HashMap
HashMap
HashMap在Java编程中具有广泛的应用场景,适合各种数据存储和检索需求。它灵活的数据结构以及动态扩容特点,使得它得到了广泛的应用。
概念
HashMap是Java集合框架中的一种数据结构,它基于哈希表实现。哈希表是由**数组和链表(或红黑树)**组成的数据结构,通过键值对来存储数据。通过使用哈希函数将键映射到数组中的位置,可在常数时间内进行插入、删除和搜索。
使用场景
- 缓存:作为缓存存储数据,在访问频繁的情况下能够快速获取数据。
- 查找表:可以根据键快速查找对应的值,例如字典等。
- 映射关系存储:保存键值对相关信息,例如存储用户ID和用户名的对应关系。
如何使用
- 创建:new
- 添加:put
- 获取:get
- 删除:remove
- 判断存在:containsKey
- 遍历
public static void main(String[] args) {
//创建
HashMap<String ,Object> map = new HashMap<>();
//添加元素
map.put("item1","test");
//获取元素
Object item1 = map.get("item1");
//删除元素
map.remove("item1");
//判断是否存在
System.out.println(map.containsKey("item1"));
//遍历集合
for (Map.Entry<String,Object> entry: map.entrySet()){
String key = entry.getKey();
Object value = entry.getValue();
}
}
数据结构
HashMap是一种以键值对形式存储数据的数据结构,在Java中常用于快速查找和访问数据。其底层数据结构主要由**数组和链表(或红黑树)**组成。
在JDK1.7及之前的版本中,HashMap使用的是数组和链表的组合结构。
在JDK1.8及之后的版本中,为了提高性能,在链表过长时,会将链表转化为红黑树。
扩容机制
HashMap的扩容机制是在当前哈希表达到一定负载因子时触发的,负载因子是指存储和桶数组大小的比值。默认情况下,负载因子为0.75。
当哈希表中的元素数量超过负载因子乘以当前桶数组大小时,就会触发扩容操作。扩容操作将创建一个新的、更大的桶数组,并将所有的键值对重新分配到新的桶数组中。
具体的扩容过程如下:
- 创建一个新的和原来桶数组大小两倍的桶数组。
- 遍历原来的桶数组,将每个键值对重新计算哈希值并插入到新的桶数组中的相应位置。
- 当所有的键值对都被重新插入到新的桶数组之后,新的桶数组将取代原来的桶数组,成为HashMap的新的存储结构。
需要注意的是,扩容操作是一个相对耗时的操作,因为它需要重新计算哈希值、重新插入元素等。
哈希冲突
HashMap是基于哈希表实现的,因此也会发生哈希冲突。
哈希冲突是指不同的输入数据经过哈希函数计算后得到相同的输出结果。
如何解决哈希冲突呢?
- rehash:通过再次哈希,得到新的地址
- 链地址法:出现哈希冲突,将重复的元素链到该节点的尾部,JAVA中HashMap使用的此种方式。
- 开放寻址:一旦发生冲突,就去寻找下个空闲的散列地址。
- 溢出空间:将集合分开为两个空间,基本表和自由表,一旦发生冲突,将冲突元素放到自由表中。
如何设置容量
为了避免扩容操作消耗,若我们一开始能预估出HashMap的大小容量,我们在创建HashMap的时候,初始化设置其大小,可以提高程序的性能,减少一定的损耗。
设置公式:设置HashMap大小=预估容器元素/0.75 + 1
例如:
我们预估HashMap元素为15,由于HashMap负载因子0.75.因此通过公式计算15/0.75 + 1 =21。
PUT过程
源码
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 1.先判断此时的数组是否为空,如果为空则进行resize操作下
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 2.以hash索引数组的长度-1与key的hash值进行与运算,得出在数组中的索引,如果索引指定的位置
// 为空,则代表可以插入,直接插入一个新的node
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 3.判断当前key是否存在,如果是则进行替换操作
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 4.如果key不存在,则判断当前节点是否为树类型,如果是树类型的话,
// 则按照树的操作去追加新节点内容
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 5.如果出现hash冲突的节点不是树类型,则说明当前发生的碰撞在链表里面,
// 则这个时候就进入循环处理逻辑
else {
for (int binCount = 0; ; ++binCount) {
// 6.先判断被碰撞的节点的下一个节点是否为空
if ((e = p.next) == null) {
// 如果为空则将新节点放到被碰撞节点的下一个节点
p.next = newNode(hash, key, value, null);
// 7.作为后继节点之后判断当前链表长度是否超过最大允许链表长度8,
// 如果大于的话,则转为红黑树执行插入
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 8.如果map的索引表为空或者当前索引表长度还小于64(最大转红黑树的索引数组表长度),
// 那么进行resize操作就行了;否则,如果被碰撞节点不为空,
// 那么就顺着被碰撞节点这条树往后新增该新节点
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 如果替换成功,返回老的value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
图示
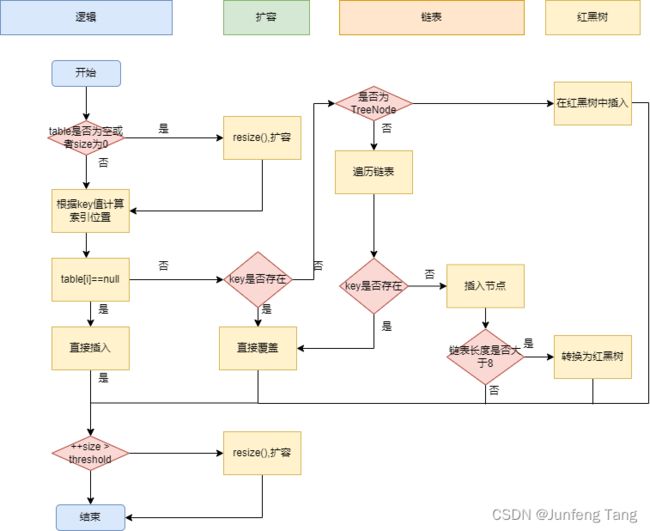
步骤
1.使用put()方法时,直接调putVal()方法
2.在put的时候先判断数组是否为空,如果为空则进行resize操作
3.以hash索引数组的长度-1与key的hash值进行与运算,得出在数组中的索引,如果索引指定的位置为空,则代表可以插入,直接插入一个新的node
4.判断当前的key是否存在,如果存在则进行替换,如果替换成功则返回老的值
5.如果key不存在,则判断当前节点是否为树类型,如果是树类型的话,则按照树的操作去追加新节点内容
6.如果出现hash冲突的节点不是树类型,则说明当前发生的碰撞在链表里面,则这个时候就进入循环处理逻辑
7.进入循环逻辑之后先判断被碰撞节点的下一个节点是否为空,如果为空就将新节点放入
8.放入后判断当前链表是否超过最大允许链表长度8,如果超过则转为红黑树进行插入
9.如果map的索引表为空或者当前索引表长度还小于64(最大转红黑树的索引数组表长度),那么进行resize操作就行了;否则,如果被碰撞节点不为空,那么就顺着被碰撞节点这条树往后新增该节点插入
GET过程
源码
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//Node数组不为空,数组长度大于0,数组对应下标的Node不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
//也是通过 hash & (length - 1) 来替代 hash % length 的
(first = tab[(n - 1) & hash]) != null) {
//先和第一个结点比,hash值相等且key不为空,key的第一个结点的key的对象地址和值均相等
//则返回第一个结点
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//如果key和第一个结点不匹配,则看.next是否为空,不为null则继续,为空则返回null
if ((e = first.next) != null) {
//如果此时是红黑树的结构,则进行处理getTreeNode()方法搜索key
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//是链表结构的话就一个一个遍历,直到找到key对应的结点,
//或者e的下一个结点为null退出循环
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
步骤
- 首先根据 hash 方法获取到 key 的 hash 值
- 然后通过 hash & (length - 1) 的方式获取到 key 所对应的Node数组下标 ( length对应数组长度 )
- 首先判断此结点是否为空,是否就是要找的值,是则返回空,否则进入第二个结点。
- 接着判断第二个结点是否为空,是则返回空,不是则判断此时数据结构是链表还是红黑树
- 链表结构进行顺序遍历查找操作,每次用 == 符号 和 equals( ) 方法来判断 key 是否相同,满足条件则直接返回该结点。链表遍历完都没有找到则返回空。
- 红黑树结构执行相应的 getTreeNode( ) 查找操作。