Mysql日志之redo log、undo log 、binlog
日志
参考尚硅谷MySQL
MySQL有不同类型的日志文件,用来存储不同类型的日志,分为 二进制日志 、 错误日志 、 通用查询日志
和 慢查询日志 ,这也是常用的4种。MySQL 8又新增两种支持的日志: 中继日志 和 数据定义语句日志 。使
用这些日志文件,可以查看MySQL内部发生的事情。
-
**慢查询日志: ** slow query log记录所有执行时间超过long_query_time的所有查询,方便我们对查询进行优化。
-
**通用查询日志:**记录所有连接的起始时间和终止时间,以及连接发送给数据库服务器的所有指令,
对我们复原操作的实际场景、发现问题,甚至是对数据库操作的审计都有很大的帮助。
- **错误日志:**记录MySQL服务的启动、运行或停止MySQL服务时出现的问题,方便我们了解服务器的
状态,从而对服务器进行维护。
- **二进制日志: ** binlog 记录所有更改数据的语句,可以用于主从服务器之间的数据同步,以及服务器遇到故
障时数据的无损失恢复。
- **中继日志:**用于主从服务器架构中,从服务器用来存放主服务器二进制日志内容的一个中间文件。
从服务器通过读取中继日志的内容,来同步主服务器上的操作。
- **数据定义语句日志:**记录数据定义语句执行的元数据操作。
binlog 、undo log、redo log 的比较
undolog 、 redo log 是事务日志,存储引擎层生成的日志,主要用于事务的原子性、一致性和持久性(事务的另一大特性隔离性一般是通过锁来保证),binlog是二进制日志,只要应用于数据库的主从复制。
redo log
也叫做重做日志
前提认识:mysql的读写都是先通过一个内存缓冲池,然后再写入到磁盘,这里就涉及到一个问题,如何保证内存中的数据和内存中的数据是一致的呢?
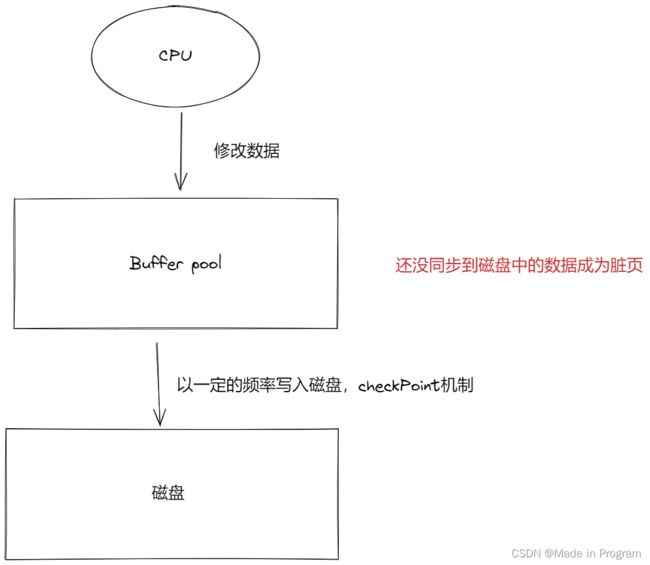
提前把修改的操作写到文件中,其实就redo log,记录了物理上的修改(比如第10号页面中偏移量为100的那个字节的值1改成了2),万一内存挂了,可以根据这个redo log来恢复数据。
特点:
- 一个事务中是不断地写日志地,插入了10万条记录,就写10W条
- 顺序写
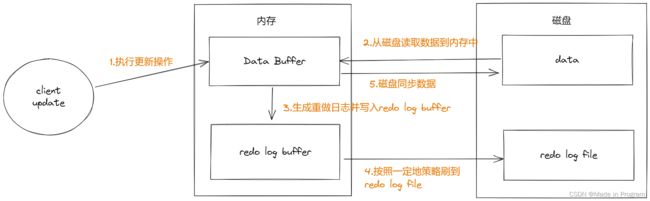
整体流程:
-
提交修改操作
-
先将原始数据读取到内存中,修改内存中地数据
-
生成重做日志,并写入redo log buffer,记录数据被修改后地值
-
当事务提交地时候,将redo log buffer 中地数据刷到redo log file 中,采用追加地方式
-
将内存中修改地数据同步到磁盘
以上的这个过程称为WAL(write ahead log) 机制
如下图所示
redol log file 位置
刷盘策略是怎么样的呢?也就是上图中的第4步。
通过参数innodb_flush_log_at_trx_commit 可以控制刷盘策略。默认是1,可以设置为0 1 2.
- 设置为1

事务提交以后就主动把redo log buffer中的缓存写入page cache,page cache刷到redo log file 中
-
设置为2
只负责写道page cache中,page cache什么时候写道redo log file中由操作系统自己决定
-
设置为0
值写入redo log buffer ,由后台线程每秒钟写道page cache
undo log
也叫做回滚日志。
一般事务执行的流程是
begin … 执行语句 … commit
在执行过程中,可能会出现一些意外,例如断电等。需要将数据恢复到begin 之前的样子。 体现了原子性,要么全部成功、要么全部失败。
undo log 是存储在 rollback segement 中的 undo log segment,在每个undo log segment 进行undo页的申请。
更新数据流程。

总结:更新数据之前写undo log 记录之前的数据,以防止回滚保证原子性,然后刷盘到redo log ,以保证持久性。
具体来说。
每行记录除了记录本身的数据意外,还有记录几个隐藏的列。
- DB_ROW_ID: 如果没有主键,会生成隐式主键
- DB_TRX_ID:事务ID
- DB_ROLL_PTR:回滚指针
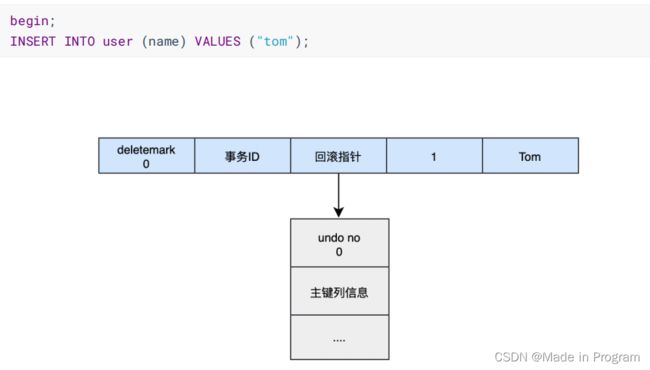
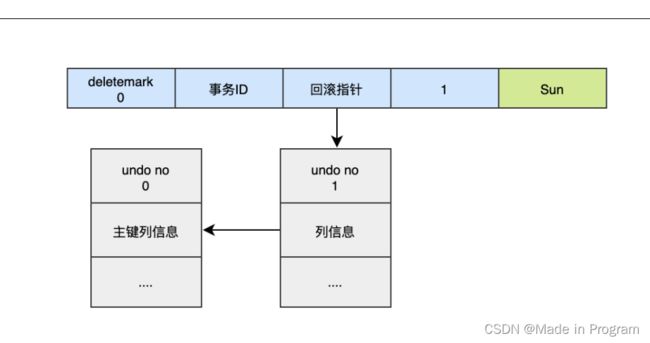
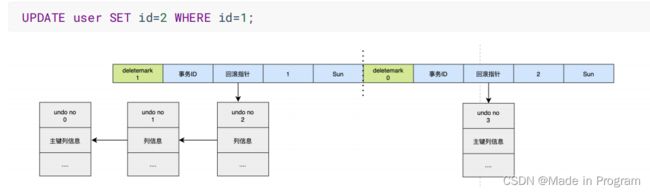
如上执行3条语句
1.insert
2.update
3.delete
如何回滚呢?
通过指针 可以想象
-
通过undo no=3的日志把id=2的数据删除
-
通过undo no=2的日志把id=1的数据的deletemark还原成0
-
通过undo no=1的日志把id=1的数据的name还原成Tom
-
通过undo no=0的日志把id=1的数据删除
undo log的删除
- 针对于insert undo log
因为insert操作的记录,只对事务本身可见,对其他事务不可见。故该undo log可以在事务提交后直接删除,不需要进行purge操作。
- 针对于update undo log
该undo log可能需要提供MVCC机制,因此不能在事务提交时就进行删除。提交时放入undo log链表,等待purge线程进行最后的删除。
binlog
Binlog日志:二进制日志,记录的是所有DML DDL的更新语句,查询语句不会记录
应用场景:
- 数据恢复
- 数据复制
binlog的三种个是 ROW、Statement、Mixed
-
ROW (也是mysql 的默认 存储格式)
仅保存哪条记录被修改了,Binlog会记录每次写操作后被操作行记录的变化。
优点:row level 的日志内容会非常清楚的记录下每一行数据修改的细节。而且不会出现某些特定情况下的存储过程,或function,以及trigger的调用和触发无法被正确复制的问题。
-
Statement
每一条会修改数据的sql 都会记录在binlog中
优点: 节省空间
缺点: 有可能造成数据不一致,例如insert语句中包含now()函数。
-
Mixed
混合模式,默认是Statement-based,如果SQL语句可能导致数据不一致,就自动切换到Row-based。
binlog 写入机制
先把日志写到binlog cache中,事务提交的时候再把binlog cache 写到binlog文件中。系统会给每个线程分配一个块内存作为binlog cache
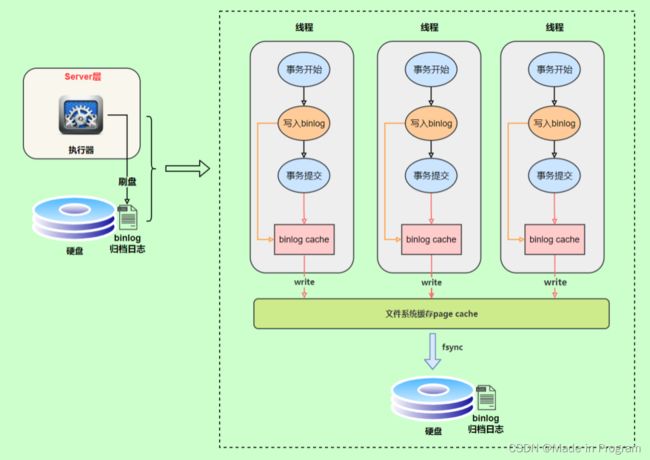
write过程是吧binlog cache中的缓存写入文件系统缓存中,交给操作系统处理,那么就会有一定的风险了,操作系统挂机了,数据不就丢失了吗?
fsync:是把操作系统中的数据刷到磁盘
这两个步骤可以通过sync_binlog控制 ,默认是0:表示每次提交事务都只write,由操作系统判断什么时候执行fsync。
为了安全起见,可以设置为 1 ,表示每次提交事务都会执行fsync,就如同redo log 刷盘流程一样。
最后还有一种折中方式,可以设置为N(N>1),表示每次提交事务都write,但累积N个事务后才fsync。
binlog和redolog对比
写入时机不同、存储得内容不同、主要得应用场景不同
-
存储内容
- redo log 是物理日志,记录的是具体的XXX数据页上做了什么修改
- binlog是逻辑日志:记录的是可以理解为sql 语句
-
写入时机
redolog是在事务执行得过程中不断写入得
binlog是在事务提交以后才写入的
-
应用场景
- redolog 应用于数据的恢复(主机)
- binlog 应用于主从备份,从机会从主机拉取binlog日志进行同步
两阶段提交
由以上原理图可得 binlog是在事务提交得时候才会写入缓存 再写入磁盘。
但是redo log不是,redo log 在事务执行得过程中可以不断写入,这两种日志
写入时机不同可能会导致redo log 与 binlog 两份日志之间的逻辑不一致,会出现什么问题?
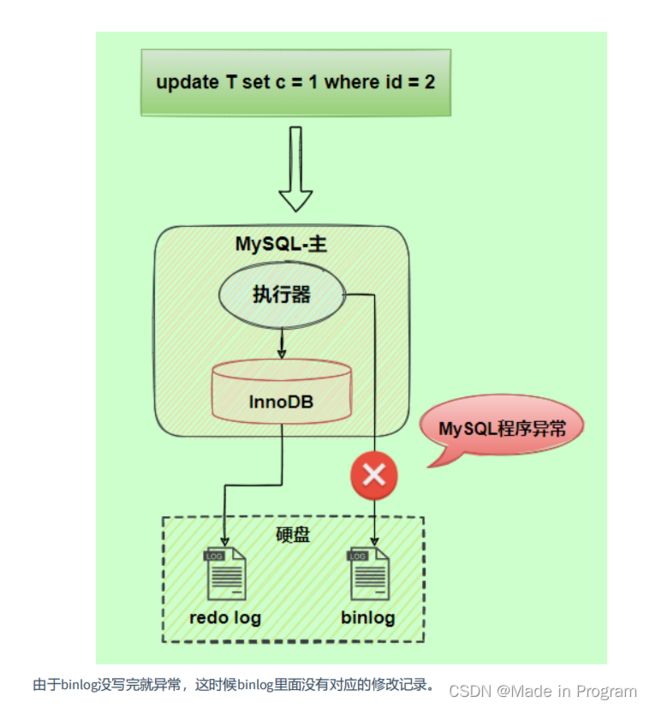
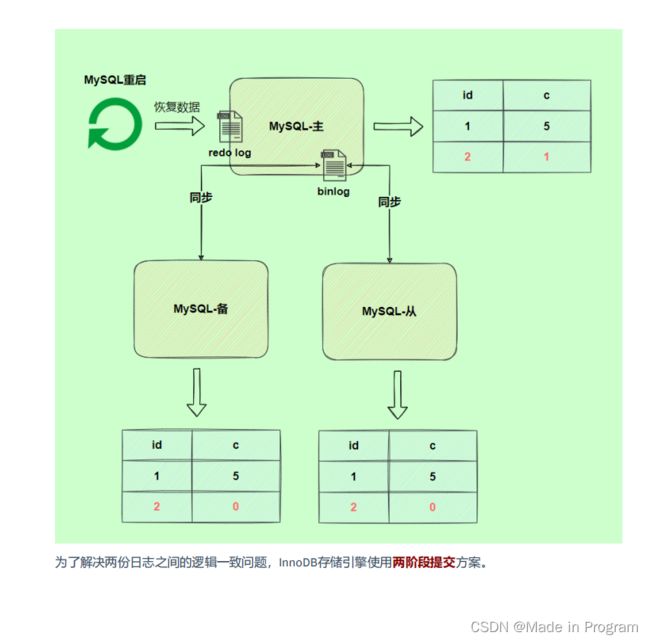
图中 从机的数据和主机的数据不一致了。
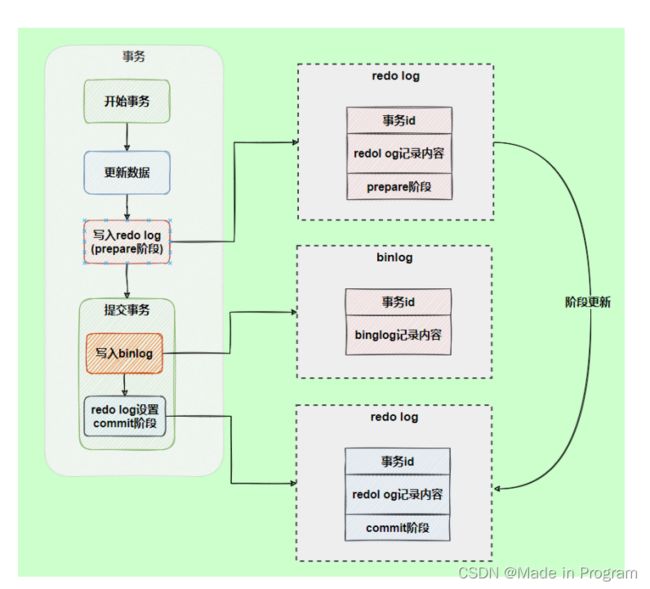
解决方案: 两阶段提交
写入bin log之前 写入redo log 这个阶段称之为prepare阶段
写入bin log 之后再写入redolog 这个阶段称之为commit阶段
是怎么解决的?再次拿出刚刚提出的问题,binlog写入磁盘的时候操作系统宕机了。如下图。
1.先判断是否是commit阶段了,不是则判断是否存在对应的binlog,不存在就回滚事务。这样就保证了 主机也是提交事务之前的记录
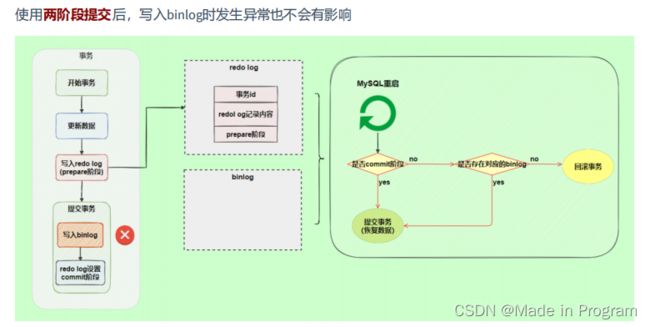
2.如果已经写入了binlog日志了,那么就提交事务
直白的说,就是多了一个判断的过程,判断事务是否已经写入binlog 了,如果写入的话,就继续提交事务,如果没有写入就回滚事务。
主从复制的具体步骤
如下图所示

涉及到三个线程:
-
Master上的二进制日志转储线程:将主库上的Binary log发送到从机上的 I/O线程,这期间会加锁
-
从库I/O线程:向master发送同步请求,将binlog写入slave中的Relay log(中继日志)
-
从库sql线程:执行中继日志中的时间,将从库中的数据和主库保持同步
存在一个延时问题:导致数据的不一致性:
主从延时问题表现:
进行主从同步的内容是二进制日志,它是一个文件,在进行网络传输的过程中就一定会存在主从延迟(比如 500ms),这样就可能造成用户在从库上读取的数据不是最新的数据,也就是主从同步中的数据不一致性问题。
原因:
在网络正常的时候,日志从主库传给从库所需的时间是很短的,即T2-T1的值是非常小的。即,网络正常
情况下,主备延迟的主要来源是备库接收完binlog和执行完这个事务之间的时间差。
**主备延迟最直接的表现是,从库消费中继日志(relay log)的速度,比主库生产binlog的速度要慢。**造成原因:
1、从库的机器性能比主库要差
2、从库的压力大
3、大事务的执行
减少主从延迟
若想要减少主从延迟的时间,可以采取下面的办法:
-
降低多线程大事务并发的概率,优化业务逻辑
-
优化SQL,避免慢SQL, 减少批量操作 ,建议写脚本以update-sleep这样的形式完成。
-
提高从库机器的配置 ,减少主库写binlog和从库读binlog的效率差。
-
尽量采用 短的链路 ,也就是主库和从库服务器的距离尽量要短,提升端口带宽,减少binlog传输
的网络延时。
- 实时性要求的业务读强制走主库,从库只做灾备,备份。
如何解决一致性问题?
读写分离情况下,解决主从同步中数据不一致的问题, 就是解决主从之间 数据复制方式 的问题,如果按
照数据一致性 从弱到强 来进行划分,有以下 3 种复制方式。
- 异步复制
- 半同步复制
- 组复制