mybatis处理有关联关系(多对多)的分页查询
一、业务场景
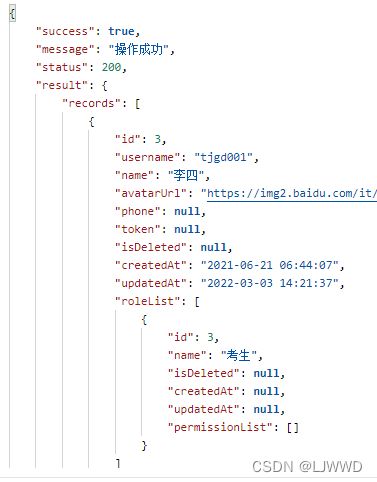
需要给前端返回下图所示格式的数据,其中user和role是多对多关系。
MyBatis-Plus如何自定义分页
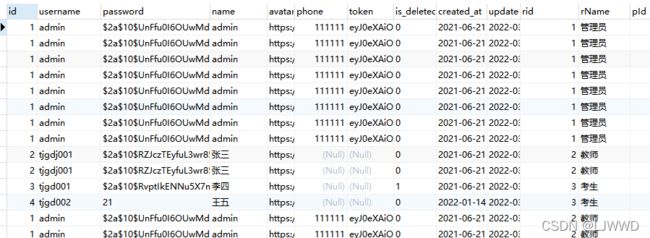
在xml中写完代码,使用MyBatis-Plus自定义分页之后发现下面的一些参数对不上。

发生这个情况的主要原因是使用了join,导致数据库返回的数据有重复。而MyBatis-Plus中是根据返回的记录做分页。
如果下图中size=3,current=1,则只会返回前三条记录,即只会返回admin这一个用户。
二、解决方案
1. 针对sql解决问题
首先是最开始有问题的sql代码,如上图。
a. 普通查询(不分页)
select u.*,r.id rid,r.name rName,p.id pId,p.`name` pName,p.url url,p.p_id pPId,p.icon icon from
user u
inner join user_role u_r
on u.id=u_r.user_id
INNER JOIN role r
on r.id=u_r.role_id
left join role_permission r_p
on r.id=r_p.role_id
left join permission p
on p.id=r_p.permission_id
稍微改进之后发现多对多关系下不能对role和permission中的字段进行搜索。
b. 对于user分页(不能添加role和permission的搜索条件)
select u.*,r.id rid,r.name rName,p.id pId,p.`name` pName,p.url url,p.p_id pPId,p.icon icon from
(select * from user limit 0,3) u
inner join user_role u_r
on u.id=u_r.user_id
INNER JOIN role r
on r.id=u_r.role_id
left join role_permission r_p
on r.id=r_p.role_id
left join permission p
on p.id=r_p.permission_id
c. 加入group_concat()(突然想到这个函数,就试了试,可以用来获取总记录数total)
select u.*,group_concat(DISTINCT r.id ) rId,group_concat(DISTINCT r.`name` ) role ,group_concat(p.id ) pId,group_concat(p.`name` ) permission,group_concat(p.`url` ) url,group_concat(p.`p_id` ) pPId,group_concat(p.`icon` ) icon
from user u
left join user_role u_r
on u.id=u_r.user_id
left JOIN role r
on r.id=u_r.role_id
left join role_permission r_p
on r.id=r_p.role_id
left join permission p
on p.id=r_p.permission_id
where r.id = 1
GROUP BY u.id
MySQL教程之concat以及group_concat的用法
效果如下。

最后想到,如果先使用user.id in (筛选出的用户id)选出满足的user,再进行join连接即可。
对于筛选出的用户id通过方案c来筛选就行了。
d. 对于user分页(可以添加role和permission的搜索条件)
select u.*,r.id rid,r.name rName,p.id pId,p.`name` pName,p.url url,p.p_id pPId,p.icon icon from user u
inner join user_role u_r
on u.id=u_r.user_id
INNER JOIN role r
on r.id=u_r.role_id
left join role_permission r_p
on r.id=r_p.role_id
left join permission p
on p.id=r_p.permission_id
where u.id in (
select id from
(select u.id
from user u
left join user_role u_r
on u.id=u_r.user_id
left JOIN role r
on r.id=u_r.role_id
left join role_permission r_p
on r.id=r_p.role_id
left join permission p
on p.id=r_p.permission_id
where r.id in (2,3)
GROUP BY u.id order by id asc limit 0,5) t1
)
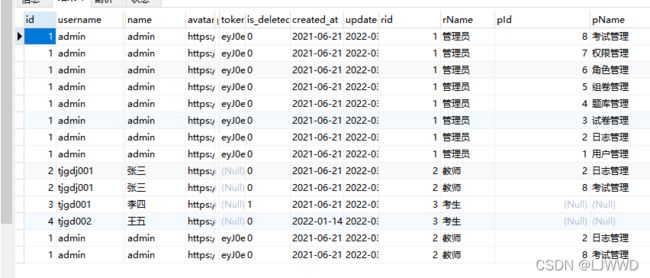
成功返回我想要的数据。
2. 获取所有数据,针对java代码中做分页
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import java.util.ArrayList;
import java.util.List;
/**
* 把所有数据传到java代码中做分页处理
*/
public class ListPageUtil {
/**
* 分页查询
* @param current:页码
* @param size:每页条数
* @param list:集合
* @return IPage
*/
public static <T> Page<T> getUserPage(List<T> list,Integer current, Integer size) {
Page<T> page = new Page<>();
// List data = new ArrayList<>();
Integer total = list.size();
Integer pages = total%size==0 ? total/size : (total/size+1);
try {
if (current*size-1<=list.size()){
list = list.subList((current-1)*size,current*size-1);
}else {
list = list.subList((current-1)*size,list.size());
}
}catch (Exception e){
System.err.println(e.getMessage());
list = new ArrayList<>();
}
page.setCurrent(current);
page.setSize(size);
page.setTotal(total);
page.setPages(pages);
page.setRecords(list);
return page;
}
}
总结
方案1需要查询两次数据库。第一次获取数据,第二次获取同等搜索条件的所有记录的总数。
方案2这个方法数据量大了之后会比较慢。
性能优化
如果需要考虑到性能方面的话采用方案1,并在上文的基础上做些许优化。首先使用覆盖索引查询出第m页的n条数据的id,然后通过where id in ()获取这n条数据。并且通过一起mysql请求获取数据。