高质量图像生成的强大的深度生成模型[13,26,54]。它们增长迅速,并在文本到图像生成中找到了应用[52,54,56],图像到图像生成[10,45,80]、视频生成[24,28]、语音合成[6,34]和3D合成[50]。
随着算法[2,3,15,25,33,43,44,49,63,64,67,71]的发展,主干的革命在扩散模型中发挥着核心作用。一个代表性的例子是基于先前工作[25,65]中使用的卷积神经网络(CNN)的U-Net。基于CNN的UNet的特征是一组下采样块、一组上采样块以及两组之间的长跳跃连接,这主导了图像生成任务的扩散模型[13,52,54,56]。另一方面,视觉transformer(ViT)[16]在各种视觉任务中显示出了前景,其中ViT与基于CNN的方法相当甚至优于[9,21,38,68,81]。因此,一个非常自然的问题出现了:在扩散模型中,是否有必要依赖基于CNN的U-Net?
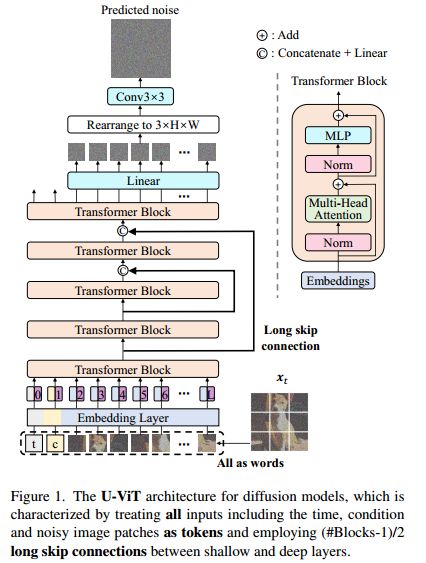
在本文中,我们设计了一种简单通用的基于ViT的架构,称为U-ViT(图1)。根据transformer的设计方法,U-ViT将所有输入(包括时间、条件和噪声图像patch)视为令牌。至关重要的是,U-ViT在浅层和深层之间采用了受U-Net启发的长跳跃连接。直观地,低级特征对于扩散模型中的像素级预测目标是重要的,并且这种连接可以简化相应预测网络的训练。此外,U-ViT可选地在输出之前添加额外的3×3卷积块,以获得更好的视觉质量。参见图2中所有组件的系统消融研究。
我们在三个流行的任务中评估U-ViT:无条件图像生成、类条件图像生成和文本到图像生成。在所有设置中,U-ViT即使不优于类似规模的基于CNN的U-Net,也具有可比性。特别是,在生成模型的训练过程中,在没有访问大型外部数据集的方法中,具有U-ViT的潜在扩散模型在ImageNet 256×256上的类条件图像生成中实现了2.29的FID得分,在MS-COCO上的文本到图像生成中达到了5.48的FID得分。
我们的结果表明,长跳跃连接是至关重要的,而基于CNN的U-Net中的下/上采样操作对于图像扩散模型并不总是必要的。我们相信U-ViT可以为未来在大规模跨模态数据集上进行扩散模型主干和效果生成建模的研究提供见解。
2. Background
扩散模型[25,62,67]逐渐将噪声注入数据,然后反向传播这一过程,从噪声中生成数据。噪声注入过程,也称为正向过程,被形式化为马尔可夫链:
q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q(\boldsymbol{x}_{1:T}|\boldsymbol{x}_0)=\prod\limits_{t=1}^T q(\boldsymbol{x}_t|\boldsymbol{x}_{t-1}) q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
这里 x 0 x_0 x0是数据, q ( x t ∣ x t − 1 ) = N ( x t ∣ α t x t − 1 , β t I ) q(x_t|x_{t−1})=\mathcal{N}(\boldsymbol{x}_{t}|\sqrt{\alpha_{t}}\boldsymbol{x}_{t-1},\beta_{t}I) q(xt∣xt−1)=N(xt∣αtxt−1,βtI), α t \alpha_t αt和 β t \beta_t βt表示噪声计划,使得 α t + β t = 1 \alpha_t+\beta_t=1 αt+βt=1。为了反向传播这一过程,高斯模型 p ( x t − 1 ∣ x t ) = N ( x t − 1 ∣ μ t ( x t ) , σ t 2 I ) p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t)=\mathcal{N}(\boldsymbol{x}_{t-1}|\boldsymbol{\mu}_t(\boldsymbol{x}_t),\sigma_t^2\boldsymbol{I}) p(xt−1∣xt)=N(xt−1∣μt(xt),σt2I)来近似基本事实反向跃迁 q ( x t − 1 ∣ x t ) q(x_{t−1}|x_t) q(xt−1∣xt),最优平均值[3]为
μ t ∗ ( x t ) = 1 α t ( x t − β t 1 − α ‾ t E [ ϵ ∣ x t ] ) \mu_t^*(\boldsymbol{x}_t)=\frac{1}{\sqrt{\alpha_t}}\left(\boldsymbol{x}_t-\frac{\beta_t}{\sqrt{1-\overline{\alpha}_t}}\mathbb{E}[\boldsymbol{\epsilon}|\boldsymbol{x}_t]\right) μt∗(xt)=αt1(xt−1−αtβtE[ϵ∣xt])
这里, α ‾ t = ∏ i = 1 t α i \overline{\alpha}_t=\prod_{i=1}^t\alpha_i αt=∏i=1tαi,并且是注入到 x t x_t xt的标准高斯噪声。因此,该学习等效于噪声预测任务。形式上,通过最小化噪声预测目标,即 E t , x 0 , ϵ ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 2 \mathbb{E}_{t,x_{0},\epsilon}\|\epsilon-\epsilon_{\theta}(x_{t},t)\|_{2}^{2} Et,x0,ϵ∥ϵ−ϵθ(xt,t)∥22,采用噪声预测网络 ϵ θ ( x t , t ) \boldsymbol{\epsilon_{\boldsymbol{\theta}}}(\boldsymbol{x}_{t},t) ϵθ(xt,t)来学习 E [ ϵ ∣ x t ] \mathbb{E}[\epsilon|x_t] E[ϵ∣xt],其中 t t t在1和 T T T之间是一致的。为了学习条件扩散模型,例如类条件[13]或文本到图像[52]模型,条件信息被进一步馈送到噪声预测目标中:
min θ E t , x 0 , c , ϵ ∥ ϵ − ϵ θ ( x t , t , c ) ∥ 2 2 (1) \underset{\theta}{\min}\mathbb{E}_{t,x_0,c,\epsilon}\|\epsilon-\epsilon_\theta(\boldsymbol{x}_t,t,c)\|_2^2 \tag{1} θminEt,x0,c,ϵ∥ϵ−ϵθ(xt,t,c)∥22(1)
其中 c c c是条件或其连续嵌入。在先前的图像建模工作中,扩散模型的成功在很大程度上依赖于基于CNN的U-Net[55,65],这是一种卷积主干,其特征是一组下采样块、一组上采样块和两组之间的长跳跃连接,并且通过自适应组归一化[13]和跨越注意力[54]等机制将 c c c馈送到U-Net中。
视觉transformer(ViT)[16]是一种纯粹的transformer架构,将图像视为一系列标记(单词)。ViT将图像重新排列为一系列扁平的补丁。然后,ViT将可学习的1D位置嵌入添加到这些patch的线性嵌入中,然后将其馈送到transformer编码器[72]。ViT在各种视觉任务中显示出了前景,但尚不清楚它是否适合基于扩散的图像建模。
3. Method
U-ViT是图像生成中扩散模型的一个简单而通用的主干(图1)。特别地,U-ViT将等式(1)中的噪声预测网络 ϵ θ ( x t , t , c ) \boldsymbol{\epsilon_{\boldsymbol{\theta}}}(\boldsymbol{x}_{t},t,c) ϵθ(xt,t,c)参数化。它以时间 t t t、条件 c c c和噪声图像 x t x_t xt作为输入,并预测注入到 x t x_t xt中的噪声。按照ViT的设计方法,图像被分割成patch,U-ViT将包括时间、条件和图像patch在内的所有输入视为令牌(单词)。
受基于CNN的U-Net在扩散模型[65]中的成功启发,U-ViT还在浅层和深层之间采用了类似的长跳跃连接。直观地,公式(1)中的目标是像素级预测任务,并且对低级别特征敏感。长跳跃连接为低级别特征提供了快捷方式,从而简化了噪声预测网络的训练。
此外,U-ViT可选地在输出之前添加一个3×3卷积块。这是为了防止transformer[78]产生的图像中的潜在伪影。根据我们的实验,该块提高了U-ViT生成的样本的视觉质量。
在第3.1节中,我们介绍了U-ViT的实施细节。在第3.2节中,我们通过研究深度、宽度和patch大小的影响,展示了U-ViT的缩放性。
3.1 实现细节
尽管U-ViT在概念上很简单,但我们仔细设计了它的实现。为此,我们对U-ViT中的关键因素进行了系统的实证研究。特别是,我们在CIFAR10[36]上进行消融,在10K生成的样本上每50K训练迭代评估FID得分[23](而不是效率方面的50K样本),并确定默认实现细节。

组合长跳跃分支的方法。 让 h m , h s ∈ R L × D \boldsymbol{h}_{m},\boldsymbol{h}_{s}\in\mathop{\mathbb{R}}^{L\times D} hm,hs∈RL×D分别是来自主分支和长跳跃分支的嵌入。在将它们馈送到下一个transformer块之前,我们考虑几种方法来组合它们:
(1)将它们级联,然后执行如图1所示的线性投影,即 L i n e a r ( C o n c a t ( h m , h s ) ) \mathop{\mathrm{Linear(\mathrm{Concat}({h}_{m},{h}_{s}))}} Linear(Concat(hm,hs));
(2) 直接相加,即 h m + h s h_m+h_s hm+hs;
(3) 对 h s h_s hs执行线性投影,然后将它们相加,即 h m + L i n e a r ( h s ) h_m+\mathrm{Linear(h_s)} hm+Linear(hs);
(4) 将它们相加,然后执行线性投影,即 L i n e a r ( h m + h s ) \mathop{\mathrm{Linear({h}_{m}+{h}_{s})}} Linear(hm+hs)。
(5) 我们还与长跳过连接被丢弃的情况进行了比较。
如图2(a)所示,直接添加 h m , h s h_m,h_s hm,hs没效果。由于transformer块通过其内部的加法运算器具有跳跃连接,因此 h m h_m hm已经包含线性形式的 h s h_s hs信息。因此, h m + h s h_m+h_s hm+hs的唯一效果是增加线性形式的 h s hs hs的系数,这不会改变网络的性质。相比之下,所有其他组合 h s h_s hs的方法都在 h s h_s hs上执行线性投影,并与无长跳跃连接相比提高了性能。其中,第一种连接方式的性能最好。
在附录D中,我们可视化了网络中表示之间的相似性,我们发现第一种连接方式会显著改变表示,这验证了其有效性。
将时间输入网络的方式。我们考虑了两种将 t t t输入网络的方法。
(1) 第一种方法是将其视为令牌,如图1所示。
(2) 第二种方法是将层归一化后的时间合并到transformer块[20]中,这类似于U-Net中使用的自适应组归一化[13]。
第二种方式被称为自适应层归一化(AdalLN)。形式上, A d a L N ( h , y ) = y s L a y e r N o r m ( h ) + y b \mathrm{AdaLN}(h,y)=y_{s}\mathrm{LayerNorm}(h)+y_b AdaLN(h,y)=ysLayerNorm(h)+yb,其中 h h h是transformer块内的嵌入,而 y s y_s ys, y b y_b yb是从时间嵌入的线性投影中获得的。如图2(b)所示,虽然很简单,但将时间视为令牌的第一种方式比AdaLN表现得更好。
在transformer块之后添加额外卷积块的方法。我们考虑两种方法在transformer块之后添加额外的卷积块。
(1) 第一种方法是在线性投影后添加一个3×3卷积块,将标记嵌入映射到图像块,如图1所示。
(2) 第二种方法是在该线性投影之前添加一个3×3卷积块,该块需要首先将令牌嵌入的1D序列 h ∈ R L × D h\in\mathbb{R}^{L\times D} h∈RL×D重新排列为形状为 H / P × W / P × D H/P\times W/P\times D H/P×W/P×D的2D特征,其中P是patch大小。
(3) 我们还与我们丢弃额外卷积块的情况进行了比较。
如图2(c)所示,在线性投影后添加3×3卷积块的第一种方法的性能略好于其他两种选择。
patch嵌入的变体。我们考虑了patch嵌入的两种变体。
(1) 原始patch嵌入采用线性投影,将patch映射到令牌嵌入,如图1所示。
(2) 或者,[73]使用3×3卷积块的堆栈,然后是1×1卷积块,将图像映射到令牌嵌入。
我们在图2(d)中对它们进行了比较,原始的patch嵌入表现更好。
位置嵌入的变体。我们考虑位置嵌入的两种变体。
(1) 第一种是在原始ViT[16]中提出的一维可学习位置嵌入,这是本文的默认设置。
(2) 第二种是二维正弦位置嵌入,它是通过级联位置 ( i , j ) (i,j) (i,j)处的patch的 i i i和 j j j的正弦嵌入[72]而获得的。
如图2(e)所示,一维可学习位置嵌入表现更好。我们还尝试不使用任何位置嵌入,并发现该模型无法生成有意义的图像,这意味着位置信息在图像生成中至关重要。
3.2 深度、宽度和patch大小的影响
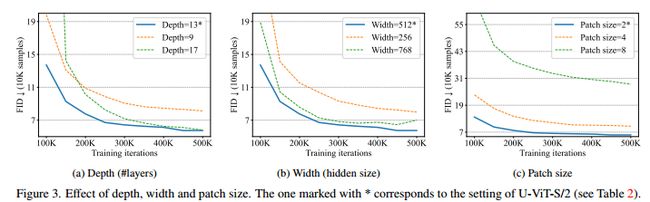
通过研究深度(即层数)、宽度(即隐藏层大小D)和patch大小对CIFAR10的影响,我们展示了U-ViT的缩放性。如图3所示,随着深度(即层数)从9增加到13,性能有所提高。尽管如此,UViT并没有像50K训练迭代中的17次那样从更大的深度中获益。类似地,将宽度(即隐藏层大小)从256增加到512可以提高性能,并且进一步增加到768不会带来增益;将patch大小从8减小到2提高了性能,并且进一步减小到1不会带来增益。请注意,要获得良好的性能,需要像2这样的小patch大小。我们假设这是因为扩散模型中的噪声预测任务是低级别的,需要小patch,不同于高级别的任务(例如分类)。由于使用小的patch大小对于高分辨率图像来说是昂贵的,我们首先将它们转换为低维潜在表示[54],并使用U-ViT对这些潜在表示进行建模。
4. Related Work
扩散模型中的Transformers. 一项相关的工作是GenViT[76]。GenViT采用了较小的ViT,该ViT不采用长跳跃连接和3×3卷积块,并为图像扩散模型引入了归一化层之前的时间。从经验上讲,通过仔细设计实现细节,我们的U-ViT比GenViT表现得更好(见表1)。另一项相关工作是VQ-Diffusion[20]及其变体[61,69]。VQ-Diffusion首先通过VQ-GAN[17]获得离散图像令牌序列,然后使用以transformer为骨干的离散扩散模型[1,62]对这些令牌进行建模。通过跨越注意力或自适应层归一化将时间和条件输入到transformer中。相比之下,我们的U-ViT只是将所有输入视为令牌,并在浅层和深层之间使用长跳跃连接,这实现了更好的FID(见表1和表4)。除了图像,扩散模型中的变换器还用于编码文本[48,52,54,56],解码文本[7,29,39,46]和生成CLIP嵌入[52]。
扩散模型中的U-Net。[65,66]最初引入了基于CNN的U-Net来对连续图像数据的对数似然函数的梯度进行建模。之后,对(连续)图像扩散模型的基于CNN的U-Net进行了改进,包括使用组归一化[25]、多头注意力[49]、改进的残差块[13]和跨越注意力[54]。相比之下,我们的U-ViT是一个基于ViT的主干,设计概念简单,同时,如果不优于类似大小的基于CNN的U-Net,则具有可比的性能(参见表1和表4)。
扩散模型的改进。除了主干之外,在其他方面也有改进,如快速采样[3,44,58,63,74],改进的训练方法[2,15,30,32,33,43,49,64,71]和可控生成[4,10,13,22,27,45,60,80]。
5. Experiments
我们在无条件和类条件图像生成(第5.2节)以及文本到图像生成(见第5.3节)中评估了所提出的U-ViT。在给出这些结果之前,我们在下面列出了主要的实验设置,附录A中提供了更多细节,如采样超参数。
5.1. 实验设置
数据集。对于无条件学习,我们考虑包含50K训练图像的CIFAR10[36]和包含162770张人脸训练图像的CelebA 64×64[41]。对于类条件学习,我们考虑64×64、256×256和512×512分辨率的ImageNet[12],它包含来自1K个不同类的1281167个训练图像。对于文本到图像学习,我们考虑256×256分辨率的MS-COCO[40],其中包含82783个训练图像和40504个验证图像。每张图片都有5个图像标注。
高分辨率图像生成。对于256×256和512×512分辨率的图像,我们遵循潜在扩散模型(LDM)[54]。我们首先使用Stable Diffusion2[54]提供的预训练图像自编码器,将它们分别转换为32×32和64×64分辨率的潜在表示。然后,我们使用所提出的U-ViT对这些潜在的表示进行建模。
文本到图像学习。在MS-COCO上,我们使用稳定扩散之后的CLIP文本编码器将离散文本转换为嵌入序列。然后将这些嵌入作为令牌序列馈送到U-ViT中。
U-ViT配置。我们在表2中确定了U-ViT的几种配置。在本文的其余部分中,我们使用简短的符号来表示U-ViT配置和输入patch大小(例如,U-ViT-H/2表示输入patch大小为2×2的U-ViT-Huge配置)。

训练。我们使用AdamW优化器[42],所有数据集的权重衰减为0.3。我们对大多数数据集使用2e-4的学习率,除了ImageNet 64×64使用3e-4。我们在CIFAR10和CelebA 64×64上训练了500K次迭代,批量大小为128。我们在ImageNet 64×64和ImageNet 256×256上训练300K迭代,在ImageNet 512×512上训练500K迭代,批量大小为1024。我们在批量大小为256的MS-COCO上训练1M次迭代。在ImageNet 256×256、ImageNet 512×512和MS-COCO上,我们在[54]之后采用了无分类器指导[27]。我们在附录A中提供了更多细节,如训练时间和如何选择超参数。
5.2. 无条件和类条件图像生成
我们将U-ViT与基于U-Net的先验扩散模型进行了比较。我们还与GenViT[76]进行了比较,后者是一种较小的ViT,不使用长跳跃连接,并包含了标准化层之前的时间。与之前的文献一致,我们报告了50K生成样本的FID评分[23],以测量图像质量。
如表1所示,U-ViT在无条件CIFAR10和CelebA 64×64上与U-Net相当,同时性能远优于GenViT。
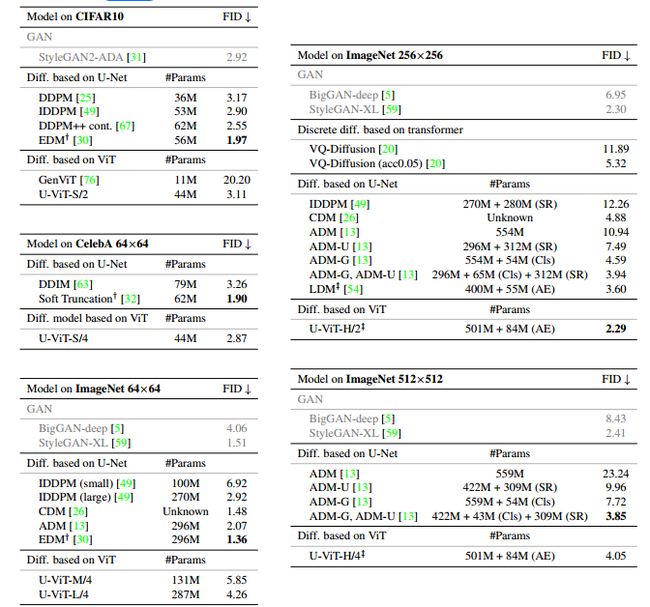

在类条件ImageNet 64×64上,我们最初尝试使用131M参数的U-ViT-M配置。如表1所示,它获得了5.85的FID,这比使用100M参数的U-Net的IDDPM的6.92要好。为了进一步提高性能,我们采用了具有287M个参数的U-ViT-L配置,FID从5.85提高到4.26。同时,我们发现我们的U-ViT在潜在空间中表现特别好[54],在应用扩散模型之前,首先将图像转换为其潜在表示。在类条件ImageNet 256×256上,我们的U-ViT获得了2.29的最先进FID,这优于所有先前的扩散模型。在类条件ImageNet 512×512上,我们的U-ViT优于直接对图像像素建模的ADM-G。
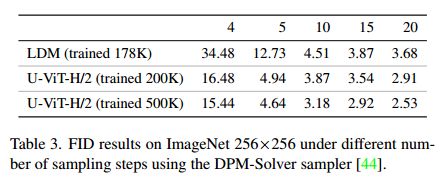
表3进一步表明,在使用相同采样器的不同采样步骤下,我们的U-ViT优于LDM。请注意,我们的U-ViT也优于VQ-Diffusion,后者是一种离散扩散模型[1],采用transformer作为主干。
我们还尝试用具有类似参数和计算成本的UNet取代我们的U-ViT,其中我们的U-ViT仍然优于U-Net(详见附录E)。
在图4中,我们在ImageNet 256×256和ImageNet 512×512上提供了选定的样本,在其他数据集上提供了随机样本,这些样本具有良好的质量和清晰的语义。

我们在附录F中提供了更多生成的样本,包括类条件样本和随机样本。
在第3.1节中,我们已经证明了长跳跃连接在小规模数据集(即CIFAR10)上的重要性。图5进一步显示了它对于像ImageNet这样的大规模数据集也是至关重要的。
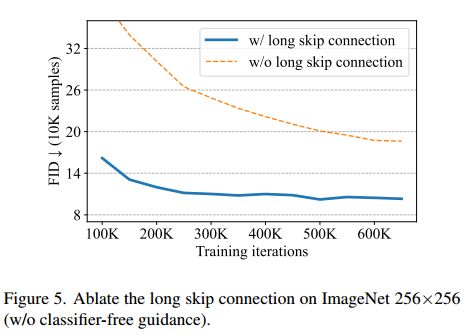
在附录C中,我们在ImageNet上展示了其他指标(如sFID、初始得分、精确度和召回率)的结果,以及更多U-ViT配置的计算成本(GFLOP)。我们的U-ViT在其他指标上仍然可以与最先进的扩散模型相媲美,同时即使不是更小的GFLOP,也具有可比性。
5.3. MS-COCO上的文本到图像生成
我们在标准基准数据集MS-COCO上评估了用于文本到图像生成的U-ViT。我们在图像的潜在空间中训练我们的U-ViT[54],如第5.1节所述。我们还训练了另一个潜在扩散模型,该模型采用了与U-ViT-S模型大小相当的U-Net,并保持其他部分不变。附录B中提供了其超参数和训练细节。我们报告了FID评分[23]以测量图像质量。与之前的文献一致,我们从MS-COCO验证集中随机抽取30K提示,并在这些提示上生成样本以计算FID。
如表4所示,我们的U-ViT-S在生成模型的训练过程中,在不访问大型外部数据集的情况下,已经在方法中实现了最先进的FID。通过将层数从13层进一步增加到17层,我们的U-ViT-S(Deep)甚至可以实现5.48的更好FID。

图6显示了使用相同随机种子生成的U-Net和U-ViT样本,以进行公平比较。我们发现UViT生成了更多高质量的样本,同时语义与文本匹配得更好。例如,给定文本“棒球运动员向球挥动球棒”,U-Net既不会生成球棒也不会生成球。相比之下,我们的U-ViT-S生成的球具有更少的参数,而我们的U-ViT-S(Deep)进一步生成击球。我们假设这是因为文本和图像在U-ViT的每一层都有交互,这比只在跨越注意力层交互的U-Net更频繁。

我们在附录F中提供了更多例子。
6. Conclusion
这项工作提出了U-ViT,这是一种简单而通用的基于ViT的架构,用于使用扩散模型生成图像。U-ViT处理所有输入,包括时间、条件和噪声图像patch作为令牌,并采用浅层和深层之间的长跳跃连接。我们在包括无条件和类条件图像生成以及文本到图像生成在内的任务中评估U-ViT。实验表明,U-ViT即使不优于类似规模的基于CNN的U-Net,也具有可比性。这些结果表明,对于基于扩散的图像建模,长跳跃连接是至关重要的,而基于CNN的U-Net中的下/上采样操作并不总是必要的。我们相信U-ViT可以为未来对扩散模型中骨干的研究提供见解,并在大规模跨模态数据集上进行效果生成建模。
Appendix
A. 实验设置
B. MS-COCO U-Net基线的详细信息
C. ImageNet上其他度量和配置的结果
D. CKA分析
E. 在参数和计算成本相似的情况下与U-Net的比较
F. 附加例子