[深度学习论文笔记]Hybrid Window Attention Based Transformer Architecture for Brain Tumor Segmentation
Hybrid Window Attention Based Transformer Architecture for Brain Tumor Segmentation
基于混合窗口注意力的Transformer结构脑肿瘤分割
Author: Himashi Peiris, Munawar Hayat, Zhaolin Chen, Gary Egan, Mehrtash Harandi
Unit: Monash University
Submitted 15 September, 2022;
originally announced September 2022.
论文:https://arxiv.org/abs/2209.07704
代码:https://github.com/himashi92/vizviva_fets_2022
1.问题动机
准确的分割是临床诊断和制定治疗计划的前提。在科学研究中迫切需要实现一个广义的深度学习模型,该模型可以为来自各种机构分布的患者数据产生可靠的预测或具有精确感兴趣区域的分割掩码。传统上,自动分割工具是使用基于人工特征工程的学习方法实现的,如决策森林、条件随机场(CRF)。然而,随着近年来卷积神经网络(CNN)的发展和计算资源(如图形处理单元(GPU))的改进,用于肿瘤分割的深度学习模型在医疗AI领域得到了许多研究者的广泛开发和研究。对于这些方法中的大多数,U-Net和3D U-Net是基础架构。这些u型架构可以在保持上下文线索的同时提取局部特征。然而,这些基于CNN的方法的不足之处在于它们无法在训练过程中提取长距离依赖关系。过于关注局部线索而不是全局线索有时会导致提取不确定或不精确的信息,从而降低分割性能和可靠性。
Transformer架构最初是为了解决上述inductive bias而提出的。这些Transformer模型被设计用于提取序列到序列任务的远程依赖关系。受Transformer用于体积脑肿瘤分割的最新进展的启发,以及它在基于卷积神经网络(CNN)的模型上的独特能力,作者提出了一种u形编码器-解码器神经网络,该网络在解码过程中采用双向窗口方法进行精细细节提取。视觉Transformer通过保持灵活的接受域,在提取远程依赖关系方面显示出突破性的性能改进。此外,基于Transformer的深度学习模型所显示的对数据损坏和遮挡的更好鲁棒性,无疑是神经网络设计中所要求的最好的东西。考虑到Transformer网络的这些方面,在作者提出的方法中,使用了两种流行的基于窗口的注意机制,即基于十字形窗口注意的Swin Transformer块和基于移位窗口注意的Swin Transformer块来构造u形体积Transformer(CR-Swin2-VT)。在CR-Swin2-VT模型中,在编码器侧并行构建Swin Transformer模块和CSWin Transformer模块以精确捕获体素信息,而在解码器侧仅使用Swin Transformer模块。
总而言之,作者的主要贡献是:
(1)提出了一种体积Transformer架构,可以将医学扫描作为整体处理;
(2)设计了两种基于窗口关注机制的编码路径,分别捕捉医疗卷的局部和全局特征;
(3)在fts Challenge 2022数据集上对脑肿瘤分割任务进行了大量实验。
2.提出的方法
![[深度学习论文笔记]Hybrid Window Attention Based Transformer Architecture for Brain Tumor Segmentation_第1张图片](http://img.e-com-net.com/image/info8/4ce7cbccbc4b4426aa45d9e360919a6b.jpg)
具体的网络细节,大家可以在原论文中找到,论文中解释的很详细,包括自注意力计算方法:
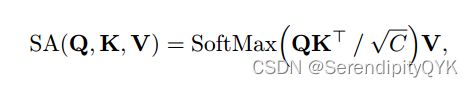
改进后的方法,主要是在SA计算中加入了典型的位置编码方法。这允许在模型训练过程中添加反向位置信息。其中最流行的方法之一是相对位置编码(RPE),它被用于著名的作品Swin Transformer。
具有RPE的SA定义为:
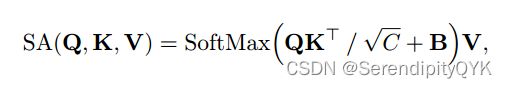
还有加入局部增强位置编码(local -enhanced Positional Encoding, LePE)的SA:

3.总体架构
![[深度学习论文笔记]Hybrid Window Attention Based Transformer Architecture for Brain Tumor Segmentation_第2张图片](http://img.e-com-net.com/image/info8/5d3d45c1db3549ffa485ba5e169eab2f.jpg)
(a)VT-UNet架构
(b)为融合块(Fusion Block)的结构,该结构聚合了网络解码器侧由CSwin Transformer块和Swin Transformer块生成的两个注意力图
©为CR-Swin2-VT模型的训练过程,其中,X、Y、radv、P分别为输入数据(原始患者数据)、ground _真值分割掩码、输入数据加扰和分割网络生成的预测。
CR-Swin2-VT的整体架构如图1所示。该模型的输入是一个尺寸为D × H × W × C的三维体,输出是一个尺寸为D × H × W × K的三维体。这里,K表示类的数量。(由三部分组成: CR-Swin2-VT Encoder、CR Swin2-VT Bottleneck 、 CR-Swin2-VT Decoder)
①CR-Swin2-VT Encoder
CR-Swin2-VT编码器由结合线性嵌入层的3D Patch Partitioning层、3D CSwin Transformer SA SWMSA块、3D Swin Transformer块、Fusion块和3D Patch merge层组成。
在3D patch partitioning过程中,输入的序列被分割成不重叠的体素3D patch,并作为一组tokens馈送到下一个线性嵌入层。这里作者使用了一个分区内核P × M × M,其中P = 2, M = 4,这就得到了一个2 × 4 × 4的patch Tpartitioning内核。在线性嵌入期间,结果标记被映射到C维向量(嵌入维度)。在实验中,作者设置C = 48。然后,这些token通过两个连续的3D Swin Transformer块,它们由(1)窗口多头SA,(2)移位窗口多头SA和两个连续的CSwin Transformer块组成,这些块由十字形窗口SA组成。
更多有关Fusion Block以及其他模块信息,可以参考论文或者代码。
②CR-Swin2-VT Decoder
CR-Swin2-VT解码器从连续的VT-W-MSA-Blks以及3Dpatch扩展层和最后的分类器开始,以生成最终的体积分割掩码。
CR-Swin2-VT模型的目标是分割体积医学图像,它的模型学习过程更像图像分割。
③损失函数
在CR-Swin2-VT模型的训练过程中,利用梯度的加权和来更新模型,并将增值过程中引入的损失作为全目标函数的正则化项
![[深度学习论文笔记]Hybrid Window Attention Based Transformer Architecture for Brain Tumor Segmentation_第3张图片](http://img.e-com-net.com/image/info8/cf674ac4821b4f31877cc1bc109c9b2e.jpg)
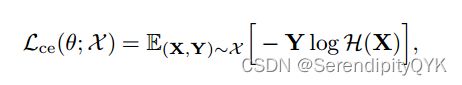
![[深度学习论文笔记]Hybrid Window Attention Based Transformer Architecture for Brain Tumor Segmentation_第4张图片](http://img.e-com-net.com/image/info8/820dad3d981849f79185d1e69e88ea25.jpg)

是不是看着很复杂,结合代码多看几遍就明白了,作者写的还是挺清晰的
4.实现结果
数据集就不多做描述了(FeTS Challenge 2022),由于患者在检查过程中的运动、采集设备的不同制造商、图像采集过程中使用的序列和参数等各种因素,MRI体积的强度不一致。为了标准化所有的体积,在裁剪强度值之后执行最小-最大缩放。然后通过去除不必要的背景像素,将图像裁剪为128 × 128 × 128的固定patch大小。
![[深度学习论文笔记]Hybrid Window Attention Based Transformer Architecture for Brain Tumor Segmentation_第5张图片](http://img.e-com-net.com/image/info8/bc8c74ec66764ede84ef33b071f544f3.jpg)
![[深度学习论文笔记]Hybrid Window Attention Based Transformer Architecture for Brain Tumor Segmentation_第6张图片](http://img.e-com-net.com/image/info8/99665ab033814c338633f94a18dcf1dc.jpg)
5.总结
提出了一种基于Transformer的方法,该方法在编码器中采用了两种窗口策略,以提取mpMRI不同模式内部和之间的长期依赖关系。使用fts Challenge 2022数据集验证了该方法在脑肿瘤分割上的有效性,结果证明了该方法的有效性。
论文里面的参数这里就不一一解释了,有不懂的地方点个关注,评论区或者后台私信我,我们一起交流学习