刨析django----配置全文索引
索引定义
在数据库中对表的一列或者多列进行排序的一种数据结构,类似于书籍中的目录,可以帮助我们快速查询所需要的数据。在数据量很大时,合理使用索引的表相当于一辆法拉利,而没有使用索引的表就相当于一辆人力三轮车,查询效率相差甚远。
虽然索引可以提高数据检索的效率,但是会降低数据库更新的效率,因为在更新数据时,索引也要进行相应的更新,耗费一定的资源。所以索引经常用于数据量较大的表中,且经常被查询,很少更新的那些字段。
索引的数据结构及类别
经常使用的关系型数据库mysql,它的索引是基于B+树的数据结构;
B+树是B树的一种改进版,具有更高的查询效率。
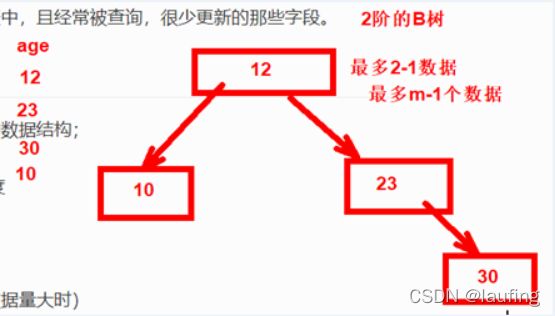
如下为简单的2阶B树:
主键索引, 主键自动建立索引,进行排序,加快检索速度
单列索引 ,单个列上的索引
复合索引 (建立在多列组合的索引)
唯一索引(字段的值必须是唯一的)
全文索引(类似模糊查询,但比模糊查询效率高,尤其数据量大时)
全文索引与模糊查询
全文索引,通过一种相似度方式,查询所需要的数据字段的类型必须是字符或者文本类型,类似于模糊查询,但比模糊查询效率高,尤其是数据量较大时。比如百度、谷歌搜索引擎就是使用全文索引进行文本检索。
模糊查询,即like ‘%xxxx%’, 这种模糊查询对于小数据量的查询效果还可以,对于大数据量,查询性能明显下降。
所以,这里使用全文索引方式,来实现商品的搜索。
haystack+whoosh
配置全文索引,为搜索栏提供搜索功能
-
django-haystack 是专门提供搜索功能的 django 第三方应用,它还支持 Elasticsearch、Whoosh、Xapian 等多种搜索引擎,配合中文自然语言处理库 jieba 分词,就可以提供一个效果不错的文字搜索系统。
-
whoosh,whoosh 是一个由 Python 实现的全文搜索引擎,没有二进制文件等,比较小巧,配置简单方便,但是whoosh 自带的是英文分词,对中文的分词支持不太好,所以使用 jieba 替换whoosh 的分词组件。
-
使用pip 安装这些包
#Ubuntu系统
sudo pip3 install django-haystack whoosh jieba
#windows
pip install django-haystack whoosh jieba -i https://pypi.tuna.tsinghua.edu.cn/simple/
haystack版本
haystack文档
- 配置haystack
#settings.py
INSTALLED_APPS = [
...
'haystack',
]
# 配置全文搜索
# 指定搜索引擎
HAYSTACK_CONNECTIONS = { #指定搜索引擎
'default': {
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',#需自定义
'PATH': os.path.join(BASE_DIR, 'whoosh_index'), #索引文件存放的目录,建立索引时自动创建
},
}
# 设置为每 10 项结果为一页,默认是 20 项为一页
HAYSTACK_SEARCH_RESULTS_PER_PAGE = 10
# 当数据库改变时,自动更新索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
- 对某app中的模型类建立全文索引(索引类)
#app>search_indexes.py 创建search_indexes.py文件
from .models import Book
from haystack import indexes
#创建一个索引类
class BookIndex(indexes.SearchIndex,indexes.Indexable):
text = indexes.CharField(document=True,use_template=True)#固定语句,惯例使用’text‘命名字段
#document=True,说明搜索引擎使用该字段内容作为索引来检索,只能有一个字段具有该属性True
#use_template=True 使用模板建立索引
#换名字的时候,注意配置HAYSTACK_DOCUMENT_FIELD = "XXX"
#templates/search/indexes/yourapp/_text.txt
#如templates/search/indexes/app/book_text.txt
#{{ object.title }} 必须object
#{{ object.content }}
#对Book.title/Book.content两个字段建立索引
def get_model(self): #必须
return Book
def index_queryset(self, using=None):
"""Used when the entire index for model is updated."""
return self.get_model().objects.all()
- 配置url
#主路由中
urlpatterns = [
...,
url(r"^search/",include("haystack.urls")),
]
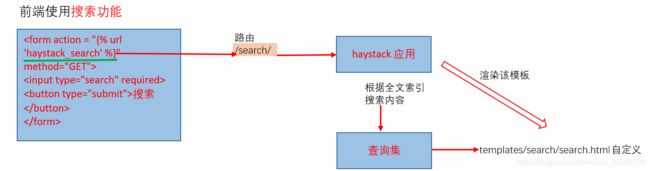
- 前端搜索表单
haystack源码中响应就是渲染templates/search/search.html
前后端不分离时,自定义search.html结构
#haystack_search 视图命名空间固定
#GET 请求action时 haystack应用自动处理,并返回templates/search/search.html
#该模板需要创建
<form method="get" action="{% url 'haystack_search' %}">
<input type="search" name="q" placeholder="搜索" required>
<button type="submit">搜索提交</button>
#
</form>
name 必须为’q‘
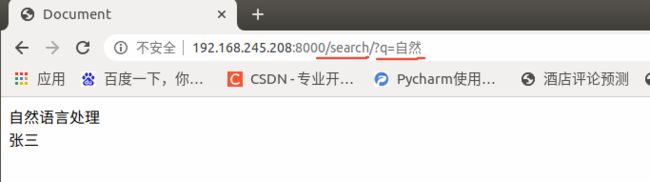
- 响应的search.html页面
定义templates>search/search.html
haystack源码是自动渲染该模板页面,也可以改源码,实现返回json响应。
/search/?q=三国演义
/search/?q=三国演义&page=2
{% load highlight %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
.keyword{
color: red;
}
</style>
</head>
<body>
<form role="search" method="get" id="searchform" action="{% url 'haystack_search' %}">
<input type="search" name="q" placeholder="搜索" required>
<button type="submit">
点击搜索
</button>
<br>
<!--搜索结果为context字典
{
"query": self.query,
"form": self.form,
"page": page,
"paginator": paginator,
"suggestion": None,
}
-->
{% if query %}
<h3>有查询结果</h3>
#自动分页
{% for result in page.object_list %}
#result.object 获取对象
<p>
<a href="{{ result.object.imgurl }}">{{ result.object.title }}</a><br/>
</p>
{% empty %}
<p>没有结果发现.</p>
{% endfor %}
{% if page.has_previous or page.has_next %}
<div>
{% if page.has_previous %}
<a href="?q={{ query }}&page={{ page.previous_page_number }}">
« Previous</a>
{% endif %}
{% if page.has_next %}
<a href="?q={{ query }}&page={{ page.next_page_number }}">
Next »</a>
{% endif %}
</div>
{% endif %}
{% else %}
{# Show some example queries to run, maybe query syntax, something else? #}
{% endif %}
</form>
</body>
</html>
-
替换whoosh的分词组件
查看haystack 应用的目录(当前使用的环境中的包)haystack.backends目录下均为支持的搜索引擎
默认whoosh_backend.py 支持英文分词创建一个中文分词组件
ChineseTokenizer.py
#ChineseTokenizer.py
import jieba
from whoosh.analysis import Tokenizer, Token
#定义中文分词类
class ChineseTokenizer(Tokenizer):
#令对象可以调用
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
"""
value:需分词的内容
positions:
chars:
keeporiginal:
removestops:
start_pos:字符索引起始位置
start_char:起始字符
"""
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
#全模式分词
seglist = jieba.cut(value, cut_all=True)
for w in seglist: #遍历每一个词
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def chinese_tokenizer():
return ChineseTokenizer()
然后,复制whoosh_backend.py---->whoosh_cn_backend.py

#whoosh_cn_backend.py
from .ChineseTokenizer import ChineseTokenizer
#搜索
schema_fields[field_class.index_fieldname] = \
TEXT(stored=True, analyzer=StemmingAnalyzer(), \
field_boost=field_class.boost, sortable=True)
#将其中的analyzer替换为ChineseTokenizer()
10.建立索引文件
#模型类已存储数据的情况下
#每次更新索引相关内容都要重建索引,将数据同步到搜索引擎
python3 manage.py rebuild_index
#将数据库的数据---->同步到搜索引擎
#查询时,从搜索引擎 查询数据,比模糊查询更高效

实战案例
单表搜索
/book/search_title/
实战1
提取码:ha8k
多表搜索
haystack会逐一搜索每个索引类
实战2
提取码:2k8q
上一篇:刨析django----阶段项目2 下一篇:刨析django----富文本