【AI】深度学习——前馈神经网络——卷积神经网络
文章目录
-
- 1.2 卷积神经网络
-
- 1.2.1 卷积
-
- 一维卷积
-
- 近似微分
- 低通滤波器/高通滤波器
- 卷积变种
- 二维卷积
-
- 卷积的核心就是翻转相乘
- 卷积应用于图像处理
- 互相关
-
- 互相关代替卷积
- 卷积与互相关的交换性
- 1.2.2 卷积神经网络
-
- 卷积代替全连接
- 卷积层
-
- 特征映射
- 卷积层结构
- 参数数量
- 汇聚层(池化层)
-
- 汇聚层区域划分
- 汇聚
- 卷积神经网络的整体结构
- 1.2.3 参数学习
-
- 参数求解目标
- 卷积求导
- 误差项求解
- 池化层误差项求解
- 1.2.4 典型卷积神经网络
-
- LeNet-5
-
- C 1 C_1 C1 层是卷积层
- S 2 S_2 S2 层为汇聚层
- C 3 C_3 C3 层为卷积层
- S 4 S_4 S4 层为汇聚层
- C 5 C_5 C5 层为卷积层
- F 6 F_6 F6 层为全连接层
- 输出层
- AlexNet
-
- 第一个卷积层
- 第一个汇聚层
- 第二个卷积层
- 第二个汇聚层
- 第三个卷积层
- 第四个卷积层
- 第五个卷积层
- 第三个汇聚层
- 三个全连接层
- 输出层 Softmax
- Inception网络
-
- Inception模块
- 1 × 1 1\times 1 1×1 卷积核的作用
- Inception网络版本
- 残差网络ResNet(152层)
-
- 残差单元
- 1.2.5 非标准卷积
-
- 空洞卷积
-
- 如何增加输出单元的感受野
- "反"卷积
-
- 转置卷积
- 微步卷积
- 1.2.6 卷积神经网络应用
-
- AlphaGo
- 目标检测RCN
- 图像分割RCNN
- 光学字符识别OCR
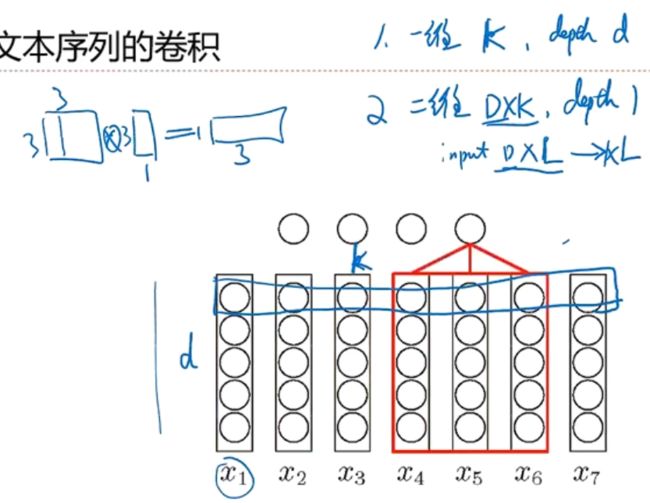
- 应用于文本
-
- Ngram特征与卷积
- 词到词向量
1.2 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN 或 ConvNet)是一种具有局部连接、权重共享等特性的深层前馈神经网络。
感受野机制:听觉、视觉等神经系统中的一些神经元,只接受其所支配的刺激区域内的信号
- 一个视觉皮层的神经元的感受野指视网膜上的特定区域,只有这个区域内的刺激才能激活该神经元
卷积神经网络
- 卷积层
- 汇聚层
- 全连接层
结构特性:
-
局部连接
与全连接的前馈神经网络相比,卷积神经网络的参数很少
-
权重共享
-
空间或时间上的次采样
1.2.1 卷积
是分析数学中的一种重要运算,在信号处理或图像处理中,经常使用一维或二维卷积
一维卷积
一维卷积常用于信号处理中,用于计算信号的延迟累积
假设一个信号发生器每个时刻 t t t 产生一个信号 x t x_t xt ,其信息的衰减率为 w k w_k wk ,在 k − 1 k-1 k−1 个时间步长后,信息变为原先的 w k w_k wk 倍

在时刻 t t t 收到的信号 y t y_t yt
y t = 1 × x t + 1 2 x t − 1 + 1 4 x t − 2 = w 1 x t + w 2 x t − 1 + w 3 x t − 2 = ∑ k = 1 3 w k x t − k + 1 \begin{aligned} y_t&=1\times x_t+\frac{1}{2}x_{t-1}+\frac{1}{4}x_{t-2}\\ &=w_1x_t+w_2x_{t-1}+w_3x_{t-2}\\ &=\sum\limits_{k=1}^3w_kx_{t-k+1} \end{aligned} yt=1×xt+21xt−1+41xt−2=w1xt+w2xt−1+w3xt−2=k=1∑3wkxt−k+1
w i w_i wi 称为滤波器或卷积核,假设滤波器的长度为 K K K ,它和一个信号序列 x 1 , x 2 , ⋯ x_1,x_2,\cdots x1,x2,⋯ 的卷积为
y t = ∑ k = 1 K w k x t − k + 1 y_t=\sum\limits_{k=1}^Kw_kx_{t-k+1} yt=k=1∑Kwkxt−k+1
- 一般情况下,滤波器的长度 K K K 远小于信号序列 x x x 的长度
信号序列 x x x 和滤波器 w w w 的卷积定义为
y = w ∗ x y=w*x y=w∗x
近似微分
当令滤波器 w = [ 1 2 , 0 , − 1 2 ] w=\left[\frac{1}{2},0,-\frac{1}{2}\right] w=[21,0,−21] 时,可以近似信号序列的一阶微分
x ′ ( t ) = x ( t + 1 ) − x ( t − 1 ) 2 x'(t)=\frac{x(t+1)-x(t-1)}{2} x′(t)=2x(t+1)−x(t−1)
- f ′ ( x ) = lim ε → 0 f ( x + ε ) − f ( x − ε ) 2 ε f'(x)=\lim\limits_{\varepsilon\rightarrow 0}\frac{f(x+\varepsilon)-f(x-\varepsilon)}{2\varepsilon} f′(x)=ε→0lim2εf(x+ε)−f(x−ε)
二阶微分,即当滤波器为 w = [ 1 , − 2 , 1 ] w=[1,-2,1] w=[1,−2,1] 时,可近似实现对信号序列的二阶微分
x ′ ′ ( t ) = x ′ ( t ) − x ′ ( t − 1 ) t − ( t − 1 ) = x ′ ( t ) − x ′ ( t − 1 ) = x ( t + 1 ) − x ( t ) ( t + 1 ) − t − x ( t ) − x ( t − 1 ) t − ( t − 1 ) = x ( t + 1 ) − 2 x ( t ) + x ( t − 1 ) \begin{aligned} x''(t)&=\frac{x'(t)-x'(t-1)}{t-(t-1)}=x'(t)-x'(t-1)\\ &=\frac{x(t+1)-x(t)}{(t+1)-t}-\frac{x(t)-x(t-1)}{t-(t-1)}\\ &=x(t+1)-2x(t)+x(t-1) \end{aligned} x′′(t)=t−(t−1)x′(t)−x′(t−1)=x′(t)−x′(t−1)=(t+1)−tx(t+1)−x(t)−t−(t−1)x(t)−x(t−1)=x(t+1)−2x(t)+x(t−1)
低通滤波器/高通滤波器

卷积变种
在卷积的标准定义基础上,还可以引入卷积核的 滑动步长 (stride) 和 零填充(zero padding) 来增加卷积的多样性
步长S:指卷积核在滑动时的时间间隔
- 增加步长,减少输出长度
零填充:在输入向量的两端补零
- 增加长度

假设卷积层的输入神经元个数为 M M M ,卷积大小为 K K K ,步长为 S S S ,在输入两端分别补 P P P 个零,那么该卷积的神经元数量为 M − K + 2 P S + 1 \frac{M-K+2P}{S}+1 SM−K+2P+1
- 窄卷积: S = 1 S=1 S=1 , P = 0 P=0 P=0 ,卷积后输出长度为 M − K + 1 M-K+1 M−K+1
- 等宽卷积: S = 1 S=1 S=1 , P = K − 1 2 P=\frac{K-1}{2} P=2K−1 ,卷积后输出长度为 M M M
- 宽卷积: S = 1 S=1 S=1, P = K − 1 P=K-1 P=K−1,卷积后输出长度为 M + K − 1 M+K-1 M+K−1
有K个窗格的滑动窗口,在一个时间间隔后滑动S个数据
二维卷积
图像是二维结构,需要将一维卷积进行扩展
给定一个图像 X ∈ R M × N X\in \R^{M\times N} X∈RM×N 和一个滤波器 W ∈ R U × V W\in\R^{U\times V} W∈RU×V ,一般 U ≪ M , V ≪ N U\ll M,V\ll N U≪M,V≪N ,其卷积为
y i j = ∑ u = 1 U ∑ v = 1 V w u v X i − u + 1 , j − v + 1 , i ∈ [ U , M − U + 1 ] , j ∈ [ V , N − V + 1 ] y_{ij}=\sum\limits_{u=1}^U\sum\limits_{v=1}^Vw_{uv}X_{i-u+1,j-v+1}\quad,i\in [U,M-U+1],j\in [V,N-V+1] yij=u=1∑Uv=1∑VwuvXi−u+1,j−v+1,i∈[U,M−U+1],j∈[V,N−V+1]

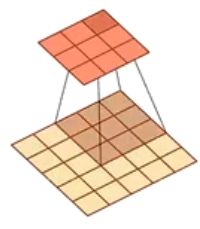
y 35 = ∑ u = 1 3 ∑ v = 1 3 w u v X 3 − u + 1 , 5 − v + 1 = w 11 × X 35 + w 33 × X 13 = 1 × 0 + ( − 1 ) × 1 = − 1 \begin{aligned} y_{35}&=\sum\limits_{u=1}^3\sum\limits_{v=1}^3w_{uv}X_{3-u+1,5-v+1}=w_{11}\times X_{35}+w_{33}\times X_{13}\\ &=1\times0+(-1)\times 1=-1 \end{aligned} y35=u=1∑3v=1∑3wuvX3−u+1,5−v+1=w11×X35+w33×X13=1×0+(−1)×1=−1
卷积的核心就是翻转相乘

W ∗ X = c o n v o l u t i o n i ∗ A + h ∗ B + g ∗ C + f ∗ D + e ∗ E + d ∗ F + c ∗ G + b ∗ H + a ∗ I W*X\xlongequal{convolution} i*A+h*B+g*C+f*D+e*E+d*F+c*G+b*H+a*I W∗Xconvolutioni∗A+h∗B+g∗C+f∗D+e∗E+d∗F+c∗G+b∗H+a∗I
-
上下翻转,左右翻转
- 相当于在一个平面内,以 e e e 为中心,旋转 18 0 ∘ 180^{\circ} 180∘
-
再逐项相乘并求和
卷积应用于图像处理
卷积的功能是在一个图像(或某种特征)上滑动一个卷积核(滤波器),通过卷积操作得到一组新的特征——一种特征提取的方法
- 经过卷积操作后的结果称为 特征映射
常见滤波器
-
均值滤波 将当前位置的像素值设为滤波窗口中所有像素的平均值 w u v = 1 U V w_{uv}=\frac{1}{UV} wuv=UV1
-
高斯滤波器 :用于对图像平滑去噪

-
边缘滤波器,提取边缘特征

互相关
互相关是衡量两个序列相关性的函数,通常用滑动窗口的点积计算来实现
一个图像 X ∈ R M × N X\in \R^{M\times N} X∈RM×N 和卷积核 W ∈ R U × V W\in \R^{U\times V} W∈RU×V ,互相关为
y i j = ∑ u = 1 U ∑ v = 1 V w u v X i + u − 1 , j + v − 1 y_{ij}=\sum\limits_{u=1}^U\sum\limits_{v=1}^Vw_{uv}X_{i+u-1,j+v-1} yij=u=1∑Uv=1∑VwuvXi+u−1,j+v−1
互相关——不翻转核的卷积
- 与卷积的区别在于卷积核是否翻转
Y = W ⊗ X = r o t 180 ( W ) ∗ X \begin{aligned} Y&=W\otimes X\\ &=rot180(W)*X \end{aligned} Y=W⊗X=rot180(W)∗X
互相关代替卷积
在计算卷积过程中,需要进行卷积核翻转
实际实现中,一般会以互相关操作来代替卷积
在神经网络中,卷积的目的就是进行特征抽取,卷积核是否进行翻转和其特征抽取能力无关
- 当卷积核是可学习的参数时,卷积和互相关在能力上是等价的
卷积与互相关的交换性
x ∗ y = y ∗ x x*y=y*x x∗y=y∗x
二维图的宽卷积具有交换性
- 二维宽卷积:二维图像 X ∈ R M × N X\in \R^{M\times N} X∈RM×N 和 二维卷积核 W ∈ R U × V W\in \R^{U\times V} W∈RU×V ,对 X X X 进行零填充,两端各补 U − 1 U-1 U−1 个零和 V − 1 V-1 V−1 个零,得到全填充的图像 X ~ ∈ R ( M + 2 U − 2 ) × ( N + 2 V − 2 ) \tilde{X}\in \R^{(M+2U-2)\times (N+2V-2)} X~∈R(M+2U−2)×(N+2V−2)
图像 X X X 和卷积核 W W W 的宽卷积定义为
W ∗ ~ X = Δ W ∗ X ~ W\tilde{*}X\overset{\Delta}{=}W* \tilde{X} W∗~X=ΔW∗X~
当输入信息和卷积核有固定长度时,他们的宽卷积具有交换性,
W ∗ X ~ = X ~ ∗ W ⟺ W ∗ ~ X = X ∗ ~ W W*\tilde{X}=\tilde{X}*W\iff W\tilde{*}X=X\tilde{*}W W∗X~=X~∗W⟺W∗~X=X∗~W
由于卷积与互相关运算的区别只有是否翻转卷积核,相应的宽互相关也有交换性
r o t 180 ( W ) ⊗ ~ X = r o t 180 ( X ) ⊗ ~ W rot180(W)\tilde{\otimes}X=rot180(X)\tilde{\otimes}W rot180(W)⊗~X=rot180(X)⊗~W
1.2.2 卷积神经网络
卷积代替全连接
在全连接网络中,第 l l l 层有 M l M_l Ml 个神经元,第 l − 1 l-1 l−1 层有 M l − 1 M_{l-1} Ml−1 个神经元,连接边有 M l × M l − 1 M_l\times M_{l-1} Ml×Ml−1 ,即权重矩阵 W ∈ R M l × M l − 1 W\in \R^{M_l\times M_{l-1}} W∈RMl×Ml−1 ,当 M l M_l Ml 和 M l − 1 M_{l-1} Ml−1 都很大时,权重矩阵的参数会很多,训练的效率会非常低

采用卷积代替全连接,第 l l l 层的净输入 z ( l ) z^{(l)} z(l) 为第 l − 1 l-1 l−1 层活性值 a ( l − 1 ) a^{(l-1)} a(l−1) 和卷积核
z ( l ) = w ( l ) ⊗ a ( l − 1 ) + b ( l ) z^{(l)}=w^{(l)}\otimes a^{(l-1)}+b^{(l)} z(l)=w(l)⊗a(l−1)+b(l)
局部连接:在卷积层 (第 l l l 层) 中的每一个神经元只与前一层 (第 l − 1 l-1 l−1 层) 中的某个局部窗口内的神经元相连,构成一个局部连接网络。
- 卷积层的数量大大减少,由 M l × M l − 1 M_l\times M_{l-1} Ml×Ml−1 个连接变为 M l × K M_l\times K Ml×K 个连接, K K K 为卷积核大小
权重共享:作为参数的卷积核 w ( l ) w^{(l)} w(l) 对于第 l l l 层的所有神经元都是相同的。可以为一个卷积核只捕捉输入数据中的一种特定的局部特征,若提取不同特征,需要使用不同的卷积核
由于局部连接与权重共享特性,卷积层的参数只有一个 K K K 维的权重 w ( l ) w^{(l)} w(l) 和一维偏置 b ( l ) b^{(l)} b(l) ,共 K + 1 K+1 K+1 个参数
参数数量与神经元数量无关,第 l l l 层神经元的个数满足 M l = M l − 1 − K + 1 M_l=M_{l-1}-K+1 Ml=Ml−1−K+1
卷积层
卷积层的作用是提取一个局部区域的特征,不同的卷积核相当于不同的特征提取器
特征映射
特征映射 :一幅图像在经过卷积提取到的特征,每个特征映射可以作为一类抽取的图像特征
- 可在每一层使用多个不同的卷积核得到不同类的特征映射
在输入层,特征映射就是图像本身
- 灰度图像,只有一个特征映射,输入层的深度 D = 1 D=1 D=1
- 彩色图像,有RGB三个颜色通道的特征映射,输入层的深度 D = 3 D=3 D=3
通常将图像神经元组织为三维结构的神经层,其大小为 高度 M × 宽度 N × 深度 D 高度M\times 宽度 N\times 深度D 高度M×宽度N×深度D ,由 D D D 个 M × N M\times N M×N 大小的特征映射构成
卷积层结构
-
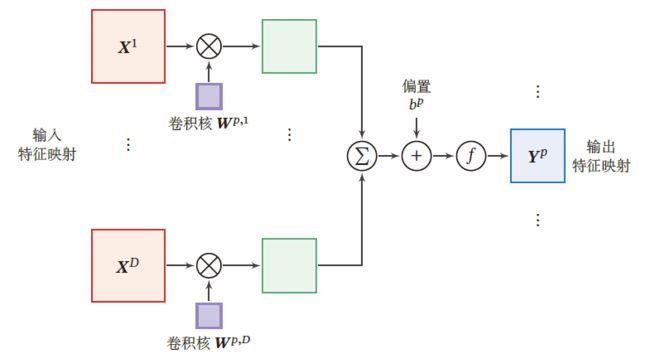
输入特征映射组: X ∈ R M × N × D \mathcal{X} \in \R^{M\times N\times D} X∈RM×N×D 为三维张量,每个切片矩阵 X d ∈ R M × N , 1 ≤ d ≤ D X^d\in \R^{M\times N},1\le d\le D Xd∈RM×N,1≤d≤D 为一个输入特征的映射
-
输出特征映射组: Y ∈ R M ′ × N ′ × P \mathcal{Y}\in \R^{M'\times N'\times P} Y∈RM′×N′×P 为三维张量,每个切片矩阵 Y p ∈ R M ′ × N , 1 ≤ p ≤ P Y^p\in \R^{M'\times N},1\le p\le P Yp∈RM′×N,1≤p≤P
输入层与输出层的特征映射是全连接关系

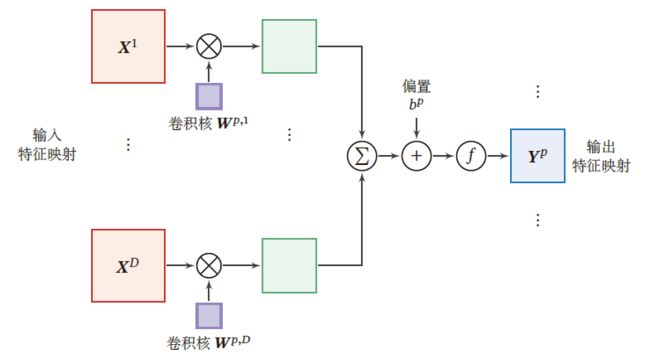
即输出层的一个特征映射,由下式得出
Z p = ∑ d = 1 D W p , d ⊗ X d + b p = W p ⊗ X + b p Y p = f ( Z p ) \begin{aligned} Z^p&=\sum\limits_{d=1}^DW^{p,d}\otimes X^{d}+b^p=W^p\otimes X+b^p\\ Y^p&=f(Z^p) \end{aligned} ZpYp=d=1∑DWp,d⊗Xd+bp=Wp⊗X+bp=f(Zp)- 其中, f ( ⋅ ) f(\cdot) f(⋅) 为非线性函数
-
卷积核: W ∈ R U × V × P × D \mathcal{W}\in \R^{U\times V\times P\times D} W∈RU×V×P×D 为四维张量,其中每个切片矩阵 W p , d ∈ R U × V W^{p,d}\in \R^{U\times V} Wp,d∈RU×V 为一个二维卷积核, 1 ≤ p ≤ P , 1 ≤ d ≤ D 1\le p\le P,1\le d\le D 1≤p≤P,1≤d≤D
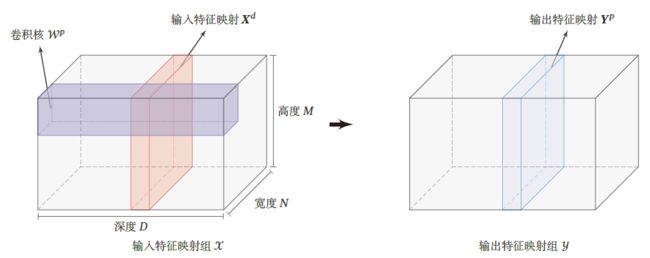
相当于:输出 Y p Y^p Yp 需要卷积核 W p W^p Wp 的 D D D 个分量逐个与 D D D 个输入 X d X^d Xd 卷积
- 图上画的是一次卷积过程,实际上要得到蓝色的输出矩阵需要 D D D 次卷积运算,所以输入特征应该是D个粉矩阵才对,图有点问题
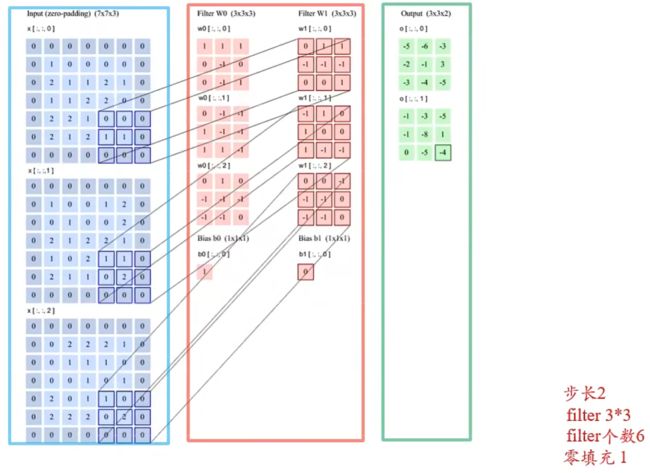
参数数量
每个输出特征映射都需要 D D D 个卷积核以及一个偏置,假设每个卷积核大小为 U × V U\times V U×V ,共需要 P × D × ( U × V ) + P P\times D\times(U\times V)+P P×D×(U×V)+P 个参数
汇聚层(池化层)
卷积层可以显著减少网络中的连接数,但对于输出层特征映射组中神经元数量的减少很少
- 一维卷积, M l = M l − 1 − ( K − 1 ) M_l=M_{l-1}-(K-1) Ml=Ml−1−(K−1) ,即只能减少 K − 1 K-1 K−1 个神经元, K K K 为卷积长度
- 二维卷积,卷积后有 [ M − ( U − 1 ) ] × [ N − ( V − 1 ) ] [M-(U-1)]\times[N-(V-1)] [M−(U−1)]×[N−(V−1)] 个神经元
汇聚层的作用就是减少神经元数量
汇聚层区域划分
假设汇聚层的输入特征映射组为 X ∈ R M ′ × N ′ × D \mathcal{X}\in\R^{M'\times N'\times D} X∈RM′×N′×D ,对于其中每一个特征映射 X d ∈ R M ′ × N ′ , 1 ≤ d ≤ D X^d\in \R^{M'\times N'},1\le d\le D Xd∈RM′×N′,1≤d≤D ,将其划分为多个小区域 R m , n d , 1 ≤ m ≤ M ′ , 1 ≤ n ≤ N ′ R_{m,n}^d,1\le m\le M',1\le n\le N' Rm,nd,1≤m≤M′,1≤n≤N′ ,这些区域可以重叠,也可以不重叠
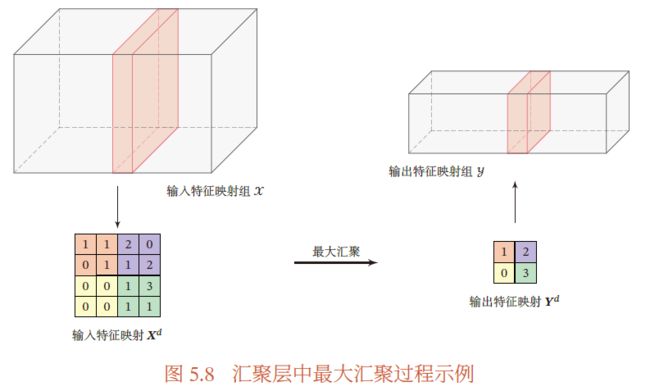
汇聚
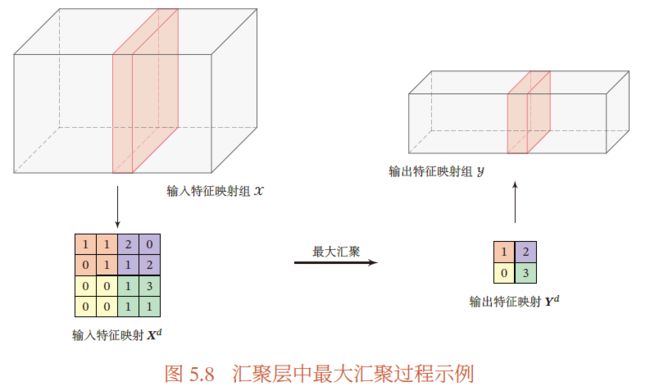
汇聚 指对每个区域进行下采样得到一个值,作为这个区域的概括
汇聚层也叫子采样层,其作用是进行特征选择,降低特征数量,从而减少参数数量
-
最大汇聚:对于一个区域 R m , n d R_{m,n}^d Rm,nd ,选择这个区域内所有神经元的最大活性值作为这个区域的表示
y m , n d = max i ∈ R m , n d x i y_{m,n}^d=\max\limits_{i\in R_{m,n}^d}x_i ym,nd=i∈Rm,ndmaxxi
-
平均汇聚:取区域内所有神经元活性值的平均值,即
y m , n d = 1 ∣ R m , n d ∣ ∑ i ∈ R m , n d x i y_{m,n}^d=\frac{1}{\vert R^d_{m,n}\vert}\sum\limits_{i\in R^d_{m,n}}x_i ym,nd=∣Rm,nd∣1i∈Rm,nd∑xi
汇聚层输出特征映射
Y d = { y m , n d } , 1 ≤ m ≤ M ′ , 1 ≤ n ≤ N ′ Y^d=\{y_{m,n}^d\},1\le m\le M',1\le n\le N' Yd={ym,nd},1≤m≤M′,1≤n≤N′
目前,主流的卷积网络仅包含 下采样 操作,但在一些早期卷积网络(LeNet-5),有时也会在汇聚层使用非线性激活函数,如
Y ′ d = f ( w d Y d + b d ) Y^{'d}=f(w^dY^d+b^d) Y′d=f(wdYd+bd)
典型的汇聚层将每个特征映射划分为 2 × 2 2\times 2 2×2 大小的不重叠区域,然后使用最大汇聚方式采样
汇聚层可以看做一个特殊的卷积层,卷积核大小为 K × K K\times K K×K ,步长为 S × S S\times S S×S ,卷积核为 m a x max max 函数或 m e a n mean mean 函数
过大的采样区域会造成神经元数量减少,也会造成较多的信息损失
卷积神经网络的整体结构
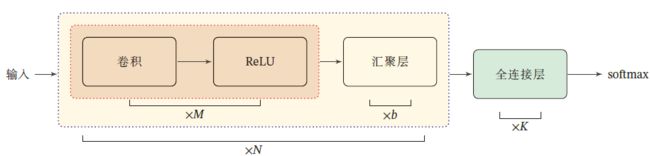
一个 卷积块 为连续 M M M 个卷积层和 b b b 个汇聚层组成( m 为 2 ∼ 5 m为2\sim 5 m为2∼5, b ∈ { 0 , 1 } b\in\{0,1\} b∈{0,1})
一个卷积网络中可以堆叠 N N N 个连续的卷积块,然后接 K K K 个全连接层
典型结构:
- 小卷积,大深度
- 趋向于全卷积:由于卷积操作越来越灵活(不同的步长),汇聚层的作用正在变小
1.2.3 参数学习
在卷积神经网络中,主要有两种不同功能的神经层:卷积层和汇聚层。参数为卷积核及偏置,只需要计算卷积层中参数的梯度
参数求解目标
若第 l l l 层卷积层,第 l − 1 l-1 l−1 层的输入特征映射为 X ( l − 1 ) ∈ R M × N × D \mathcal{X}^{(l-1)}\in \R^{M\times N\times D} X(l−1)∈RM×N×D ,通过卷积计算得到第 l l l 层的特征映射净输入 Z ( l ) ∈ R M ′ × N ′ × P Z^{(l)}\in \R^{M'\times N'\times P} Z(l)∈RM′×N′×P ,第 l l l 层的第 p p p 个特征映射净输入
Z ( l , p ) = ∑ d = 1 D W ( l , p , d ) ⊗ X ( l − 1 , d ) + b ( l , p ) Y ( l , p ) = f ( Z ( l , p ) ) \begin{aligned} Z^{(l,p)}&=\sum\limits_{d=1}^D W^{(l,p,d)}\otimes X^{(l-1,d)}+b^{(l,p)}\\ Y^{(l,p)}&=f(Z^{(l,p)}) \end{aligned} Z(l,p)Y(l,p)=d=1∑DW(l,p,d)⊗X(l−1,d)+b(l,p)=f(Z(l,p))
第 l l l 层共有 P × D P\times D P×D 个卷积核和 P P P 个偏置,可以通过链式法则计算梯度
采用交叉熵损失函数
L ( Y ( l , p ) , Y ^ ( l , p ) ) = − Y ( l , p ) log Y ^ ( l , p ) \mathcal{L}(Y^{(l,p)},\hat{Y}^{(l,p)})=-Y^{(l,p)}\log \hat{Y}^{(l,p)} L(Y(l,p),Y^(l,p))=−Y(l,p)logY^(l,p)
若有 N N N 个训练数据,则结构风险函数为
R ( W ( l , p , d ) , b ( l , p ) ) = 1 N ∑ i = 1 N L ( Y i ( l , p ) , Y ^ i ( l , p ) ) + 1 2 λ ∥ W ( l , p , d ) ∥ F 2 \mathcal{R}(W^{(l,p,d)},b^{(l,p)})=\frac{1}{N}\sum\limits_{i=1}^N\mathcal{L}(Y_i^{(l,p)},\hat{Y}_i^{(l,p)})+\frac{1}{2}\lambda\Vert W^{(l,p,d)}\Vert_F^2 R(W(l,p,d),b(l,p))=N1i=1∑NL(Yi(l,p),Y^i(l,p))+21λ∥W(l,p,d)∥F2
与全连接前馈神经网络类似,参数学习核心为梯度的学习,即求 ∂ L ∂ W ( l , p , d ) \frac{\partial \mathcal{L}}{\partial W^{(l,p,d)}} ∂W(l,p,d)∂L 与 ∂ L ∂ b ( l , p ) \frac{\partial \mathcal{L}}{\partial b^{(l,p)}} ∂b(l,p)∂L
W ( l , p , d ) ← W ( l , p , d ) − α ∂ R ( W ( l , p , d ) , b ( l , p ) ) ∂ W ( l , p , d ) ← W ( l , p , d ) − α ( 1 N ∑ i = 1 N ∂ L ( Y i ( l , p ) , Y ^ i ( l , p ) ) ∂ W ( l , p , d ) + λ W ( l , p , d ) ) b ( l , p ) ← b ( l , p ) − α ∂ R ( W ( l , p , d ) , b ( l , p ) ) ∂ b ( l , p ) ← b ( l , p ) − α ( 1 N ∑ i = 1 N ∂ L ( Y i ( l , p ) , Y ^ i ( l , p ) ) ∂ b ( l , p ) ) \begin{aligned} W^{(l,p,d)}&\leftarrow W^{(l,p,d)}-\alpha\frac{\partial \mathcal{R}(W^{(l,p,d)},b^{(l,p)})}{\partial W^{(l,p,d)}}\\ &\leftarrow W^{(l,p,d)}-\alpha\left(\frac{1}{N}\sum\limits_{i=1}^N\frac{\partial \mathcal{L}(Y_i^{(l,p)},\hat{Y}_i^{(l,p)})}{\partial W^{(l,p,d)}}+\lambda W^{(l,p,d)}\right)\\ b^{(l,p)}&\leftarrow b^{(l,p)}-\alpha\frac{\partial \mathcal{R}(W^{(l,p,d)},b^{(l,p)})}{\partial b^{(l,p)}}\\ &\leftarrow b^{(l,p)}-\alpha\left(\frac{1}{N}\sum\limits_{i=1}^N\frac{\partial \mathcal{L}(Y_i^{(l,p)},\hat{Y}_i^{(l,p)})}{\partial b^{(l,p)}}\right) \end{aligned} W(l,p,d)b(l,p)←W(l,p,d)−α∂W(l,p,d)∂R(W(l,p,d),b(l,p))←W(l,p,d)−α(N1i=1∑N∂W(l,p,d)∂L(Yi(l,p),Y^i(l,p))+λW(l,p,d))←b(l,p)−α∂b(l,p)∂R(W(l,p,d),b(l,p))←b(l,p)−α(N1i=1∑N∂b(l,p)∂L(Yi(l,p),Y^i(l,p)))
卷积求导
假设 Z = W ⊗ X Z=W\otimes X Z=W⊗X ,其中 X ∈ R M × N X\in \R^{M\times N} X∈RM×N , W ∈ R U × V W\in \R^{U\times V} W∈RU×V , Z ∈ R ( M − U + 1 ) × ( N − V + 1 ) Z\in \R^{(M-U+1)\times (N-V+1)} Z∈R(M−U+1)×(N−V+1) ,有函数 f ( Z ) ∈ R f(Z)\in \R f(Z)∈R 为标量
∂ f ( Z ) ∂ w u v = ∑ i = 1 M − U + 1 ∑ j = 1 N − V + 1 ∂ Z i j ∂ w u v ∂ f ( Z ) ∂ Z i j = ∑ i = 1 M − U + 1 ∑ j = 1 N − V + 1 X i + u − 1 , j + v − 1 ∂ f ( Z ) ∂ Z i j = ∑ i = 1 M − U + 1 ∑ j = 1 N − V + 1 ∂ f ( Z ) ∂ Z i j X i + u − 1 , j + v − 1 \begin{aligned} \frac{\partial f(Z)}{\partial w_{uv}}&=\sum\limits_{i=1}^{M-U+1}\sum\limits_{j=1}^{N-V+1}\frac{\partial Z_{ij}}{\partial w_{uv}}\frac{\partial f(Z)}{\partial Z_{ij}}\\ &=\sum\limits_{i=1}^{M-U+1}\sum\limits_{j=1}^{N-V+1}X_{i+u-1,j+v-1}\frac{\partial f(Z)}{\partial Z_{ij}}\\ &=\sum\limits_{i=1}^{M-U+1}\sum\limits_{j=1}^{N-V+1}\frac{\partial f(Z)}{\partial Z_{ij}}X_{i+u-1,j+v-1} \end{aligned} ∂wuv∂f(Z)=i=1∑M−U+1j=1∑N−V+1∂wuv∂Zij∂Zij∂f(Z)=i=1∑M−U+1j=1∑N−V+1Xi+u−1,j+v−1∂Zij∂f(Z)=i=1∑M−U+1j=1∑N−V+1∂Zij∂f(Z)Xi+u−1,j+v−1
-
互相关结果的每个元素 Z i j Z_{ij} Zij 都与某一卷积核元素 w u v w_{uv} wuv 相关
Z i j = ∑ u = 1 U ∑ v = 1 V w u v X i + u − 1 , j + v − 1 Z_{ij}=\sum\limits_{u=1}^U\sum\limits_{v=1}^Vw_{uv}X_{i+u-1,j+v-1} Zij=u=1∑Uv=1∑VwuvXi+u−1,j+v−1
所以对某一卷积核元素求偏导,为所有输出元素对该元素求偏导的和
f ( Z ) f(Z) f(Z) 关于 W W W 的偏导数为 X X X 与 ∂ f ( Z ) ∂ Z \frac{\partial f(Z)}{\partial Z} ∂Z∂f(Z) 的卷积
∂ f ( Z ) ∂ W = ∂ f ( Z ) ∂ Z ⊗ X \frac{\partial f(Z)}{\partial W}=\frac{\partial f(Z)}{\partial Z}\otimes X ∂W∂f(Z)=∂Z∂f(Z)⊗X
∂ f ( Z ) ∂ X s t = ∑ i = 1 M − U + 1 ∑ j = 1 N − V + 1 ∂ Z i j ∂ X s t ∂ f ( Z ) ∂ Z i j = ∑ i = 1 M − U + 1 ∑ j = 1 N − V + 1 W s − i + 1 , t − j + 1 ∂ f ( Z ) ∂ Z i j \begin{aligned} \frac{\partial f(Z)}{\partial X_{st}}&=\sum\limits_{i=1}^{M-U+1}\sum\limits_{j=1}^{N-V+1}\frac{\partial Z_{ij}}{\partial X_{st}}\frac{\partial f(Z)}{\partial Z_{ij}}\\ &=\sum\limits_{i=1}^{M-U+1}\sum\limits_{j=1}^{N-V+1}W_{s-i+1,t-j+1}\frac{\partial f(Z)}{\partial Z_{ij}} \end{aligned} ∂Xst∂f(Z)=i=1∑M−U+1j=1∑N−V+1∂Xst∂Zij∂Zij∂f(Z)=i=1∑M−U+1j=1∑N−V+1Ws−i+1,t−j+1∂Zij∂f(Z)
- 其中当 ( s − i + 1 ) < 1 (s-i+1)<1 (s−i+1)<1 或 ( s − i + 1 ) > U (s-i+1)>U (s−i+1)>U ,或 ( t − j + 1 ) < 1 (t-j+1)<1 (t−j+1)<1 或 t − j + 1 > V t-j+1>V t−j+1>V 时, W s − i + 1 , t − j + 1 = 0 W_{s-i+1,t-j+1}=0 Ws−i+1,t−j+1=0 ,即相当于对 W W W 进行了 P = ( M − u , N − V ) P=(M-u,N-V) P=(M−u,N−V) 的零填充
f ( Z ) f(Z) f(Z) 关于 X X X 的偏导数为 W W W 和 ∂ f ( Z ) ∂ Z \frac{\partial f(Z)}{\partial Z} ∂Z∂f(Z) 的宽卷积
∂ f ( Z ) ∂ X = r o t 180 ( ∂ f ( Z ) ∂ Z ) ⊗ ~ W = r o t 180 ( W ) ⊗ ~ ∂ f ( Z ) ∂ Z \begin{aligned} \frac{\partial f(Z)}{\partial X}&=rot180(\frac{\partial f(Z)}{\partial Z})\tilde{\otimes}W\\ &=rot180(W)\tilde{\otimes}\frac{\partial f(Z)}{\partial Z} \end{aligned} ∂X∂f(Z)=rot180(∂Z∂f(Z))⊗~W=rot180(W)⊗~∂Z∂f(Z)
误差项求解
根据卷积求导公式,有
∂ L ∂ W ( l , p , d ) = ∂ L ∂ Z ( l , p ) ⊗ X ( l − 1 , d ) = δ ( l , p ) ⊗ X ( l − 1 , d ) ∂ L ∂ b ( l , p ) = ∂ L ∂ Z ( l , p ) ⋅ ∂ Z ( l , p ) ∂ b ( l , p ) = δ ( l , p ) \begin{aligned} \frac{\partial \mathcal{L}}{\partial W^{(l,p,d)}}&=\frac{\partial \mathcal{L}}{\partial Z^{(l,p)}}\otimes X^{(l-1,d)}\\ &=\delta^{(l,p)}\otimes X^{(l-1,d)}\\ \frac{\partial \mathcal{L}}{\partial b^{(l,p)}}&=\frac{\partial \mathcal{L}}{\partial Z^{(l,p)}}\cdot \frac{\partial Z^{(l,p)}}{\partial b^{(l,p)}}\\ &=\delta^{(l,p)} \end{aligned} ∂W(l,p,d)∂L∂b(l,p)∂L=∂Z(l,p)∂L⊗X(l−1,d)=δ(l,p)⊗X(l−1,d)=∂Z(l,p)∂L⋅∂b(l,p)∂Z(l,p)=δ(l,p)
即在卷积网络中,第 l l l 层参数依赖其所在层的误差项 δ ( l , p ) \delta^{(l,p)} δ(l,p)
δ ( l , p ) = Δ ∂ L ∂ Z ( l , p ) = ∂ X ( l , p ) ∂ Z ( l , p ) ∂ L ∂ X ( l , p ) = f l ′ ( Z ( l , p ) ) ⊙ ∑ t = 1 P ( r o t 180 ( W ( l + 1 , t , p ) ) ⊗ ~ ∂ L ∂ Z ( l + 1 , t ) ) = f l ′ ( Z ( l , p ) ) ⊙ ∑ t = 1 P ( r o t 180 ( W ( l + 1 , t , p ) ) ⊗ ~ δ ( l + 1 , t ) ) \begin{aligned} \delta^{(l,p)}&\overset{\Delta}{=}\frac{\partial \mathcal{L}}{\partial Z^{(l,p)}}\\ &=\frac{\partial X^{(l,p)}}{\partial Z^{(l,p)}}\frac{\partial \mathcal{L}}{\partial X^{(l,p)}}\\ &=f_l'(Z^{(l,p)})\odot\sum\limits_{t=1}^P\left( rot180(W^{(l+1,t,p)})\tilde{\otimes}\frac{\partial \mathcal{L}}{\partial Z^{(l+1,t)}}\right)\\ &=f_l'(Z^{(l,p)})\odot\sum\limits_{t=1}^P\left( rot180(W^{(l+1,t,p)})\tilde{\otimes}\delta^{(l+1,t)}\right) \end{aligned} δ(l,p)=Δ∂Z(l,p)∂L=∂Z(l,p)∂X(l,p)∂X(l,p)∂L=fl′(Z(l,p))⊙t=1∑P(rot180(W(l+1,t,p))⊗~∂Z(l+1,t)∂L)=fl′(Z(l,p))⊙t=1∑P(rot180(W(l+1,t,p))⊗~δ(l+1,t))
-
由于第 l + 1 l+1 l+1 层的输入 X ( l , p ) X^{(l,p)} X(l,p) 为第 l l l 层的活性值 Y ( l , p ) = f l ( Z ( l , p ) ) Y^{(l,p)}=f_l(Z^{(l,p)}) Y(l,p)=fl(Z(l,p)) ,即有 D ( l + 1 ) = P ( l ) D^{(l+1)}=P^{(l)} D(l+1)=P(l) ,故
∂ X ( l , p ) ∂ Z ( l , p ) = ∂ f l ( Z ( l , p ) ) ∂ Z ( l , p ) = f l ′ ( Z ( l , p ) ) \frac{\partial X^{(l,p)}}{\partial Z^{(l,p)}}=\frac{\partial f_l(Z^{(l,p)})}{\partial Z^{(l,p)}}=f_l'(Z^{(l,p)}) ∂Z(l,p)∂X(l,p)=∂Z(l,p)∂fl(Z(l,p))=fl′(Z(l,p)) -
而第 l + 1 l+1 l+1 层
Z ( l + 1 , p ) = ∑ d = 1 D W ( l + 1 , p , d ) ⊗ X ( l , d ) + b ( l + 1 , p ) Z^{(l+1,p)}=\sum\limits_{d=1}^DW^{(l+1,p,d)}\otimes X^{(l,d)}+b^{(l+1,p)} Z(l+1,p)=d=1∑DW(l+1,p,d)⊗X(l,d)+b(l+1,p)
由于第 l + 1 l+1 l+1 层的输入个数 D ( l + 1 ) D^{(l+1)} D(l+1) 为第 l l l 层的输出个数 P ( l ) P^{(l)} P(l) ,所以相当于 X ( l + 1 ) X^{(l+1)} X(l+1) 为 P ( l ) P^{(l)} P(l) 维向量,对其求偏导为
∂ L ∂ X ( l , p ) = ∑ t = 1 P r o t 180 ( W ( l + 1 , t , p ) ) ⊗ ~ L ∂ Z ( l + 1 , t ) \frac{\partial \mathcal{L}}{\partial X^{(l,p)}}=\sum\limits_{t=1}^Prot180\left(W^{(l+1,t,p)}\right)\tilde{\otimes}\frac{\mathcal{L}}{\partial Z^{(l+1,t)}} ∂X(l,p)∂L=t=1∑Prot180(W(l+1,t,p))⊗~∂Z(l+1,t)L
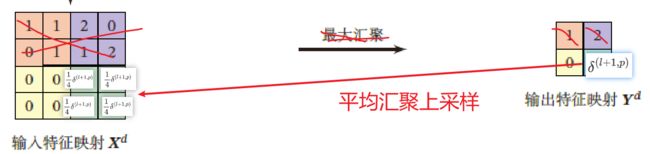
池化层误差项求解
当第 l + 1 l+1 l+1 层是汇聚层时,因为汇聚层是下采样操作, l + 1 l+1 l+1 层的误差项 δ \delta δ 对应于第 l l l 层的相应特征映射的一个区域,
l l l 层的第 p p p 个特征映射中的每个神经元都有一条边和 l + 1 l+1 l+1 层的第 p p p 个特征映射中的一个神经元相连
第 l l l 层第 p p p 个特征映射的误差项 δ ( l , p ) \delta^{(l,p)} δ(l,p) 的具体推导为
δ ( l , p ) = Δ ∂ L ∂ Z ( l , p ) = ∂ X ( l , p ) ∂ Z ( l , p ) ∂ Z ( l + 1 , p ) ∂ X ( l , p ) L ∂ Z ( l + 1 , p ) = f l ′ ( Z ( l , p ) ) ⊙ u p ( δ ( l + 1 , p ) ) \begin{aligned} \delta^{(l,p)}&\overset{\Delta}{=}\frac{\partial \mathcal{L}}{\partial Z^{(l,p)}}\\ &=\frac{\partial X^{(l,p)}}{\partial Z^{(l,p)}}\frac{\partial Z^{(l+1,p)}}{\partial X^{(l,p)}}\frac{\mathcal{L}}{\partial Z^{(l+1,p)}}\\ &=f_l'(Z^{(l,p)})\odot up(\delta^{(l+1,p)}) \end{aligned} δ(l,p)=Δ∂Z(l,p)∂L=∂Z(l,p)∂X(l,p)∂X(l,p)∂Z(l+1,p)∂Z(l+1,p)L=fl′(Z(l,p))⊙up(δ(l+1,p))
u p up up 为上采样函数,与汇聚层的下采样操作相反
-
若下采样是最大汇聚,则 δ ( l + 1 , p ) \delta^{(l+1,p)} δ(l+1,p) 中每个值会直接传递到前一层对应区域中的最大值对应的神经元,该区域中其他神经元设为0

-
若下采样是平均汇聚,则误差项 δ ( l + 1 , p ) \delta^{(l+1,p)} δ(l+1,p) 中每个值被平均分配到前一层对应区域的所有神经元上
1.2.4 典型卷积神经网络
LeNet-5
基于 LeNet-5 的手写数字识别系统在20世纪90年代被美国很多银行使用

LeNet-5 共有7层,接受输入图像大小为 32 × 32 = 1024 32\times 32=1024 32×32=1024 ,输出对应10个类别的划分
C 1 C_1 C1 层是卷积层
C 1 C_1 C1 层是卷积层,使用 6 6 6 个 5 × 5 5\times 5 5×5 的卷积核,得到 ( 32 − 5 + 1 ) × ( 32 − 5 + 1 ) = 28 × 28 = 784 (32-5+1)\times(32-5+1)=28\times 28=784 (32−5+1)×(32−5+1)=28×28=784 的特征映射,因此 C 1 C_1 C1 层的神经元数量为 6 × 784 = 4704 6\times 784=4704 6×784=4704 ,可训练的参数数量为 6 × 5 × 5 + 6 = 156 6\times 5\times 5+6=156 6×5×5+6=156 ,连接数为 784 × 156 = 122304 784\times 156=122304 784×156=122304 个
S 2 S_2 S2 层为汇聚层
采样窗口为 2 × 2 2\times 2 2×2 ,使用平均汇聚,并使用一个非线性函数 Y ′ d = f ( w d Y d + b d ) Y'^d=f(w^dY^d+b^d) Y′d=f(wdYd+bd) 。神经元个数为 6 × 14 × 14 = 1176 6\times 14\times14=1176 6×14×14=1176 ,可训练参数数量为 6 × ( 1 + 1 ) = 12 6\times (1+1)=12 6×(1+1)=12,连接数为 156 × 14 × 14 × ( 4 + 1 ) = 5880 156\times 14\times 14\times(4+1)=5880 156×14×14×(4+1)=5880
- 偏置也算一个连接
C 3 C_3 C3 层为卷积层
LeNet-5 中用连接表定于会输入和输出特征映射间的依赖关系

由于输入和输出特征映射之间不一定需要全连接关系 Y ^ ( l , p ) = f ( ∑ d = 1 D W ( l , p , d ) ⊗ X ( l − 1 , d ) + b ( l , p ) ) \hat{Y}^{(l,p)}=f\left(\sum\limits_{d=1}^DW^{^{(l,p,d)}}\otimes X^{(l-1,d)}+b^{(l,p)}\right) Y^(l,p)=f(d=1∑DW(l,p,d)⊗X(l−1,d)+b(l,p))
连接表 T 用于描述输入和输出特征映射之间的连接关系, C 3 C_3 C3 层的第 0 ∼ 5 0\sim 5 0∼5 个特征映射依赖于 S 2 S_2 S2 层的每3个连续子集,第 6 ∼ 11 6\sim 11 6∼11 个特征映射依赖于 S 2 S_2 S2 层的每4个连续子集,第 12 ∼ 14 12\sim 14 12∼14 个特征映射依赖于 S 2 S_2 S2 层的每4个不连续子集,第 15 15 15 个特征映射依赖于 S 2 S_2 S2 层的所有特征映射
- 第 p p p 个输出特征映射依赖于第 d d d 个输入特征映射,则 T p , d = 1 T_{p,d}=1 Tp,d=1 ,否则为0,此时有卷积表达式
Y ^ ( l , p ) = f ( ∑ d = 1 T p , d = 1 D W ( l , p , d ) ⊗ X l − 1 , d + b ( l , p ) ) \hat{Y}^{(l,p)}=f\left(\sum\limits_{\substack{d=1\\T_{p,d}=1}}^DW^{(l,p,d)\otimes X^{l-1,d}}+b^{(l,p)}\right) Y^(l,p)=f d=1Tp,d=1∑DW(l,p,d)⊗Xl−1,d+b(l,p)
其中,T为 P × D P\times D P×D 大小的连接表,假设连接表中非零个数为 T T T ,则每个卷积核的大小为 T × U × V T\times U\times V T×U×V ,共需 T × U × V + P T\times U\times V+P T×U×V+P 个参数
对于 C 3 C_3 C3 层,共使用 60 60 60 个 5 × 5 5\times 5 5×5 的卷积核,得到 16 16 16 组大小为 ( 14 − 5 + 1 ) × ( 14 − 5 + 1 ) = 15 × 15 (14-5+1)\times (14-5+1)=15\times 15 (14−5+1)×(14−5+1)=15×15 的特征映射,神经元数量为 16 × 100 = 1600 16\times 100=1600 16×100=1600 ,可训练参数数量为 ( 60 × 25 ) + 16 = 1516 (60\times 25)+16=1516 (60×25)+16=1516 ,连接数为 100 × 1516 = 151600 100\times 1516=151600 100×1516=151600
S 4 S_4 S4 层为汇聚层
采样窗口为 2 × 2 2\times 2 2×2 ,得到 16 16 16 个 5 × 5 5\times 5 5×5 的特征映射,可训练参数数量为 16 × ( 1 + 1 ) = 32 16\times (1+1)=32 16×(1+1)=32 ,连接数为 16 × 5 × 5 × ( 4 + 1 ) = 2000 16\times 5\times 5\times(4+1)=2000 16×5×5×(4+1)=2000
- 偏置也算一个连接
C 5 C_5 C5 层为卷积层
使用 120 × 16 = 1920 120\times 16=1920 120×16=1920 个 5 × 5 5\times 5 5×5 大小的卷积核,得到 120 120 120 组大小为 1 × 1 1\times 1 1×1 的特征映射。 C 5 C_5 C5 层的神经元数量为 120 120 120 ,可训练参数数量为 1920 × 25 + 120 = 48120 1920\times 25+120=48120 1920×25+120=48120 ,连接数为 120 × ( 16 × 25 + 1 ) = 48120 120\times (16\times 25+1)=48120 120×(16×25+1)=48120
F 6 F_6 F6 层为全连接层
有 84 84 84 个神经元,可训练参数数量为 84 × ( 120 + 1 ) = 10164 84\times (120+1)=10164 84×(120+1)=10164 ,连接数与参数数相同
输出层
输出层为 10 10 10 个径向奇函数
AlexNet
全监督的端到端学习模型,第一个现代深度卷积网络模型
- GPU进行并行训练
- 采用 R e L U ReLU ReLU 作为非线性激活函数
- 使用 Dropout 防止过拟合
- 使用数据增强来提高模型准确率

输入为 224 × 224 × 3 224\times 224\times 3 224×224×3 的图像,输出为 1000 1000 1000 个类别的条件概率,5个卷积层,3个汇聚层,3个全连接层
- 由于当时GPU算力限制,所以将网络拆为两半
对于特殊的一维卷积变体,输出映射有以下变式计算
M − K + 2 P S + 1 \frac{M-K+2P}{S}+1 SM−K+2P+1
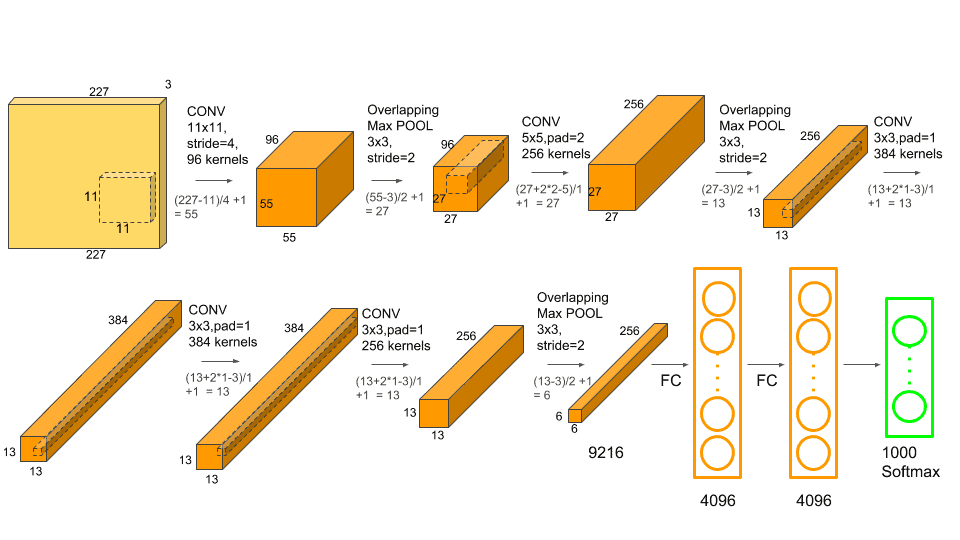
第一个卷积层
两个大小为 11 × 11 × 3 × 48 11\times 11\times 3\times 48 11×11×3×48 的卷积核( D = 3 , P = 48 D=3,P=48 D=3,P=48) ,步长 S = 4 S=4 S=4 ,零填充 P = 3 P=3 P=3 ,得到两个大小为 ( 224 − 11 + 2 × 3 4 + 1 ) × ( 224 − 11 + 2 × 3 4 + 1 ) × 48 = 55 × 55 × 48 (\frac{224-11+2\times 3}{4}+1)\times (\frac{224-11+2\times 3}{4}+1)\times48=55\times 55\times 48 (4224−11+2×3+1)×(4224−11+2×3+1)×48=55×55×48 的特征映射组
第一个汇聚层
大小为 3 × 3 3\times 3 3×3 的最大汇聚操作,步长 S = 2 S=2 S=2 ,得到两个 ( 55 − 3 + 2 × 0 2 + 1 ) × ( 55 − 3 + 2 × 0 2 + 1 ) × 48 = 27 × 27 × 48 (\frac{55-3+2\times 0}{2}+1)\times (\frac{55-3+2\times 0}{2}+1)\times 48=27\times 27\times48 (255−3+2×0+1)×(255−3+2×0+1)×48=27×27×48 个特征映射组
第二个卷积层
使用两个大小为 5 × 5 × 48 × 128 5\times 5\times 48\times 128 5×5×48×128 的卷积核( D = 48 , P = 128 D=48,P=128 D=48,P=128) ,步长 S = 1 S=1 S=1 ,零填充 P = 2 P=2 P=2 ,得到两个大小为 ( 27 − 5 + 2 × 2 1 + 1 ) × ( 27 − 5 + 2 × 2 1 + 1 ) × 128 = 27 × 27 × 128 \left(\frac{27-5+2\times 2}{1}+1\right)\times \left(\frac{27-5+2\times 2}{1}+1\right)\times 128=27\times 27\times 128 (127−5+2×2+1)×(127−5+2×2+1)×128=27×27×128 的特征映射
第二个汇聚层
使用 3 × 3 3\times 3 3×3 的最大汇聚操作,步长 S = 2 S=2 S=2 ,得到两个 ( 27 − 3 + 2 × 0 2 + 1 ) × ( 27 − 3 + 2 × 0 2 + 1 ) × 128 = 13 × 13 × 128 \left(\frac{27-3+2\times 0}{2}+1\right)\times \left(\frac{27-3+2\times 0}{2}+1\right)\times 128=13\times 13\times 128 (227−3+2×0+1)×(227−3+2×0+1)×128=13×13×128 的特征映射组
第三个卷积层
两个路径的融合,使用一个大小为 3 × 3 × 256 × 384 3\times 3\times 256\times 384 3×3×256×384 的卷积核( D = 256 , P = 384 D=256,P=384 D=256,P=384) ,步长 S = 1 S=1 S=1,零填充 P = 1 P=1 P=1 ,得到两个大小为 ( 13 − 3 + 2 × 1 1 + 1 ) × ( 13 − 3 + 2 × 1 1 + 1 ) × 192 = 13 × 13 × 192 \left(\frac{13-3+2\times 1}{1}+1\right)\times \left(\frac{13-3+2\times 1}{1}+1\right)\times 192=13\times 13\times 192 (113−3+2×1+1)×(113−3+2×1+1)×192=13×13×192 的特征映射组
第四个卷积层
使用两个大小为 3 × 3 × 192 × 192 3\times 3\times 192\times 192 3×3×192×192 的卷积核( D = 192 , P = 192 D=192,P=192 D=192,P=192) ,步长 S = 1 S=1 S=1,零填充 P = 1 P=1 P=1 ,得到两个大小为 13 × 13 × 192 13\times 13\times 192 13×13×192 的特征映射组
第五个卷积层
使用两个大小为 3 × 3 × 192 × 128 3\times 3\times192\times 128 3×3×192×128 的卷积核( D = 192 , P = 128 D=192,P=128 D=192,P=128) ,步长 S = 1 S=1 S=1 ,零填充 P = 1 P=1 P=1 ,得到两个大小为 ( 13 − 3 + 2 × 1 1 + 1 ) × ( 13 − 3 + 2 × 1 1 + 1 ) × 128 = 13 × 13 × 128 \left(\frac{13-3+2\times 1}{1}+1\right)\times \left(\frac{13-3+2\times 1}{1}+1\right)\times 128=13\times 13\times 128 (113−3+2×1+1)×(113−3+2×1+1)×128=13×13×128 的特征映射组
第三个汇聚层
使用大小为 3 × 3 3\times 3 3×3 的最大汇聚操作,步长 S = 2 S=2 S=2 ,得到两个大小为 ( 13 − 3 + 2 × 0 2 + 1 ) × ( 13 − 3 + 2 × 0 2 + 1 ) × 128 = 6 × 6 × 128 \left(\frac{13-3+2\times 0}{2}+1\right)\times\left(\frac{13-3+2\times 0}{2}+1\right)\times 128=6\times 6\times 128 (213−3+2×0+1)×(213−3+2×0+1)×128=6×6×128 的特征映射
三个全连接层
全连接层1+ReLU+Dropout:参数矩阵 W ∈ R 6 × 6 × 256 × 4096 = 9216 × 4096 W\in \R^{6\times 6\times 256\times 4096=9216\times 4096} W∈R6×6×256×4096=9216×4096 ,有 4096 4096 4096 个神经元
全连接层2+ReLU+Dropout:参数矩阵 W ∈ R 4096 × 4096 W\in \R^{4096\times 4096} W∈R4096×4096 ,有 4096 4096 4096 个神经元
全连接层3:有 1000 1000 1000 个神经元,参数矩阵 W ∈ R 4096 × 1000 W\in \R^{4096\times 1000} W∈R4096×1000
输出层 Softmax
Inception网络
卷积层的卷积核大小是一个十分关键的问题
在 Inception 网络中,一个卷积层包含多个不同大小的卷积操作,称为 Inception 模块
Inception 网络由多个 Inception 模块和少量汇聚层堆叠而成
Inception模块
Inception 模块同时使用不同大小的卷积核,并将得到的特征映射在深度上拼接(堆叠)起来作为输出特征映射
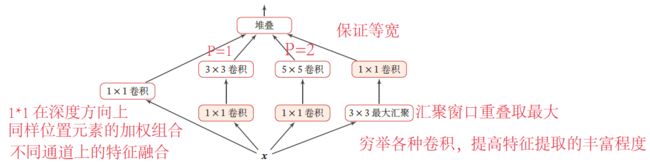
若 X ∈ R M × N × D X\in \R^{M\times N\times D} X∈RM×N×D
-
对于 1 × 1 × D 1\times 1\times D 1×1×D 的卷积核,得到特征映射 M × N × D M\times N\times D M×N×D
-
对于 3 × 3 3\times 3 3×3 的卷积核,特征映射 ( M − 3 + 2 × 1 1 + 1 ) × ( N − 3 + 2 × 1 1 + 1 ) × D = M × N × D \left(\frac{M-3+2\times 1}{1}+1\right)\times \left(\frac{N-3+2\times 1}{1}+1\right)\times D=M\times N\times D (1M−3+2×1+1)×(1N−3+2×1+1)×D=M×N×D
为得到等宽卷积,补 P = 3 − 1 2 = 1 P=\frac{3-1}{2}=1 P=23−1=1 个零
-
对于 5 × 5 5\times 5 5×5 的卷积核,为得到等宽卷积,补 P = 5 − 1 2 = 2 P=\frac{5-1}{2}=2 P=25−1=2 个零
1 × 1 1\times 1 1×1 卷积核的作用
-
降维/升维

1 × 1 1\times 1 1×1 的卷积核不会改变宽度和长度,直观看可以改变深度,即通道数
降维:可以通过减少通道数来减少参数,进而可以进行数据的降维处理
- 假设有一个 M × N × 3 M\times N\times 3 M×N×3 的图像,通过 1 × 1 × 3 × 2 1\times 1\times 3\times 2 1×1×3×2 ( D = 3 , P = 2 D=3,P=2 D=3,P=2 ) 的卷积核处理,得到 M × N × 2 M\times N\times 2 M×N×2 的特征映射,达到降维目的
升维:同样可以通过增加通道数来增加参数,对数据进升维处理
- 同样的输入,经过 1 × 1 × 3 × 4 1\times 1\times 3\times 4 1×1×3×4 的卷积核处理,得到 M × N × 4 M\times N\times 4 M×N×4 的特征映射,达到升维的目的
-
跨通道信息整合
使用 1 × 1 1\times 1 1×1 的卷积核,实现降维和升维的操作其实是利用通道间信息的线性组合,
3 × 3 × 64 3\times 3\times 64 3×3×64 的输入,经过 1 × 1 × 64 × 28 1\times 1\times 64\times 28 1×1×64×28 的卷积核,就变成了 3 × 3 × 28 3\times 3\times 28 3×3×28 的输出,可以理解为原来的64个通道的输入跨通道线性组合变成了28个通道,这就是通道间的信息交互
-
减少计算量

原先:
Z ( l , p ) = ∑ d = 1 D W ( l , p , d ) ⊗ X ( l − 1 , d ) + b ( l , p ) Z^{(l,p)}=\sum\limits_{d=1}^DW^{(l,p,d)}\otimes X^{(l-1,d)}+b^{(l,p)} Z(l,p)=d=1∑DW(l,p,d)⊗X(l−1,d)+b(l,p) ,对于一次卷积,需要经过 M ′ × N ′ × U × V M'\times N'\times U\times V M′×N′×U×V 次乘法,故若要计算上述输入特征映射,需要 P × D × M ′ × N ′ × U × V = 32 × 192 × 5 2 × 2 8 2 P\times D\times M'\times N'\times U\times V=32\times 192\times 5^2\times 28^2 P×D×M′×N′×U×V=32×192×52×282
-
增加网络的深度,添加非线性,增强神经网络的表达能力
增加网络深度好处:卷积核越大,网络的深度也就增加。随着网络深度的增加,越靠后的特征图上的节点感受野也越大。因此特征也越来越形象,也就是更能看清这个特征是个什么东西。层数越浅,就越不知道这个提取的特征到底是个什么东西。
添加非线性:想在不增加卷积核大小的情况下,让网络加深,可以加一层 1 × 1 1\times 1 1×1 的卷积核,在不改变输入规模的情况下,一个卷积层包含激活和池化,相当于多了一个非线性的激活函数,如 R e L U ReLU ReLU 和 S i g m o d Sigmod Sigmod
卷积层之后经过激励层,经过卷积核得到的特征映射,可以添加非线性激活函数,提高网络的表达能力
Inception网络版本
其中最早的Inception v1 版本就是非常著名的GoogLeNet
GoogLeNet 由9 个Inception v1 模块和5 个汇聚层以及其他一些卷积层和全连接层构成,总共为22 层网络
为了解决梯度消失问题,GoogLeNet 在网络中间层引入两个辅助分类器来加强监督信息
Inception 网络有多个改进版本,其中比较有代表性的有Inception v3 网络。Inception v3 网络用多层的小卷积核来替换大的卷积核以减少计算量和参数量,并保持感受野不变

- 使用两层 3 × 3 3\times 3 3×3 的卷积替代 v1 中的 5 × 5 5\times 5 5×5 的卷积
- 使用连续的 K × 1 K\times 1 K×1 和 1 × K 1\times K 1×K 替换 K × K K\times K K×K 的卷积
- 引入标签平滑和批量归一化等优化方法进行训练
残差网络ResNet(152层)
通过给非线性的卷积层增加直连边的方式来提高信息的传播效率
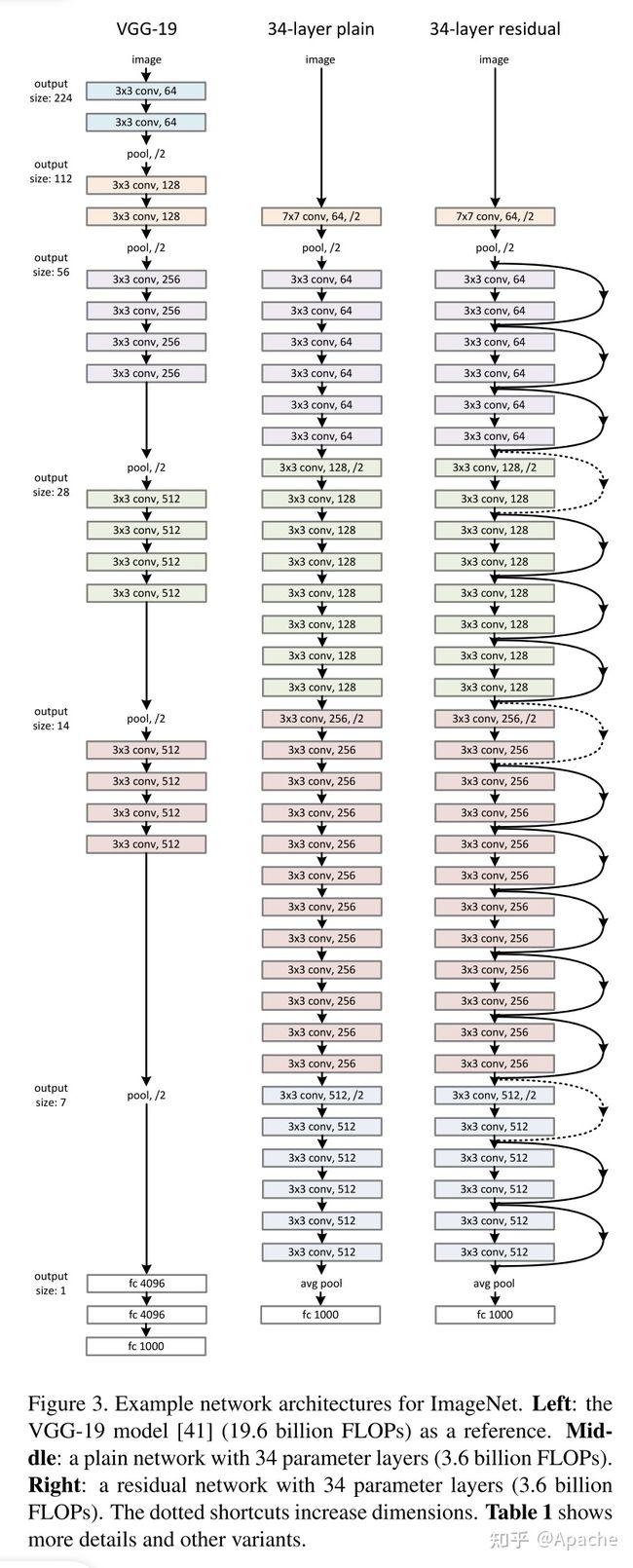
残差单元
假设在一个深度网络中,我们期望一个非线性单元 f ( x ; θ ) f(x;\theta) f(x;θ) 去逼近一个目标函数 h ( x ) h(x) h(x) ,可以将目标函数拆分成两部分
h ( x ) = x ⏟ 恒等函数 + ( h ( x ) − x ) ⏟ 残差函数 h(x)=\underbrace{x}_{恒等函数}+\underbrace{(h(x)-x)}_{残差函数} h(x)=恒等函数 x+残差函数 (h(x)−x)
-
根据通用近似定理,一个由神经网络构成的非线性单元有足够多的能力来近似逼近原始目标函数或残差函数,但由于线性函数 h ( x ) = x h(x)=x h(x)=x 很难用非线性单元拟合,所以拟合残差函数反而容易
故将原始优化问题变为:让非线性单元 f ( x ; θ ) f(x;\theta) f(x;θ) 去近似残差函数 h ( x ) − x h(x)-x h(x)−x ,并用 f ( x ; θ ) + x f(x;\theta)+x f(x;θ)+x 去逼近 h ( x ) h(x) h(x)

残差单元有多个级联的(等宽)卷积层和一个跨层的直连边组成,再经过 R e L U ReLU ReLU 激活后得到输出
- 由于直连边的存在,偏导大于等于1,使得卷积网络可以堆很深
∂ h ( x ) ∂ x = 1 + ∂ f ( x ; θ ) ∂ x \frac{\partial h(x)}{\partial x}=1+\frac{\partial f(x;\theta)}{\partial x} ∂x∂h(x)=1+∂x∂f(x;θ)
1.2.5 非标准卷积
空洞卷积
如何增加输出单元的感受野
感受野和卷积长度(卷积核大小)直接相关
-
增加卷积核大小——增加参数数量
-
增加层数:两层 3 × 3 3\times 3 3×3 近似一层 5 × 5 5\times 5 5×5 卷积的效果
增加复杂度
-
卷积前进行汇聚——产生信息损失
汇聚层不但可以有效减少神经元的数量,还可以使网络对一些小的局部形态改变保持不变性,并拥有更大的感受野
第2层卷积层神经元感受野有K个神经元,第3层卷积层神经元感受野有 2 K − 1 2K-1 2K−1 个神经元,依次类推,随着卷积层数深度增加,神经元感受野也就越大,越容易提取到高级特征
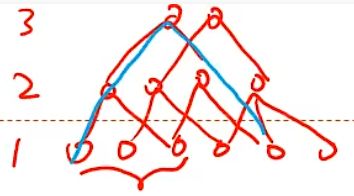
空洞卷积 不增加参数数量,同时增加输出单元感受野——膨胀卷积
在卷积核每两个元素之间插入 D − 1 D-1 D−1 个空洞,卷积核的有效大小为
K ′ = K + ( K − 1 ) × ( D − 1 ) K'=K+(K-1)\times (D-1) K′=K+(K−1)×(D−1)
- D D D 为膨胀率,当 D = 1 D=1 D=1 时卷积核为普通的卷积核
通过给卷积核插入空洞(改变步长)来增加感受野

"反"卷积
转置卷积
低维特征映射到高维特征映射——转置卷积,反卷积
假设一个高维向量 X ∈ R D X\in \R^D X∈RD 和一个低维向量 Z ∈ R M Z\in \R^M Z∈RM ,且 M < D M
Z = W X , W ∈ R M × D Z=WX,W\in \R^{M\times D} Z=WX,W∈RM×D
若用仿射变换来实现高维到低维的映射
X = W T Z X=W^TZ X=WTZ
两个映射形式上是转置关系
- 在全连接网络中,忽略激活函数,前向计算和反向传播就是一种转置关系
Z ( l + 1 ) = W ( l + 1 ) Z ( l ) δ ( l ) = ( W ( l + 1 ) ) T δ ( l + 1 ) Z^{(l+1)}=W^{(l+1)}Z^{(l)}\\ \delta^{(l)}=(W^{(l+1)})^T\delta^{(l+1)} Z(l+1)=W(l+1)Z(l)δ(l)=(W(l+1))Tδ(l+1)
对于二维向量

- C C C 为稀疏矩阵,其非零元素来自于卷积核 W W W 中的元素

对于一个 M M M 维的向量 Z Z Z 和大小为 K K K 的卷积核,如果希望通过卷积操作来映射到更高维的向量,需要对 Z Z Z 两端进行补零 P = K − 1 P=K-1 P=K−1 ,可以得到 M + K − 1 M+K-1 M+K−1 维向量
对于 M × N M\times N M×N 维向量 X X X ,通过 U × V U\times V U×V 为卷积核 W W W ,在 M M M 边分别补 U − 1 U-1 U−1 个零, N N N 边分别补 V − 1 V-1 V−1 个零,可以得到转置卷积 ( M + U − 1 ) × ( N + V − 1 ) (M+U-1)\times (N+V-1) (M+U−1)×(N+V−1) 维输出

微步卷积
步长变小——微步卷积
整体思路:通过增加卷积的步长 S > 1 S>1 S>1 ,实现对特征的下采样操作,大幅降低特征映射维数(神经元数量)
同样,减小步长 S < 1 S<1 S<1 ,能使特征映射的维数(神经元数量)增加
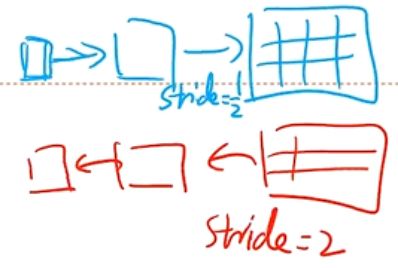
若希望转置卷积的步长变为 1 S \frac{1}{S} S1 ,则需要在输入特征之间插入 S − 1 S-1 S−1 个零来使移动速度变慢
-
以一维转置卷积为例,对一个 M M M 维的向量 Z Z Z 和大小为 K K K 的卷积核,通过对向量 Z Z Z 进行两端补零 P = K − 1 P=K-1 P=K−1 ,并且在每两个向量元素之间插入 D D D 个零,然后进行步长为 1 1 1 的卷积,得到 ( D + 1 ) × ( M − 1 ) + K (D+1)\times (M-1)+K (D+1)×(M−1)+K 维向量
-
对于 M × N M\times N M×N 的输入向量 X X X 和 U × V U\times V U×V 的卷积核,对向量 X X X 分别补 U − 1 U-1 U−1 与 V − 1 V-1 V−1 个零,并且在每两个元素之间插入 D 1 D_1 D1 与 D 2 D_2 D2 个零,得到 [ ( D 1 + 1 ) × ( M − 1 ) + U ] × [ ( D 2 + 1 ) × ( N − 1 ) + V ] [(D_1+1)\times (M-1)+U]\times [(D_2+1)\times (N-1)+V] [(D1+1)×(M−1)+U]×[(D2+1)×(N−1)+V] 维的输出向量 Z Z Z
若原先步长 S = 2 S=2 S=2 ,若步长减少 1 2 \frac{1}{2} 21 输出的特征映射会增加一倍
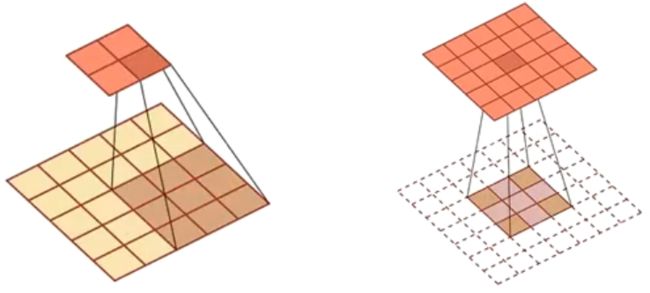
左图:输入 X ∈ R 5 × 5 X\in \R^{5\times 5} X∈R5×5 ,步长 S = 2 S=2 S=2
右图:步长 S = 1 S=1 S=1 ,填充零
- [ ( 1 + 1 ) × ( 2 − 1 ) + 3 ] × [ ( 1 + 1 ) × ( 2 − 1 ) + 3 ] = 5 × 5 [(1+1)\times (2-1)+3]\times[(1+1)\times (2-1)+3]=5\times 5 [(1+1)×(2−1)+3]×[(1+1)×(2−1)+3]=5×5
1.2.6 卷积神经网络应用
AlphaGo
决策网络

目标检测RCN
区域卷积网络
图像分割RCNN
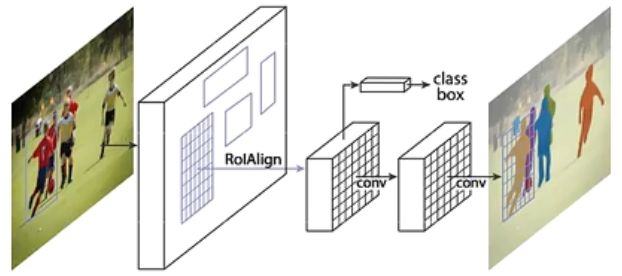
- 像素级图像分割
光学字符识别OCR
应用于文本
Ngram特征与卷积
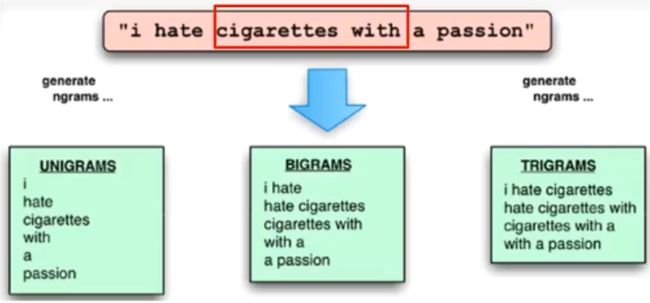
- 一元特征
- 二元特征:单词顺序
- 三元特征
可以理解为滑动窗口
词到词向量
通过Lookup Table 将一个单词变为一个词向量