分布式搜索引擎——elasticsearch(一)
目录
1、认识elasticsearch
正向索引和倒排索引
2、分词器
3、索引库操作
文档操作
4、RestClient操作
1、索引库
代码操作
2、文档
1、认识elasticsearch

正向索引和倒排索引
elasticsearch采用倒排索引:
- 文档(document):每条数据就是一个文档
- 词条(term):文档按照语义分成的词语
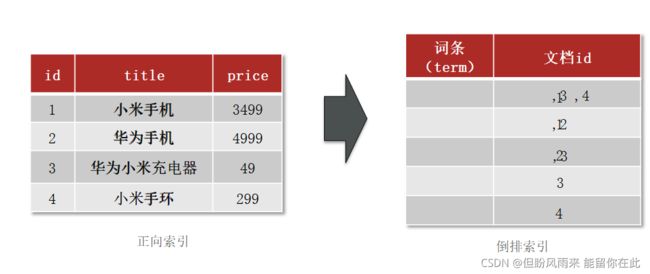
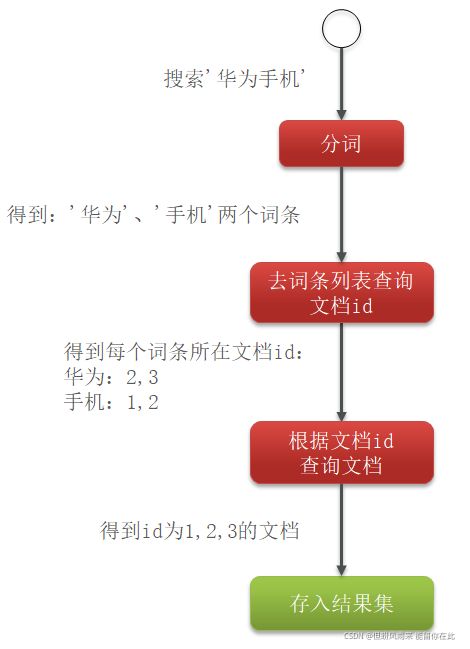
倒排索引中包含两部分内容:
- 词条词典(Term Dictionary):记录所有词条,以及词条与倒排列表(Posting List)之间的关系,会给词条创建索引,提高查询和插入效率
- 倒排列表(Posting List):记录词条所在的文档id、词条出现频率 、词条在文档中的位置等信息
- 文档id:用于快速获取文档
- 词条频率(TF):文档在词条出现的次数,用于评分

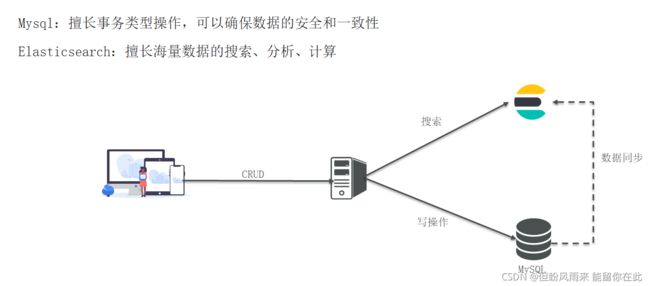
elasticsearch是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。
文档数据会被序列化为json格式后存储在elasticsearch中。



docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1http://192.168.126.134:9200/
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1http://192.168.126.135:5601/
2、分词器
es在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好。


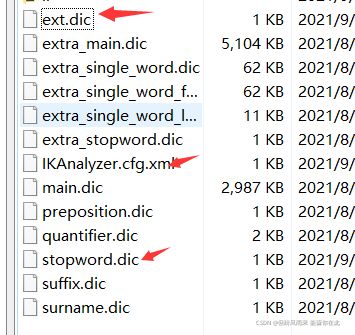
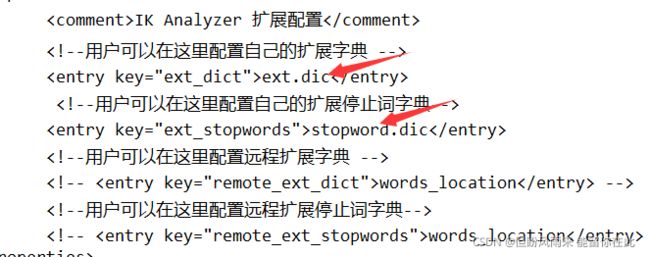
处理中文分词,一般会使用IK分词器。
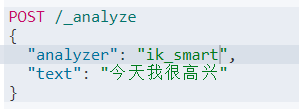
ik分词器包含两种模式:
- ik_smart:最少切分,粗粒度
- ik_max_word:最细切分,细粒度

3、索引库操作


ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下:
PUT /man
{
"mappings": {
"properties": {
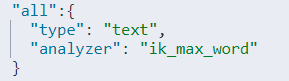
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
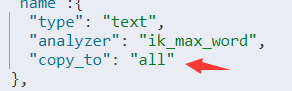
"name":{
"type": "object",
"properties": {
"firstname":{
"type":"keyword"
},
"lastname":{
"type":"keyword"
}
}
}
}
}
}

索引库和mapping一旦创建无法修改,但是可以添加新的字段 。

文档操作
新增文档
POST /man/_doc/1
{
"info":"一个乐观聪明的男生",
"email":"[email protected]",
"name":{
"firstname":"张",
"lastname":"三"
}
} 



4、RestClient操作
1、索引库
mapping要考虑的问题:
字段名、数据类型、是否参与搜索、是否分词、如果分词,分词器是什么?
id用keyword
type: keyword不分词,text分词
analyzer:如果分词选择分词器
"index": false 不参与搜索

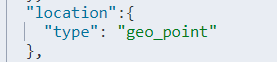
根据多个字段查询
代码操作
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.12.1
SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本

public class HotelIndexTest {
private RestHighLevelClient client;
//初始化
@Test
void test(){
System.out.println(client);
}
@BeforeEach
void before(){
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.126.135:9200")
));
}
@AfterEach
void after() throws IOException {
this.client.close();
}
}创建索引库
@Test
void test2() throws IOException {
// 1.创建Request对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
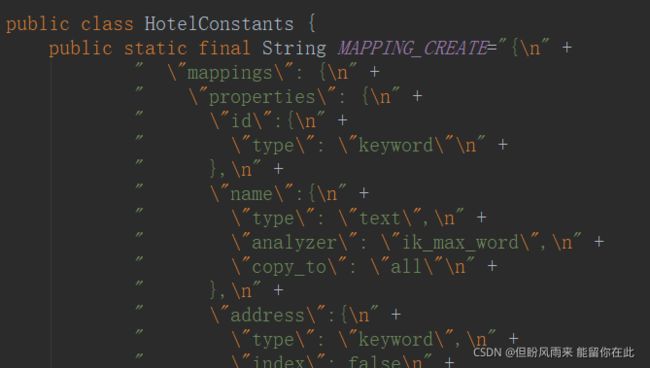
// 2.请求参数,MAPPING_TEMPLATE是静态常量字符串,内容是创建索引库的DSL语句
request.source(HotelConstants.MAPPING_CREATE, XContentType.JSON);
// 3.发起请求
client.indices().create(request, RequestOptions.DEFAULT);
} 
@Test //删除
void test3() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
client.indices().delete(request,RequestOptions.DEFAULT);
}
@Test //判断是否存在
void test4() throws IOException {
GetIndexRequest request = new GetIndexRequest("hotel");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists?"存在":"不存在");
}2、文档
@Test //将数据库中数据放入索引库
void test1() throws IOException {
Hotel hotel = hotelService.getById(36934L);
HotelDoc hotelDoc = new HotelDoc(hotel);
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);
}@Test //根据id查询到的文档数据是json,需要反序列化为java对象
void test2() throws IOException {
GetRequest request = new GetRequest("hotel","36934");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
String s = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(s, HotelDoc.class);
System.out.println(hotelDoc);
}@Test //局部更新。只更新部分字段,
void test3() throws IOException {
UpdateRequest request = new UpdateRequest("hotel","36934");
request.doc(
"price","520",
"starName","3钻"
);
client.update(request,RequestOptions.DEFAULT);
}@Test //删除
void test4() throws IOException {
DeleteRequest request = new DeleteRequest("hotel","36934");
client.delete(request,RequestOptions.DEFAULT);
}@Test //批量导入数据
void test5() throws IOException {
List list = hotelService.list();
BulkRequest request = new BulkRequest();
for(Hotel hotel : list){
HotelDoc hotelDoc = new HotelDoc(hotel);
request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).
source(JSON.toJSONString(hotelDoc), XContentType.JSON));
}
client.bulk(request,RequestOptions.DEFAULT);
} ![]()