优先级队列priority_queue
优先级队列priority_queue
优先级队列是一个拥有权值的queue,其内部元素按照元素的权值排列。权值较高者排在最前优先出队。其中缺省情况下系统是通过一个max-heap以堆实现完成排序特性,表现为一个以vector表现的完全二叉树
1、优先级队列介绍
这是一个queue,所以只允许在底端加入元素,并从顶端取出元素。
但是优先级队列中的元素并非依照被推入队列的顺序排列。而是自动依照元素的权值排列。权值最高者排在最前面。
缺省的情况下维护的是一个大堆,即权值以从高到低排列。

priority_queue<Type, Container, Functional>
其中Type代表数据类型,Container代表容器类型,缺省状态为vector; Functional是比较方式,默认采用的是大顶堆(less<>)。
//升序队列 小顶堆 great 小到大
priority_queue <int,vector<int>,greater<int> > pri_que;
//降序队列 大顶堆 less 大到小 默认
priority_queue <int,vector<int>,less<int> > pri_que;
2、优先级队列内置函数
q.size();//返回q里元素个数
q.empty();//返回q是否为空,空则返回1,否则返回0
q.push(k);//在q的末尾插入k
q.pop();//删掉q的第一个元素
q.top();//返回q的第一个元素
3、自定义比较函数
①仿函数(函数对象)
使用这种方式,需要显示定义优先级队列的容器类型和比较函数
#include结果:

②、使用自定义类型比较关系
重载比较类型的 < 符号,之后在类型直接写类型名称即可
#include结果:

③、使用lambda表达式
使用lambda表达式需要在pq对象构造的时候,将lambda表达式作为参数传入其中,即pq(cmp)
#include, function > pq(cmp); // 和上面的效果相同,但是用function需要包含头文件functional
pq.push(a);
pq.push(b);
pq.push(c);
pq.push(d);
pq.push(e);
while (!pq.empty())
{
cout << pq.top().x << "," << pq.top().y << endl;
pq.pop();
}
return 0;
}
结果:

④、函数指针
使用函数指针与使用lambda表达式类似,都是在priority_queue<.,.,Cmp>中定义Compare的类型同时在priorityQueue(cmp)的中输入具体的对象作为参数,不过 这里使用的是函数和函数的指针(地址)而不是lambda表达式对象。
#include结果:
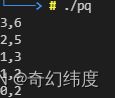
4、优先级队列排序函数的顺序问题
对于sort和priority_queue,使用greater和less类模板是结果不同的。
主要原因是因为priority_queue的内部实现方法是堆,less对应的是大顶堆。在此排序下调用top()得到的是堆顶,也就是取值时是从大到小。push对应的底层函数是push_heap(),每次添加元素入堆时,在默认情况下添加进去的数据作为较小值入堆。
//默认都是less
sort(vec.begin(),vec.end(),less<int>()); //内置类型从小到大 升序
priority_queue <int,vector<int>,less<int> > pql; //top出数据从大到小 降序
sort(vec.begin(),vec.end(),greater<int>()); //内置类型从大到小 降序
priority_queue <int,vector<int>,greater<int> > pqg; //top出数据从小到大 升序
| 方法或容器 | less()的顺序 | greater()的顺序 | cmp函数 > | cmp函数 < |
|---|---|---|---|---|
| priority_queue 全是反过来的 | 降序 大->小 | 升序 小->大 | 升序 小->大 | 降序 大->小 |
| sort | 升序 小->大 | 降序 大->小 | 降序 大->小 | 升序 小->大 |
除了priority_queue使用的是堆,导致全部大小比较反了过来,其他均是正常符合逻辑的操作,即判断为func(a,b)判断为true则a在前。只有priority_queue特殊,如果func(a,b)判断为true,优先级队列中b在前。
注意: 队头在最右侧
struct node{
int x;
int y;
}point;
bool operator<(const node &a,const node &b)
{
if(a.x==b.x) return a.y > b.y;
else return a.x < b.x;
}
priority_queue<node> Q;
1、sort排序里面的比较函数,将元素按照比较函数的逻辑排序
2、优先队列priority_queue里面默认使用大顶堆,也就是less<>,并不是按照比较的顺序直接进行排序。
3、如上述代码,对于a和b的排序,先对a.x和b.x进行比较,如果前者小,其优先级低,放在后面,按照降序排列;如果两者相等,再对a.y和b.y进行比较,如果前者小,此时优先级高,放在前面,按照升序排列。
4、总结,先按照x降序排列,对于x相同的,按照y升序排列,而非直接根据大小进行排列。排列的标准是优先级,而非具体的数值大小。返回true代表优先级更低。
参考资料:
1、https://blog.csdn.net/qq_29592167/article/details/82708780
2、https://zhuanlan.zhihu.com/p/344121142
3、https://blog.csdn.net/qq_41484228/article/details/123137801
4、https://blog.csdn.net/red_red_red/article/details/84559951