C语言快捷键+一堆宝藏技巧,全网最全~
write in front
大家好,我是Aileen.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流.
本文由Aileen_0v0 原创 CSDN首发 如需转载还请通知⚠️
个人主页:Aileen_0v0—CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏:Aileen_0v0的C语言学习系列专栏——CSDN博客
我的格言:"没有罗马,那就自己创造罗马~"

目录
编辑
什么是调试(debug)
如何进行调试
1.环境准备
2.调试快捷键-注:手提电脑需要+Fn
C语言中其他的常用快捷键
监视和内存观察
监视
调试举例1
调试举例2
调试举例3-扫雷游戏
编译错误类型
1.编译型错误:
2.链接错误:
3.运行时错误:
什么是调试(debug)
当我们发现程序中存在的问题的时候,那下一步就是找到问题,并修复问题。
这个找问题的过程---称为调试,英文叫debug (消灭bug) 的意思。调试一个程序,首先是承认出现了问题,然后通过各种手段去定位问题的位置,可能是逐过程的调试,也可能是隔离和屏蔽代码的方式,找到问题所的位置,然后确定错误产生的原因,再修复代码重新测试。
debug 和 release

在VS上编写代码的时候,就能看到有debug和release两个选项
#define _CRT_SECURE_NO_WARNINGS 1
#include
int main()
{
printf("hehe\n");
return 0;
} Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序.
Release 称为发布版本,它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优的以便用户很好地使用。
例子:
X86 环境下 debug 的运行结果: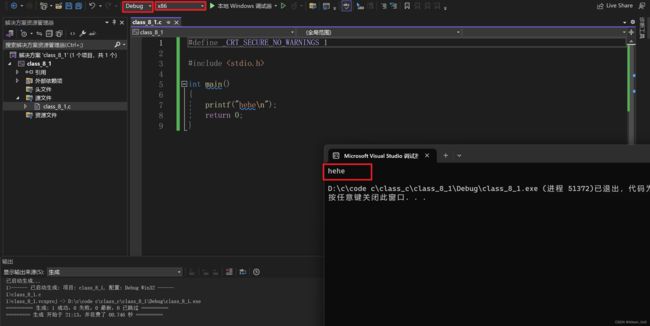
debug文件下它的大小为:
X86 环境下 release的运行结果: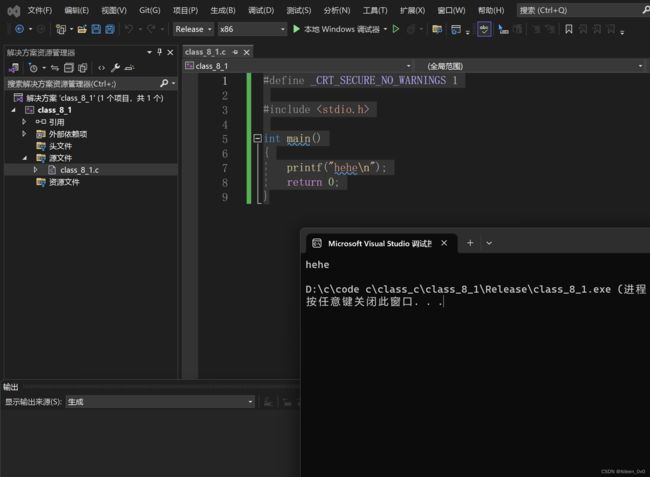
release 文件下 它的大小为:

debug的调试过程:
release的调试过程:
通过调试结果,我们可以知道 release 里面不包含任何的调试结果
如何进行调试
1.环境准备

选择 debug X86 和 X64环境 都可以进行调试
2.调试快捷键-注:手提电脑需要+Fn
F10 : 逐过程进行调试 ---如下示例:
F11:逐语句进行调试 ---如下示例:
对比 F10 和 F11 可得出以下结论:
F10: 逐过程,不会进入函数内部
F11: 逐语句,就是每次都执行一条语句,但是这个快捷键可以使我们的执行逻辑进入函数内部。
在函数调用的地方,想进入函数观察细节,必须使用F11,如果使用F10,直接完成函数调用。
ctrl + F5: 开始执行,不调试.
F5: 启动调试 ,经常用来跳到下一个断点处--->[指的是执行逻辑的下一个断点处,比如说循环语句里面打断点,按F5第一次循环执行结束后再按一次F5它就会继续第二次循环直到回到断点处,直到我们结束循环.而不是根据我们打的断点直接跳到下一个断点处(这是物理逻辑上的断点)],
经常和 F9 配合使用
根据上面的操作我们可以发现,按F9创建断点,按F5会直接快速运行断点之前的代码然后到断点处就停下来了
便于我们快速检查后面代码的错误
F9: 创建断点 和 取消断点
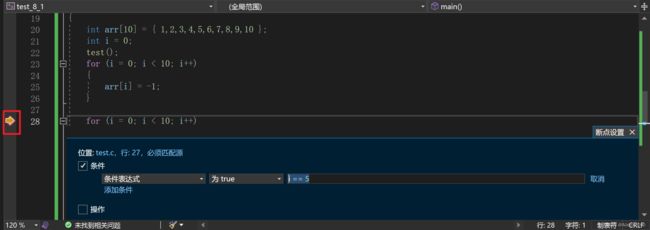
 我们还可以右击断点进行条件设置,从而控制程序运行.
我们还可以右击断点进行条件设置,从而控制程序运行.
C语言中其他的常用快捷键
1、窗口快捷键
记忆诀窍:凡跟窗口挂上钩的快捷键必有一个W(Windows);
Ctrl+W,W: 浏览器窗口 (浏览橱窗用有道的翻译是window shopping)Ctrl+W,S: 解决方案管理器 (Solution)
Ctrl+W,C: 类视图 (Class)
Ctrl+W,E: 错误列表 (Error)
Ctrl+W,O: 输出窗口(输出Output;输出程序的的编译信息 ;可在vs中“工具”—-“选项”—-“调试”—-“输出窗口”进行配置需要查看哪些信息)
Ctrl+W,P: 属性窗口 (属性 Property)
Ctrl+W,T: 任务列表 (任务Task)
Ctrl+W,X: 工具箱 (事实上工具应该是Tool 但t已被任务列表占用了 ;参照一些大神的记忆方法:“X”长得四通八达,而工具就有这样一个特点,所以属性的快捷键是“X”)
Ctrl+W,B: 书签窗口 (书签 Bookmark 书签非常好用,如果有几千行代码,在寻找代码的时候添加书签找起来要快很多)
Ctrl+W,U: 文档大纲 (OutLine;使用第二个字母U)
Ctrl+D,B: 断点窗口 (breakpoint)
Ctrl+D,I: 即时窗口 (immediately)
2、项目功能快捷键**
规律:ctrl是强制功能键
shift有给项目增加功能
CTRL + F6 /CTRL + TAB下一个文档窗口即活动窗体切换 (windows操作系统是alt+tab表示在任务之间切换CTRL + SHIFT + F6 /CTRL + SHIFT + TAB上一个文档窗口 (在windows系统操作中 相信大家都知道shift有相反的功能 哈哈 在这里体现了)
F7: 查看代码 (WebForm开发里面,是查看后台代码)
Shift+F7: 查看窗体设计器 (在后台cs文件的时候,这种方式很方便跳转到前台.aspx页面)
Ctrl+Shift+N: 新建项目 (N是New新建的意思 那如果需要强制在项目中新建项目的话 自然就是组合键Ctrl+Shift+N)
Ctrl+Shift+O: 打开项目 (Open)
CTRL + SHIFT + C显示类视图窗口(C代表Class类的意思)
CTRL + F4关闭文档窗口 (相信用过qq的大家都有使用alt+f4来关闭当前聊天窗口 想想用ctrl+tab在活动标签窗口切换就知道为什么关闭当前标签窗口是ctrl+f4)
CTRL + SHIFT + E显示资源视图 (E代表Explorer资源管理器的意思)
CTRL + SHIFT + B生成解决方案 (B代表Build生成的意思 其实用F6也可以实现)
Shift+F6表示生成当前项目 (上面已经说过使用f6可以生成整个解决方案 那如果是当前项目的生成那自然就是加上功能键shift了 )
F4 显示属性窗口 SHIFT + F4显示项目属性窗口
Ctrl+Shift+S: 全部保存 (S代表Save保存的意思 这里表示全部保存是因为如果只是单个保存Ctrl+S跟整个项目没有任何瓜葛 而全部保存的概念应该是说在整个项目中 所以组合键中自然会有shift了哦)
Ctrl+Shift+A: 新建项(A是Add的意思)
Shift+Alt+C: 新建类 (shift是跟项目有关的功能键;Alt用的非常多,空格(用的非常多)旁;C是Class;而且添加类用的非常多;所以自然就是:Shift+Alt+C)
3、查找相关快捷键
Ctrl+F: 查找 (Find) Ctrl+Shift+F: 在文件中查找 (上面已经提过了shift是表示在项目中 所以如果需要在项目中的文件中查找的话 那自然就少不了Shift)
F3: 查找下一个 (相信使用过windows系统的人都知道f3是查找的快捷键)
Shift+F3: 查找上一个 (shift在此有反向的功能哦)
Ctrl+H: 替换
Ctrl+Shift+H: 在文件中替换4、代码快捷键
Ctrl+E,D(ctrl+k,d) —-格式化全部代码 ;让你的代码瞬间整洁起来。Ctrl+E,F —-格式化选中的代码(如果你已经记住Ctrl+E+D是格式化全部代码的话 那你想想规律不就知道了吗 F不就在D的右边表示它是特定某一范围)
Ctrl+K,C: 注释选定内容 (Comment)
Ctrl+K,U: 取消选定注释内容 (UnComment)
Ctrl+J /Ctrl+K,L: 智能提示 列出成员 (kernel核心内容 list列表 如果我们想查看一个对象具有的成员具体信息的时候试下这个快捷键吧)
Ctrl+K,P: 参数信息 (kernel核心内容 Parameters参数 如果我们想查看一个方法的具体参数的时候这个组合键可是挺有用的哦)
Ctrl+K,I: 快速查看信息(Infomation)
Ctrl+K,S: 外侧代码(平时个人惯会时不时的用#region 用了region之后代码看起来就特别整洁 所以自然而然的就用**惯了这个)
CTRL + M, CTRL + M 折叠或展开当前方法
CTRL + M, CTRL + O 折叠所有方法
CTRL + M, CTRL + L展开所有方法
CTRL + M, CTRL + P展开所有方法Ctrl+M,P: 停止大纲显示 (用了region将代码折叠起来之后试试用这组组合键吧 体验一下折叠和展开的**吧 看着舒服的代码我相信你记住这对快捷键肯定是值得的)
ctrl+shift+f10:自动添加using命名空间(在实例化对象的时候,使用的非常多)
5、调试快捷键
F5: 启动调试Ctrl+F5: 开始执行(不调试)
Shift+F5: 停止调试
Ctrl+Shift+F5: 重启调试
F9: 启用/关闭断点
Ctrl+F9: 停止断点
Ctrl+Shift+F9: 删除全部断点
F10: 逐过程
Ctrl+F10: 运行到光标处
F11: 逐语句6、编辑快捷键
Shift+Alt+Enter: 切换全屏编辑(如果想一心一意的只写代码 让整个vs铺满全屏 感觉还不错哦)F12: 转到所调用过程或变量的定义
Alt+F12: 查找符号(列出所有查找结果)
shift+f12:查找所有引用(讲光标放在单词上, 然后按Shift + F12)
Ctrl+U: 全部变为小写 (的sql语句全部转换成大写以提高性能 )
Ctrl+Shift+U: 全部变为大写 (U表示Upper )
Ctrl+Shift+V: 剪贴板循环 (平时我们都只**惯用ctrl+c 和ctrl+v 大家可能还不知道事实上微软都已经帮我们把多次剪切的结果都保存了下来 记下这组快捷键吧 可以粘贴上几次剪切的结果 一用便知道它的强大厉害之处)
Ctrl+Shift+L: 删除当前行 (这个很有用哦 因为大家常常会要删除多余的空行 哈哈 这组快捷键会让你省力不少)
Ctrl+E,S: 查看空白(ctrl+r,w 和它一样可以查看空白或者说显示或隐藏tab标记)
Ctrl+E,W: 自动换行 (代码太长还有滚动条,特别是写append(sql.toString)语句的时候,太长,所以这时候就不得不拖动滚动条,这样以后就可以换行显示了)
Ctrl+G: 转到指定行 (通过情况下 我们想在跳转到具体某一行 用它太方便了)
Shift+Alt+箭头键: 选择矩形文本 Alt+鼠标左按钮: 选择矩形文本
CTRL + DELETE删除至词尾 CTRL + BACKSPACE删除至词头 SHIFT + TAB取消制表符
Ctrl+左右箭头键:一次可以移动一个单词
Ctrl+单击: 选中当前点击的整个单词
SHIFT + END选择至行尾
SHIFT + HOME选择至行开始处CTRL + SHIFT + END选择至文档末尾 CTRL + SHIFT + HOME选择至文档末尾开始
CTRL + SHIFT + PAGE UP选择至本页前面 CTRL + SHIFT + PAGE DOWN选择至本页后面
CTRL + PAGE DOWN光标定位到窗口上方 CTRL + PAGE UP光标定位到窗口下方
CTRL + END文档定位到最后 CTRL + HOME文档定位到最前
按两下tab快速**代码段(写for, foreach循环,或者try, 还有绑定事件方法)
ctrl+减号:回退到光标上一次的位置(这个真心挺有用的)
监视和内存观察
监视
一定要开始调试以后,才能看到窗口.

监视可以自定义的监视任何你所定义的合法的窗口

//求n的阶乘
int main()
{
int n = 0;
scanf("%d", & n);
int i = 0;
int result = 1;
for (i = 1; i <= n; i++)
{
result = result * i;
}
printf("%d\n", result);
return 0;
}调试举例1
int main()
{
//求n的阶乘
int n = 0;
//1*2*3*4*5 = 120
int i = 0;
int ret = 1;
int sum = 0;
//1!+2!+3! = 1+2+6 = 9
for (n = 1; n <= 3; n++)
{
for (i = 1; i <= n; i++)
{
ret = ret * i;
}
sum = sum + ret;
}
printf("%d\n", sum);
return 0;
}上面这段代码本来运行结果应该是:9的,但是结果却是:

这是为什么呢?

我们可以通过调试找到代码的问题:
本来内循环计算3的阶乘应该得到6的,结果它得到12,这说明之前计算2的阶乘的时候的ret值还保留在ret里面,在后面计算的时候会把之前的ret的结果又带回去计算


 修改后的代码:
修改后的代码:
int main()
{
//求n的阶乘
int n = 0;
//1*2*3*4*5 = 120
int i = 0;
int ret = 1;
int sum = 0;
//1!+2!+3! = 1+2+6 = 9
for (n = 1; n <= 3; n++)
{
for (i = 1; i <= n; i++)
{
ret = ret * i;
}
sum = sum + ret;
}
printf("%d\n", sum);
return 0;
}优化后的代码:
//优化后的代码
int main()
{
//求n的阶乘
int n = 0;
//1*2*3*4*5 = 120
int i = 0;
int ret = 1;
int sum = 0;
//1!+2!+3! = 1+2+6 = 9
for (n = 1; n <= 3; n++)
{
ret = ret * n;
sum = sum + ret;
}
printf("%d\n", sum);
return 0;
}
调试举例2
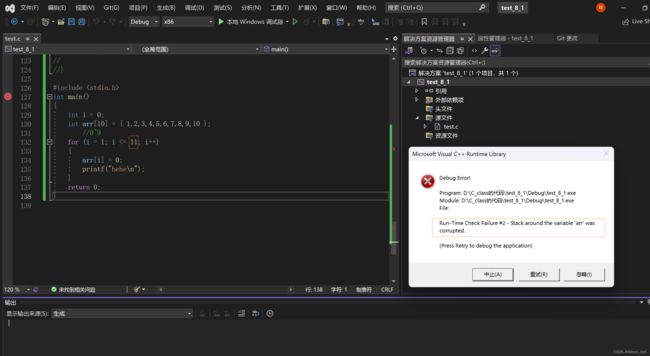
#include
int main()
{
int i = 0;
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
//0~9
for (i = 1; i <= 12; i++)
{
arr[i] = 0;
printf("hehe\n");
}
return 0;
}
控制台运行结果:
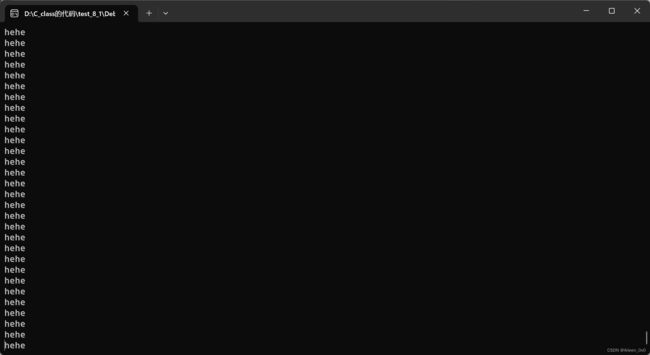
我们可以从运行结果发现,程序进行了死循环
我们通过调试发现程序发生了越界访问,我们试一下&i和&arr[12]

我们会发现i和arr[12]在同样的运行环境下
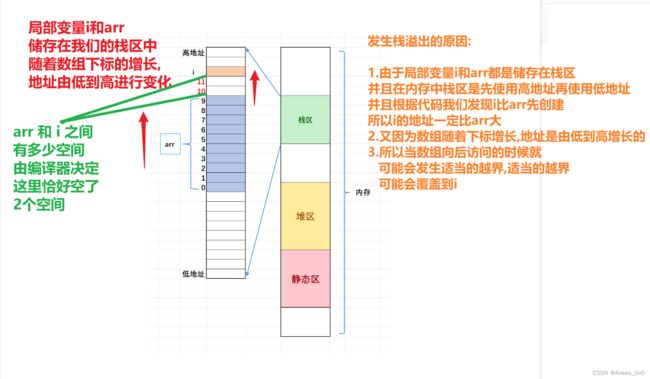
当i改成 <=11时就会再次运行程序会发生越界的报错,而当i<=12时它由于在忙着打印hehe没办法停下来进行报错.
所以 当 i改为 < 10时,再次运行程序时,我们会发现 ,这次运行就不会发生错误
面试真题:
这个程序可能会发生死循环并且可能会进行越界访问现象,原理如下:

调试举例3-扫雷游戏
对于一维数组,如果我们直接调试会发现,只能显示一个元素.
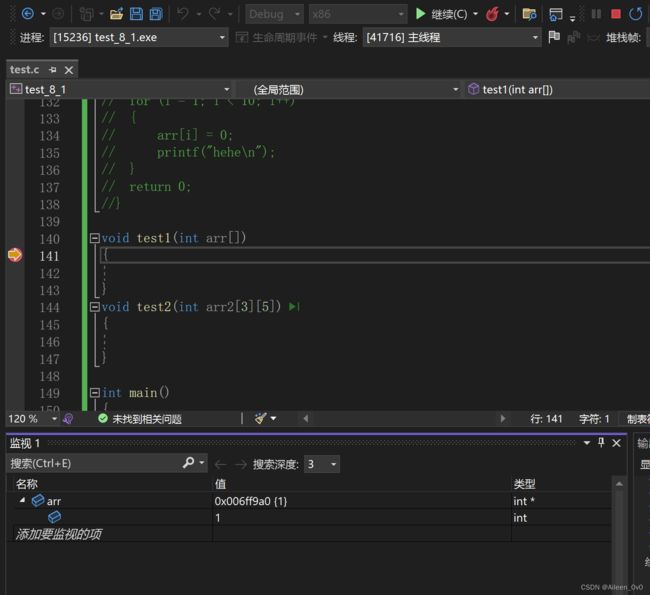
这里有个小tips: 数组名,n

对于二维数组,我们通过调试看一下:

我们通过调试结果可以发现,它和一维数组一样,只能显示一行的结果,我们可以用之前那个方法:
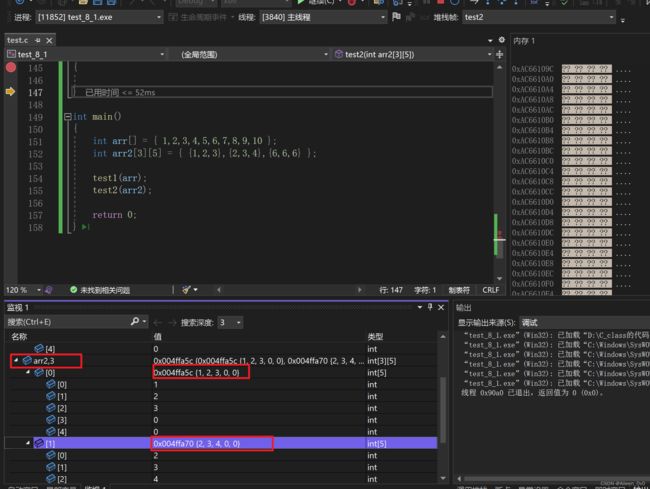
优化一下之前扫雷游戏的代码:
之前没有考虑到两个坐标相同的问题:
补充修改好的代码在这里:
game.c:
#define _CRT_SECURE_NO_WARNINGS
#include "game.h"
#include
void InitBoard(char board[ROWS][COLS], int rows, int cols, char set)
{
int i = 0;
for (i = 0; i < rows; i++)
{
int j = 0;
for (j = 0; j < cols; j++)
{
board[i][j] = set;
}
}
}
//打印棋盘,就是打印数组
void DisplayBoard(char board[ROWS][COLS], int row, int col)
{
int i = 0;
printf("-----------扫雷游戏-----------\n");
//打印棋盘序号
for (i = 0; i <= row; i++)
{
printf("%d ", i);
}
printf("\n");
//打印9*9的棋盘
for (i = 1; i <= row; i++)
{
printf("%d ", i);
int j = 0;
for (j = 1; j <= col; j++)
{
printf("%c ", board[i][j]);
}
printf("\n");
}
printf("-----------扫雷游戏-----------\n");
}
//布置雷
void SetMine(char mine[ROWS][COLS], int row, int col)
{
int count = EASY_COUNT;
while (count)
{
int x = rand() % row + 1;
int y = rand() % col + 1;
if (mine[x][y] == '0')//如果该位置无雷才在这个位置放雷
{
mine[x][y] = '1';
count--;
}
}
}
//实现GetMineCount数组
static int GetMineCount(char mine[ROWS][COLS], int x, int y)
{
return(mine[x - 1][y] +
mine[x - 1][y - 1] +
mine[x][y - 1] +
mine[x + 1][y - 1] +
mine[x + 1][y] +
mine[x + 1][y + 1] +
mine[x][y + 1] +
mine[x - 1][y + 1] - 8 * '0');
}
//排查雷
void FindMine(char mine[ROWS][COLS], char show[ROWS][COLS], int row, int col)
{
int x = 0;
int y = 0;
int win = 0;
while (win < row * col - EASY_COUNT)//根据雷和非雷的数量关系限制循环次数
{
printf("请输入要排查的坐标:>");
scanf("%d %d", &x, &y);
//注意:x y 要在有效的排查范围(9*9)之内
if (x >= 1 && x <= row && y >= 1 && y <= col)
{
//如果输入的坐标已经被排查过,怎么办?
if (show[x][y] != '*') {
printf("该坐标被排查过,重新输入坐标\n");
}
//开始排查是否是雷
else if (mine[x][y] == '1')
{
printf("很遗憾,你被炸死了\n");
DisplayBoard(mine, ROW, COL);
break;
}
else
{
int count = GetMineCount(mine, x, y);
show[x][y] = count + '0';
DisplayBoard(show, ROW, COL);
//count + 字符'0;变成对应的数字字符放到show数组里
win++;
}
}
else
{
printf("坐标非法,重新输入\n");
}
}
if (win == row * col - EASY_COUNT)
{
printf("恭喜你,扫雷成功\n");
DisplayBoard(mine, ROW, COL);
}
} 编译错误类型

一般双击错误信息就能找到错误在哪.
1.编译型错误:
编译型错误⼀般都是语法错误,这类错误⼀般看错误信息就能找到⼀些蛛丝⻢迹的,双击错误信息也能初步的跳转到代码错误的地⽅。编译错误,随着语⾔的熟练掌握,会越来越少,也容易解决。
2.链接错误:
看错误提⽰信息,主要在代码中找到错误信息中的标识符,然后定位问题所在。⼀般是因为• 标识符名不存在• 拼写错误• 头⽂件没包含• 引⽤的库不存在
3.运行时错误:
运⾏时错误,是千变万化的,需要借助调试,逐步定位问题,调试解决的是运⾏时问题。