Elasticsearch基础篇(四):Elasticsearch的基础介绍与索引设置
Elasticsearch的基础介绍与索引设置
- 一、Elasticsearch概述
-
- Elasticsearch简介
- 什么是全文检索引擎
- Elasticsearch 应用案例
- 二、索引和文档的概念
-
- 1. 索引(Index)
- 2. 文档(Document)
- 三、倒排索引(Inverted Index)
-
- 1. 倒排索引的概念
- 2. 倒排索引的构建过程
- 3. 倒排索引的查询过程
- 4. 倒排索引的优势
- 5. 正向索引与倒排索引的对比
-
- 5.1 正向索引(forward index)
- 5.2 倒排索引(inverted index)
- 四、索引的创建
-
- 索引创建
- 索引查询
- 删除索引
- 全部索引查询
- 五、索引模块设置
-
- 索引模块
- 索引设置
- 静态索引设置
-
- `index.number_of_shards`
- index.number_of_routing_shards
- index.shard.check_on_startup
- index.codec
- index.routing_partition_size
- index.soft_deletes.enabled
- index.soft_deletes.retention_lease.period
- index.load_fixed_bitset_filters_eagerly
- 动态索引设置
-
- index.hidden
- `index.number_of_replicas`
- index.auto_expand_replicas
- index.search.idle.after
- `index.refresh_interval`
- `index.max_result_window`
- `index.max_inner_result_window`
- index.max_rescore_window
- `index.max_docvalue_fields_search`
- `index.max_script_fields`
- index.max_refresh_listeners
- index.analyze.max_token_count
- index.highlight.max_analyzed_offset
- `index.max_terms_count`
- index.max_regex_length
- index.routing.allocation.enable
- index.routing.rebalance.enable
一、Elasticsearch概述
Elasticsearch简介
Elasticsearch是一个基于lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。
ELK技术栈是Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称。
而Elasticsearch 是一个开源的高扩展的分布式全文搜索引擎, 是整个 ELK技术栈的核心。
- Elasticsearch是一个基于lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。
- Logstash是中央数据流引擎,用于从不同目标(文件/数据存储/mq)收集不同格式的数据,经过过滤后支持输出到不同目的地
- Kibana可以将es的数据通过友好的页面展示出来,提供实时分析的功能

什么是全文检索引擎
这里说到的全文搜索引擎指的是目前广泛应用的主流搜索引擎。它的工作原理是
计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的应用场景
- 检索的数据对应是大量的非结构化的文本型数据
- 文件的记录量至少是十万以上级别
- 支持交互式文本的全文检索查询
- 对于检索结果的相关性具有较高的要求,且检索的实时性要求很高
Elasticsearch 应用案例
GitHub: 2013 年初,抛弃了 Solr,采取 Elasticsearch 来做 PB 级的搜索。 “GitHub 使用Elasticsearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码”。
维基百科:启动以 Elasticsearch 为基础的核心搜索架构
百度:目前广泛使用 Elasticsearch 作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部 20 多个业务线(包括云分析、网盟、预测、文库、直达号、钱包、 风控等),单集群最大 100 台机器, 200 个 ES 节点,每天导入 30TB+数据。
新浪:使用 Elasticsearch 分析处理 32 亿条实时日志。
阿里:使用 Elasticsearch 构建日志采集和分析体系。
二、索引和文档的概念
1. 索引(Index)
-
定义:索引是 Elasticsearch 存储、组织和搜索数据的逻辑容器。它类似于 MySQL 中的数据表,一个 Elasticsearch 集群可以包含多个索引。
-
特点:
- 索引通常包含一组具有相似结构的文档。
- 每个索引都有一个唯一的名称,用于标识和检索数据。
- 索引可以被视为 Elasticsearch 中数据的逻辑分区,类似于数据库中的表。
-
类比 MySQL:索引类似于 MySQL 中的数据库。在 MySQL 中,一个数据库可以包含多个表,而在 Elasticsearch 中,一个集群可以包含多个索引。
2. 文档(Document)
-
定义:文档是 Elasticsearch 存储的
基本数据单元,它类似于 MySQL 中的行。每个文档都是 JSON 格式的数据对象。 -
特点:
- 文档包含各种字段,字段可以是文本、数字、日期等类型的数据。
- 每个文档都有一个唯一的 ID,用于标识文档。
- 文档通常代表了一个实体,例如一篇文章、一本书、一位用户等。
-
类比 MySQL:文档类似于 MySQL 中的行。在 MySQL 中,一行数据表示一个实体,例如一位用户的信息。在 Elasticsearch 中,一个文档也表示一个实体,例如一篇文章的内容。
三、倒排索引(Inverted Index)
倒排索引(Inverted Index)是 Elasticsearch 检索引擎的核心之一,它是支持高效文本搜索和全文检索的关键数据结构。倒排索引在信息检索领域得到广泛应用,它的工作方式与传统数据库索引不同,更适用于文本数据。
1. 倒排索引的概念
-
定义:倒排索引是一种用于快速查找文档中包含特定词汇或关键字的数据结构。它将文档中的每个词汇与包含该词汇的文档进行关联,并构建一张映射表,将词汇作为键,对应的文档列表作为值。
-
核心概念:
- 词项(Term):文档中的单词或关键字,是倒排索引的基本单位。
- 倒排列表(Inverted List):存储了每个词项出现在哪些文档中的列表。每个词项都有一个对应的倒排列表。
2. 倒排索引的构建过程
倒排索引的构建过程可以分为以下几个步骤:
步骤 1:文档分词(Tokenization)
- 文档首先需要被分成词项。这个过程通常包括将文本拆分成单词,去除标点符号,处理大小写等。
步骤 2:建立倒排列表(Inverted Lists)
- 对于每个词项,记录它出现在哪些文档中。每个文档ID都被添加到倒排列表中,以表示该词项在该文档中出现。
步骤 3:建立倒排索引(Inverted Index)
- 将所有的倒排列表组合成一个倒排索引。这个索引由词项作为键,对应的倒排列表作为值构成。
3. 倒排索引的查询过程
-
查询阶段:当用户输入一个查询词汇时,Elasticsearch 将查找倒排索引,找到包含该词汇的文档ID列表。
-
组合结果:Elasticsearch 将不同词汇的文档ID列表组合,得到满足查询条件的文档列表。
-
排序与评分:根据查询的相关性,对文档进行排序并计算文档的评分,以确定最匹配的文档。
-
返回结果:将排序后的文档列表返回给用户,完成搜索过程。
4. 倒排索引的优势
-
高效的搜索速度:由于倒排索引的结构,它可以快速定位到包含查询词汇的文档,而不需要遍历所有文档。
-
支持复杂查询:倒排索引支持各种查询类型,包括全文搜索、短语匹配、模糊搜索、通配符查询等。
-
支持分布式检索:Elasticsearch 可以在分布式环境中构建和查询倒排索引,以支持大规模数据的存储和检索。
-
高度可定制:Elasticsearch 允许用户定义自定义的分析器和过滤器,以适应不同的文本数据和检索需求。
5. 正向索引与倒排索引的对比
在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(实际上在搜索引擎索引库中,关键词也已经转换为关键词ID)。例如“文档1”经过分词,提取了20个关键词,每个关键词都会记录它在文档中的出现次数和出现位置。
5.1 正向索引(forward index)
得到正向索引的结构如下:通过key,去找value。
“文档1”的ID > 单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。
“文档2”的ID > 此文档出现的关键词列表。

正向索引的弊端:假设使用正向索引检索关键词"索引测试",那么需要扫描全库索引检索,然后根据某个权重策略进行排序返回给用户。问题就在于数据量十分庞大时的全库扫描无法满足实时的检索需求
5.2 倒排索引(inverted index)
搜索引擎会将正向索引重新建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
得到倒排索引的结构如下:从词的关键字,去找文档ID。
“关键词1”:“文档1”的ID,“文档2”的ID,…………。
“关键词2”:带有此关键词的文档ID列表。

四、索引的创建
下列操作基于kibana7.17.11,安装部署可参考 ibana7.17.11安装部署
索引创建
PUT /books
{
"acknowledged" : true, //响应结果
"shards_acknowledged" : true,//分配结果
"index" : "books"//索引名
}

索引查询
GET /books
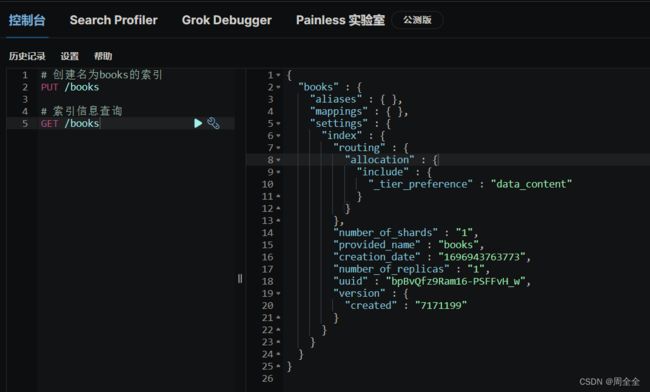
查询结果为Elasticsearch索引的元数据信息,其中包含了索引的配置和属性每项的作用:
{
# 索引的名称,索引是Elasticsearch用来存储和组织数据的主要数据结构之一
"books" : { # 别名(aliases)的部分,用于定义索引的别名。别名是索引的可选名称,可以用于查询或引用索引,以简化索引操作
"aliases" : { }, # 索引的映射(mapping)部分。索引映射定义了索引中`存储的文档的结构和字段类型`。这里没有显式定义映射表示将根据插入的文档自动创建映射。
"mappings" : { }, # 索引的设置(settings)部分,包含了索引级别的配置。
"settings" : { # 索引级别的设置,包含了以下子项
"index" : { # 索引路由配置的一部分,指定了分片(shard)分配策略。
"routing" : { # 分片分配的配置,包括以下子项:
"allocation" : { # 指定了分片分配的条件,这里使用了`"_tier_preference": "data_content"`,表示根据数据内容的优先级来分配分片。
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1", # 指定了索引的主分片数量,这里设置为"1",意味着索引将被划分为1个主分片
"provided_name" : "books", # 索引的提供名称,即索引的实际名称,这里是"books"
"creation_date" : "1696943763773", # 索引的创建日期,表示为一个时间戳(毫秒级)
"number_of_replicas" : "1", # 指定了每个主分片的副本数量,这里设置为"1",表示每个主分片有1个副本
"uuid" : "bpBvQfz9Ram16-PSFFvH_w",# 索引的唯一标识符(UUID)
"version" : { # 包含了索引的版本信息
"created" : "7171199" # 索引的创建版本
}
}
}
}
}
删除索引
慎重使用,删除后数据就丢失了
delete /books
全部索引查询
GET _cat/indices?v
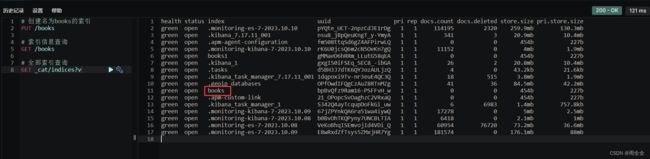
返回字段说明:
- health 当前服务器健康状态: green(集群完整) yellow(单点正常、集群不完整) red(单点不正常)
- status 索引打开、关闭状态
- index 索引名
- uuid 索引统一编号(随机生成)
- pri 主分片数量
- rep 副本数量
- docs.count 可用文档数量
- docs.deleted 文档删除状态(逻辑删除)
- store.size 主分片和副分片整体占空间大小
- pri.store.size 主分片占空间大小
五、索引模块设置
以下来自官方文档:
索引模块
索引模块是每个索引创建的模块,控制与索引相关的所有方面。
索引设置
索引级别的设置可以针对每个索引进行设置。设置可以是:
- 静态的
它们只能在索引创建时或在关闭的索引上设置。 - 动态的
它们可以在活动索引上使用update-index-settings API进行更改。
在关闭的索引上更改静态或动态索引设置可能导致不正确的设置,而无法在不删除和重新创建索引的情况下纠正。
静态索引设置
标红的设置为常用设置,可以暂时忽略非标红的设置
index.number_of_shards
索引应具有的主分片数量。默认为1。此设置只能在索引创建时设置。不能在关闭的索引上更改它。
每个索引的分片数量限制为1024。这个限制是为了防止意外创建可能由于资源分配而使集群不稳定的索引。可以通过在集群中的每个节点上指定"export ES_JAVA_OPTS="-Des.index.max_number_of_shards=128"系统属性来修改限制。
index.number_of_routing_shards
用于拆分索引的路由分片数。
例如,一个具有5个分片的索引,number_of_routing_shards设置为30(5 x 2 x 3),可以按2或3的因数拆分。换句话说,它可以按以下方式拆分:
5 → 10 → 30(首先按2拆分,然后按3拆分)
5 → 15 → 30(首先按3拆分,然后按2拆分)
5 → 30(按6拆分)
此设置的默认值取决于索引中主分片的数量。默认值设计为允许按2的因数拆分,最多可以拆分为1024个分片。
index.shard.check_on_startup
在打开之前,是否应检查分片是否损坏。当检测到损坏时,将阻止分片被打开。接受以下内容:
false(默认值):在打开分片时不检查损坏。
checksum:检查物理损坏。
true:检查物理和逻辑损坏。从CPU和内存使用的角度来看,这更昂贵。
(只适用于专家。在大型索引上检查分片可能需要很长时间。)
index.codec
默认值使用LZ4压缩来压缩存储的数据,但可以设置为best_compression,它使用DEFLATE以获得更高的压缩比,但牺牲了存储字段性能。如果要更新压缩类型,则将在合并段之后应用新的压缩类型。可以使用force merge来强制执行段合并。
index.routing_partition_size
自定义路由值可以去的分片数量。默认为1,只能在索引创建时设置。此值必须小于index.number_of_shards,除非index.number_of_shards的值也为1。有关如何使用此设置的更多详细信息,请参阅路由到索引分区。
index.soft_deletes.enabled
[7.6.0] 在7.6.0中已弃用。在未来的Elasticsearch版本中,将删除禁用软删除的索引的创建。指示索引上是否启用了软删除。只能在索引创建时配置软删除,并且只能在Elasticsearch 6.5.0或之后创建的索引上配置。默认为true。
index.soft_deletes.retention_lease.period
在将其视为过期之前,保留分片历史保留租约的最长期限。分片历史保留租约确保在Lucene索引上合并期间保留软删除。如果软删除在可以复制到跟随者之前被合并,那么下面的过程将由于主节点上的不完整历史而失败。默认为12小时。
index.load_fixed_bitset_filters_eagerly
指示是否为嵌套查询预加载缓存的过滤器。可能的值为true(默认)和false。
动态索引设置
以下是与任何特定索引模块无关的所有动态索引设置的列表:
index.hidden
指示索引是否应默认隐藏。默认情况下,使用通配符表达式时,隐藏索引不会默认返回。此行为可以通过使用expand_wildcards参数控制每个请求来更改。可能的值为true和false(默认)。
index.number_of_replicas
每个主分片具有的副本数量。默认为1。
index.auto_expand_replicas
根据集群中数据节点的数量自动扩展副本数量。设置为破折号分隔的下限和上限(例如0-5),或使用all作为上限(例如0-all)。默认为false(即禁用)。请注意,自动扩展的副本数量仅考虑分配过滤规则,但不考虑任何其他分配规则,例如分片分配感知和每个节点的总分片数,这可能会导致集群健康状态变为黄色,如果适用的规则阻止分配所有副本。
index.search.idle.after
在分片在没有搜索或获取请求的情况下多长时间才能被视为搜索空闲。默认值为30秒。
index.refresh_interval
执行刷新操作的频率,使索引中的最新更改对搜索可见。默认为1秒。可以设置为-1以禁用刷新。如果未明确设置此设置,则在未看到搜索流量至少index.search.idle.after秒的分片将不会接收后台刷新,直到它们收到搜索请求。命中等待刷新挂起的空闲分片的搜索将等待下一个后台刷新(在1秒内)。此行为
旨在自动优化默认情况下执行批量索引时,不执行搜索的情况。为了退出此行为,应将1秒的明确值设置为刷新间隔。
index.max_result_window
搜索此索引时from + size的最大值。默认为10000。搜索请求占用堆内存和时间与from + size成正比,这限制了内存。请参阅滚动或搜索之后以提高效率的替代方法,以提高此值。
index.max_inner_result_window
内部命中定义和此索引的顶级命中的from + size的最大值。默认为100。内部命中和顶级命中聚合占用堆内存和时间与from + size成正比,这限制了内存。
关于此项设置的说明
index.max_inner_result_window 是 Elasticsearch 索引级别的一个动态设置,用于控制内部命中(inner hits)的分页大小。内部命中是 Elasticsearch 查询的一部分,通常用于在父文档与相关子文档之间建立关联。当在查询中使用内部命中时,可以通过 index.max_inner_result_window 来限制内部命中的结果数量。
例如,如果在父文档与相关子文档之间执行了一个查询,并且设置了 index.max_inner_result_window 为默认值100,那么将只能获得最多100个相关的子文档。对于控制内部命中结果的数量以防止内存消耗过多非常有用.
总之,index.max_inner_result_window 允许限制内部命中结果的数量,以控制查询的性能和资源消耗。
index.max_rescore_window
在此索引的搜索中,rescore请求的window_size的最大值。默认为index.max_result_window,默认为10000。搜索请求占用堆内存和时间与max(window_size,from + size)成正比,这限制了内存。
设置说明
index.max_rescore_window 是 Elasticsearch 索引级别的动态设置,用于控制 rescore 查询中的 window_size 的最大值。默认情况下,它与 index.max_result_window 相同,为 10000。这限制了在重新评分查询中要考虑的文档数量,以防止过多的内存和资源消耗。这个设置影响搜索性能和资源分配,需要谨慎配置,以满足特定用例的需求,同时确保集群稳定性。
index.max_docvalue_fields_search
允许在查询中使用的docvalue_fields的最大数量。默认为100。文档值字段是昂贵的,因为它们可能会导致每个字段的每个文档的搜索。
设置说明
index.max_docvalue_fields_search是Elasticsearch中的一个配置参数,用于控制搜索操作中能够使用的最大doc_values字段数量。doc_values是Elasticsearch用于存储字段值的一种数据结构,它们通常用于排序、聚合和脚本等操作。
以下是有关index.max_docvalue_fields_search参数的说明:
-
默认值:默认情况下,
index.max_docvalue_fields_search参数的值默认为100。文档值字段是昂贵的,因为它们可能会导致每个字段的每个文档的搜索。 -
用途:该参数的主要用途是限制搜索操作中使用doc_values字段的数量,以防止搜索请求耗尽过多的内存资源。当搜索请求涉及大量的doc_values字段时,可能会导致内存使用过多,从而影响Elasticsearch节点的性能和稳定性。
-
配置方式:可以在Elasticsearch的索引设置中配置
index.max_docvalue_fields_search参数。例如,可以使用以下方式配置:PUT /your_index_name/_settings { "index.max_docvalue_fields_search": 100 }
上述示例将index.max_docvalue_fields_search参数的值设置为100,表示每个搜索请求最多只能使用100个doc_values字段。
- 注意事项:在设置该参数时,需要根据具体需求和硬件资源来选择合适的值。如果搜索请求通常涉及大量的doc_values字段,可能需要增加该参数的值以提高性能。然而,过高的值可能会导致内存压力,因此需要权衡。
index.max_script_fields
在查询中允许的script_fields的最大数量。默认为32。
设置说明
index.max_script_fields是Elasticsearch中的一个配置参数,用于控制一个搜索请求中可以使用的最大脚本字段数量。脚本字段允许在搜索请求中使用自定义脚本来计算或变换字段值。
以下是有关index.max_script_fields参数的说明:
-
默认值:默认情况下,
index.max_script_fields参数的值为32,表示每个搜索请求最多只能使用32个脚本字段。 -
用途:该参数的主要用途是限制搜索请求中使用脚本字段的数量,以防止搜索请求中使用大量脚本字段而导致性能下降。脚本执行可能会消耗一定的计算资源,因此限制其数量可以帮助确保Elasticsearch节点的性能和稳定性。
-
配置方式:可以在Elasticsearch的索引设置中配置
index.max_script_fields参数。例如可以使用以下方式配置:PUT /your_index_name/_settings { "index.max_script_fields": 50 }上述示例将
index.max_script_fields参数的值设置为50,表示每个搜索请求最多只能使用50个脚本字段。 -
注意事项:在设置此参数时,需要根据的具体需求和硬件资源来选择合适的值。如果搜索请求需要大量脚本字段来执行自定义计算或变换操作,可能需要增加该参数的值。要注意过高的值可能会导致性能问题。
index.max_refresh_listeners
索引的每个分片上可用的刷新侦听器的最大数量。这些侦听器用于实现refresh=wait_for。
index.analyze.max_token_count
可以使用_analyze API生成的令牌的最大数量。默认为10000。
index.highlight.max_analyzed_offset
将分析的最大字符数,将其用于突出显示请求。仅在请求突出显示时适用于未带有偏移或词项向量的文本索引。默认为1000000。
index.max_terms_count
在Terms查询中允许使用的术语的最大数量。默认为65536。
index.max_regex_length
在Regexp查询中允许使用的正则表达式的最大长度。默认为1000。
index.routing.allocation.enable
控制此索引的分片分配。可以设置为:
- all(默认值)-允许所有分片的分片分配。
- primaries-仅允许主分片的分片分配。
- new_primaries-仅允许新创建的主分片的分片分配。
- none-不允许分片分配。
index.routing.rebalance.enable
启用此索引的分片平衡。可以设置为:
- all(默认值)-允许所有分片的分片平衡。
- primaries-仅允许主分片的分片平衡。
- replicas-仅允许副本分片的分片平衡。
- none-不允许分片平衡。