中间件-Kafka学习笔记
目录
- Kafka概述
- Kafka安装Linux集群版
- Kafka命令行操作
- Kafka生产者
- Kafka消费者
- Kafka API操作
-
- Producer API
- Consumer API
- Kafka监控
- Kafka调优
-
- Kafka机器数量计算
- Kfka压力测试
- Kafka分区数计算
Kafka概述
kafka基础架构
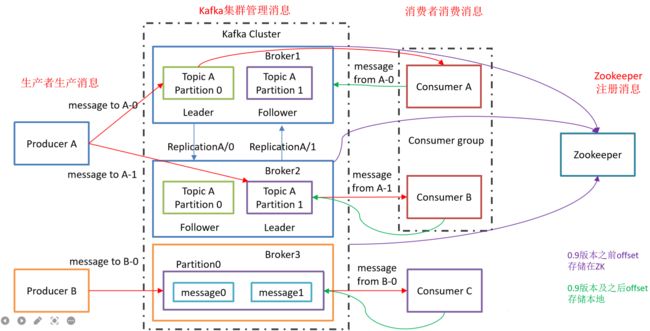
Producer:消息生产者,向kafka broker发消息得客户端
Consumer:消息消费者,向kafka broker取消息的客户端
Consumer Grroup:消费者组,由多个Consumer组成,消费者组内每个消费者负责不同分区的数据,一个分区只能由一个组内消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者
Broker:一台kafka服务器就是一个broker,一个集群是由多个broker组成,一个broker可以容纳多个topic
Topic:主题类似一个消息队列,生产者和消费者面向的都是一个topic
Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker上,一个topic可以分为多个partition,每个partition是一个有序序列
Replica:副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower
leader:每个分区多个副本的主,生产者发送数据的对象,以及消费者消费数据的对象都是leader
follower:每个分区多个副本中的从,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的leader
kafka工作流程

Kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的
topic是逻辑上的概念,而partition是物理上的概念,每个partition对应一个log文件,该log文件中存储的就是producer生产的数据。Producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费。
kafka文件存储机制

由于生产者生产的消息会不断追加到log文件末尾,为防止log文件大导致数据定位效率低下,kafka采取了分片和索引的机制,将每个partition分为多个segment。每个segment对应两个文件(.index索引文件和.log文件)。这些文件位于一个文件夹下,该文件夹的命名规则为topic名称+副本序号。如:first这个topic有三个副本,则其对应的文件为first-0,first-1,first-2
first-0
first-1
first-2

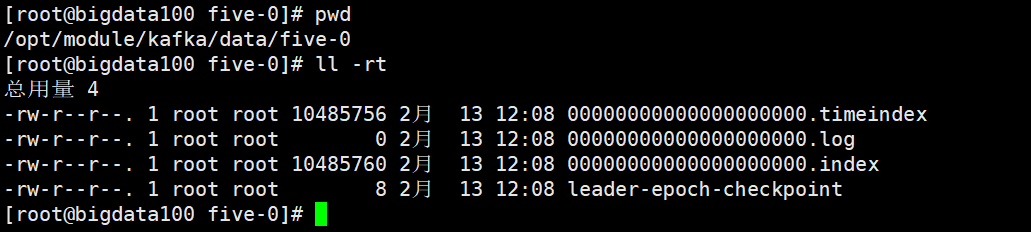
index和log文件以当前segment的第一条消息的offset命名

.index文件存储大量的索引信息,.log文件存储大量的数据,索引文件中的元数据指向对应数据中message的物理偏移地址。
Kafka安装Linux集群版
官网地址
http://kafka.apache.org/downloads.html

修改配置文件
解压文件,修改kafka文件夹内config/server.properties
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka数据存储位置
log.dirs=/opt/module/kafka/data
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181
配置环境变量可以全局使用kafka脚本vim /etc/profile,使环境生效source /etc/profile
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
将配置好的kafka文件夹分发到集群下,修改集群另外服务器的broker.id,broker.id不能重复
kafka集群启停脚本
集群启动:依次在集群上执行kafka-server-start.sh -daemon config/server.properties
集群停止:依次在集群上执行kafka-server-stop.sh stop
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh stop"
done
};;
esac
Kafka命令行操作
对topic主题的操作
查看当前服务器中的所有topic
kafka-topics.sh --zookeeper hadoop102:2181 --list
查看某个topic的详情
kafka-topics.sh --zookeeper hadoop102:2181 --describe --topic first
创建topic
# --topic 定义topic名
# --replication-factor 定义副本数
# --partitions 定义分区数
kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 3 --partitions 1 --topic first
修改分区数
kafka-topics.sh --zookeeper hadoop102:2181 --alter --topic first --partitions 6
删除topic
# 需要server.properties中设置delete.topic.enable=true否则只是标记删除
kafka-topics.sh --zookeeper hadoop102:2181 --delete --topic first
发送消息
kafka-console-producer.sh --broker-list hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic first
> hello world
消费消息
# 0.9版本,消费offset存在zk,之后版本存在本地,故已放弃使用
kafka-console-consumer.sh --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181 --topic first
# 目前在用
kafka-console-consumer.sh --bootstrap-server hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic first
# 从开始读取 --from-beginning会把主题中以往所有的数据都读取出来
kafka-console-consumer.sh --bootstrap-server hadoop102:9092,hadoop103:9092,hadoop104:9092 --from-beginning --topic first
Kafka生产者
分区策略
分区方便再集群中扩展,每个partition可以通过调整以适应它所在的机器,而一个topic又可以有多个partition组成,因此整个集群就可以适应任意大小的数据。同时分区也可以提高并发度,因为可以以Partition为单位进行读写。
producer发送数据需要封装一个ProducerRecord对象

指明partition的情况下,直接将指明的值作为partition的值
没有指明partition的值,但是有key的情况下,将key的hash值与topic的partition数进行取余得到partition的值。
既没有partition也没有key值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与topic可用的partition总数取余得到partition值,也就是常说的round-robin算法。
数据可靠性保证
为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,都需要向producer发送ack(acknowledgement确认收到)。如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。
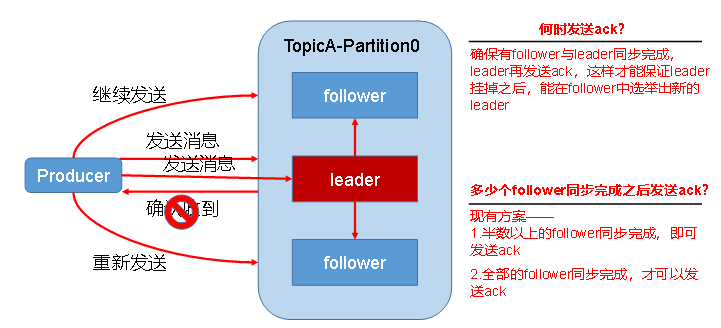
| 方案 | 优点 | 缺点 |
|---|---|---|
| 半数以上完成同步,就发送ack | 延迟低 | 选举新的leader时,容忍n台节点的故障,需要2n+1个副本 |
| 全部完成同步,才发送ack | 选举新的leader时,容忍n台节点的故障,需要n+1个副本 | 延迟高 |
kafka采用全部完成同步才发送ack的方案,因为同样为了容忍n台节点的故障,第一种方案需要2n+1个副本,而第二种方案只需要n+1个副本,而Kafka的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。虽然第二种方案的网络延迟会比较高,但网络延迟对Kafka的影响较小。
在kafka采用的大体方案中,引入了ISR概念:Leader维护了一个动态的in-sync replica set (ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就会给follower发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由replica.lag.time.max.ms参数设定。Leader发生故障之后,就会从ISR中选取新的leader。这样就可以解决(leader收到数据,所有follower都开始同步数据,但有一个follower,因为某种故障,迟迟不能与leader进行同步,那leader就要一直等下去,直到它完成同步,才能发送ack)的问题
ack应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等ISR中的follower全部接收成功。Kafka提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置
| ack参数配置 | 说明 |
|---|---|
| 0 | producer不等待broker的ack,这一操作提供了一个最低的延迟,broker一接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据 |
| 1 | producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据 |
| -1(all) | producer等待broker的ack,partition的leader和follower全部落盘成功后才返回ack。但是如果在follower同步完成后,broker发送ack之前,leader发生故障,那么会造成数据重复。 |
ack=1数据丢失

ack=-1数据重复
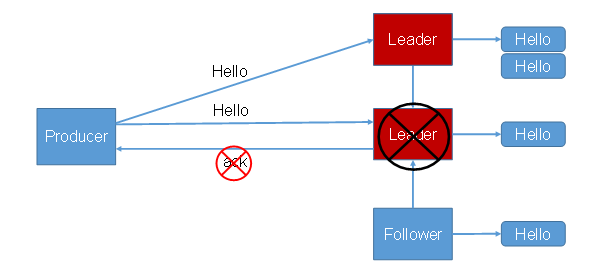
故障处理细节HW和LEO

LEO:指的是每个副本最大的offset;
HW:指的是消费者能见到的最大的offset,ISR队列中最小的LEO
follower故障:follower发生故障后会被临时踢出ISR,等待该follower恢复后,follower会读取本地磁盘记录的上次HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。等待follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR
leader故障:leader发生故障之后,会从ISR中选取一个新的leader,之后,为保证多个副本之间数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。这样能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复
Exactly Once语义
将服务器的ACK级别设置为-1.可以保证producer到server之间不会丢失数据(但是不能保证重重数据),即At Least Once语义。相对的,将服务器级别设置为0,可以保证生产者每条消息只会被发送一次(但是不能保证数据不丢失),即At Most Once语义。
At Least Once可以保证数据不丢失,但是不能保证数据不重复;相对的,At Least Once可以保证数据不重复,但是不能保证数据不丢失。**但是,对于一些非常重要的信息,比如说交易数据,下游数据消费者要求数据既不重复也不丢失,即Exactly Once语义。**在0.11版本以前的Kafka,对此是无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局去重。对于多个下游应用的情况,每个都需要单独做全局去重,这就对性能造成了很大影响。
0.11版本的Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指Producer不论向Server发送多少次重复数据,Server端都只会持久化一条。幂等性结合At Least Once语义,就构成了Kafka的Exactly Once语义。即:At Least Once + 幂等性 = Exactly Once
要启用幂等性,只需要将Producer的参数中enable.idompotence设置为true即可。Kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。开启幂等性的Producer在初始化的时候会被分配一个PID,发往同一Partition的消息会附带Sequence Number。而Broker端会对
Kafka从0.11版本开始引入了事务支持。事务可以保证Kafka在Exactly Once语义的基础上,生产和消费可以跨分区和会话,要么全部成功,要么全部失败
Producer事务:为了实现跨分区跨会话的事务,需要引入一个全局唯一的Transaction ID,并将Producer获得的PID和Transaction ID绑定。这样当Producer重启后就可以通过正在进行的Transaction ID获得原来的PID。为了管理Transaction,Kafka引入了一个新的组件Transaction Coordinator。Producer就是通过和Transaction Coordinator交互获得Transaction ID对应的任务状态。Transaction Coordinator还负责将事务所有写入Kafka的一个内部Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以得到恢复,从而继续进行
Consunmer事务:上述事务机制主要是从Producer方面考虑,对于Consumer而言,事务的保证就会相对较弱,尤其时无法保证Commit的信息被精确消费。这是由于Consumer可以通过offset访问任意信息,而且不同的Segment File生命周期不同,同一事务的消息可能会出现重启后被删除的情况
Kafka消费者
消费方式
consumer采用pull(拉)模式从broker中读取数据
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout
分区分配策略
一个consumer group中有多个consumer,一个 topic有多个partition,所以必然会涉及到partition的分配问题,即确定哪个partition由哪个consumer来消费
Kafka有两种分配策略,一是RoundRobin,一是Range
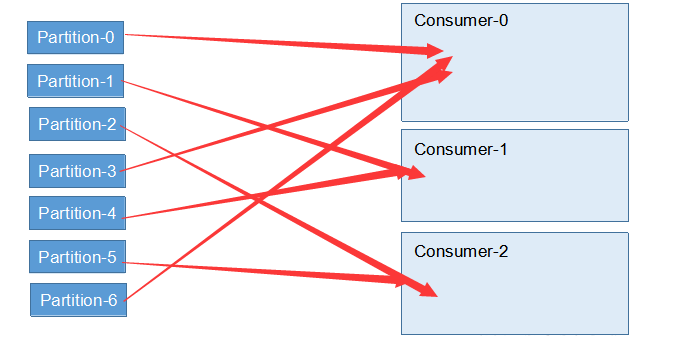
分区分配策略RoundRobin轮询
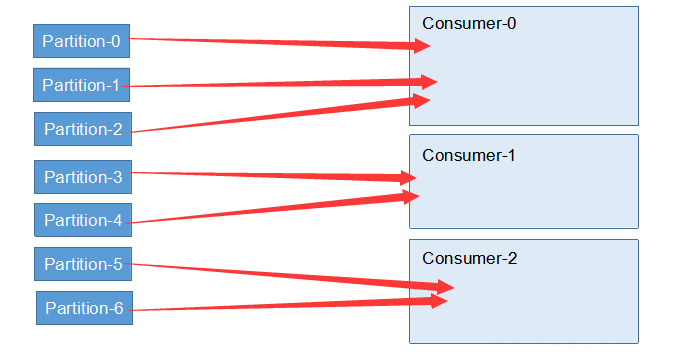
分区分配策略Range,取模
offset的维护
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费
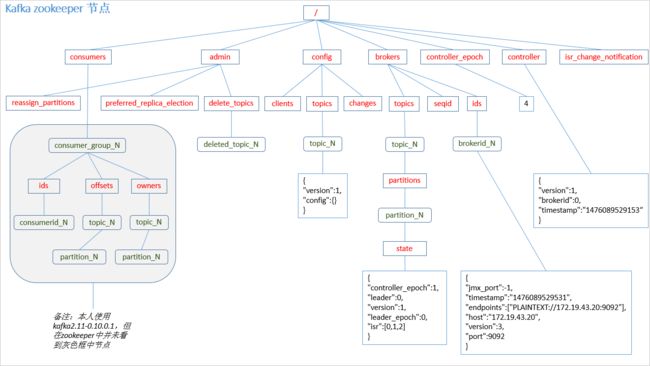
Kafka 0.9版本之前,consumer默认将offset保存在Zookeeper中,从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets
读取__consumer_offsets
修改配置文件consumer.properties
exclude.internal.topics=false
读取offset数据
# 0.11.0.0之前版本
bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper hadoop102:2181 --formatter "kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning
# 0.11.0.0之后版本(含)
bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper hadoop102:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning
指定消费者组消费数据
kafka-console-consumer.sh --bootstrap-server hadoop102:2181 --topic first --from-beginning --consumer-property group.id='test'
Kafka API操作
引入依赖
<dependencies>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>2.4.1version>
dependency>
dependencies>
Producer API
Kafka的Producer发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程——main线程和Sender线程,以及一个线程共享变量——RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka broker
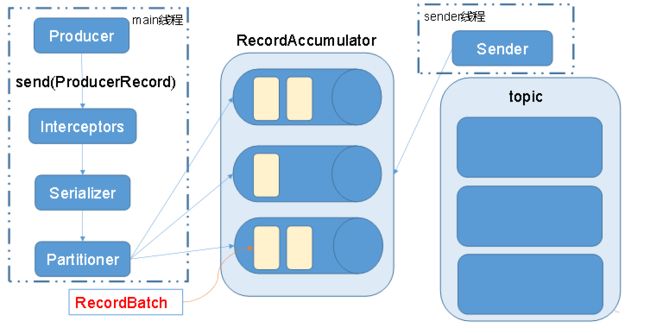
batch.size:只有数据积累到batch.size之后,sender才会发送数据。
linger.ms:如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据
不带回调函数发送
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "bigdata100:9092");
properties.put(ProducerConfig.ACKS_CONFIG, "all");
//重试次数
properties.put(ProducerConfig.RETRIES_CONFIG, 1);
//批次大小 16k
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
//等待时间
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
//RecordAccumulator缓冲区大小 32M
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// 序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
ProducerRecord producerRecord = new ProducerRecord<String, String>("bigdata","czs", "hello world");
producer.send(producerRecord)
producer.close();
带回调函数发送
回调函数会在producer收到ack时调用,为异步调用,该方法有两个参数,分别是RecordMetadata和Exception,如果Exception为null,说明消息发送成功,如果Exception不为null,说明消息发送失败。消息发送失败会自动重试,不需要在回调函数中手动重试
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "bigdata100:9092");
properties.put(ProducerConfig.ACKS_CONFIG, "all");
//重试次数
properties.put(ProducerConfig.RETRIES_CONFIG, 1);
//批次大小 16k
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
//等待时间
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
//RecordAccumulator缓冲区大小 32M
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// 序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
ProducerRecord producerRecord = new ProducerRecord<String, String>("bigdata","czs", "hello world");
producer.send(new ProducerRecord<>("first", 0, "czs", "hello world"), (metadata, exception) -> {
if (exception == null) {
System.out.println(metadata.partition() + "---" + metadata.offset());
} else {
exception.printStackTrace();
}
});
producer.close();
同步发送
同步发送的意思就是,一条消息发送之后,会阻塞当前线程,直至返回ack。由于send方法返回的是一个Future对象,根据Futrue对象的特点,我们也可以实现同步发送的效果,只需在调用Future对象的get方发即可。
ProducerRecord producerRecord = new ProducerRecord<String, String>("bigdata","czs", "hello world");
producer.send(producerRecord).get();
Consumer API
Consumer消费数据时的可靠性是很容易保证的,因为数据在Kafka中是持久化的,故不用担心数据丢失问题。由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。所以offset的维护是Consumer消费数据是必须考虑的问题。
自动提交offset
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "bigdata100:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "czs");
// 开启自动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 自动提交时间
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
kafkaConsumer.subscribe(Collections.singletonList("bigdata"));
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.key() + "---" + consumerRecord.value());
}
}
}
手动提交offset
虽然自动提交offset十分简介便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此Kafka还提供了手动提交offset的API。
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次poll的一批数据最高的偏移量提交;不同点是,commitSync阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而commitAsync则没有失败重试机制,故有可能提交失败。
由于同步提交offset有失败重试机制,故更加可靠
// 同步提交
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "bigdata100:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "czs");
// 关闭自动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
kafkaConsumer.subscribe(Collections.singletonList("bigdata"));
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.key() + "---" + consumerRecord.value());
}
//同步提交,当前线程会阻塞直到offset提交成功
kafkaConsumer.commitSync();
}
}
虽然同步提交offset更可靠一些,但是由于其会阻塞当前线程,直到提交成功。因此吞吐量会收到很大的影响。因此更多的情况下,会选用异步提交offset的方式
// 异步提交
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "bigdata100:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "czs");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
kafkaConsumer.subscribe(Collections.singletonList("bigdata"));
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.key() + "---" + consumerRecord.value());
}
// 异步提交
kafkaConsumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (exception != null) {
System.err.println("Commit failed for" + offsets);
}
}
});
}
}
自定义offset
Kafka 0.9版本之前,offset存储在zookeeper,0.9版本及之后,默认将offset存储在Kafka的一个内置的topic中。除此之外,Kafka还可以选择自定义存储offset。
offset的维护是相当繁琐的,因为需要考虑到消费者的Rebalace。
当有新的消费者加入消费者组、已有的消费者推出消费者组或者所订阅的主题的分区发生变化,就会触发到分区的重新分配,重新分配的过程叫做Rebalance。
消费者发生Rebalance之后,每个消费者消费的分区就会发生变化。因此消费者要首先获取到自己被重新分配到的分区,并且定位到每个分区最近提交的offset位置继续消费。
要实现自定义存储offset,需要借助ConsumerRebalanceListener,其中提交和获取offset的方法,需要根据所选的offset存储系统自行实现
private static Map<TopicPartition, Long> currentOffset = new HashMap<>();
public static void main(String[] args) {
//创建配置信息
Properties props = new Properties();
//Kafka集群
props.put("bootstrap.servers", "hadoop102:9092");
//消费者组,只要group.id相同,就属于同一个消费者组
props.put("group.id", "test");
//关闭自动提交offset
props.put("enable.auto.commit", "false");
//Key和Value的反序列化类
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//创建一个消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//消费者订阅主题
consumer.subscribe(Arrays.asList("first"), new ConsumerRebalanceListener() {
//该方法会在Rebalance之前调用
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
commitOffset(currentOffset);
}
//该方法会在Rebalance之后调用
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
currentOffset.clear();
for (TopicPartition partition : partitions) {
consumer.seek(partition, getOffset(partition));//定位到最近提交的offset位置继续消费
}
}
});
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);//消费者拉取数据
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
currentOffset.put(new TopicPartition(record.topic(), record.partition()), record.offset());
}
commitOffset(currentOffset);//异步提交
}
}
//获取某分区的最新offset
private static long getOffset(TopicPartition partition) {
return 0;
}
//提交该消费者所有分区的offset
private static void commitOffset(Map<TopicPartition, Long> currentOffset) {
}
自定义Interceptor
public class TimeInterceptor implements ProducerInterceptor<String, String> {
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
return new ProducerRecord<String, String>(record.topic(), record.partition(), record.key(), System.currentTimeMillis() + "," + record.value());
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
public class CounterInterceptor implements ProducerInterceptor<String, String> {
private int success;
private int error;
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (metadata != null) {
success++;
} else {
error++;
}
}
@Override
public void close() {
System.out.println("success: " + success);
System.out.println("error: " + error);
}
@Override
public void configure(Map<String, ?> configs) {
}
}
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "bigdata100:9092");
props.put("acks", "all");
props.put("retries", 3);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 拦截器
ArrayList<String> interceptors = new ArrayList<>();
interceptors.add("czs.study.kafka.interceptor.TimeInterceptor");
interceptors.add("czs.study.kafka.interceptor.CounterInterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
String topic = "first";
Producer<String, String> producer = new KafkaProducer<>(props);
// 3 发送消息
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "message" + i);
producer.send(record);
}
// 4 一定要关闭producer,这样才会调用interceptor的close方法
producer.close();
}
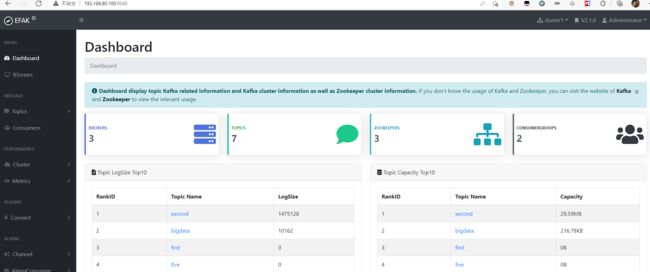
Kafka监控
使用kafka-eagle监控kafka,下载地址Download - EFAK (kafka-eagle.org)
准备环境
修改kafka目录下的conf中的kafka-server-start.sh,修改之后在启动Kafka之前要分发之其他节点
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"sh
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
解压官网下载的kafka-eagle里面的kafka-eagle-web
tar -zxvf kafka-eagle-web-xxx -C /opt/module/
给启动文件执行权限,在kafka-eagle-web的bin目录下
chmod 777 ke.sh
修改配置文件,在kafka-eagle-web的conf目录下的system-config.properties
######################################
# multi zookeeper&kafka cluster list
######################################
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=hadoop102:2181,hadoop103:2181,hadoop104:2181
######################################
# kafka offset storage
######################################
cluster1.kafka.eagle.offset.storage=kafka
######################################
# enable kafka metrics
######################################
kafka.eagle.metrics.charts=true
kafka.eagle.sql.fix.error=false
######################################
# kafka jdbc driver address
######################################
kafka.eagle.driver=com.mysql.cj.jdbc.Driver
kafka.eagle.url=jdbc:mysql://bigdata100:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=root
添加环境变量,source /etc/profile
export KE_HOME=/opt/module/eagle
export PATH=$PATH:$KE_HOME/bin
启动eagle
bin/ke.sh start
Kafka调优
Kafka机器数量计算
Kafka机器数量= 2 *(峰值生产速度 * 副本数 / 100)+ 1
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量
峰值生产速度:峰值生产速度可以压测得到。
副本数:副本数默认是1个,在企业里面2-3个都有,2个居多。副本多可以提高可靠性,但是会降低网络传输效率。
举例:比如峰值生产速度是50M/s。副本数为2。Kafka机器数量 = 2 *(50 * 2 / 100)+ 1 = 3台
Kfka压力测试
kafka压测
用Kafka官方自带的脚本,对Kafka进行压测kafka-consumer-perf-test.sh、kafka-producer-perf-test.sh
Kafka压测时,在硬盘读写速度一定的情况下,可以查看到哪些地方出现了瓶颈(CPU,内存,网络IO)。一般都是网络IO达到瓶颈
KafkaProducer压力测试
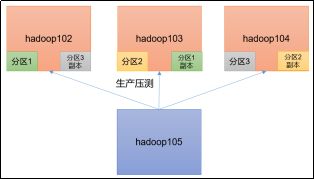
环境准备
hadoop102、hadoop103、hadoop104的网络带宽都设置为100mbps
关闭hadoop102主机,并根据hadoop102克隆出hadoop105(修改IP和主机名称)
hadoop105的带宽不设限
创建一个test topic,设置为3个分区2个副本
bin/kafka-topics.sh --zookeeper bigdata100:2181,bigdata102:2181,bigdata104:2181/kafka --create --replication-factor 2 --partitions 3 --topic test
压力测试
# record-size是一条信息有多大,单位是字节
# num-records是总共发送多少条信息
# throughput 是每秒多少条信息,设成-1,表示不限流,尽可能快的生产数据,可测出生产者最大吞吐量
bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 10000000 --throughput -1 --producer-props bootstrap.servers=bigdata100:9092,bigdata102:9092,bigdata104:9092
压测结果
hadoop102、hadoop103、hadoop104三台集群的网络总带宽30m/s左右,由于是两个副本,所以Kafka的吞吐量30m/s 除2(副本) = 15m/s ,因此网络带宽和副本会影响吞吐量
699884 records sent, 139976.8 records/sec (13.35 MB/sec), 1345.6 ms avg latency, 2210.0 ms max latency.
713247 records sent, 141545.3 records/sec (13.50 MB/sec), 1577.4 ms avg latency, 3596.0 ms max latency.
773619 records sent, 153862.2 records/sec (14.67 MB/sec), 2326.8 ms avg latency, 4051.0 ms max latency.
773961 records sent, 154206.2 records/sec (15.71 MB/sec), 1964.1 ms avg latency, 2917.0 ms max latency.
776970 records sent, 154559.4 records/sec (15.74 MB/sec), 1960.2 ms avg latency, 2922.0 ms max latency.
776421 records sent, 154727.2 records/sec (15.76 MB/sec), 1960.4 ms avg latency, 2954.0 ms max latency.
调整batch.size
batch.size默认值是16k
batch.size较小,会降低吞吐量。比如说,批次大小为0则完全禁用批处理,会一条一条发送消息)
batch.size过大,会增加消息发送延迟。比如说,Batch设置为64k,但是要等待5秒钟Batch才凑满了64k,才能发送出去。那这条消息的延迟就是5秒钟
bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 10000000 --throughput -1 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=500
69169 records sent, 13833.8 records/sec (1.32 MB/sec), 2517.6 ms avg latency, 4299.0 ms max latency.
105372 records sent, 21074.4 records/sec (2.01 MB/sec), 6748.4 ms avg latency, 9016.0 ms max latency.
113188 records sent, 22637.6 records/sec (2.16 MB/sec), 11348.0 ms avg latency, 13196.0 ms max latency.
108896 records sent, 21779.2 records/sec (2.08 MB/sec), 12272.6 ms avg latency, 12870.0 ms max latency.
linger.ms
如果设置batch size为64k,但是比如过了10分钟也没有凑够64k,则可以设置,linger.ms。比如linger.ms=5ms,那么就是要发送的数据没有到64k,5ms后,数据也会发出去。
总结
同时设置batch.size和linger.ms,就是哪个条件先满足就都会将消息发送出去Kafka需要考虑高吞吐量与延时的平衡
KafkaConsumer压力测试
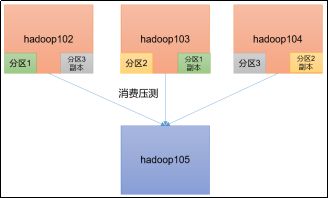
Consumer的测试,如果这四个指标(IO,CPU,内存,网络)都不能改变,考虑增加分区数来提升性能
# --broker-list指定Kafka集群地址
# --topic 指定topic的名称
# --fetch-size 指定每次fetch的数据的大小
# --messages 总共要消费的消息个数
bin/kafka-consumer-perf-test.sh --broker-list hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic test --fetch-size 10000 --messages 10000000 --threads 1
# 测试结果说明
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec
2021-08-03 21:17:21:778, 2021-08-03 21:18:19:775, 514.7169, 8.8749, 5397198, 93059.9514
开始测试时间,测试结束数据,共消费数据514.7169MB,吞吐量8.8749MB/s
调整fetch-size
bin/kafka-consumer-perf-test.sh --broker-list hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic test --fetch-size 100000 --messages 10000000 --threads 1
# 测试结果说明
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec
2021-08-03 21:22:57:671, 2021-08-03 21:23:41:938, 514.7169, 11.6276, 5397198, 121923.7355
总结
吞吐量受网络带宽和fetch-size的影响
Kafka分区数计算
计算步骤
创建一个只有1个分区的topic,测试这个topic的producer吞吐量和consumer吞吐量,假设他们的值分别是Tp和Tc,单位可以是MB/s,然后假设总的目标吞吐量是Tt,那么分区数 = Tt / min(Tp,Tc)
举例:producer吞吐量 = 20m/s;consumer吞吐量 = 50m/s,期望吞吐量100m/s;分区数 = 100 / 20 = 5分区
分区数一般设置为:3-10个
详细说明
kafka分区设计