MySQL增删查改(进阶2)
一、查询
1.聚合查询
1.1聚合函数:
(1)count() 获取整个结果集的行数(数据的数量)
count(某个字段)=count(*)=count(常量值)
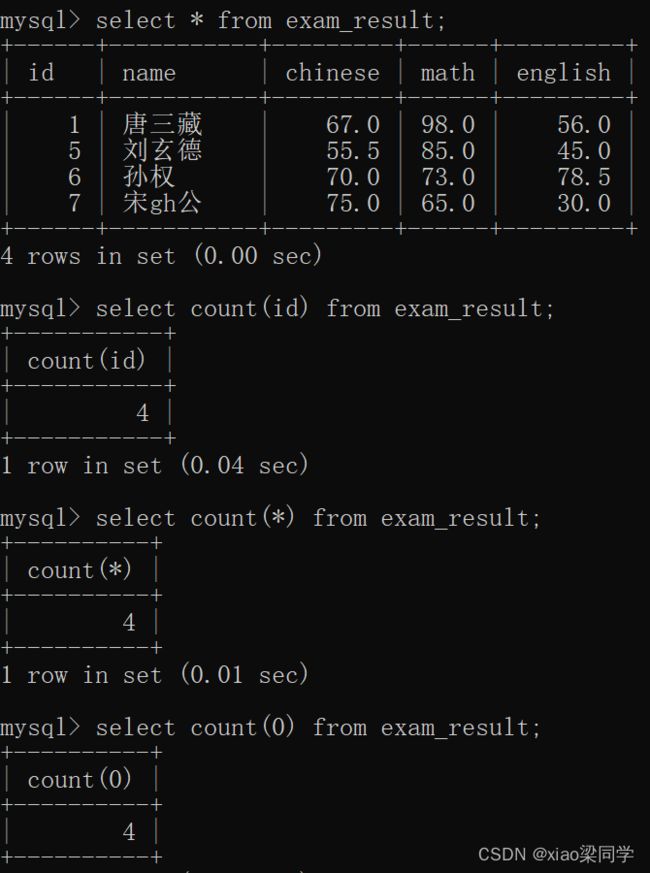
(2)sum(某个字段) 将结果集这个字段求和计算
(3)avg(某个字段) 将结果集这个字段求平均值计算
(4)max(某个字段) 将结果集这个字段取最大值
(5)min(某个字段) 将结果集这个字段取最小值
2-5会将结果集进行聚合操作,只返回一条数据
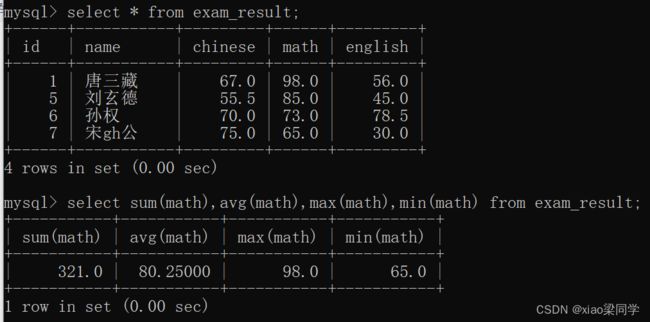
聚合是在 查询返回结果集后再进行聚合的
1.2 group by:分组
语法:select 查询字段 from 表 where 条件 group by 分组字段1,分组字段2
表数据如下:
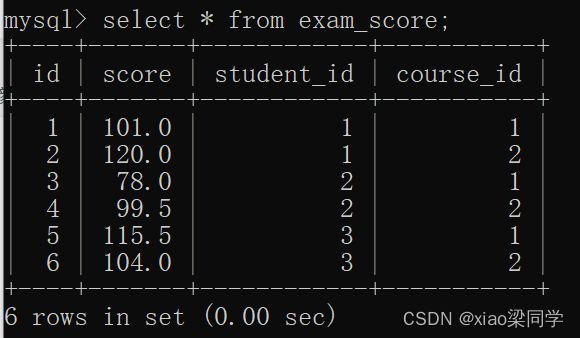
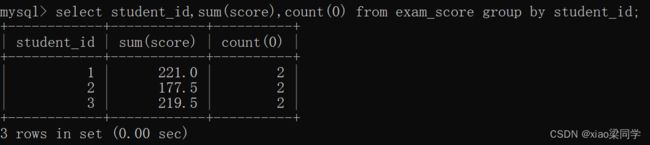
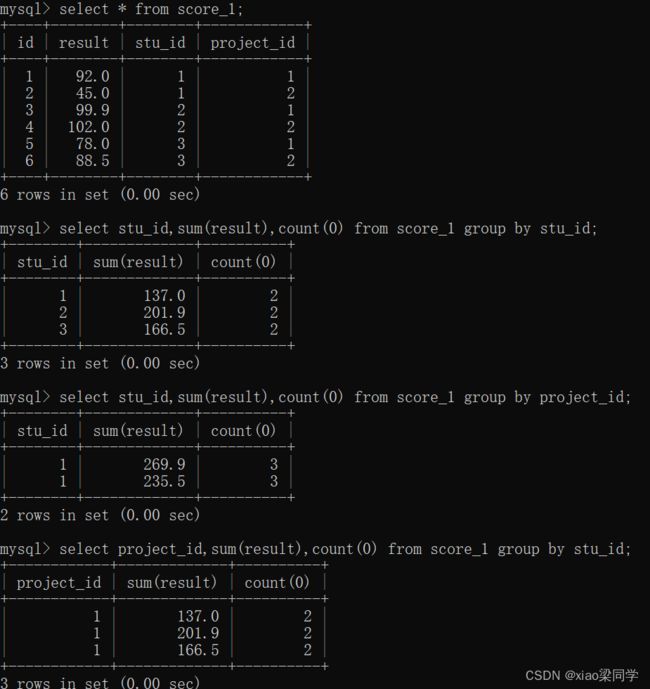
分组查询操作:
查询字段必须是
(1)分组字段
(2)如果分组会造成聚合,非分组字段必须写在聚合函数中;分组不会造成聚合,非分组字段就可以直接写
(3) id是主键,分组不会有聚合操作,非分组字段还是具有真实含义:
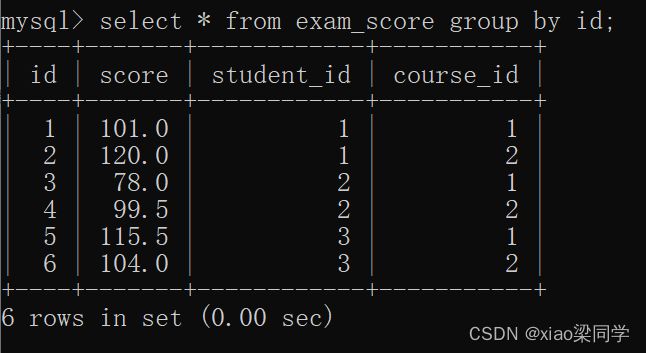
- 对多个字段分组
业务:一个学生,一个课程,在多个学期可以考试
一个学生,考多个课程的考试成绩
学生-->成绩=1:m
学生+课程-->成绩=1:n
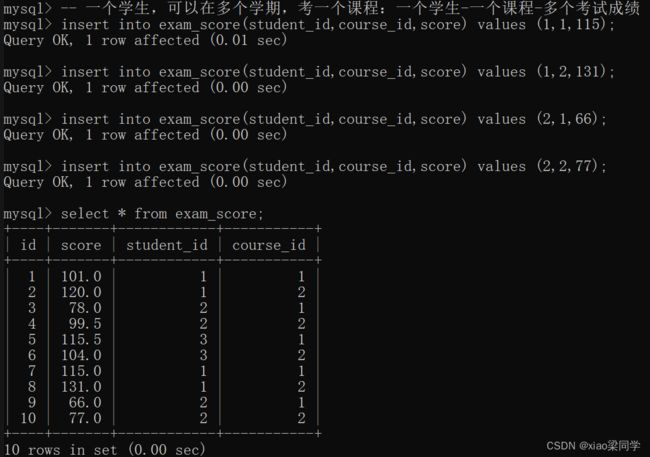
此时多个分组字段就有意义
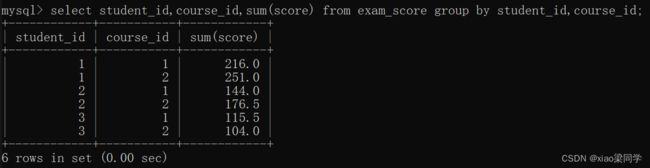
1.3 having:分组后的条件过滤
语法:select 查询字段 from 表 where 条件 group by 分组字段1,分组字段2 having 分组后的条件

因为having是在分组后执行,having中需要使用字段,和分组查询字段,是三个相同的条件
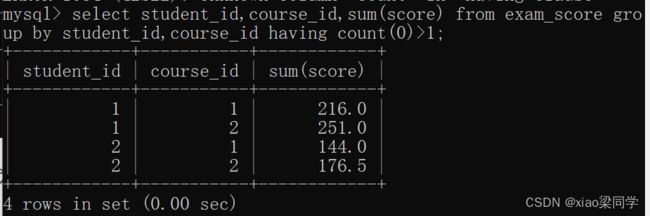
查询字段其实可以包含count(0)
- group by+having操作:
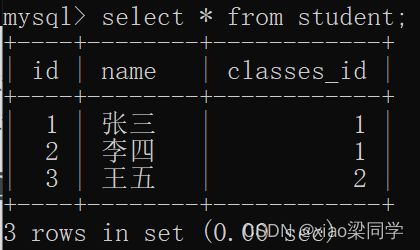
- 查询学生表,学生姓名,班级id重复的就是重复数据
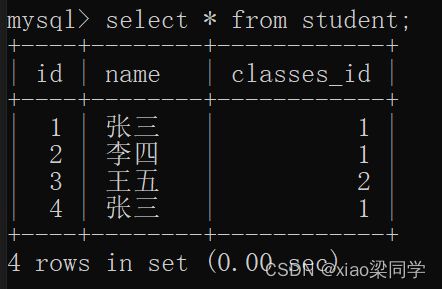
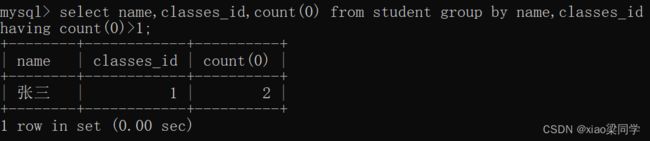
一般来说业务上真实存在的一些bug 特别是一些高并发的场景,就会插入一些重复数据,主键是不同,但是业务上某些字段相同,就可以判定是重复数据
2.联合查询
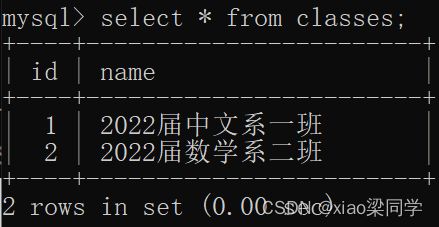
- 多张表之间逗号间隔,返回的就是笛卡尔积
上面两张表的笛卡尔积:
(classes.*,student.*)

但是观察可以知道,上面笛卡尔积的结果有部分数据没有意义(2,4,5条数据没有意义)
(1)遍历第一张表的数据
(2)每条数据与第二张表的所有数据相关联
(3)遍历第二张表的数据
笛卡尔积的结果:就是两张表的每条数据相连接,产生的一个结果集(虚拟表)
结果集的行数=第一张表的行数*第二张表的行数
联合查询:单纯的笛卡尔积返回的结果集进行过滤(把不符合真实业务的数据过滤掉)剩下的就是有意义的。
where条件过滤之后:(表名.字段名来判断是否相同--->可能比较麻烦,那么可以使用表的别名)

使用别名:(别名.字段名)
![]()
结果集字段可能有重复,建议:若只是简单查询数据则写--->*;写项目把查询字段写全(如下)
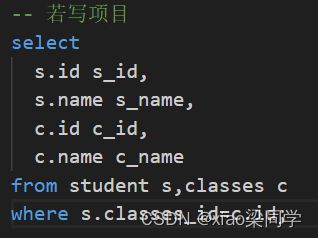
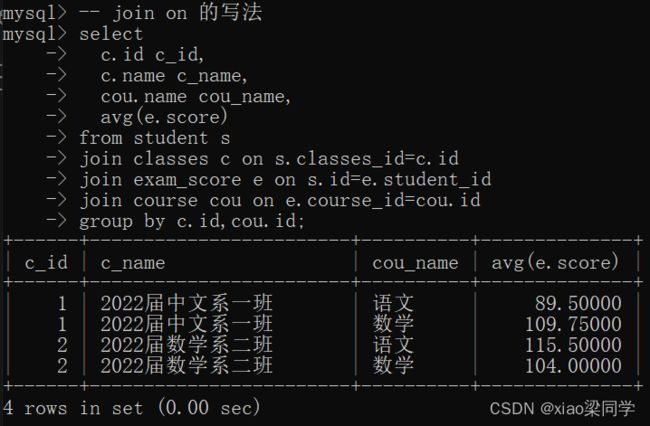
2.1内连接
语法:
(1)select 查询字段 from 表1,表2 where 连接条件 and 其他条件
(2)select 查询字段 from 表1 [inner] join 表2 on 连接条件 and 其他条件
连接条件和其他条件没有区别;[inner]表示可写可不写
多张表也可以进行关联,比如:
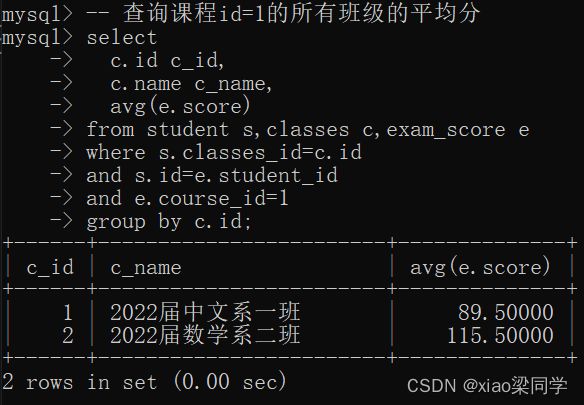
查询所有班级在id=1的课程的平均分:
(1)查询所有学生,班级,考试成绩的信息
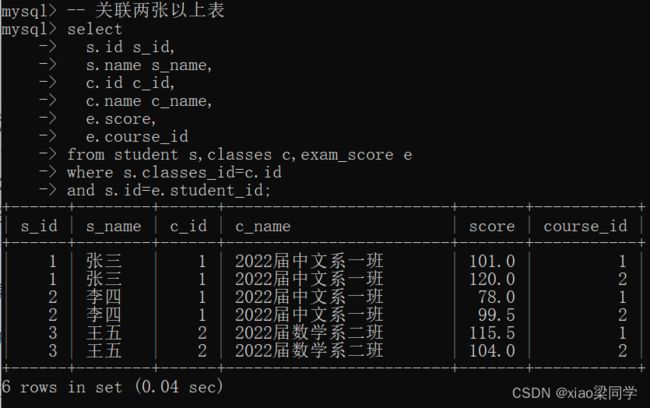
(2)where查询条件 课程id=1
(3)对班级id字段进行分组,取score的聚合avg
扩展:
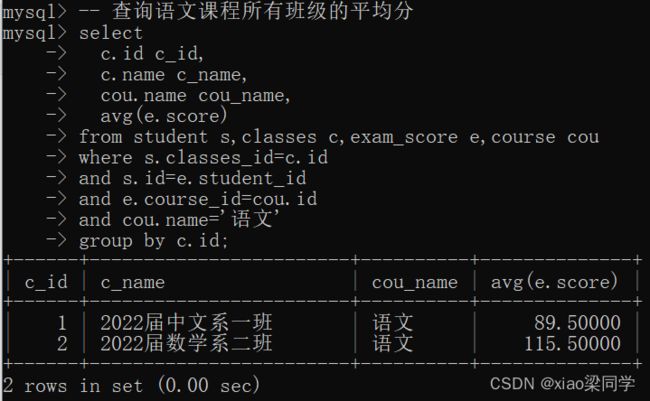
(1)查询语文课程所有班的平均分:
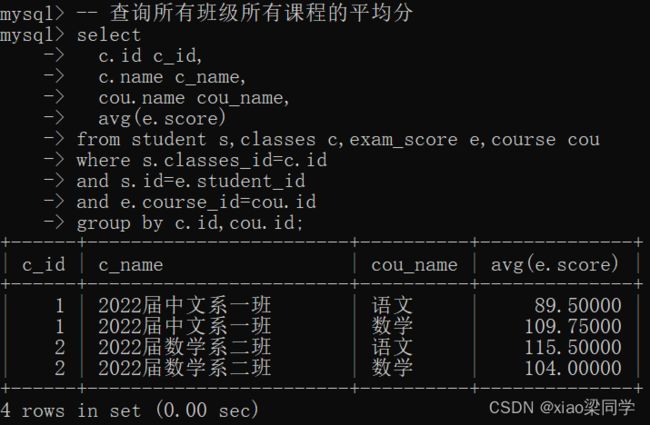
(2) 所有班级所有课程的平均分:
- classes <=>student 一对多
- student <=> exam_score 一对多
- course <=>exam_score 一对多
- student <=> course 多对多
班级表(classes)通过学生表(student),就可以和考试成绩表(exam_score)建立关系
2.2外连接
只能使用join on的写法,且left join表示左外连接;right join表示右外连接
语法:
select 查询字段 from 左表 left join 右表 on 连接条件 where 其他条件
select 查询字段 from 左表 right join 右表 on 连接条件 where 其他条件
观察外连接和内连接查询结果的区别 :
- 内连接:关联学生和班级班级中没有学生的就无法显示;
- 外连接:班级表作为外表,即使班级没有学生,也可以显示;
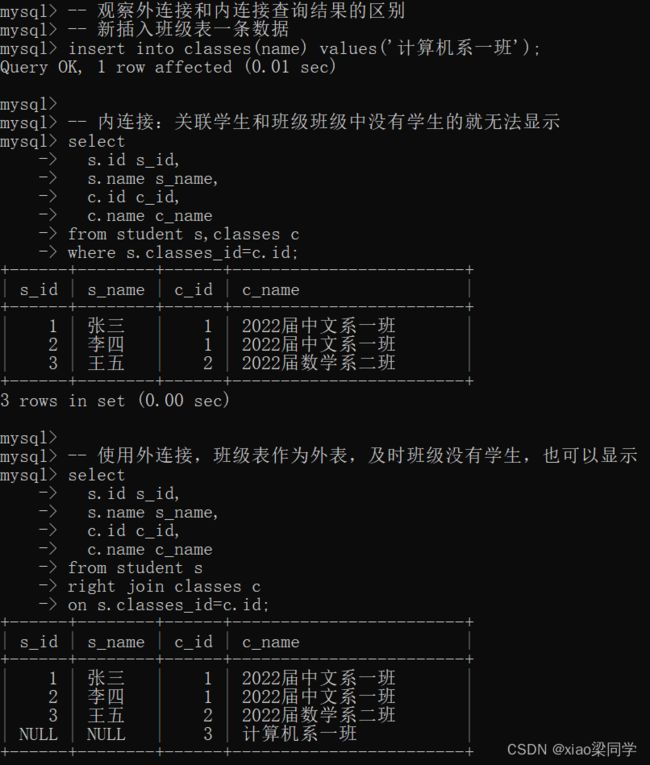
连接条件不满足的时候,外表的数据存在,关联的另一张表没有关联数据,还是会返回;
外连接,是否返回这条数据=连接条件满足 | 外表存在;
其他条件,就必须满足
内连接VS外连接:
内连接必须满足连接条件+其他条件才会返回;
外连接满足连接条件+其他条件或者满足其他条件但外表存在(即使不满足连接条件)也可以返回;
2.3自连接
一张表,自己连接自己。
这里是同一张表,不同行,不同字段进行比较
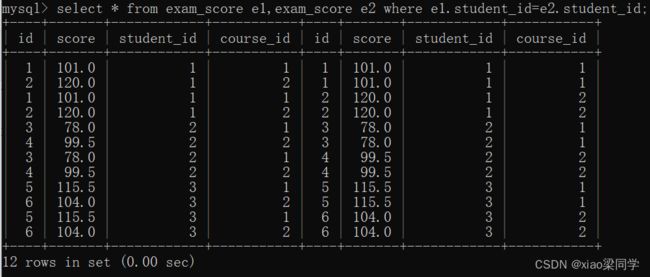
(1)先取笛卡尔积观察结果
![]()
(2)取同一个学生,语文成绩比数学成绩高:按学生id作为连接条件
(3)第一张表取语文成绩,第二张表取数学成绩
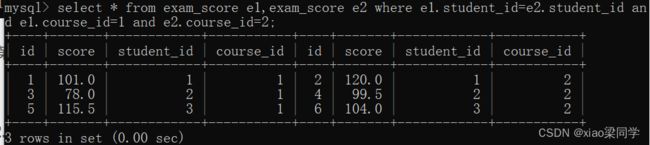
(4)取出来后进行比较

查询语文成绩大于数学成绩:
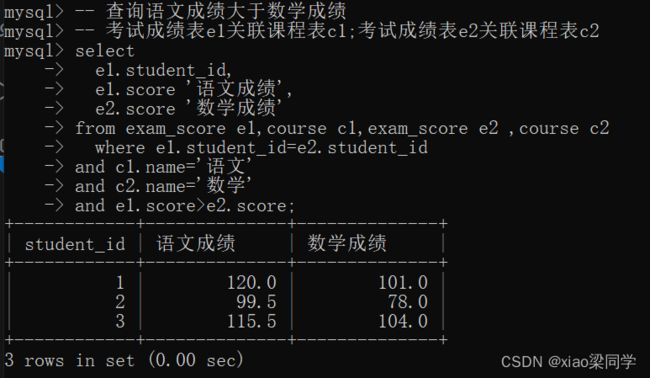
e1与e2自连接(自身对成绩进行比较),e1与c1连接(取语文成绩),e2与c2连接取数学成绩
2.4子查询
又叫嵌套查询
select 语句,用()包起来,用在其他的地方:如常量、表、in
(1)子查询返回一行一列的时候,可以当作常量
查询张三同学的同班同学:

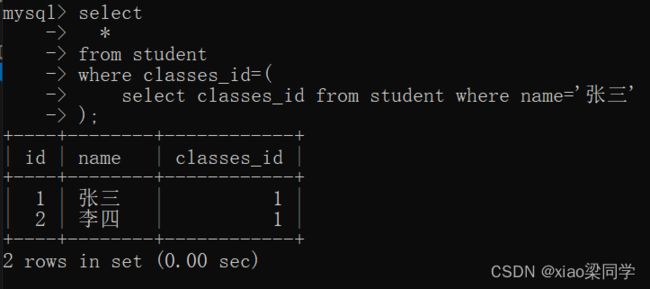
(2)[not] in(多个常量值,逗号间隔)--->子查询:返回多行数据
①一个字段in(子查询)--->返回多行数据,一个字段
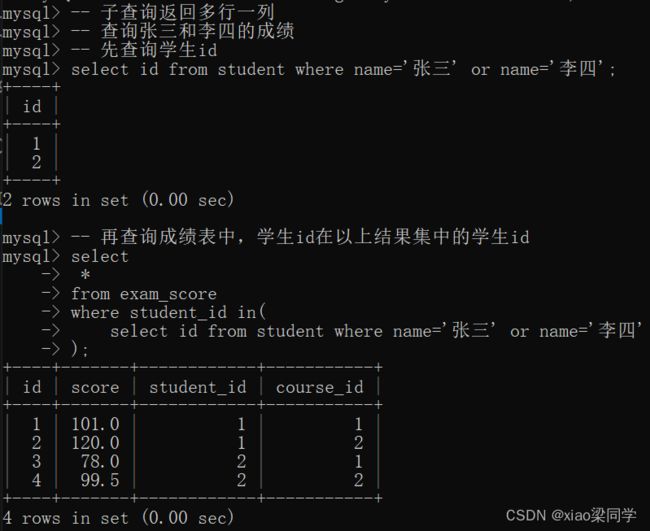
②(多行数据)in(子查询)--->返回多行数据,查询字段和in前面的字段数量、顺序一致
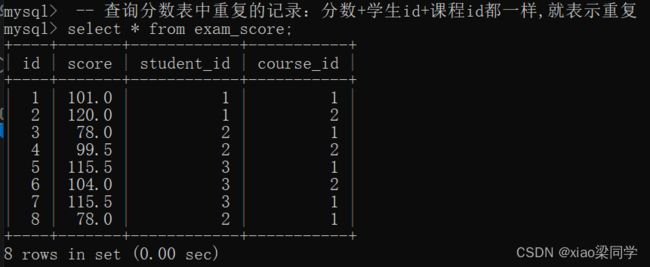
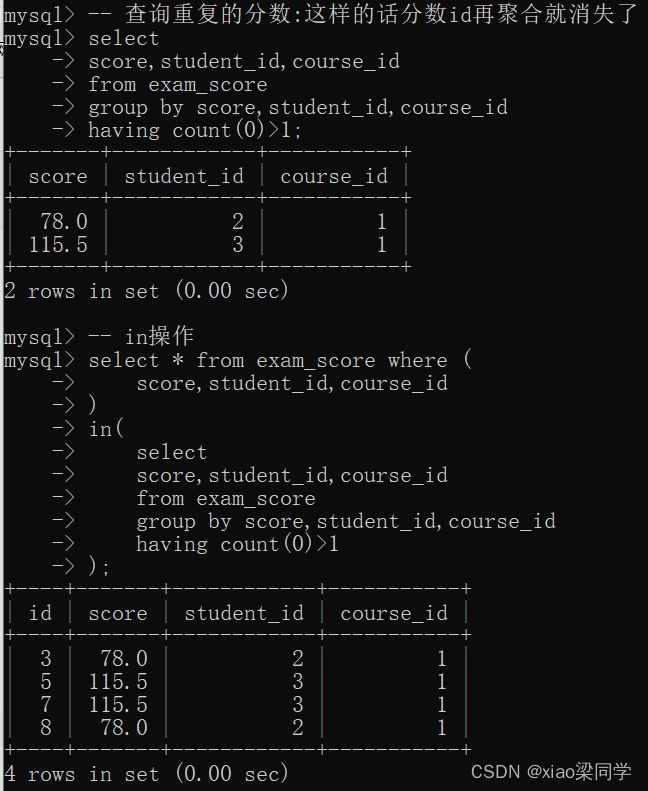
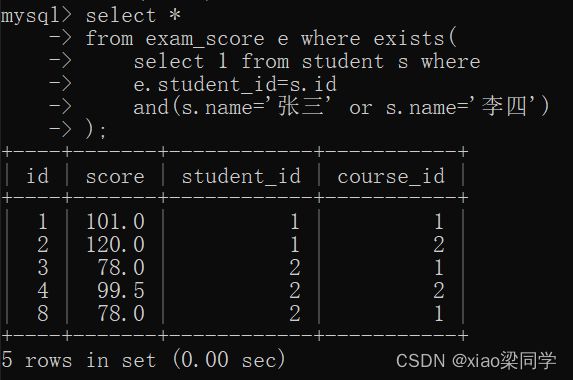
(3)not exists
(4)子查询作为临时表
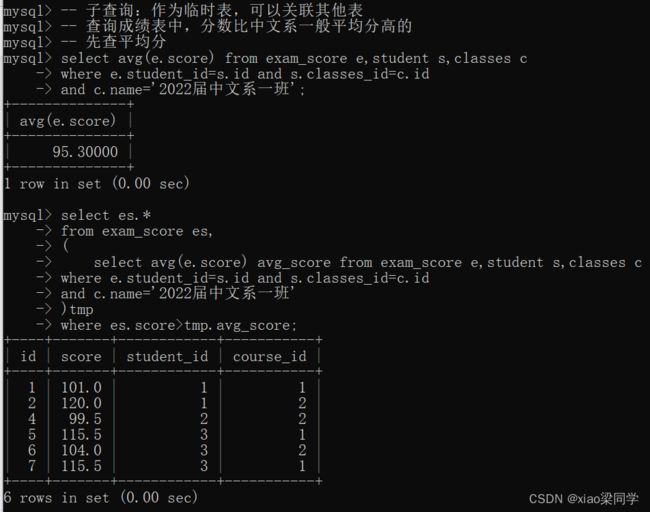
2.5合并查询
2.5.1union
取两个结果集的并集,并去重(按结果集所有查询字段去重)
单表的结果集取并集其实是可以使用or实现的,但是union是使用两个结果集(不一定是一张表)

2.5.2union all
取两个结果集的并集
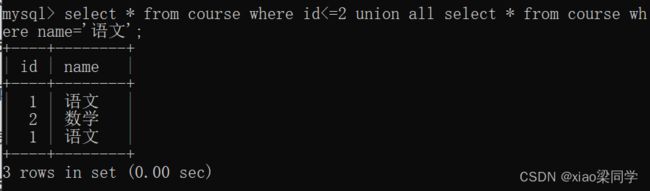
两个结果集的查询字段,顺序和数量要一致;