文件系统初识
内核中函数的调用关系可以通过 dump_stack(); 函数来打印,具体的使用方法为:
1. 该函数返回值和形参均为空,所以调用方式为 dump_stack();
2. 该函数的效果是打印函数的堆栈,里面会包含函数名字,进而直观的看到调用流程。
3. 在函数内部直接调用即可,注意最好能前后都加提示类的printk。
printk(KERN_EMERG "mlwmlw_817 stack start!");
dump_stack();
printk(KERN_EMERG "mlwmlw_817 stack end!");
应用层的调用关系:使用backtrace()来定位和打印具体的调用关系。
---------------------------------------------
#include
#include
#include
#include
void print_stack(void)
{
int j, nptrs;
#define SIZE 100
void *buffer[100];
char **strings;
nptrs = backtrace(buffer, SIZE);
printf("backtrace() returned %d addresses\n", nptrs);
strings = backtrace_symbols(buffer, nptrs);
if (strings == NULL) {
perror("backtrace_symbols");
exit(EXIT_FAILURE);
}
for(j = 0; j < nptrs; j++)
printf("%s\n", strings[j]);
free(strings);
}
void func1(void)
{
print_stack();
printf("fun 1");
}
void func2(void)
{
func1();
}
void func3(void)
{
func2();
}
void func4(void)
{
func3();
}
void main()
{
func4();
}
---------------------------------------------
注意gcc时,需要加 -rdynamic 编译选项,否则backtrace只打印地址,而不带名字
./a.out(print_stack+0x2e) [0x400ad4]
./a.out(func1+0x9) [0x400ba2]
./a.out(func2+0x9) [0x400bbd]
./a.out(func3+0x9) [0x400bc9]
./a.out(func4+0x9) [0x400bd5]
./a.out(main+0x9) [0x400be1]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0xf0) [0x7f81307e5840]
./a.out(_start+0x29) [0x4009d9]
注意:linux支持多种不同的文件系统,比如 ubifs, ext2,ext3, ext4, jffs2, ufs等,内核下的上述文件系统的源码详见 linux4.19/fs;其次各个文件系统的回调函数均为 xxx__file_operations:
ubifs/ubifs.h:1466: extern const struct file_operations ubifs_file_operations;
ext4/ext4.h:3106: extern const struct file_operations ext4_file_operations;
jffs2/os-linux.h:154: extern const struct file_operations jffs2_file_operations;
------------------------------------重点-----------------------------------
1. 具体的文件系统与系统调用的关系: 【用户空间 write】-----【sys_write】------【VFS即虚拟文件系统的写方法 vfs_write】-----【文件系统的写方法xxx_file_operations->write】------【存储介质】
百度安全验证
1. 定义: 文件系统 是 操作系统 用于明确存储设备上 文件的组织的 方法和数据结构
文件系统本质上是方法和数据结构。
文件系统一般不是孤立的,一般是属于操作系统的一部分。
2. 文件系统由三部分组成:1)文件系统的接口 2)对对象操纵和管理的软件集合 3)对象及属性。
3. 操作系统中一般会集成文件系统,
二。简介:
1. 文件系统中的文件被存放在树状结构中。
2. 文件系统指定文件命名的规则,包括 文件名的最大字符数;哪种字符可以使用;通过树状结构找到文件的格式等。
三。
1. 文件系统是用于明确文件的组织方法 的 数据结构和方法。
2. 一个分区作为文件系统使用前,需要初始化,并将记录数据结构写到磁盘上,该过程就叫做建立文件系统。
3.大部分的unix(linux属于unix)上的文件系统的结构是通用的,分为五部分。即使细节有所变化
1) 超级块:SuperBlock::
超级块包括文件系统的总体信息,如大小(其准确性依赖文件系统)
2) i节点: inode
i节点包括 除了名字外的一个文件的所有信息, 名字与i节点数目一起存在目录中。
3) 数据块 DataBlock
4) 目录块: directory block
5)间接块: indirection block
注意:上述对文件系统的组成的描述不够精确,后续需要更准确的描述。
扩展:Linux是一套免费使用和自由传播的类Unix操作系统,即linux是一种优化后的unix系统。
4. 文件系统中孔的概念和作用
5. linux中文件系统的源码位于 fs/ 目录下,对于降成本产品来说,位于 fs/ubifs 目录下
四。EXT4文件系统:
1. EXT4支持的文件系统大小以及单个文件大小都比EXT3大很多,解除了一些应用场景的限制。
2. EXT3最多支持32000级子目录,EXT4无此限制。
3. 更多的块和inode数量:块数量以及inode数量在 EXT3均使用32bit记录,EXT4使用64bit记录。
4. 多块分配:即EXT3的数据块分配器每次只分配一个4KB的块,需要分配25600次,EXT4 可以一次分配25600个块。
5. 多块分配和延迟分配,可以将随机IO变为顺序IO,即写一个文件时,时间上可能有停顿,如果立刻回写flash,会导致不同时刻写的东西不连续,而且时间不确定,导致随机IO; 但是如果等全部写完后一次性回写flash,就可以做到空间和时间的连续,即顺序IO
==============================================
五。文件系统的原理:
1. 文件,目录,块设备,管道均属于文件。
2. 文件系统会为每个上述元素分配两个结构:索引节点inode 和 目录项directory entry
1) 其中inode记录的是文件的元信息,包括inode编号,文件大小,访问权限,创建时间,修改时间,数据在磁盘的位置等, 存放在硬盘中,所以也占用硬盘空空间。
2) 其中directory entry 用于记录文件名字,索引节点(inode)指针,以及与其他目录的层级关系。 与索引节点不同,不放在硬盘中,而是放在内存中。
注意区分目录和目录项,目录属于文件,存在磁盘;目录项是数据结构,存在内存。
3. 索引节点inode唯一标识一个文件,与文件是一对一的; 目录项directory entry只记录文件名和目录,与文件是多对一的,(比如一个文件如果有多个硬连接,即多个目录项中的inode节点指向同一个文件)
4. 内核会把访问过的文件的目录项(数据结构,不是读取出来的) 存到内存,当再次访问该文件时,直接从内存读写,效率更高。
5. 磁盘的最小读写单位为扇区,扇区仅512B,单位太小导致读写效率很低。linux的文件系统会把8个扇区组成一个逻辑块(4KB),提高了效率。
文件系统中使用两个结构来描述一个文件 struct dentry; struct inode; 来描述一个文件。

图中绿色的部分即dentry, 右侧的部分即磁盘上的内容,
参考右侧的图像可知,磁盘被格式化的时候会分为以下三个区:
1) 超级块:用于存储文件系统的详细信息,比如块数,块大小,空闲块等。
2) 索引节点(inode)区:用于存储索引节点。
3) 数据块区: 用于存储文件的具体数据。
注意上述三种块中的前两种即超级块和索引节点被使用时会被加载进内存,即:
1) 超级块:当文件系统挂载进内存时候(因为超级块存储的是文件系统的关键信息)
2) 索引节点(inode)区::当文件被访问时。
六。 虚拟文件系统:与其说是文件系统,更像是 “文件系统中间层”,类似封装层,屏蔽不通融文件系统的区别,为用户提供统一接口。
1. 文件系统有很多种,不同文件系统接口不完全相同,操作系统为了屏蔽这些区别,为用户提供统一的接口,于是在文件系统和用户之间构建了一层“虚拟文件系统”,用于屏蔽不同文件系统的区别,为用户提供统一的接口,称为VFS。
2. VFS是操作系统构建出来的一层,具体的构建方法是 定义一组所有文件系统都支持的数据结构和接口,这样程序员只需要了解VFS封装出来的接口即可,而不用关心具体的底层的文件系统的接口.
3. linux系统下,用户,系统调用,VFS,缓存(cache), 文件系统,存储(flash)之间的关系如下:
==============================扩展:linux中的系统调用==============
1. 系统调用是操作系统为用户提供的唯一合法的进入内核态的方法(除此之外还有异常和陷入,属于非正常的方法),其具体实现为软中断(不详细展开).当系统调用发生时,CPU通过软中断切换到内核态开始执行系统调用对应的内核态函数。
2. 三种触发系统调用的方法
Linux 下系统调用的三种方法_海风林影的博客-CSDN博客系统调用(System Call)是操作系统为在用户态运行的进程与硬件设备(如CPU、磁盘、打印机等)进行交互提供的一组接口。当用户进程需要发生系统调用时,CPU 通过软中断切换到内核态开始执行内核系统调用函数。下面介绍Linux 下三种发生系统调用的方法:通过 glibc 提供的库函数glibc 是 Linux 下使用的开源的标准 C 库,它是 GNU 发布的 libc 库,即运行时https://blog.csdn.net/hazir/article/details/11894427?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165468995016781435495320%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=165468995016781435495320&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-11894427-null-null.142%5Ev11%5Epc_search_result_control_group,157%5Ev13%5Econtrol&utm_term=linux+%E7%B3%BB%E7%BB%9F%E8%B0%83%E7%94%A8&spm=1018.2226.3001.4187
3. linux下 用于,系统调用,VFS,缓存(cache) 文件系统, 存储(flash) 之间关系如下:

系统调用涉及进程上下文之类的概念,不详细展开
七, linux支持的文件系统:根据存储位置的不同,可以分为三类。
1. 磁盘使用的文件系统:数据存放在磁盘上 EXT4, UBIFS, YSFFIS
2. 内存的文件系统:数据放在内存中,比如 proc sys, 这类的读写实际上是对内存的读写
3. 网络文件系统:用于访问其他主机的文件系统 NFS SMB等。
文件系统需要挂载到某个目录才能使用,比如linux启动时,会把文件系统挂载到根目录。
八。文件的使用:
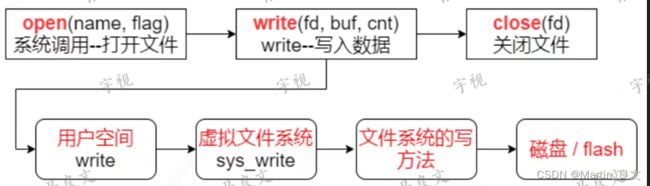
1. 以文件的写入为例,具体流程为 open 打开文件----write写入数据-----close关闭文件。
2. 其中open,write close 均为系统调用,其内部的流程为:用户空间的write----虚拟文件系统的sys_write-------文件系统的写方法-----磁盘。
3. 操作系统会为每一个进程单独维护一个打开的文件列表,列表中的每一项代表一个打开的文件,其中的每一项又被称为“文件描述符”
扩展:与文件描述符相关的一个概念为 “文件上下文” ,即文件描述符以及其所关联的文件的位置,打开次数,以及文件的权限等信息。
各个进程用于保存打开文件信息的表格大致如下:
================================================
1. 文件指针 即文件上次读写到的位置
2. 文件打开计数器(多个进程打开同一文件)
3. 文件在磁盘的位置
4. 访问权限。每个进程打开文件都有一个访问模式,该信息保存在打开文件列表中。
================================================
1. 文件指针 即文件上次读写到的位置
2. 文件打开计数器(多个进程打开同一文件)
3. 文件在磁盘的位置
4. 访问权限。每个进程打开文件都有一个访问模式,该信息保存在打开文件列表中。
================================================
1. 文件指针 即文件上次读写到的位置
2. 文件打开计数器(多个进程打开同一文件)
3. 文件在磁盘的位置
4. 访问权限。每个进程打开文件都有一个访问模式,该信息保存在打开文件列表中。
================================================
特别的,
1. 需要注意各个进程的文件表大小是有限制的(分为系统级限制和用户级限制)的,所以当这个文件的引用计数(打开次数)归零时,需要将该描述符从表格中删除(不删除的话就爆了),
2. 所谓的删除,其实不是禁用这个描述符,而是复用(或说重用)该描述符,用以打开其他的文件。
3. 文件描述符从表中删除的充分条件是其打开数归零(多个进程都有可能打开同一文件)
九。文件操作 之 用户视角 和 操作系统视角:
1. 从用户的视角看,文件操作重要的是保证内容正确,可以是一个字节一个字节的内容
2. 从操作系统的视角看,文件操作重要的是如何将以字节为单位的操作 与 以块为单位的操作联系起。
即用户可能是按字节读写的,但是操作系统层面要将其转换为以块为单位的读写。
当用户读取1字节时,文件系统需要获取该字节所在的数据块,在返回数据块中该字节的值。
当用户写1字节时,文件系统需要获取该字节所在的数据块,改写对应的字节以后,将数据块写回磁盘。 文件系统的基本操作单位是块,非字节。
十,文件的存储:
1. 文件的数据需要存放在哎磁盘上,具体的存储方式有两种,
1) 连续空间存储方式
2) 非连续空间存储方式:分为 链表方式 和 索引方式。
注意:对存储方式而言,重点是存储效率和读写性能。
2. 连续空间存储方式:
1. 简介:顾名思义,各个文件在磁盘中均是连续存储的,该模式下,文件数据紧挨着,所以读写效率很高。
2. 前提:必须知道文件的大小,知道文件大小后,文件系统会根据文件大小找到一块磁盘生的连续空间分配给该文件。
3. 所以文件头(类似inode)里面需要指定“起始块的位置” 和 “长度” 即可表示连续存放的文件。
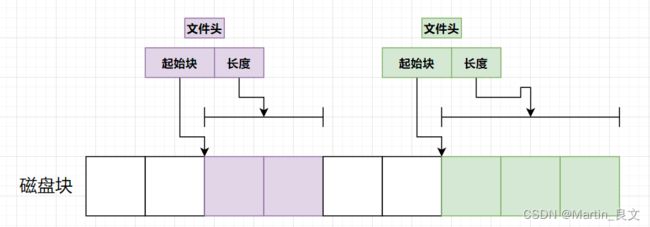
4. 连续存储方式的缺点: 【磁盘空间碎片】 和 【文件不易扩展】
1) 磁盘空间碎片:

2) 文件不易扩展:比如上面的A想要加大2,是不可行的,会侵入B的空间。
综上,连续存储不是一个好用的方法。
3. 非连续空间存储方式:分为链表方式 和 索引方式;均可以消除上述两个缺点(碎片和不易扩展)其中的链表方式:分为隐式链表 和 显示链表。
1) 隐式链表:实现方式为 文件头(类似inode)中包含第一块和最后一块的位置,并且每个数据块中额外留出空间用以存储下一个数据块的位置,这样通过文件头找到第一个数据块,然后顺着数据块的指针可以顺序访问整个文件。
(1)一个文件只有文件头(类似inode)位于内存中,它里面的指针指向第一个数据块,然后各个数据块中有指针直响下一个数据块。
(2)缺点:无法直接访问数据块,只能通过文件头从前向后访问; 其次就是数据块中的指针浪费了一些空间

显示链表法:目的和优势就是为了解决隐式链表的两个问题,具体方案是:将每个数据区后面的指针区放到内存里,形成表格,但并非一个文件一个表格,而是一个磁盘一张表格,那么如何在一张表格中区分不同的文件呢?
每个表项都有编号,此外还有指针指向所属文件的下一个表项,直至某个表项的编号为-1 (约定的特殊编号),其优缺点介绍如下:缺点主要是不适合用于大的磁盘。

索引数据块如下: 即每个文件在磁盘上会建立一个索引数据块,

索引的优点在于: 1. 文件的创建,增大,缩小很方便。 2. 不会有碎片的问题 3. 支持顺序读写和随机读写。
缺点是1)小文件也需要一个单独的索引块,会占用空间; 2) 索引块有大小限制,一级索引块表示的文件大小有限。大的文件要用多级索引,
综上所述,前面提到的三种方式(直接存取,链表,索引)的优缺点如下

11. unix文件系统存储文件的方式:集合了上述三种算法:
首先是inode的结构:包含13个指针:可以灵活的使用上述的结构以支持不同大小的文件。
1) 10个指向数据块的指针
2) 第11个指向一级索引块的指针
3)第12个指向二级索引块的指针
4) 第13个指向三级索引块的指针
这种方式可以灵活的支持小文件和大文件:
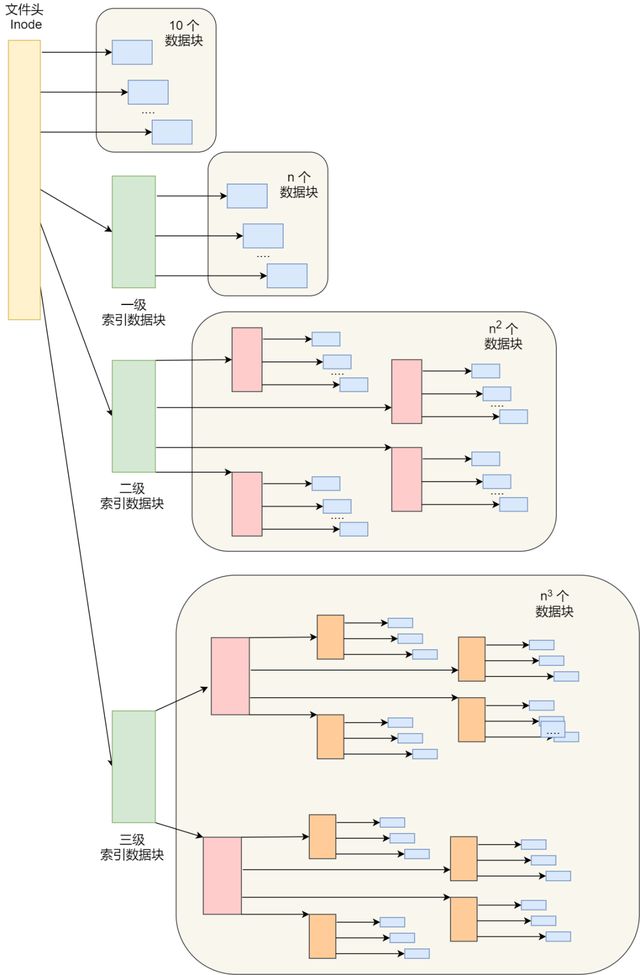
对于小文件:使用直接查找的方式减少索引数据块的开销
对于大文件,以多级索引的方式实现,这期间需要查询大量数据块
上述方案用在了linux的EXT2/3文件系统中,明显的,仍存在大文件访问慢的问题。 EXT4优化了结构,不展开。
=====================空闲位置的管理===================
大部分场景下我们用的是离散化的块管理,新建一个文件时,我们需要知道空闲的块的位置,这就需要对空闲的块进行管理。有以下常用的三种方法:
1) 空闲表法 2) 空闲链表法 3)位图法
1) 空闲表法:即简单的为所有的空闲空间建立一张表,每个表项代表一块连续的空闲空间,每个表项包含 起始空闲块ID以及空闲块个数

空闲表法:
1) 当新建文件时,会依次扫描空闲表里的内容,直至找到一个合适的空闲区域为止。
2) 当用户删除文件时,系统回收文件,顺序扫描空闲表,找到一个空闲条目放进去。
这种方法仅当有少量空闲区域时候又较好效果,如果有大量小的空闲,则效率很低。
空闲链表法:
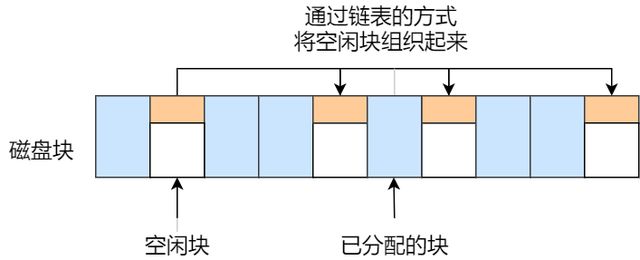
这种技术只要在主存上存储一个指针,令其指向一个空闲块,特点是简单,但是不能随机访问。
上述两种方法都不适合大型文件系统。
位图法: linux文件系统用的就是 该方式
位图法利用二进制的一位表示一个块的使用情况,所有的块都有一个二进制位与之对应,当值为0时,表示对应的块空闲,值为1时,表示块已分配。【inode也存储在磁盘,也有类似的管理】
=========================文件系统结构=================
1. 假设一个文件的 块位图块 (指示各个块的使用情况)占用一个块,则可以表示的块的个数为 2^15块,这些块按照一个4KB计算,共计128MB,但是很多文件比这个大,所以需要使用多个 块位图块,linux中,把 一个块位图块 + 对应的块,称为一个块组。根据上面的计算,一个块组可表示128MB的空间,大文件一般使用N个块组。(一个块只能表示128MB大小的文件)
2. EXT2文件系统的结构: 由开头的一个引导块 和 后面的 若干块组组成,如下:
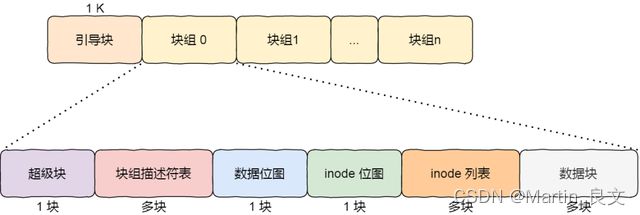
其中每个块组的组成如下:注意各个块组中有一些重复的部分,属于冗余涉及。
1) 超级块:包含文件系统的重要信息,比如inode总个数,块总个数,每个块的inode数等。
2) 块组 描述符:包含文件系统中各个块组的状态,比如组中空闲块的inode的数目,每个块中都i包含了文件系统中【所有块组的描述信息】
3) 数据位图和inode位图,用于表示对应数据块或inode是空闲的,或是使用中。
4)inode列表:包含了块组中所有的inode,inode相当于文件头。
5) 数据块:包含文件的有效数据。
注意:上述各个块组中包含了不少冗余信息,比如超级块,块组描述符,这两个均属于全局信息,但是每个块组都包含了一遍,主要原因为:
(1)如果系统崩坏了超级快或块描述符,意味着文件系统的全局信息丢失,此时冗余设计就有价值了。
(2)通过使全局数据(文件系统的全局数据)和 具体数据(数据块)尽可能接近,进而减少磁头寻道和旋转,可以提高文件系统的性能。
思考和优化:EXT2文件系统是每个块组都包含一组文件系统的全局信息,如此密集其实是没有必要的,EXT2后续的版本使用了稀疏技术,该算法是 文件系统的全局信息(超级快和块组描述符)不再存储的如此密集,而是只存储在块组0,1和其他块组ID为3,5,7的幂的块组中。 3
注意上述标红的为文件系统的全局信息。老旧的EXT2的思路是每个块组都伴随着全局信息,但是后面的文件系统是只有特定规律的块才包含全局信息。
===============目录的存储===============
1. 目录本质上也是文件,也有inode的概念;区别就是目录保存的数据是期目录下的文件和文件夹
2. 目录中保存文件和文件夹的方式一般为列表,即逐项记录所包含的内容的名字以及哈希值(key)
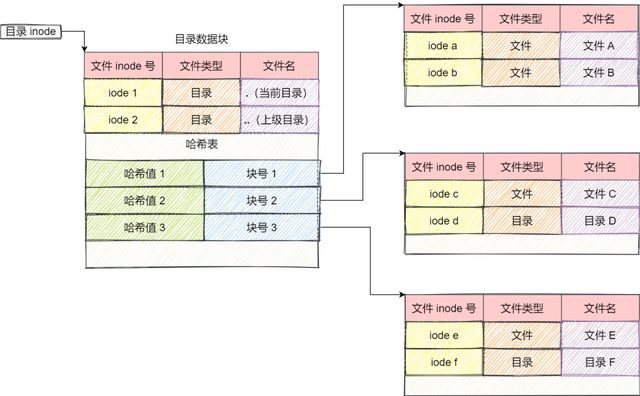
3. 通常情况下,第一项为[.] ,第二项为[..] , 然后就是一项一项的文件名和inode. 查找文件时,如果按照逐项的方式查找,效率会很低,所以文件的查找一般是用哈希表实现,键值对为(文件名--文件名的哈希值),查找文件时通过计算文件名的哈希值,然后通过哈希表的方式查找。
4. linux的EXT文件系统使用哈希的方式存储目录下的内容,查找快,抑郁增删,但是需要一些方法来避免哈希冲突。
====================软链接和硬链接====================
1. 扩展:单讲软硬链接的区别:
1) 软链接:创建使用 ln -s 命令; 软链接的inode与源文件的inode是独立的,没有任何关系,唯一的关系是: 软链接的数据块的内容是源文件的路径, 由于数据块的内容是路径,软链接与源文件之间除此之外没有其他的约束。两者相对很独立,从源文件来看,软链接对其没有任何约束。
2) 硬链接:一inode 对应 多个 文件名; 即一个inode对应多个文件名。各个文件之间的属性,权限完全相同,但是删除一个文件不影响其他的文件
3) 常用的是软链接,值得注意的是软链接文件的大小是其源文件路径的长度(软链接的数据块存储的是源文件的路径)。
2. 硬链接正式介绍:即多个文件名指向同一inode, 但是ionde明显是不能跨越文件系统的。而且如果想删除一个有硬链接的文件,必须把全部文件全部删掉。
3. 软链接正式介绍:软链接文件和源文件之间没有过多的约束,唯一的相关性在于软链接的数据块中存储的是源文件的路径。是一个新的文件,可以跨越文件系统
==========================================
===========================文件IO=================
1. 文件的IO有很多中分类,大致的集中分类:
1) 缓冲 与 非缓冲IO
2)直接 与 非直接IO
3) 阻塞IO 与 非阻塞IO VS 同步与异步IO
2. 缓冲 与 非缓冲IO:printf 即缓冲IO :
1) printf 中 不加\n 或者不调用fflush, 会出现不打印的现象,即缓冲IO:
2)缓冲IO即利用标准库的缓存实现文件的加速访问,
3) 非缓冲IO:直接通过系统调用访问文件,不经过标准库缓存。
3. 直接与非直接IO:
1) 出现的原因:磁盘的IO很慢,linux内核为了减少磁盘IO次数,用户给数据到内核后,内核会把这些数据缓存起来,该内核空间即“页缓存”,只有页缓存满足一定条件后才会发起磁盘的IO。
2) 直接IO:用户给的数据直接通过磁盘IO写入磁盘;不经过内核的页缓存。
3) 非直接IO:写操作时,数据从用户程序拷贝给内核,由内核决定磁盘IO的时机。
比如write函数,如果指定 O_DIRECT标志,则进行的就是直接IO,不指定,则默认非直接IO。
4) 问题:非直接IO时,内核发起磁盘IO的时机:
(1)用于存储的页缓存慢的时候
(2)用户调用sync
(3)内核页缓存数据时长超过一段时间后。
-----------------------------阻塞与非阻塞IO && 同步与异步IO-------------
1. 阻塞与非阻塞IO, 同步与异步IO 很接近,很容易混淆。
2. 阻塞IO:应用程序执行read, 线程会被阻塞,一直等内核准备好数据和将数据拷贝至用户,read才算完成,阻塞等待的是(内核准备好数据 和 内核将数据拷贝至用户)

3. 非阻塞IO: 还是上面的例子,区别是用户程序会循环调用 read(NOBLOCCK),与read的区别在于,read调用时,如果此时内核没有数据,read立即返回,然后应用程序不停的调用read,图示如下:

注意上图中最后一次的read调用不立即返回的原因是内核准备好了数据,但是还是需要耗copy_to_usr的时间。即最后一次调用是一个同步的过程,是需要等待的,这里的同步指的是内核态数据拷贝到用户程序的过程。
对于阻塞和非阻塞,一般的,通过标志(NO_BLOCK来选择),使用阻塞方式调用会使得线程阻塞,使用非阻塞的方式调用会使得APP干不了别的事情,“IO多路复用技术”即select诞生,其调用一般如下:
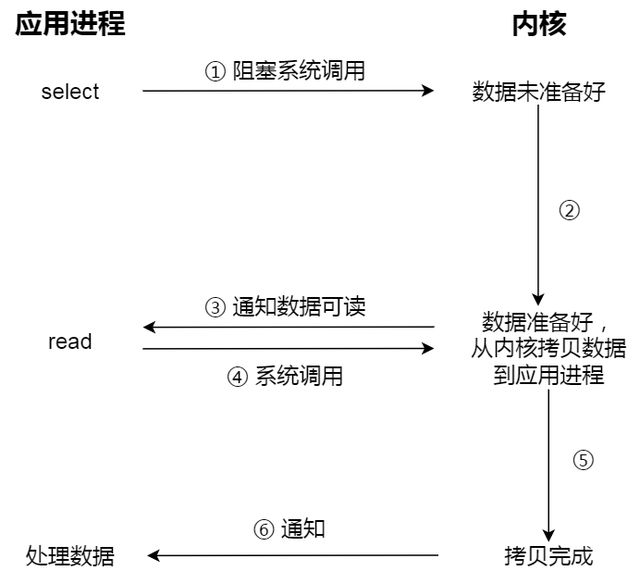
但是,上述提到的 阻塞IO, 非阻塞IO,抑或select, 都是同步调用,即当内核准备好数据后,copy_to_usr都是需要等待的。此时,某些原因可能会导致拷贝的时间比较长。
与同步IO对应的,就是非同步IO,即aio_read, 此函数调用后立刻返回,内核会自动将数据准备好后,自动拷贝至用户。即上述的两个耗时操作均有内核自动完成

-------------------------------------总结----------------
总结:
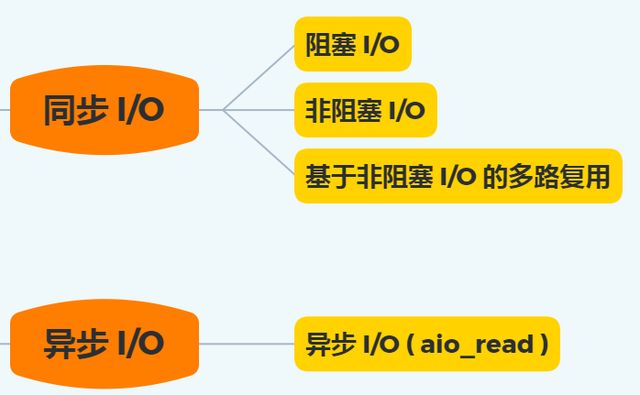
IO分为两个过程:【1:内核准备好数据】 和 【2:内核将数据拷贝至用户】
阻塞IO会阻塞在1和2中。 非阻塞过程会阻塞在 1和2。 select 会阻塞在过程2中。所以这三个均可认为是同步IO。关于阻塞非阻塞,同步非同步有个故事如下:
