ElastiSearch-介绍及安装
安装ElastiSearch
1.docker中安装elastic search
(1)下载elastic search和kibana
docker pull elasticsearch:7.6.2
docker pull kibana:7.6.2(2)配置挂载数据文件夹
# 创建配置文件目录
mkdir -p /mydata/elasticsearch/config
# 创建数据目录
mkdir -p /mydata/elasticsearch/data
# 将/mydata/elasticsearch/文件夹中文件都可读可写
chmod -R 777 /mydata/elasticsearch/
# 配置任意机器可以访问 elasticsearch
echo "http.host: 0.0.0.0" >/mydata/elasticsearch/config/elasticsearch.yml(3)启动ElasticSearch
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.6.2 -p 9200:9200 -p 9300:9300:向外暴露两个端口,9200用于HTTP REST API请求,9300 ES 在分布式集群状态下 ES 之间的通信端口;-e "discovery.type=single-node":es 以单节点运行-e ES_JAVA_OPTS="-Xms64m -Xmx512m":设置启动占用内存,不设置可能会占用当前系统所有内存- -v:挂载容器中的配置文件、数据文件、插件数据到本机的文件夹;
-d elasticsearch:7.6.2:指定要启动的镜像
(4) 设置开机启动elasticsearch
docker update elasticsearch --restart=always(5)查看es启动效果

访问端口号9200,看到上图说明安装成功。
(6)启动kibana
docker run --name kibana \
-e ELASTICSEARCH_HOSTS=http://192.168.56.10:9200 \
-p 5601:5601 \
-d kibana:7.6.2-e ELASTICSEARCH_HOSTS=http://192.168.56.10:9200 \ 设置成自己的虚拟机ip地址。
(7)设置开机启动kibana
docker update kibana --restart=always(8)查看kibana启动效果

出现上图访问成功。
ElastiSearch的简介
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
Elaticsearch,简称为es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。es也使用java开发并使用Lucene作为其核心来实现所有索引和搜索的功能。
据国际权威的数据库产品评测机构DB Engines的统计,在2016年1月,ElasticSearch已超过Solr等,成为排名第一的搜索引擎类应用。
Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
同时也是ELK的核心组件之一
E:ElastiSearch
L:Logstach 搜集数据的功能,是日志收集系统
K:Kibana 数据可视化,可以用图表的方式来去展示是数据可视化平台
ElastiSearch的优点
1.当实时建立索引时,Solr会产生io阻塞,查询性能较差.ElasticSearch具有明显优势。
2.随着数据量的增多,Solr搜索效率会变得低,ElasticSearch没有明显变化。
3.es开箱即用(解压即可),Solr安装略微复杂。
4.ElasticSearch带有分布式协调管理功能。
ElastiSearch的使用
1._cat操作
1. /_cat/nodes:查看所有节点
2. /_cat/health:查看ES健康状况
3. /_cat/master:查看主节点信息
4. /_cat/indicies:查看所有索引
2.索引文档
1.put请求
PUT http://192.168.56.10:9200/customer/external/1
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
这些返回的JSON串的含义;这些带有下划线开头的,称为元数据,反映了当前的基本信息。
"_index": "customer" 表明该数据在哪个数据库下;
"_type": "external" 表明该数据在哪个类型下;
"_id": "1" 表明被保存数据的id;
"_version": 1, 被保存数据的版本
"result": "created" 这里是创建了一条数据,如果重新put一条数据,则该状态会变为updated,并且版本号也会发生变化。2.post请求
POST http://192.168.56.10:9200/customer/external/
区别:
- POST新增,如果不指定id,会自动生成id。指定id就会修改这个数据,并新增版本号;
- PUT可以新增也可以修改。PUT必须指定id;由于PUT需要指定id,我们一般用来做修改操作,不指定id会报错。
3.查看文档
Get http://192.168.56.10:9200/customer/external/1
{
"_index": "customer",//在哪个索引
"_type": "external",//在哪个类型
"_id": "1",//记录id
"_version": 3,//版本号
"_seq_no": 6,//并发控制字段,每次更新都会+1,用来做乐观锁
"_primary_term": 1,//同上,主分片重新分配,如重启,就会变化
"found": true,
"_source": {
"name": "John Doe"
}
}4.更新文档
post http://192.168.56.10:9200/customer/external/1/_update
区别:
-
当PUT请求带id,且有该id数据存在时,会更新文档;
-
当POST请求带id,与PUT相同,该id数据已经存在时,会更新文档;
这两种请求类似,即带id,且数据存在,就会执行更新操作。
5.删除文档或索引
1.删除文档
delete http://192.168.56.10:9200/customer/external/1
2.删除索引
delete http://192.168.56.10:9200/customer
6.eleasticsearch的批量操作——bulk
语法格式:
{action:{metadata}}\n //例如index保存记录,update更新
{request body }\n
{action:{metadata}}\n
{request body }\n1.指定索引和类型的批量操作

2.对所有索引执行批量操作
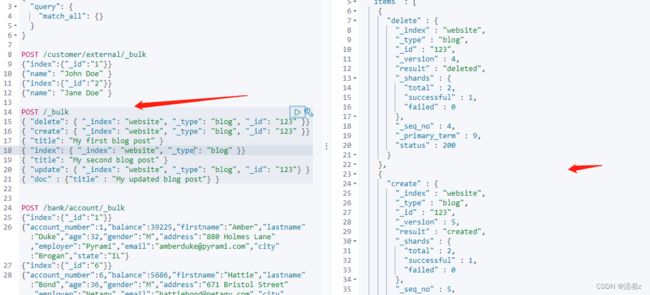
3.总结
这里的批量操作,当发生某一条执行发生失败时,其他的数据仍然能够接着执行,也就是说彼此之间是独立的。
bulk api以此按顺序执行所有的action(动作)。如果一个单个的动作因任何原因失败,它将继续处理它后面剩余的动作。
当bulk api返回时,它将提供每个动作的状态(与发送的顺序相同),所以您可以检查是否一个指定的动作是否失败了。
ElastiSearch进阶检索
参考官方文档
1.Query DSL
参考官网
1.基本语法
GET bank/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 5,
"sort": [
{
"account_number": {
"order": "desc"
},
"balance": {
"order": "asc"
}
}
]
}
# match_all 查询类型【代表查询所有的所有】,es中可以在query中组合非常多的查询类型完成复杂查询;
# from+size 限定,完成分页功能;从第几条数据开始,每页有多少数据
# sort 排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准;2.部分字段
GET bank/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 5,
"sort": [
{
"account_number": {
"order": "desc"
}
}
],
"_source": ["balance","firstname"]
}
# _source 指定返回结果中包含的字段名3.match-匹配查询
非文本
GET bank/_search
{
"query": {
"match": {
"account_number": 20
}
}
}
# 查找匹配 account_number 为 20 的数据 非文本推荐使用 term模糊查询-文本字符串
GET bank/_search
{
"query": {
"match": {
"address": "mill lane"
}
}
}
# 查找匹配 address 包含 mill 或 lane 的数据精确匹配-文本字符串
GET bank/_search
{
"query": {
"match": {
"address.keyword": "288 Mill Street"
}
}
}
# 查找 address 为 288 Mill Street 的数据。
# 这里的查找是精确查找,只有完全匹配时才会查找出存在的记录,
# 如果想模糊查询应该使用match_phrase 短语匹配4.match_phrase-短语匹配
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill lane"
}
}
}
# 这里会检索 address 匹配包含短语 mill lane 的数据5.multi_math-多字段匹配
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill",
"fields": [
"city",
"address"
]
}
}
}
# 检索 city 或 address 匹配包含 mill 的数据,会对查询条件分词6.bool-复合查询
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "M"
}
},
{
"match": {
"address": "mill"
}
}
]
}
}
}
# 查询 gender 为 M 且 address 包含 mill 的数据复合语句可以合并,任何其他查询语句,包括符合语句。这也就意味着,复合语句之间
可以互相嵌套,可以表达非常复杂的逻辑。
must:必须达到must所列举的所有条件
must_not,必须不匹配must_not所列举的所有条件。
should,应该满足should所列举的条件。
7.filter-结果过滤
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "mill"
}
}
],
"filter": {
"range": {
"balance": {
"gte": "10000",
"lte": "20000"
}
}
}
}
}
}
# 这里先是查询所有匹配 address 包含 mill 的文档,
# 然后再根据 10000<=balance<=20000 进行过滤查询结果8.term-精确检索
GET bank/_search
{
"query": {
"term": {
"age": "28"
}
}
}
# 查找 age 为 28 的数据9.Aggregation-执行聚合
具体参考官方文档

Elasticsearch-分词
1.安装ik分词器
# 进入挂载的插件目录 /mydata/elasticsearch/plugins
cd /mydata/elasticsearch/plugins
# 安装 wget 下载工具
yum install -y wget
# 下载对应版本的 IK 分词器(这里是7.6.2)
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip检查容器安装效果
# 进入容器内部
docker exec -it elasticsearch /bin/bash
# 查看 es 插件目录
ls /usr/share/elasticsearch/plugins
# 可以看到 elasticsearch-analysis-ik-7.6.2.zip2.解压
# 进入到 es 的插件目录
cd /mydata/elasticsearch/plugins
# 解压到 plugins 目录下的 ik 目录
unzip elasticsearch-analysis-ik-7.6.2.zip -d ik
# 删除下载的压缩包
rm -f elasticsearch-analysis-ik-7.6.2.zip
# 修改文件夹访问权限
chmod -R 777 ik/3.查看安装的ik插件
# 进入 es 容器内部
docker exec -it elasticsearch /bin/bash
# 进入 es bin 目录
cd /usr/share/elasticsearch/bin
# 执行查看命令 显示 ik
elasticsearch-plugin list
# 退出容器
exit
# 重启 Elasticsearch
docker restart elasticsearch4.可以在Xftp操作
将ik分词器下载到本地,拖进虚拟机文件夹下。 解压
解压
5.测试分词器

2.自定义分词库
1.nginx 中自定义分词文件
echo "黑鱼泡" > /mydata/nginx/html/fenci.txt2.给 es 配置自定义词库
# 1. 打开并编辑 ik 插件配置文件
vim /mydata/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml修改以下
IK Analyzer 扩展配置
http://192.168.56.10:8081/fenci.txt
3.重启 elasticsearch 容器
docker restart elasticsearch
4.测试自定义词库
会看到这是一个词出现。