微服务第六章-分布式搜索elasticsearch搜索:索引库创建增删RestAPi、文档创建增删RestApi
随着数据量的庞大,传统的mysql数据库难以满足我们的业务需求了,微服务技术下都会用到一种分布式搜索技术
初识elasticsearch
了解ES,比如搜索手机、spring、查询到的信息比如搜iphone会高亮显示
ES还包含了好几个组件,比如线上数据日志,监控cpu,内存等
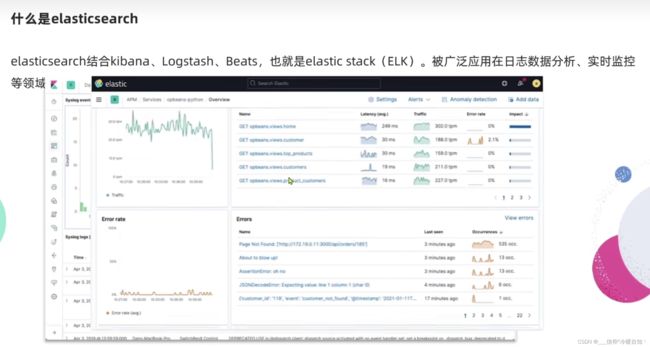
只有ES不可替代,别的都可以 ,比如谷歌在展示、数据抓取有自己的技术

ES底层实现是一个叫lucene的技术
lucene可以理解为是一个jar包,只限于java语言
ES就是基于Lucene实现的二次开发


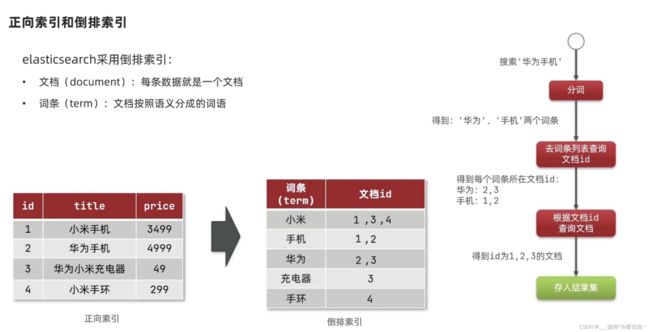
倒排索引
传统数据库查询,字段添加索引,模糊查询的话索引就失效了,那么就会逐条去查询,判断是否符合条件,如果有1百万条数据,可能就得查询100万次

词条可以建立索引,根据词条查询更快
倒排索引经过了两次检索:
- 第一次是根据用户输入内容的词条去词条列表中寻找并找到对应的文档id
- 第二次是拿到文档id去库表里找文档
- 虽然是两次,但是每次都经历了索引查询,比逐条查询效率高(数据量大的时候)
在正向索引中,我要找包含手机的信息,非索引字段得一行一行的看,找到titile看是否包含手机,包含放到结果集,不包含废弃,是先找到文档然后看词条要求,是根据文档找词
而倒排索引是反过来的,是基于词条创建索引,然后关联到文档,查询的时候是先找到词,根据词条找到对应的文档id,是根据词找文档

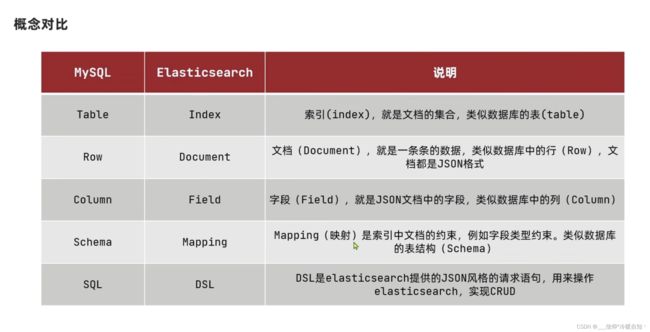
ES的一些概念
不同类型,放到不同的索引库

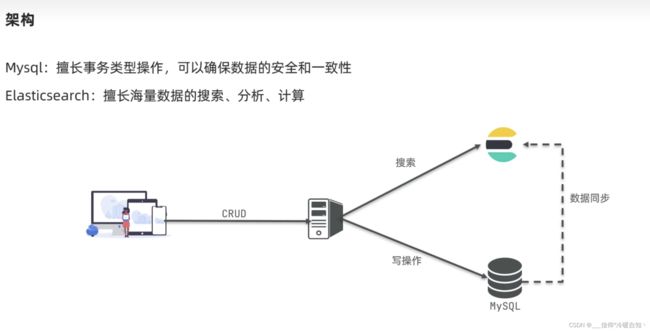

安装ES、kbana
首先需要创建一个网络,因为将来我们的Es和kbana还要做互联,将来还有可能不需要kbana,有可能只是需要es,这里操作如何单独部署
1.部署单点es
1.1.创建网络
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
1.2.加载镜像
这里我们采用elasticsearch的7.12.1版本的镜像,课前资料提供了镜像的tar包:

运行命令加载即可:
# 导入数据
docker load -i es.tar同理还有kibana的tar包也需要这样做。
1.3.运行
运行docker命令,部署单点es:
docker run -d --name es -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
命令解释
两个端口9200就是http协议端口,将来供我们用户访问的
9300容器节点之间互联的端口
-e "cluster.name=es-docker-cluster":设置集群名称
-e "http.host=0.0.0.0":监听的地址,可以外网访问
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小
-e "discovery.type=single-node":非集群模式
-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录
-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录
-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录
--privileged:授予逻辑卷访问权
--network es-net :加入一个名为es-net的网络中
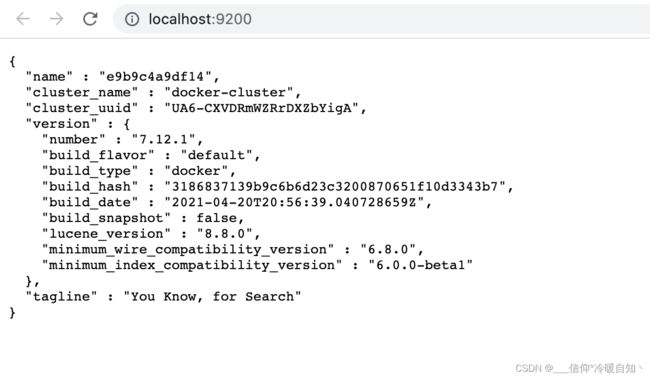
-p 9200:9200:端口映射配置在浏览器中输入:http://localhost:9200 即可看到elasticsearch的响应结果:
2.部署kibana
kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习。
2.1.部署
运行docker命令,部署kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
--network es-net :加入一个名为es-net的网络中,与elasticsearch在同一个网络中
-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以 用容器名 直接访问elasticsearch
-p 5601:5601:端口映射配置kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana
查看运行日志,当查看到下面的日志,说明成功:
此时,在浏览器输入地址访问:http://localhost:5601,即可看到结果
两种方案,我们选第二种自己导入数据,另一种是用官方的
Dev Tools控制台,可以让我们非常方便的去发送DSL请求
本质就是发送一个Rest请求到ES当中 ,就是一个http请求

-analyze分析 ,post 、get是发送rest的请求
ES默认分词器:standard
text:带边的是文本,要分词的数据内容
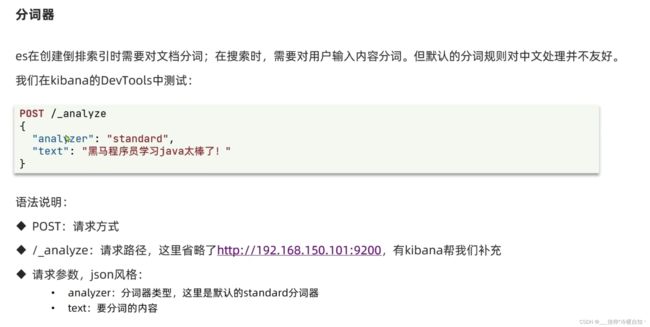
分词器分词中文是有问题的,是按逐个字去分词的
标准分词器、english、chinese分词器这些都不可以,英文分的还可以
一般中文分词用ik分词器,逐词去分
3.安装IK分词器
3.1.在线安装ik插件(较慢)
# 进入容器内部
docker exec -it elasticsearch /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
#退出
exit
#重启容器
docker restart elasticsearch3.2.离线安装ik插件(推荐)
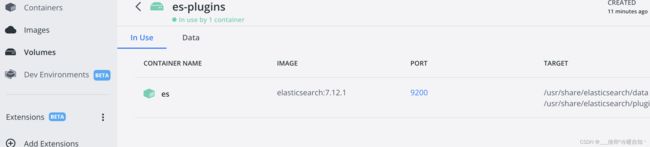
1)查看数据卷目录
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins显示结果:
[
{
"CreatedAt": "2022-05-06T10:06:34+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data这个目录中。
2)解压缩分词器安装包
下面我们需要把课前资料中的ik分词器解压缩,重命名为ik
3)上传到es容器的插件数据卷中
也就是/var/lib/docker/volumes/es-plugins/_data:

我这里没有虚拟机,直接利用docker复制的方法,elasticsearch可以用id,它自己的id,复制完直接docker restart id就可以了
docker cp /Users/yuhaiyang/Documents/py es:/usr/share/elasticsearch/plugins/因为我做了数据卷关在,再小鲸鱼是可以看见的,如果传错了导致ES容器起不来,可以去小鲸鱼里删除,比如我传错了,传承ik.zip导致服务起不来,exec也进不去,来这里删掉ik.zip就好了,因为是挂载的,可以同步,别的方法目前不知道了
4)重启容器
# 4、重启容器
docker restart es
# 查看es日志
docker logs -f es5)测试:
IK分词器包含两种模式:
-
ik_smart:最少切分,比如“太棒了”,就分出一个,内存占用少 -
ik_max_word:最细切分,比如“太棒了”,可能分出三个,太棒,太棒了,了,内存占用多
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "黑马程序员学习java太棒了"
}结果:
{
"tokens" : [
{
"token" : "黑马",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "程序员",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "程序",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "员",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "学习",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "java",
"start_offset" : 7,
"end_offset" : 11,
"type" : "ENGLISH",
"position" : 5
},
{
"token" : "太棒了",
"start_offset" : 11,
"end_offset" : 14,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "太棒",
"start_offset" : 11,
"end_offset" : 13,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "了",
"start_offset" : 13,
"end_offset" : 14,
"type" : "CN_CHAR",
"position" : 8
}
]
}分词器,底层是有个字典的,但是肯定不能包含所有的词语,我们可以自己去扩展,比如白嫖可能就没有,会分成白,嫖两个字,这肯定不行的,还有白嫖的课程,的可能会单独分一个词,没意义
自定义配置添加词库

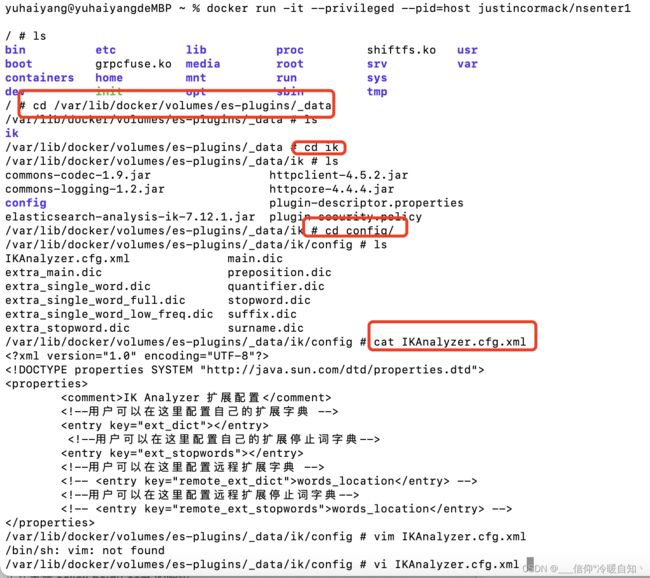
vi命令可以修改如下

这里默认是没有的,可以加上

这两个文件是在当前文件的所在目录呢,返回发现没有,那我们就新建两个文件,用touch命令新建

stopword.dic不用新建,里边就有,我们可以加入一些汉语之类的无意义的词,比如嘤嘤嘤,的,了

配置好了后就重启,让它生效
docker restart es再次请求就会发现分词效果成功了
总结:

索引库操作
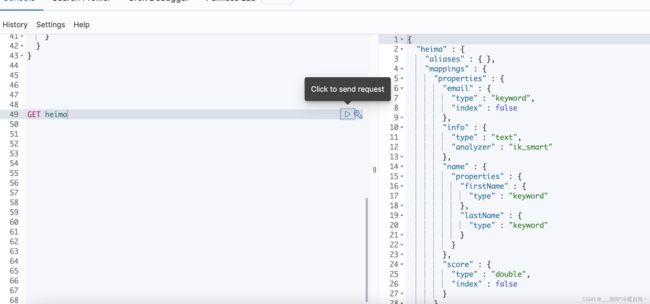
mapping映射属性
需要拆分的就是text,不需要拆分的就是keyword
index是否创建倒排索引,如果不写,默认每个字段都有倒排索引,也就意味着每个字段都有搜索功能,实际开发过程中不是每个字段都要搜索的,某个字段不参与搜索,就把该字段设置为false,否则就不用管了,默认就是true
analyzer分词器,只有text需要用,其他类型都不需要
properties,该字段的子字段,比如name下的firstName


DSL语法
索引库名称:是随便定义的
字符串需要分词用 text 不需要分词用keyword,类型用了text就必须指定分词器,有子属性的话,那么就是object类型
mappings 映射
第一个properties 代表接下来就是具体的字段了,如下,索引库就创建成功了
索引库的CRUD

遵循restful风格
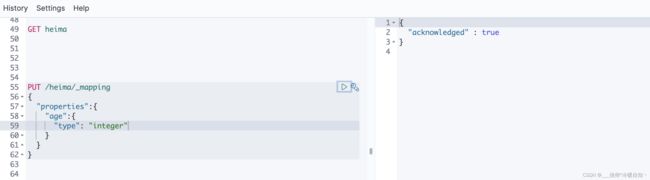
修改:事实上索引库是不允许修改的,因为索引库创建完后mapping映射都已经定义好了,我们会基于这些mapping去创建倒排索引,如果去修改一个字段,就会导致原有的倒排索引就会失效
所以,在ES里边是禁止修改索引库的
但是可以添加新字段
put 名字 映射,代表我要改索引库的映射,然后就可以添加新的字段了
注意:一定要是一个全新的字段名字,否则就认为是再改一个已经存在的字段了,执行会报错的非法参数异常,不允许修改

例如:
delete /heima 执行完后,再get 就会报404 找不到嘞

文档操作
新增文档
如果不加id,将来ES就会随机生成一个,这不是我们希望的,所以不要忘了

插入成功

查询文档

version:版本控制,每做一次版本修改,版本就会+1
source就是我们插入的原始文档

删除文档

在查询就会找不到嘞

在插入,查询,就会发现版本已经变成3了
插入第一次,版本为1,删除,版本为2,再插入版本为3 ,就是每次写操作都会导致版本自增1

修改文档
全量修改,会根据我们传的id,去索引库里找到旧的文档,然后把它干掉,然后再把新的添加进去
如果说传的id在索引库里本来就不存在呢?删除不会执行,新增不会受影响,所以我们认为这种方式技能新增,也能修改


把id改了,让索引库里没有这个id就是新增了

方式二:只更新一个字段,局部更新


RestAPI
用java代码操作ES

创建索引库
删除索引库
判断索引库是否存在

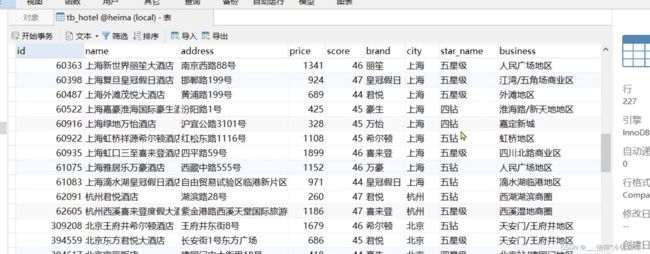
导入到mysql
注意:id这个字段在es里要设置成keyword,不参与分词,但是要CRUD,所以是需要索引的
经纬度是两个字段拼在一起的,是一个点,用geoPoint类型
注意:以后参与搜索是多个字段,实现在一个字段里搜索多个业务
copy_to ,将字段拷贝到all里,到时候搜索的时候,就可以支持多个条件当做一个字段搜索了,比如:酒店,如家,两个调价一起搜索
PUT /hotel
{
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score": {
"type": "integer"
},
"brand": {
"type": "keyword",
"copy_to": "all"
},
"city": {
"type": "keyword"
},
"starName": {
"type": "keyword"
},
"business": {
"type": "keyword",
"copy_to": "all"
},
"location": {
"type": "geo_point"
},
"pic": {
"type": "keyword",
"index": false
},
"all": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
版本和客户端版本保持一致,是7.12.1的

引入jar包后,发现有连个组件被定义成了7.6.2
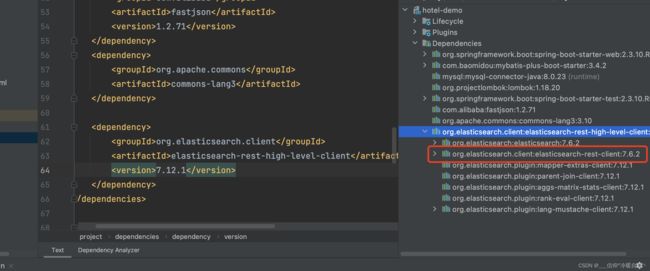
因为我们的项目是spring-boot项目,里边所有的依赖都会被spring-boot管理

所以在springboot环境下版本信息不是我们管理了,可以覆盖它,再次查询就会发现,版本都变成7.12.1了
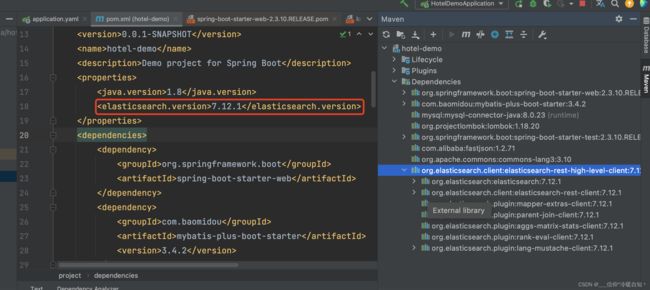
也就是说当我们要使用springboot环境下的ES的时候,一定要强制执行版本
初始化RestHighLevelClient

RequestOptions是请求头的一些信息,默认就行,indices就是index的复数,就是索引的意思,mapping_teplate是dsl语句的常量
indices返回的是操作索引库的API

执行完后,kanbal上执行get请求就可以获取到我们创建的hotel索引库了
删除、查询指定名字就行

总结:

RestClient操作文档


新增文档
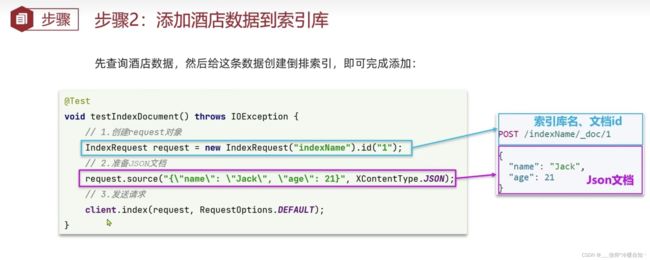
文档操作,直接index就可以,创建倒排索引了,indeices代表索引库操作
我们在查询数据库的时候,数据库表有一份bean,doc文档的应该也有一份bean对应es里的字段
这里有经纬度,我们在构造函数里直接将他们两个拼接在一起 ,以,隔开
注意,测试类注入需要添加springboot的注解@SpringBootTest

然后就可以去Dev Tools上查询了,发现已经成功了
查询文档

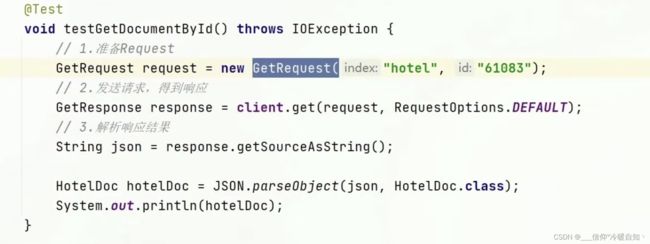
删除文档

修改文档


批量导入文档
将来数据库有成千上万条数据,就不能一次新增一条了,需要批量插入
BlukRequest不需要参数,只是负责封装,把别的请求捆绑到一起了
用一个链式编程,id.source,就是把N个请求都放到bulk里边,一起提交,client才是发送请求,br只是add
@Test
void insertAllDoc() throws IOException {
BulkRequest br = new BulkRequest();
List list = hotelService.list();
for (int i=0;i 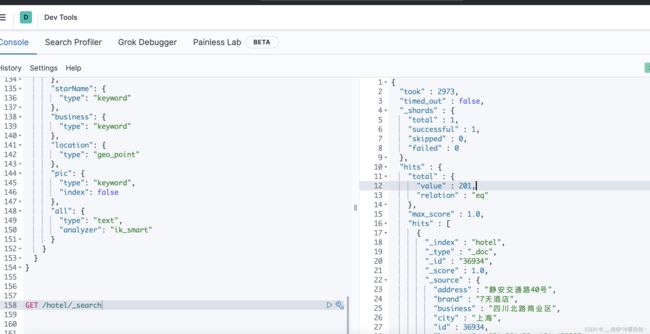
get /hotel/_search总共查询了201条数据,说明批量导入成功了