MongoDB
一、MongoDB 相关概念
1.1 业务应用场景
1.1.1 三高需求
传统的关系型数据库(如 MySQL) ,在数据操作的 “三高” 需求以及应对 Web2.0 的网站需求面前,显得力不从心。”三高“ 需求如下所示,而 MongoDB 可应对 “三高” 需求。
High performance - 对数据库高并发读写的需求。
Huge Storage - 对海量数据的高效率存储和访问的需求
High Scalability && High Availability - 对数据库的高可扩展性和高可用性的需求
1.1.2 常见的使用 MongoDB 的场景
1)社交场景,使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能。
2)游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、高效率存储和访问。
3)物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。
4)物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析。
5)视频直播,使用 MongoDB 存储用户信息、点赞互动信息等。
在上述的这些应用场景中,数据操作方面的共同特点是:数据量大、写入操作频繁(读写都很频繁)、价值较低的数据,对事务性要求不高。对于这样的数据,我们更适合使用 MongoDB 来实现数据的存储。
1.1.3 什么时候选择 MongoDB
如果下述有1个符合,可以考虑 MongoDB,2 个及以上的符合,选择 MongoDB 绝不会后悔。
应用不需要事务及复杂 join 支持;新应用,需求会变,数据模型无法确定,想快速迭代开发;应用需要 2000-3000 以上的读写 QPS(更高也可以);应用需要 TB 甚至 PB 级别数据存储;应用发展迅速,需要能快速水平扩展;应用要求存储的数据不丢失;应用需要 99.999% 高可用;应用需要大量的地理位置查询、文本查询。
1.2 MongoDB 简介
MongoDB 是一个开源、高性能、无模式的文档型数据库,当初的设计就是用于简化开发和方便扩展,是 NoSQL 数据库产品中的一种。是最像关系型数据库(MySQL)的非关系型数据库。
它支持的数据结构非常松散,是一种类似于 JSON 的格式叫 BSON,所以它既可以存储比较复杂的数据类型,又相当的灵活。
MongoDB 中的记录是一个文档,它是一个由字段和值对(field:value)组成的数据结构。MongoDB 文档类似于 JSON 对象,即一个文档认为就是一个对象。字段的数据类型是字符型,它的值除了使用基本的一些类型外,还可以包括其他文档、普通数组和文档数组。
1.3 体系结构
Mysql 和 MongDB 对比,如下:
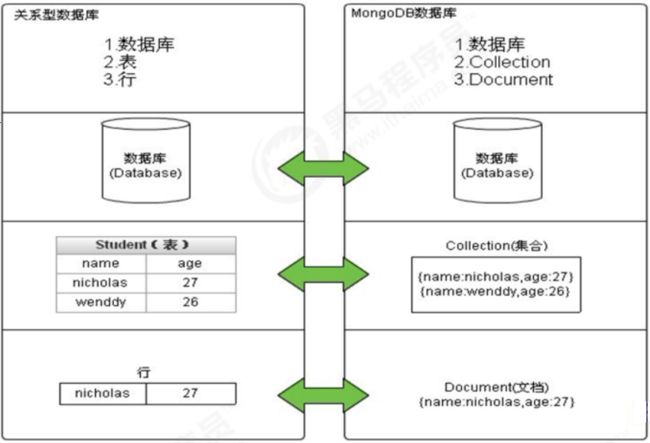
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|
database
|
database
|
数据库
|
|
table
|
collection
|
数据库表 / 集合
|
|
row
|
document
|
数据记录行 / 文档
|
|
column
|
field
|
数据字段 / 域
|
|
index
|
index
|
索引
|
|
table joins
|
表连接, MongoDB 不支持
|
|
|
嵌入文档
|
MongoDB 通过嵌入式文档来替代多表连接
|
|
|
primary key
|
primary key
|
主键, MongoDB 自动将 _id 字段设置为主键
|
1.4 数据类型
MongoDB 的最小存储单位就是文档 (document) 对象。文档 (document) 对象对应于关系型数据库的行。数据在 MongoDB 中以 BSON(Binary-JSON)文档的格式存储在磁盘上。
BSON(Binary Serialized Document Format)是一种类 json 的一种二进制形式的存储格式,简称 Binary JSON。BSON 和 JSON 一样,支持内嵌的文档对象和数组对象,但是 BSON 有 JSON 没有的一些数据类型,如 Date 和 BinData 类型。
BSON 采用了类似于 C 语言结构体的名称、对表示方法,支持内嵌的文档对象和数组对象,具有轻量性、可遍历性、高效性的三个特点,可以有效描述非结构化数据和结构化数据。这种格式的优点是灵活性高,但它的缺点是空间利用率不是很理想。
Bson 中,除了基本的 JSON 类型:string,integer,boolean,double,null,array 和 object,MongoDB 还使用了特殊的数据类型。这些类型包括 date,object id,binary data,regular expression 和 code。每一个驱动都以特定语言的方式实现了这些类型,查看你的驱动的文档来获取详细信息。
BSON 数据类型参考列表:
| 数据类型 | 描述 | 举例 |
|
字符串
|
UTF-8 字符串都可表示为字符串类型的数据
|
{"x" : "foobar"}
|
|
对象 id
|
对象 id 是文档的 12 字节的唯一 ID
|
{"X" :ObjectId() }
|
|
布尔值
|
真或者假: true 或者 false
|
{"x":true}+
|
|
数组
|
值的集合或者列表可以表示成数组
|
{"x" : ["a", "b", "c"]}
|
|
32 位整数
|
类型不可用。JavaScript仅支持64位浮点数,所以32位整数会被自动转换。 | shell是不支持该类型的,shell中默认会转换成64位浮点数 |
|
64 位整数
|
不支持这个类型。shell会使用一个特殊的内嵌文档来显示64位整数 | shell是不支持该类型的,shell中默认会转换成64位浮点数 |
|
64 位浮点数
|
shell 中的数字就是这一种类型
|
{"x" : 3.14159 , "y" : 3}
|
|
null
|
表示空值或者未定义的对象
|
{"x":null}
|
|
undefined
|
文档中也可以使用未定义类型
|
{"x":undefined}
|
|
符号
|
shell不支持,shell会将数据库中的符号类型的数据自动转换成字符串 | |
|
正则表达式
|
文档中可以包含正则表达式,采用 JavaScript 的正则表达式语法
|
{"x" : /foobar/i}
|
|
代码
|
文档中还可以包含 JavaScript 代码
|
{"x" : function() { /* …… */ }}
|
|
二进制数据
|
二进制数据可以由任意字节的串组成,不过 shell 中无法使用
|
|
| 最大值/最小值 | BSON包括一个特殊类型,表示可能的最大值。shell中没有这个类型。 |
提示:shell 默认使用 64 位浮点型数值,例如:{“x”:3.14} 或 {“x”:3}
对于整型值,可以使用 NumberInt(4 字节符号整数)或 NumberLong(8 字节符号整数),例如:{“x”:NumberInt(“3”)} 或 {“x”:NumberLong(“3”)}
1.5 MongoDB 特点
a、高性能
MongoDB 提供高性能的数据持久性。特别是对嵌入式数据模型的支持减少了数据库系统上的 I/O 活动。索引支持更快的查询,并且可以包含来自嵌入式文档和数组的键。(文本索引解决搜索的需求、TTL 索引解决历史数据自动过期的需求、地理位置索引可用于构建各种 O2O 应用)。Gridfs 解决文件存储的需求。
b、高可用性
MongoDB 的复制工具称为副本集(replica set),它可提供自动故障转移和数据冗余。
c、高扩展性
MongoDB 提供了水平可扩展性作为其核心功能的一部分。分片将数据分布在一组集群的机器上(海量数据存储,服务能力水平扩展)。
从 3.4 开始,MongoDB 支持基于片键创建数据区域。在一个平衡的集群中,MongoDB 将一个区域所覆盖的读写只定向到该区域内的那些片。
d、丰富的查询支持
MongoDB 支持丰富的查询语言,支持读和写操作(CRUD),比如数据聚合、文本搜索和地理空间查询等。
二、单机部署
2.1 Windows 系统安装启动
第一步,下载安装包,MongoDB 提供了可用于 32 位和 64 位系统的预编译二进制包,你可以从 MongoDB 官网下载安装,选择版本如下,其中 zip 包为免安装版本。
MongoDB 的版本命名规范如:x.y.z
y 为奇数时表示当前版本为开发版,如:1.5.2、4.1.13;
y 为偶数时表示当前版本为稳定版,如:1.6.3、4.0.10;
z 是修正版本号,数字越大越好。
第二步,解压安装启动,将压缩包解压到一个目录中。在解压目录中,手动创建两个文件夹data/db 用于存放数据文件,如下:

解压完成后,就可以启动 MongoDB 服务了,有两种启动方式,第一种是命令行参数启动,打开 cmd 的命令行窗口,切换到 MongoDB 的 bin 目录下,执行下面的命令:
mongod --dbpath=..\data\db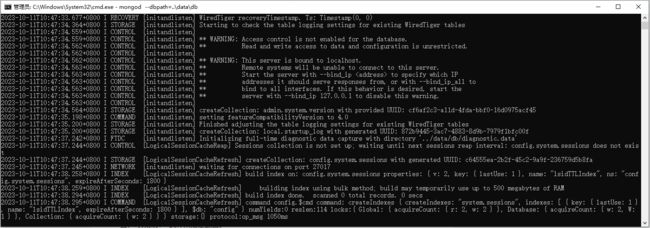
我们在启动信息中可以看到,MongoDB 的默认端口是 27017,如果我们想改变默认的启动端口,可以通过 --port 来指定端口。
第二种是配置文件方式启动服务,在解压目录中新建 config 文件夹,该文件夹中新建配置文件 mongod.conf ,内容如下,需要注意的是,里面的标签是 yaml 形式的,注意空格的个数。
storage:
#The directory where the mongod instance stores its data.Default Value is "\data\db" on Windows.
dbPath: F:\mongodb-win32-x86_64-2008plus-ssl-4.0.28\data\db
启动方式为:切换到 bin 目录下,然后执行下面的命令:
mongod -f ..\config\mongod.conf
或
mongod --config ..\config\mongod.conf
2.2 连接服务端
我们上一小节安装了 MongoDB 的服务端,接下来我们使用自带的工具来连接下服务端,打开 cmd 窗口,切换到 bin 目录下,记得服务端的 cmd 窗口不能关,执行下面的命令:
mongo
或
mongo --host=127.0.0.1 --port=27017出现下面这些内容就表示安装成功了。
可以先输入一些简单的命令来看下

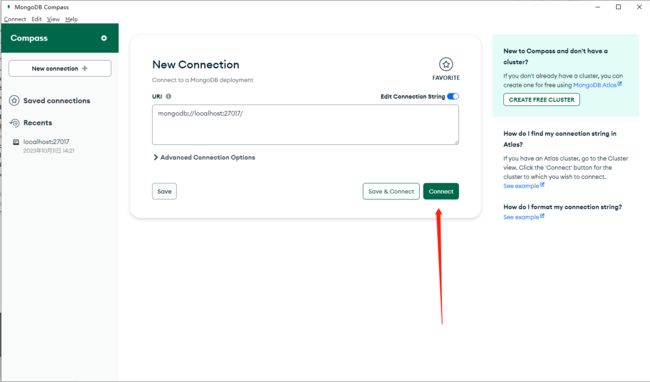
2.3 安装 Compass 图形化界面客户端
在 MongoDB 官网下载 MongoDB Compass,则按照步骤安装,如果是下载加压缩版,直接解压,执行里面的 MongoDBCompassCommunity.exe 文件即可。在打开的界面中,输入主机地址、端口等相关信息,点击连接:
2.4 Linux 系统安装和启动
第一步,你可以从 MongoDB 官网下载,如下
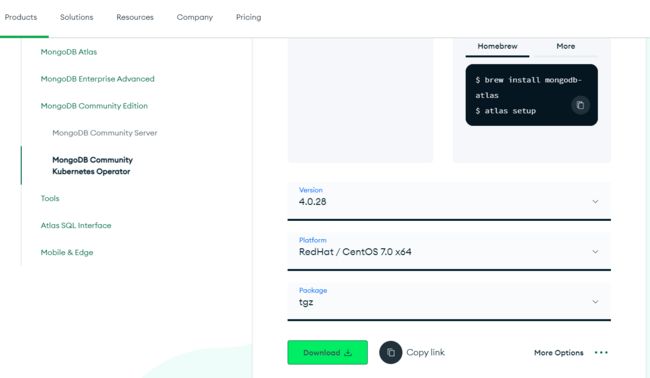
第二步,下载完成后上传到 linux 服务器的 /usr/local 路径下,然后执行以下的步骤:
# 解压文件
[root@node1 local]# tar -xvf mongodb-linux-x86_64-rhel70-4.0.28.tgz
# 文件重命名
[root@node1 local]# mv mongodb-linux-x86_64-rhel70-4.0.28 mongodb
# 新建目录用于数据存储
[root@node1 local]# mkdir -p mongodb/single/data/db
# 新建目录用于日志存储
[root@node1 local]# mkdir -p mongodb/single/log
# 新建并修改配置文件
[root@node1 local]# vi mongodb/single/mongod.conf配置文件的内容如下:
systemLog:
# MongoDB 发送所有日志输出的目标指定为文件
# The path of the log file to which mongod or mongos should send all diagnostic logging
information
destination: file
# mongod 或 mongos 应向其发送所有诊断日志记录信息的日志文件的路径
path: "/usr/local/mongodb/single/log/mongod.log"
# 当 mongos 或 mongod 实例重新启动时,mongos 或 mongo d会将新条目附加到现有日志文件的末尾。
logAppend: true
storage:
# mongod 实例存储其数据的目录。storage.dbPath 设置仅适用于 mongod。
# The directory where the mongod instance stores its data.Default Value is "/data/db".
dbPath: "/usr/local/mongodb/single/data/db"
journal:
#启用或禁用持久性日志以确保数据文件保持有效和可恢复。
enabled: true
processManagement:
# 启用在后台运行 mongos 或 mongod 进程的守护进程模式。
fork: true
net:
# 服务实例绑定的IP,默认是 localhost
bindIp: localhost,192.168.229.154
# bindIp
# 绑定的端口,默认是 27017
port: 27017第三步,启动服务,并查看是否启动成功。
# 启动服务
[root@node1 local]# /usr/local/mongodb/bin/mongod -f mongodb/single/mongod.conf
about to fork child process, waiting until server is ready for connections.
forked process: 9788
child process started successfully, parent exiting
# 通过进程来查看服务是否启动了
[root@node1 local]# ps -ef | grep mongod
root 9788 1 3 23:38 ? 00:00:00 /usr/local/mongodb/bin/mongod -f mongodb/single/mongod.conf
root 9985 4542 0 23:38 pts/1 00:00:00 grep --color=auto mongod
第四步,开放远程连接,需要关闭防火墙,命令如下
# 查看防火墙状态
systemctl status firewalld
# 临时关闭防火墙
systemctl stop firewalld
# 开机禁止启动防火墙
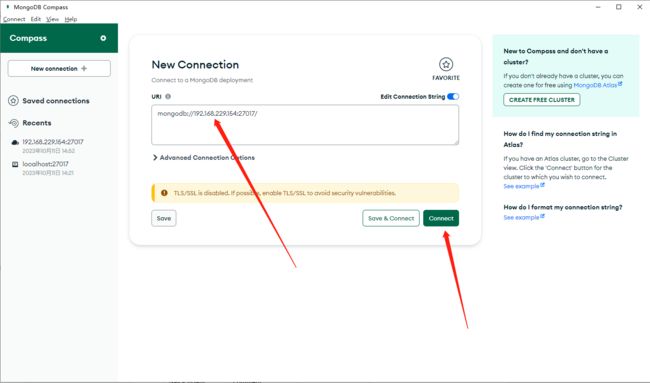
systemctl disable firewalld关闭防火墙之后,使用 Compass 工具连接我们刚才启动的 MongoDB 服务,如下图
三、基本常用命令
3.1 案例需求
存放文章评论的数据存放到 MongoDB 中,数据结构参考如下,其中数据库为 articledb,
|
专栏文章评论
|
comment
|
||
|
字段名称
|
字段含义
|
字段类型
|
备注
|
|
_id
|
ID
|
ObjectId 或 String
|
Mongo 的主键的字段
|
|
articleid
|
文章 ID
|
String
|
|
|
content
|
评论内容
|
String
|
|
|
userid
|
评论人 ID
|
String
|
|
|
nickname
|
评论人昵称
|
String
|
|
|
createdatetime
|
评论的日期时间
|
Date
|
|
|
likenum
|
点赞数
|
Int32
|
|
|
replynum
|
回复数
|
Int32
|
|
|
state
|
状态
|
String
|
0 :不可见; 1 :可见;
|
|
parentid
|
上级 ID
|
String
|
如果为 0 表示文章的顶级评论
|
3.2 数据库操作
3.2.1 选择和创建数据库
在 MongoDB 中,集合只有在内容插入后才会创建。 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
# 选择和创建数据库的语法格式
# 数据库名可以是满足以下条件的任意UTF-8字符串。
# 不能是空字符串("")
# 不得含有' '(空格)、.、$、/、\和\0 (空字符)
# 应全部小写
# 最多64字节
use 数据库名称
# 如果数据库不存在则自动创建,例如,以下语句创建 spitdb 数据库
use articledb
# 查看有权限查看的所有的数据库命令
show dbs 或 show databases
# 查看正在使用的数据库命令
# MongoDB 中默认的数据库为 test,如果你没有选择数据库,集合将存放在 test 数据库中。
db
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库,如下
admin: 从权限的角度来看,这是 "root" 数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
config: 当 Mongo 用于分片设置时,config 数据库在内部使用,用于保存分片的相关信息。
3.2.2 数据库的删除
# 会删除当前正在使用的库,主要用来删除已经持久化的数据库
db.dropDatabase()3.3 集合操作
集合,类似关系型数据库中的表。可以显示的创建,也可以隐式的创建。
3.3.1 集合的显示创建
# 集合的命名规范
# 集合名不能是空字符串""。
# 集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。
# 集合名不能以"system."开头,这是为系统集合保留的前缀。
# 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
# 基本语法格式如下
# name: 要创建的集合名称
db.createCollection(name)
# 创建一个名为 mycollection 的普通集合
db.createCollection("mycollection")
# 查看当前库中的表
show collections 或 show tables
3.3.2 集合的隐式创建
当向一个集合中插入一个文档的时候,如果集合不存在,则会自动创建集合。通常我们使用隐式创建文档即可。
3.3.3 集合的删除
# 语法格式如下
db.collection.drop() 或 db.集合.drop()
# 要删除 mycollection 集合,
# 如果成功删除选定集合,则 drop() 方法返回 true,否则返回 false
db.mycollection.drop()
3.4 文档操作
文档(document)的数据结构和 JSON 基本一样。所有存储在集合中的数据都是 BSON 格式。
3.4.1 文档的插入
1):单个文档的插入
使用 insert() 或 save() 方法向集合中插入文档,语法如下:
db.collection.insert(
,
{
writeConcern: ,
ordered:
}
)
|
Parameter
|
Type
|
Description
|
|
document
|
document or array
|
要插入到集合中的文档或文档数组。( (json 格式)
|
|
writeConcern
|
document
|
插入时性能和可靠性的级别,了解即可。 |
|
ordered
|
boolean
|
可选。如果为真,则按顺序插入数组中的文档,如果其中一个文档出现错误,MongoDB将返回而不处理数组中的其余文档。如果为假,则执行无序插入,如果其中一个文档出现错误,则继续处理数组中的主文档。在版本2.6+中默认为true |
接下来我们要向 comment 的集合(表)中插入一条测试数据,执行下面语句:
# 示例代码
db.comment.insert(
{"articleid":"100000","content":"今天天气真好,阳光明媚","userid":"1001","nickname":"Rose","createdatetime":new Date(),"likenum":NumberInt(10),"state":null}
)提示:
1)comment 集合如果不存在,则会隐式创建。
2)mongo 中的数字,默认情况下是 double 类型,如果要存整型,必须使用函数NumberInt(整型数字),否则取出来就有问题了。
3)插入当前日期使用 new Date()
4)插入的数据没有指定 _id ,会自动生成主键值
5)如果某字段没值,可以赋值为 null,或不写该字段。
出现下面的内容就证明插入成功了
![]()
注意:
1. 文档中的键/值对是有序的。
2. 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
3. MongoDB 区分类型和大小写。
4. MongoDB 的文档不能有重复的键。
5. 文档的键是字符串。除了少数例外情况,键可以使用任意 UTF-8 字符。
文档键命名规范:
1、键不能含有\0 (空字符)。这个字符用来表示键的结尾。
2、.和$有特别的意义,只有在特定环境下才能使用。
3、以下划线 "_" 开头的键是保留的(不是严格要求的)。
2):多个文档的插入
使用 insertMany() 方法向集合中插入多个文档,语法如下:
db.collection.insertMany(
[ , , ... ],
{
writeConcern: ,
ordered:
}
) 接下来我们要向 comment 的集合(表)中插入多条文章评论,执行下面语句:
db.comment.insertMany([
{"_id":"1","articleid":"100001","content":"我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。","userid":"1002","nickname":"相忘于江湖","createdatetime":new Date("2019-08-05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"},
{"_id":"2","articleid":"100001","content":"我夏天空腹喝凉开水,冬天喝温开水","userid":"1005","nickname":"伊人憔悴","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888),"state":"1"},
{"_id":"3","articleid":"100001","content":"我一直喝凉开水,冬天夏天都喝。","userid":"1004","nickname":"杰克船长","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"},
{"_id":"4","articleid":"100001","content":"专家说不能空腹吃饭,影响健康。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-06T08:18:35.288Z"),"likenum":NumberInt(2000),"state":"1"},
{"_id":"5","articleid":"100001","content":"研究表明,刚烧开的水千万不能喝,因为烫嘴。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-06T11:01:02.521Z"),"likenum":NumberInt(3000),"state":"1"}
]);
提示:
如果插入时指定了 _id ,则主键就是该值。如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚掉。
因为批量插入由于数据较多容易出现失败,因此,可以使用 try catch 进行异常捕捉处理,测试的时候可以不处理。如(了解):
try {
db.comment.insertMany([
{"_id":"1","articleid":"100001","content":"我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。","userid":"1002","nickname":"相忘于江湖","createdatetime":new Date("2019-08-05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"},
{"_id":"2","articleid":"100001","content":"我夏天空腹喝凉开水,冬天喝温开水","userid":"1005","nickname":"伊人憔悴","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888),"state":"1"},
{"_id":"3","articleid":"100001","content":"我一直喝凉开水,冬天夏天都喝。","userid":"1004","nickname":"杰克船长","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"},
{"_id":"4","articleid":"100001","content":"专家说不能空腹吃饭,影响健康。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-06T08:18:35.288Z"),"likenum":NumberInt(2000),"state":"1"},
{"_id":"5","articleid":"100001","content":"研究表明,刚烧开的水千万不能喝,因为烫嘴。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-06T11:01:02.521Z"),"likenum":NumberInt(3000),"state":"1"}
]);
} catch (e) {
print (e);
}3.4.2 文档的查询
# 查询数据的语法格式如下:
db.collection.find(, [projection]) |
Parameter
|
Type
|
Description
|
|
query
|
document
|
可选。使用查询运算符指定选择筛选器。若要返回集合中的所有文档,请省略此参数或传递空文档( {} )。 |
|
projection
|
document
|
可选。指定要在与查询筛选器匹配的文档中返回的字段(投影)。若要返回匹配文档中的所有字段,请省略此参数。 |
1)查询所有
db.comment.find()
或
db.comment.find({})这里你会发现每条文档会有一个叫 _id 的字段,这个相当于我们原来关系数据库中表的主键,当你在插入文档记录时没有指定该字段,MongoDB 会自动创建,其类型是 ObjectID 类型。
如果我们在插入文档记录时指定该字段也可以,其类型可以是 ObjectID 类型,也可以是MongoDB 支持的任意类型。

如果我想按一定条件来查询,比如我想查询 userid 为 1003 的记录,怎么办?很简单!只要在 find() 中添加参数即可,参数也是 json 格式,如下:
# 查询指定条件的数据
db.comment.find({userid:'1003'})![]()
如果你只需要返回符合条件的第一条数据,我们可以使用 findOne 命令来实现,语法和 find 一样。
# 查询用户编号是 1003 的记录,但只最多返回符合条件的第一条记录:
db.comment.findOne({userid:'1003'})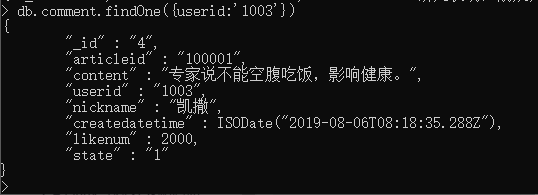
2)投影查询
如果要查询结果返回部分字段,则需要使用投影查询(不显示所有字段,只显示指定的字段),其中 _id 字段会默认显示。
# 查询结果只显示 _id、userid、nickname 字段
db.comment.find({userid:"1003"},{userid:1,nickname:1})
# 查询结果只显示 、userid、nickname ,不显示 _id
db.comment.find({userid:"1003"},{userid:1,nickname:1,_id:0})
# 查询所有数据,但只显示 _id、userid、nickname
db.comment.find({},{userid:1,nickname:1})
3.4.3 文档的更新
更新文档的语法如下:
db.collection.update(query, update, options)
//或
db.collection.update(
,
,
{
upsert: ,
multi: ,
writeConcern: ,
collation: ,
arrayFilters: [ , ... ],
hint: // Available starting in MongoDB 4.2
}
) 只需要关注前四个参数就可以了
|
Parameter
|
Type
|
Description
|
|
query
|
document
|
更新的选择条件。可以使用与 find() 方法中相同的查询选择器,类似 sql update 查询内 where 后面的。在 3.0 版中进行了更改:当使用 upsert:true 执行 update() 时,如果查询使用点表示法在 _id 字段上指定条件,则 MongoDB 将拒绝插入新文档。
|
|
update
|
document or pipeline | 要应用的修改。该值可以是:包含更新运算符表达式的文档,或仅包含:对的替换文档 |
|
upsert
|
boolean
|
可选。如果设置为 true ,则在没有与查询条件匹配的文档时创建新文档。默认值为 false ,如果找不到匹配项,则不会插入新文档。
|
|
multi
|
boolean
|
可选。如果设置为 true ,则更新符合查询条件的多个文档。如果设置为 false ,则更新一个文档。默认值为 false 。
|
|
writeConcern
|
document
|
可选。表示写问题的文档。抛出异常的级别。
|
|
collation
|
document
|
可选。指定要用于操作的校对规则。校对规则允许用户为字符串比较指定特定于语言的规则,例如字母大小写和重音标记的规则。 |
|
arrayFilters
|
array
|
可选。一个筛选文档数组,用于确定要为数组字段上的更新操作修改哪些数组元素。
|
|
hint
|
Document or string |
可选。指定用于支持查询谓词的索引的文档或字符串。该选项可以采用索引规范文档或索引名称字符串。如果指定的索引不存在,则说明操作错误。例如,请参阅版本 4 中的 “ 为更新操作指定提示。
|
1):覆盖的修改
# 修改_id为1的记录,点赞量为1001
db.comment.update({_id:"1"},{likenum:NumberInt(1001)})执行完上面的语句后,我们会发现,这条文档除了 likenum 字段其它字段都不见了

2):局部修改
为了解决这个问题,我们需要使用修改器 $set 来实现,命令如下
# 修改 _id 为 2 的记录,浏览量为 889
db.comment.update({_id:"2"},{$set:{likenum:NumberInt(889)}})这样执行就可以更新指定的字段了,如下所示
![]()
3):批量的修改
# 默认只修改第一条数据
db.comment.update({userid:"1003"},{$set:{nickname:"凯撒2"}})
# 修改所有符合条件的数据
db.comment.update({userid:"1003"},{$set:{nickname:"凯撒大帝"}},{multi:true})4):列值增长的修改
如果我们想实现对某列值在原有值的基础上进行增加或减少,可以使用 $inc 运算符来实现。
# 对3号数据的点赞数,每次递增1
db.comment.update({_id:"3"},{$inc:{likenum:NumberInt(1)}})3.4.4 文档的删除
# 删除文档的语法结构
db.集合名称.remove(条件)
# 将数据全部删除,请慎用
db.comment.remove({})
# 删除_id=1的记录,输入以下语句
db.comment.remove({_id:"1"})