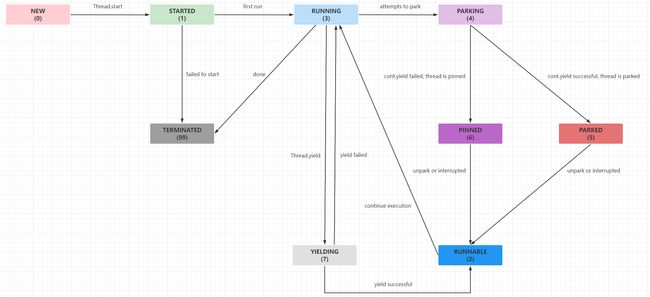
JDK19虚拟线程
JDK19中的虚拟线程就是业界的协程
因为协程是用户态的,线程是操作系统内核态的,所以协程仍然是基于的是线程,一个线程可以承载多个协程,但如果所有协程都只基于一个线程,哪有效率肯定不会高,所以JDK19中协程会给予forkJoinPool线程池,利用多个线程来支持协程的运行,并且利用forkJoinPoll而不是不同的ThreadPoolExecutor
JDK19中的协程底层是基于ForkJoinPool的,相当于,我们在利用协程执行Runnable时,底层会把Runnable提交到一个ForkJoinPool中去执行,我们可以通过:
- -Djdk.virtualThreadScheduler.parallelism=1
- -Djdk.virtualThreadScheduler.maxPoolSize=1
这俩个参数来设置ForkJoinPool的核心线程和最大线程数
parallelism默认为Runtime.getRuntime().availableProcessors() (cpu的线程数)
maxPoolSize默认为256
ForkJoinPool中的线程在执行任务过程中,一旦线程阻塞了,比如sleep、lock、io操作时,那么这个线程就会去执行ForkJoinPool中的其他任务,从而可以做到一个线程在执行过程中,也能并发的执行多个任务,达到协程并发执行任务的效果。
简介
虚拟线程(virtual Threads)具有和Go语言的goroutines和Erlang语言进程类似的方式,它们是用户模式(user-mode)线程的一种形式
在过去java中常常使用线程池来进行平台线程的共享以提高对计算机硬件的使用率,但在这种异步风格中,请求的每个阶段可能在不同地的线程桑执行,每个线程一交错的方式运行属于不同阶段的请求,与java平台设计不协同而导致
- 堆栈跟踪不提供可用上下文
- 调试器不能单步请求处理逻辑
- 分析器不能将操作的成本与其调用方式关联
而虚拟线程既保持与平台设计兼容,同时又能最佳地利用硬件从而不影响可伸缩性能.虚拟线程是由JDK而非操作系统提供的线程轻量级实现
- 虚拟线程是没有绑定到特点操作系统线程的线程
- 平台线程是以传统方式实现的线程,作为围绕操作系统线程的简单包装
摘要
向java平台引入虚拟线程.虚拟线程是轻量级线程,它可以大大减少编写,维护和观察高吞吐量并发应用程序的工作量
thread-per-request style
服务器应用程序通常处理彼此独立的并发用户请求,因此应用程序通过在整个请求持续期间为该请求分配一个线程来处理请求是有意义的。这种按请求执行线程的 style 易于理解、易于编程、易于调试和配置,因为它使用平台的并发单元来表示应用程序的并发单元。
服务器应用程序的可伸缩性受到利特尔定律(Little's Law)的支配,该定律关系到延迟、并发性和吞吐量: 对于给定的请求处理持续时间(延迟) ,应用程序同时处理的请求数(并发性) 必须与到达速率(吞吐量) 成正比增长。
例如,假设一个平均延迟为 50ms 的应用程序通过并发处理 10 个请求实现每秒 200 个请求的吞吐量。为了使该应用程序的吞吐量达到每秒 2000 个请求,它将需要同时处理 100 个请求。如果在请求持续期间每个请求都在一个线程中处理,那么为了让应用程序跟上,线程的数量必须随着吞吐量的增长而增长。
不幸的是,可用线程的数量是有限的,因为 JDK 将线程实现为操作系统(OS)线程的包装器。操作系统线程代价高昂,因此我们不能拥有太多线程,这使得实现不适合每个请求一个线程的 style 。
如果每个请求在其持续时间内消耗一个线程,从而消耗一个 OS 线程,那么线程的数量通常会在其他资源(如 CPU 或网络连接)耗尽之前很久成为限制因素。JDK 当前的线程实现将应用程序的吞吐量限制在远低于硬件所能支持的水平。即使在线程池中也会发生这种情况,因为池有助于避免启动新线程的高成本,但不会增加线程的总数。
asynchronous style
一些希望充分利用硬件的开发人员已经放弃了每个请求一个线程(thread-per-request) 的 style ,转而采用线程共享(thread-sharing ) 的 style 。
请求处理代码不是从头到尾处理一个线程上的请求,而是在等待 I/O 操作完成时将其线程返回到一个池中,以便该线程能够处理其他请求。这种细粒度的线程共享(其中代码只在执行计算时保留一个线程,而不是在等待 I/O 时保留该线程)允许大量并发操作,而不需要消耗大量线程。
虽然它消除了操作系统线程的稀缺性对吞吐量的限制,但代价很高: 它需要一种所谓的异步编程 style ,采用一组独立的 I/O 方法,这些方法不等待 I/O 操作完成,而是在以后将其完成信号发送给回调。如果没有专门的线程,开发人员必须将请求处理逻辑分解成小的阶段,通常以 lambda 表达式的形式编写,然后将它们组合成带有 API 的顺序管道(例如,参见 CompletableFuture,或者所谓的“反应性”框架)。因此,它们放弃了语言的基本顺序组合运算符,如循环和 try/catch 块。
在异步样式中,请求的每个阶段可能在不同的线程上执行,每个线程以交错的方式运行属于不同请求的阶段。这对于理解程序行为有着深刻的含义:
堆栈跟踪不提供可用的上下文
调试器不能单步执行请求处理逻辑
分析器不能将操作的成本与其调用方关联。
当使用 Java 的流 API 在短管道中处理数据时,组合 lambda 表达式是可管理的,但是当应用程序中的所有请求处理代码都必须以这种方式编写时,就有问题了。这种编程 style 与 Java 平台不一致,因为应用程序的并发单元(异步管道)不再是平台的并发单元。
使用虚拟线程保留thread-per-request style
为了使应用程序能够在与平台保持和谐的同时进行扩展,我们应该通过更有效地实现线程来努力保持每个请求一个线程的 style ,以便它们能够更加丰富。
操作系统无法更有效地实现 OS 线程,因为不同的语言和运行时以不同的方式使用线程堆栈。然而,Java 运行时实现 Java 线程的方式可以切断它们与操作系统线程之间的一一对应关系。正如操作系统通过将大量虚拟地址空间映射到有限数量的物理 RAM 而给人一种内存充足的错觉一样,Java 运行时也可以通过将大量虚拟线程映射到少量操作系统线程而给人一种线程充足的错觉。
- 虚拟线程是没有绑定到特定操作系统线程的线程。
- 平台线程是以传统方式实现的线程,作为围绕操作系统线程的简单包装。
thread-per-request样式的应用程序代码可以在整个请求期间在虚拟线程中运行,但虚拟线程只在cpu上执行计算时,使用操作系统线程.其结果是与异步样式相同的可伸缩性,除了它是透明实现的
当虚拟线程中运行的代码调用java.*API中的阻塞I/O操作时(传统io就是阻塞io),运行一个非阻塞操作的系统调用,并自动挂起线程,直到稍后恢复.
对于java开发人员来说,虚拟线程是创建成本低廉,数量几乎无限多的线程,硬件利用率最佳,允许高水平的并发性,从而提高吞吐量
虚拟线程是廉价和丰富的,因此永远不应该被共享(即使用线程池) : 应该为每个应用程序任务创建一个新的虚拟线程。
因此,大多数虚拟线程的寿命都很短,并且具有浅层调用堆栈,执行的操作只有单个 HTTP 客户机调用或单个 JDBC 查询那么少。相比之下,平台线程是重量级和昂贵的,因此经常必须共享。它们往往是长期存在的,具有深度调用堆栈,并且在许多任务之间共享。
总之,虚拟线程保留了可靠的 thread-per-request style ,这种 style 与 Java 平台的设计相协调,同时又能最佳地利用硬件。使用虚拟线程并不需要学习新的概念,尽管它可能需要为应对当今线程的高成本而养成的忘却习惯。虚拟线程不仅可以帮助应用程序开发人员ーー它们还可以帮助框架设计人员提供易于使用的 API,这些 API 与平台的设计兼容,同时又不影响可伸缩性。
说明
如今,java.lang 的每一个实例。JDK 中的线程是一个平台线程。平台线程在底层操作系统线程上运行 Java 代码,并在代码的整个生命周期中捕获操作系统线程。平台线程的数量仅限于操作系统线程的数量。
虚拟线程是 java.lang 的一个实例。在基础操作系统线程上运行 Java 代码,但在代码的整个生命周期中不捕获该操作系统线程的线程。这意味着许多虚拟线程可以在同一个 OS 线程上运行它们的 Java 代码,从而有效地共享它们。平台线程垄断了一个珍贵的操作系统线程,而虚拟线程却没有。虚拟线程的数量可能比操作系统线程的数量大得多。
虚拟线程是由 JDK 而非操作系统提供的线程的轻量级实现。它们是用户模式(user-mode)线程的一种形式,已经在其他多线程语言中取得了成功(例如,Go 中的 goroutines 和 Erlang 的进程)。在 Java 的早期版本中,用户模式线程甚至以所谓的“绿线程”为特色,当时 OS 线程还不成熟和普及。然而,Java 的绿色线程都共享一个 OS 线程(M: 1调度) ,并最终被平台线程超越,实现为 OS 线程的包装器(1:1调度)。虚拟线程采用 M: N 调度,其中大量(M)虚拟线程被调度在较少(N)操作系统线程上运行。
虚拟线程vs平台线程
开发人员可以选择使用虚拟线程还是平台线程。下面是一个创建大量虚拟线程的示例程序。该程序首先获得一个 ExecutorService,它将为每个提交的任务创建一个新的虚拟线程。然后,它提交10000项任务,等待所有任务完成:
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 10000).forEach(i -> {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
return i;
});
});
} // executor.close() is called implicitly, and waits本例中的任务是简单的代码(休眠一秒钟) ,现代硬件可以轻松支持10,000个虚拟线程并发运行这些代码。在幕后,JDK 在少数操作系统线程上运行代码,可能只有一个线程。
如果这个程序使用 ExecutorService 为每个任务创建一个新的平台线程,比如 Executors.newCachedThreadPool () ,那么情况就会大不相同。ExecutorService 将尝试创建10,000个平台线程,从而创建10,000个 OS 线程,程序可能会崩溃,这取决于计算机和操作系统。
相反,如果程序使用从池中获取平台线程的 ExecutorService (例如 Executors.newFixedThreadPool (200)) ,情况也不会好到哪里去。ExecutorService 将创建200个平台线程,由所有10,000个任务共享,因此许多任务将按顺序运行,而不是并发运行,而且程序将需要很长时间才能完成。对于这个程序,一个有200个平台线程的池只能达到每秒200个任务的吞吐量,而虚拟线程达到每秒10,000个任务的吞吐量(在充分预热之后)。此外,如果示例程序中的10000被更改为1000000,那么该程序将提交1,000,000个任务,创建1,000,000个并发运行的虚拟线程,并且(在足够的预热之后)实现大约1,000,000任务/秒的吞吐量。
如果这个程序中的任务执行一秒钟的计算(例如,对一个巨大的数组进行排序)而不仅仅是休眠,那么增加超出处理器核心数量的线程数量将无济于事,无论它们是虚拟线程还是平台线程。
虚拟线程并不是更快的线程ーー它们运行代码的速度并不比平台线程快。它们的存在是为了提供规模(更高的吞吐量) ,而不是速度(更低的延迟) 。它们的数量可能比平台线程多得多,因此根据 Little’s Law,它们能够实现更高吞吐量所需的更高并发性。
换句话说,虚拟线程可以显著提高应用程序的吞吐量,在如下情况时:
并发任务的数量很多(超过几千个)
工作负载不受 CPU 限制,因为在这种情况下,比处理器核心拥有更多的线程并不能提高吞吐量
虚拟线程有助于提高典型服务器应用程序的吞吐量,因为这类应用程序由大量并发任务组成,这些任务花费了大量时间等待。
虚拟线程可以运行平台线程可以运行的任何代码。特别是,虚拟线程支持线程本地变量和线程中断,就像平台线程一样。这意味着处理请求的现有 Java 代码很容易在虚拟线程中运行。许多服务器框架将选择自动执行此操作,为每个传入请求启动一个新的虚拟线程,并在其中运行应用程序的业务逻辑。
使用
下面是一个服务器应用程序示例,它聚合了另外两个服务的结果。假设的服务器框架(未显示)为每个请求创建一个新的虚拟线程,并在该虚拟线程中运行应用程序的句柄代码。然后,应用程序代码创建两个新的虚拟线程,通过与第一个示例相同的 ExecutorService 并发地获取资源:
void handle(Request request, Response response) {
var url1 = ...
var url2 = ...
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
var future1 = executor.submit(() -> fetchURL(url1));
var future2 = executor.submit(() -> fetchURL(url2));
response.send(future1.get() + future2.get());
} catch (ExecutionException | InterruptedException e) {
response.fail(e);
}
}
String fetchURL(URL url) throws IOException {
try (var in = url.openStream()) {
return new String(in.readAllBytes(), StandardCharsets.UTF_8);
}
}这样的服务器应用程序使用简单的阻塞代码,可以很好地扩展,因为它可以使用大量虚拟线程。
NewVirtualThreadPerTaskExector ()并不是创建虚拟线程的唯一方法。新的 java.lang.Thread.Builder。可以创建和启动虚拟线程。此外,结构化并发提供了一个更强大的 API 来创建和管理虚拟线程,特别是在类似于这个服务器示例的代码中,通过这个 API,平台及其工具可以了解线程之间的关系。
虚拟线程是一个预览 API,默认情况下是禁用的
上面的程序使用 Executors.newVirtualThreadPerTaskExector ()方法,因此要在 JDK 19上运行它们,必须启用以下预览 API:
使用javac --release 19 --enable-preview Main.java编译该程序,并使用 java --enable-preview Main 运行该程序;或者:
在使用源代码启动程序时,使用 java --source 19 --enable-preview Main.java 运行程序; 或者:
在使用 jshell 时,使用 jshell --enable-preview 启动它。
不要共享(pool)虚拟线程
开发人员通常会将应用程序代码从传统的基于线程池的 ExecutorService 迁移到每个任务一个虚拟线程的 ExecutorService。与所有资源池一样,线程池旨在共享昂贵的资源,但虚拟线程并不昂贵,而且从不需要共享它们。
开发人员有时使用线程池来限制对有限资源的并发访问。例如,如果一个服务不能处理超过20个并发请求,那么通过提交给大小为 20 的池的任务将确保执行对该服务的所有访问。因为平台线程的高成本使得线程池无处不在,所以这个习惯用法也变得无处不在,但是开发人员不应该为了限制并发性而将虚拟线程集中起来。应该使用专门为此目的设计的构造(如信号量semaphores)来保护对有限资源的访问。这比线程池更有效、更方便,也更安全,因为不存在线程本地数据从一个任务意外泄漏到另一个任务的风险。
总结
虚拟线程提供了使用线程池共享平台线程以达到异步之外的另一种更加可调试、可跟踪、可分析的方式。
曾经 Java 开发者们面对GO对高并发的友好支持只能干瞪眼,而现在让我们拥抱属于 Java 的高并发未来。