目标检测模型总结
1 问题概况
1.1 定义
目标检测的任务是对画面中的目标进行定位和分类。定位是指回归目标的矩形框,分类是指对目标框进行类别区分。
1.2 主要问题
目标检测任务主要解决以下几个问题:目标的种类和数量、目标的尺寸、外界的干扰因素、特定场景任务等;
2 方法概况
目标检测算法可以分为传统目标检测算法和基于深度学习的目标检测算法。其中传统的目标检测算法的主要工作集中在手工设计中低层面的特征提取算法,如SIFT、HOG特征等;基于深度学习的目标检测算法的主要功能是通过网络的设计,结合数据和loss的使用,使特征提取这个工作智能化,并将整个目标检测任务简单化。近些年随着计算领域的突破和深度学习算法架构的突破,基于深度学习的算法性能大大优于传统的方法,传统的算法已经渐渐退出历史舞台了。不过很多深度学习的方法也是基于传统算法的思路去做实现的,接下来文章会给大家介绍传统算法和深度学习算法的发展过程,让大家对目标检测算法有个大致的概念。
2.1 传统目标检测算法
传统目标检测算法流程示意图如下所示:

候选框提取:通过滑动窗口算法、SS算法等选取目标候选框;
特征提取:手工设计算法提取特征,如VJ、HOG特征等算法,传统方法的主要工作都集中在底层和中层特征提取的算法设计上;
分类器:通过SVM等算法对每一个候选框进行分类;
NMS非极大值抑制:
- 将所有的候选框使用分类器按类别划分,并剔除背景类,因为背景类无需NMS;
- 对每个物体类中的边界框(B_BOX),按照分类置信度降序排列;
- 在某一类中,选择置信度最高的边界框B_BOX1,将B_BOX1从输入列表中去除,并加入输出列表;
- 逐个计算B_BOX1与其余B_BOX2的交并比IoU,若IoU(B_BOX1,B_BOX2) > 阈值TH,则在输入去除B_BOX2;
- 重复上述3、4两个步骤,直到输入列表为空,完成一个物体类的遍历;
- 重复上述1、2、3、4四个步骤,直到所有物体类的NMS处理完成;
2.2 基于深度学习的目标检测算法
目前基于深度学习的目标算法技术方向可以分为基于anchor base和基于anchor free的方法。anchor base和anchor free 的区别在于,有没有使用anchor来提取候选框。目标检测领域的发展从anchor free到anchor base,现在又有回到anchor-free的趋势,学术界技术的迭代更新也引导着工业界的变革。其中基于anchor base的技术路线中又可以分为two-stage和one-stage的方法。
Anchor
Anchor也叫做锚,其实是一组预设的边界框用于在训练时学习真实的边框位置相对于预设边框的偏移。通俗点说就是预先设置目标可能存在的大概位置,然后再在这些预设边框的基础上进行精细化的调整。而它的本质就是为了解决标签分配的问题。
锚作为一系列先验框信息,其生成涉及以下几个部分:
- 用网络提取特征图的点来定位边框的位置;
- 用锚的尺寸来设定边框的大小;
- 用锚的长宽比来设定边框的形状;
通过设置不同尺度,不同大小的先验框,就有更高的概率出现对于目标物体有良好匹配度的先验框约束。
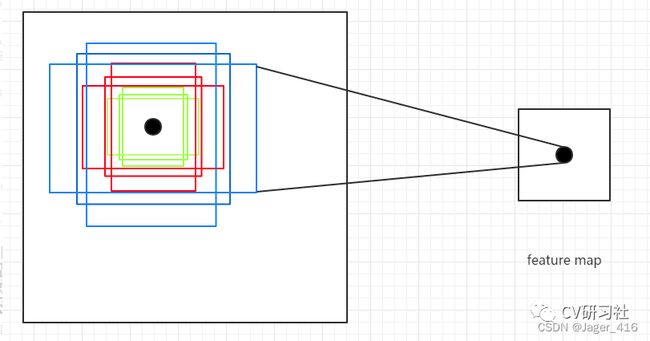
anchor(也被称为anchor box)是在训练之前,在训练集上利用k-means等方法聚类出来的一组矩形框,代表数据集中目标主要分布的长宽尺度。
Anchor Base
代表算法:CornerNet、ExtremeNet、CenterNet、FCOS等;
Anchor-Base即有先验锚框,先通过一定量的数据做聚类等方法得到一些锚框尺度与大小,然后结合先验锚框与预测偏移量得到预测锚框。
基于Anchor-Free的目标检测算法有两种方式:
- 关键点检测方法,通过定位目标物体的几个关键点来限定它的搜索空间;
- 通过目标物体的中心点来定位,然后预测中心到边界的距离。
最直接的好处就是不用在训练之前对当前训练数据聚类出多个宽高的anchor参数了。

Faster R-CNN-设置了3种尺度3种宽高ratio一共9个anchor提取候选框
Anchor Free
代表算法:Faster R-CNN、SSD、Yolo(2、3、4、5)等;
Anchor-Free即无先验锚框,直接通过预测具体的点得到锚框。
前几年目标检测领域一直被基于锚的检测器所统治,此类算法的流程可以分为三步:
- 在图像或者点云空间预设大量的anchor(2D/3D);
- 回归目标相对于anchor的四个偏移量;
- 用对应的anchor和回归的偏移量修正精确的目标位置;
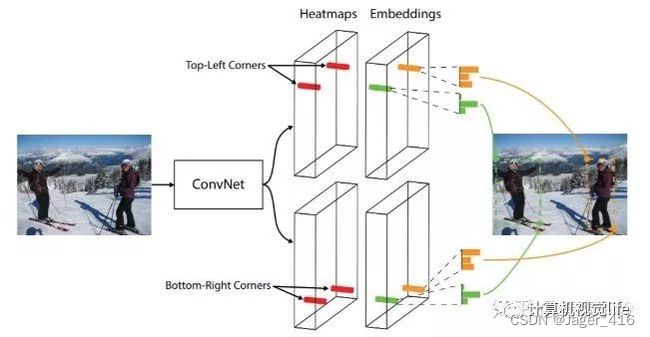
CornerNet直接预测每个点是左上、右下角点的概率,通过左上右下角点配对提取目标框。
Two-Stage(两阶段算法)
RCNN系列
RCNN系列网络是two-stage网络的经典之作,其中RCNN网络首次将CNN网络引入目标检测领域,是CNN在目标检测领域的开山之作。
下图是RCNN系列迭代示意图:

RCNN
论文地址:Girshick_Rich_Feature_Hierarchies_2014_CVPR_paper

算法流程:
- 候选区域生成:采用SS算法(Selective Search)方法为每一张图像生成1K~2K个候选区域
- 特征提取:对每个候选区域,使用深度卷积网络提取特征 (CNN)
- 类别判断:特征送入每一类的SVM 分类器,判别是否属于该类
- 位置精修:使用回归器精细修正候选框位置
改进点: - SS算法比滑动窗口更高效、精度更高;
不足: - SS算法还是很耗时;
- 四个模块基本是单独训练的,CNN使用预训练模型微调、SVM重头训练、边框回归重头训练、微调困难;
Fast RCNN
论文地址:https://arxiv.org/abs/1504.08083v2

算法流程:
- 同样是寻找一个在imagenet上训练过的预训练cnn模型(VGG16);
- 与rcnn一样,通过selective search在图片中提取2000个候选区域;
- 将一整个图片都输入cnn模型中,提取到图片的整体特征(共享卷积特征);
- 把候选区域映射到上一步cnn模型提取到的feature map里;
- 采用rol pooling层对每个候选区域的特征进行上采样,从而得到固定大小的feature map;
- 根据softmax loss和smooth l1 loss对候选区域的特征进行分类和回归调整的过程;
改进点:
- 共享卷积特征,大大提升了候选框特征提取效率;
- 把分类任务和回归任务一起输出;
不足: - 候选框提取SS算法还是太耗时了;
Faster RCNN
论文地址:https://arxiv.org/abs/1506.01497
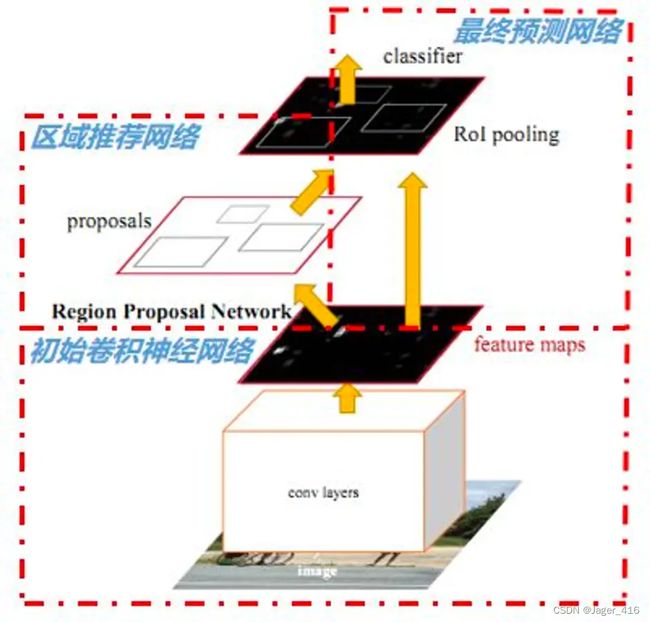
算法流程:Faster RCNN网络可以看做是RPN + Fast RCNN
整个网络流程与Fast RCNN类似,只是将其中耗费大量时间的区域建议网络(Region Proposal)SS算法修改为RPN网络直接提取候选框,并将其融入进整体网络中,使得综合性能有较大提高,在检测速度方面尤为明显。
改进点:
- 提出RPN网络取代SS算法;
不足: - 相比较one stage算法,速度慢,无法做到实时;
优点: - 网络精度高;
- RPN网络速度明显快于SS算法;
- 实现了真正的端到端的训练;
One-Stage(一阶段算法)
SSD
论文地址:https://arxiv.org/abs/1512.02325
SSD算法的全名是Single Shot MultiBox Detector,其是在是YOLO V1出来后,YOLO V2出来前的一款One-stage目标检测器。SSD用到了多尺度的特征图,在之后的YOLO V3的darknet53中,也是用到了多尺度特征图的思想。较浅层的特征图上,每个cell的感受野不是很大,所以适合检测较小的物体,而在较深的特征图上,每个cell的感受野就比较大了,适合检测较大的物体。
SSD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。如下图所示:

网络分为三部分:
- Backbone: VGG16用于图片特征提取的网络
- Extra: 用于引出多尺度特征图的网络
- Loc和cls: 用于框位置回归和目标分类的网络
SSD的特点:
- Single Shot Detection :Single shot指明了SSD算法属于One Stage算法,SSD模型在网络的前向运算中封装了定位和检测,从而显著提高了运算速度。
- 多尺度特征映射图(Multiscale Feature Maps):MultiBox指明了SSD是多框预测,SSD网络包含了多个卷积层,模型使用不同深度的卷积层输出特征映射图来定位和检测不同尺度的目标。
- 锚框(Anchors):在特征映射图的每个位置预先定义不同大小的矩形框,这些矩形框包含了不同的宽高比,它们用来匹配真实物体的矩形框。
YOLO 系列
YOLO系列算法出自Joseph Redmon之手,可以说是one-stage目标检测算法的奠基之作。YOLO全称you only look once,意思是把将类别分类和框回归的任务进行统一。从YOLOv1 到YOLOv3,作者完成了YOLO系列网络的基础框架搭建,后续的网络大部分(YOLOv4、YOLOv5、YOLObile和YOLOX等等)都是基于YOLOv3的网络做的一些修改。作者Joseph Redmon在2020年2月,在推文上宣布退出了CV领域(原因是军方邀请他观看了YOLOv3在军事无人机上的应用,作者认为这有违他的初衷)。在作者宣布退出CV界之后的4月23号和6月25号,YOLOv4和YOLOv5相续发表。
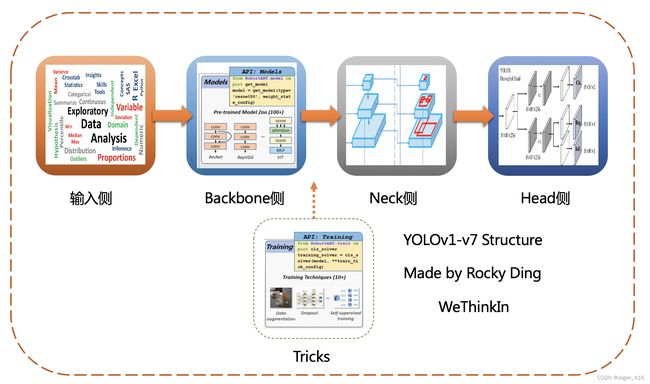
YOLOv1
论文地址:https://arxiv.org/abs/1506.02640

算法流程:
- 把原图分成7×7的格子;
- 每个格子有2个候选框,但是只负责预测一个目标(框置信度以及每个类别的分数);
- 再对7×7×2个格子,通过阈值删除置信度低的框,再使用NMS算法删除冗余框;
优点: - 速度快;
- 背景误检率低;
- 通用能力强;
缺点: - 对小目标和母鸡目标检测能力差;
- 召回率低;
- 对边框定位不够精准;
YOLOv2(YOLO9000)
论文地址:https://arxiv.org/abs/1612.08242
YOLO9000就是YOLOv2网络,在YOLO系列网络中起着承上启下的作用。

上表是论文中列出的改进点以及每个改进点的提升:
改进点:
- 增加了BN层;
- 使用高分辨率的分类器;
- 使用先验的anchor尺寸;
- 使用聚类的方式获取anchor的尺寸;
- 约束anchor的中心点位置;
- 提出passthrough层,增加细粒度特征;
- 使用多尺度的输入训练;
- 提出Darknet-19网络;
- 提出WordTree结构,支持9K+目标;
优点:
- 大幅度提高了精度;
- 大幅度提高了检测目标数量;
YOLOv3
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf
YOLOv3是一篇不是严格意义上的学术论文,而是一篇技术报告。作者是因为需要在另外一篇文章中需要引用YOLOv3,临时写的一篇报告。所以在描述和结果对比上表达得很随意。
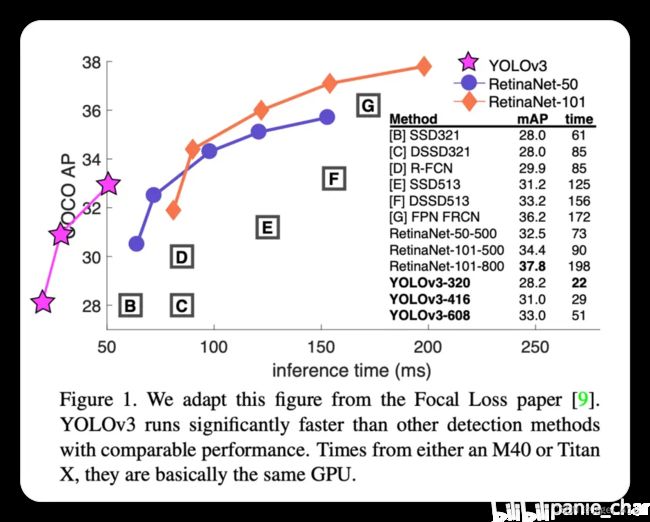
上图,源自YOLOv3原文开头,作者把YOLOv3的结果画到了坐标轴的外面,以此来表明YOLOv3的结果明显优于比当的前SOTA网络RetinaNet(有装逼的嫌疑,也可能是作者直接取了RetinaNet论文的图,不想再重新绘制,直接在上面添加了YOLOv3的结果)。但是不管怎么样,YOLOv3基本上奠定了YOLO系列检测网络的基本框架,后续的改进都是基于这个框架增加一些当前work的方法进去。
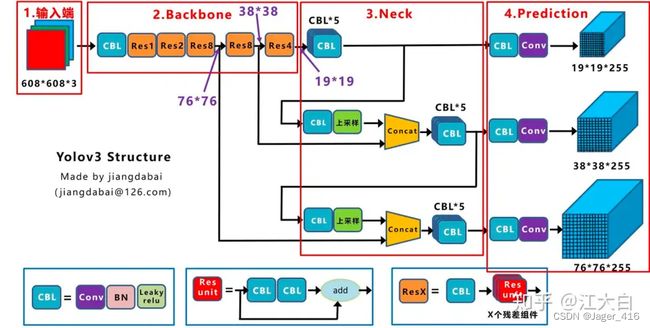
改进点:
- 多尺度预测(引入FPN);
- 更好的基础分类网络(Darknet-53,类似于ResNet 引入残差结构);
- 分类器不再使用Softmax,分类损失采用binary cross-entropy loss(二分类交叉损失熵)
优点: - 提升了检测精度;
- 多尺度预测大幅度提升了检测目标数(8K+)和小目标检测能力;
YOLOv4
论文地址:https://arxiv.org/abs/2004.10934

YOLOv4像一篇目标检测网络的tricks文献综述,作者把目标检测领域当时work的方法基本都用试了一遍,可见作者的“炼丹”水平。YOLOv4网络在保持和YOLOv3相同速度的情况下大幅提升了网络的精度。

改进点:
- 相较于YOLO V3的DarkNet53,YOLO V4用了CSPDarkNet53;
- 相较于YOLO V3的FPN,YOLO V4用了SPP+PAN;
- CutMix数据增强和马赛克(Mosaic)数据增强;
- DropBlock正则化;
- 等等
优点: - 相同速度下大幅提升了网络精度;
YOLOv5
项目地址:https://github.com/ultralytics/yolov5
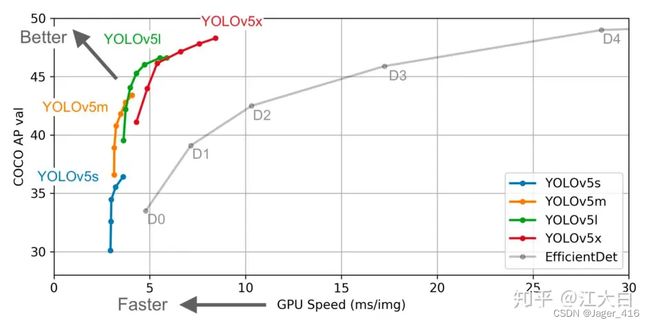
YOLOv5主要是针对工程化做了一系列的优化。相比YOLOv4在同精度的情况下,速度由原来的50FPS达到了140FPS,这对工业界来说是很有意义的。

改进点:
- 使用Pytorch框架,对用户非常友好,能够方便地训练自己的数据集,相对于YOLO V4采用的Darknet框架,Pytorch框架更容易投入生产。
- 代码易读,整合了大量的计算机视觉技术,非常有利于学习和借鉴。
- 不仅易于配置环境,模型训练也非常快速,并且批处理推理产生实时结果。
- 能够直接对单个图像,批处理图像,视频甚至网络摄像头端口输入进行有效推理。
- 能够轻松的将Pytorch权重文件转化为安卓使用的ONXX格式,然后可以转换为OPENCV的使用格式,或者通过CoreML转化为IOS格式,直接部署到手机应用端。
- 最后YOLO V5s高达140FPS的对象识别速度令人印象非常深刻,使用体验非常棒。
优点: - 速度快;
- 工程化部署便捷
YOLOX
论文地址:http://arxiv.org/abs/2107.08430
YOLOX的Backbone沿用了YOLOv3的Backbone结构

改进点:
- 特征使用了Focus网络结构、CSPDarknet以及SPPNet;
- 分类回归层修改(Decoupled Head,以前版本的Yolo所用的解耦头是一起的,也就是分类和回归在一个1X1卷积里实现,YoloX认为这给网络的识别带来了不利影响。在YoloX中,Yolo Head被分为了两部分,分别实现,最后预测的时候才整合在一起);
- Mosaic数据增强;
- 不使用先验框,Anchor Base 改为 Anchor Free;
- 为不同大小的目标动态匹配正样本,SimOTA ;
优点: - 提升了网络精度;
YOLOv6
YOLOv6的Backbone侧在YOLOv5的基础上,设计了EfficientRep Backbone结构。
和YOLOv5的Backbone相比,YOLOv6的Backbone不但能够高效利用硬件算力,而且还具有较强的表征能力。
YOLOv6的Backbone中将普通卷积都替换成了RepConv结构。同时,在RepConv基础上设计了RepBlock结构,其中RepBlock中的第一个RepConv会做channel维度的变换和对齐。
另外,YOLOv6将SPPF优化设计为更加高效的SimSPPF,增加特征重用的效率。

改进点:
- Hardware-friendly 的骨干网络设计,在backbone上就引入了RepVGG的结构,并且基于硬件又进行了改良,提出了效率更高的EfficientRep;
- 更简洁高效的 Decoupled Head ,采用了解耦检测头(Decoupled Head)结构,并对其进行了精简设计。采用 Hybrid Channels 策略重新设计了一个更高效的解耦头结构,在维持精度的同时降低了延时,缓解了解耦头中 3x3 卷积带来的额外延时开销;
- 更有效的训练策略,Anchor-free 无锚范式、SimOTA 标签分配策略、SIoU 边界框回归损失;
优点: - 提升了检测精度;
- 加快了训练速度;
YOLOv7
YOLOv7的Backbone侧在YOLOv5的基础上,设计了E-ELAN和MPConv结构。
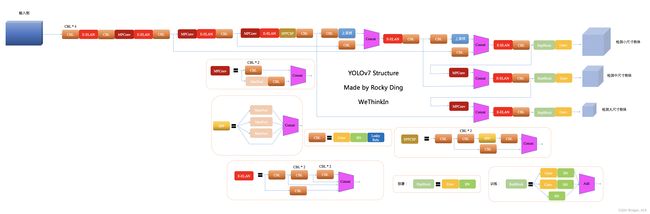
改进点:
- 模型重参数化,将模型重参数化引入到网络架构中,重参数化这一思想最早出现于REPVGG中;
- 动态标签分配,集成了YOLOv5和YOLOX两者的精华,YOLOV7的标签分配策略采用的是YOLOV5的跨网格搜索,以及YOLOX的匹配策略;
- ELAN高效网络架构,YOLOV7中提出的一个新的网络架构,以高效为主;
- 带辅助头的训练,YOLOV7提出了辅助头的一个训练方法,主要目的是通过增加训练成本,提升精度,同时不影响推理的时间,因为辅助头只会出现在训练过程中;
优点: - 提升了检测精度;
- 加快了训练速度;
基于Transformer的算法
自从Transformer出来以后,Transformer便开始在NLP领域一统江湖。而Transformer在CV领域反响平平,一度认为不适合CV领域,直到早些时间计算机视觉领域出来几篇Transformer文章,性能直逼基于CNN的SOTA,给予了计算机视觉领域新的想象空间。
在基于Transformer的计算机视觉相关研究中,ViT用于图像分类,DETR和Deformable DETR等用于目标检测。从这几篇可以看出,Transformer在计算机视觉领域的范式已经初具雏形,可以大致概括为:Embedding -> Transformer -> Head
ViT
论文地址:https://arxiv.org/abs/2010.11929
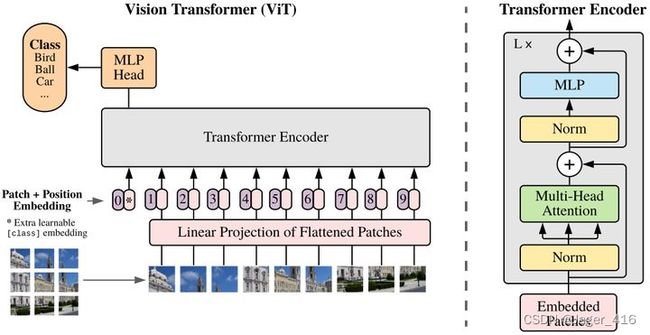
Vision Transformer(ViT)将输入图片拆分成16x16个patches,每个patch做一次线性变换降维同时嵌入位置信息,然后送入Transformer,避免了像素级attention的运算。类似BERT[class]标记位的设置,ViT在Transformer输入序列前增加了一个额外可学习的[class]标记位,并且该位置的Transformer Encoder输出作为图像特征。
ViT舍弃了CNN的归纳偏好问题,更加有利于在超大规模数据上学习知识,即大规模训练优归纳偏好,在众多图像分类任务上直逼SOTA。
DETR
论文地址:https://arxiv.org/abs/2005.12872
DETR 即 DEtection TRansformer, 是 Facebook AI 研究院提出的 CV 模型,主要用于目标检测,也可以用于分割任务。该模型使用 Transformer 替代了复杂的目标检测传统套路,比如 two-stage 或 one-stage、anchor-based 或 anchor-free、nms 后处理等;也没有使用一些骚里骚气的技巧,比如在使用多尺度特征融合、使用一些特殊类型的卷积(如分组卷积、可变性卷积、动态生成卷积等)来抽取特征、对特征图作不同类型的映射以将分类与回归任务解耦、甚至是数据增强,整个过程就是使用 CNN 提取特征后编码解码得到预测输出。
可以说,整体工作很 solid,虽然效果未至于 SOTA,但将炼丹者们通常认为是属于 NLP 领域的 Transformer 拿来跨界到 CV 领域使用,并且能 work,这是具有重大意义的,其中的思想也值得我们学习。这种突破传统与开创时代的工作往往是深得人心的,比如 Faster R-CNN 和 YOLO,你可以看到之后的许多工作都是在它们的基础上做改进的。
概括地说,DETR 将目标检测任务看作集合预测问题, 对于一张图片,固定预测一定数量的物体(原作是 100 个,在代码中可更改),**模型根据这些物体对象与图片中全局上下文的关系直接并行输出预测集,**也就是 Transformer 一次性解码出图片中所有物体的预测结果,这种并行特性使得 DETR 非常高效。
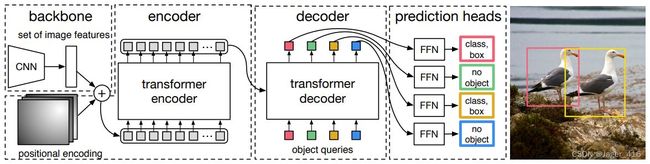
网络架构:
- Backbone:首先通过卷积得到图片的patch向量,加入位置编码,输入到encoder中
encoder对backbone的输入进行特征提取,得到K,V(与VIT一样) - Encoder:将Backbone输出的feature map转换成一维表征,得到特征图,然后结合positional encoding作为Encoder的输入。每个Encoder都由Multi-Head Self-Attention和FFN组成。和Transformer Encoder不同的是,因为Encoder具有位置不变性,DETR将positional encoding添加到每一个Multi-Head Self-Attention中,来保证目标检测的位置敏感性。
- Decoder:对输入的100个向量(object queries)根据ecoder提取到的特征进行重构,object queries是核心,让它学会怎么从ecoder提取到的原始特征找到是物体的位置
- Prediction heads:对重构后的object queries进行分类和回归
- FFN:FFN 是由具有 ReLU 激活函数且具有隐藏层的 3 层线性层计算的,或者说就是 1 × 1 卷积。FFN 预测框标准化中心坐标,高度和宽度,然后使用 softmax 函数激活获得预测类标签。

Deformable DETR
DETR存在的缺点:
- 模型很难收敛,训练困难。相比于现存的检测器,他需要更长的训练时间来收敛,在coco数据集上,他需要500轮来收敛,是faster r-cnn的10到20倍;
- DETR在小物体检测上性能较差。现存的检测器通常带有多尺度的特征,小物体目标通常在高分辨率特征图上检测,而DETR没有采用多尺度特征来检测,主要是高分辨率的特征图会对DETR增加不可接受的计算复杂度。
存在上述问题的原因: - 初始化时,attention model对于特征图上所有像素权重几乎是统一的(即一个query与所有的k相乘的贡献图比较均匀,理想状况是q与高度相关且稀疏的k相关性更强),因此需要长时间学习更好的attention map;
- 处理高分辨率特征存在计算量过大,存储复杂的特点;
改进方案: - 让encoder初始化的权重不再是统一分布,即不再与所有key计算相似度,而是与更有意义的key计算相似度可变形卷积就是一种有效关注稀疏空间定位的方式;
- 提出deformable DETR,融合deformable conv的稀疏空间采样与transformer相关性建模能力在整体feature map像素中,模型关注小序列的采样位置作为预滤波,作为key。
基于此,提出了Deformable DETR模型,deformable detr结合了deformable conv的空间稀疏采样优势和transformer的元素间关系建模能力。detr的计算复杂性来自于其中的transformer结构在全局上下文中的注意力计算,而且作者注意到,尽管这种注意力是在全局上下文中计算的,但最终某一个视觉元素只会与很小一部分其他视觉元素通过权重建立起强的联系。
因此deformable detr不再采用全局的注意力计算,只计算reference point周围一小部分点的注意力,而不是计算全局的,这样可以减少计算量,加快收敛速度。


Deformable DETR提出的Deformable Attention可以可以缓解DETR的收敛速度慢和复杂度高的问题。同时结合了deformable convolution的稀疏空间采样能力和transformer的关系建模能力。Deformable Attention可以考虑小的采样位置集作为一个pre-filter突出所有feature map的关键特征,并且可以自然地扩展到融合多尺度特征,并且Multi-scale Deformable Attention本身就可以在多尺度特征图之间进行交换信息,不需要FPN操作。
网络架构:
- Encoder:将attention模块全部换成multi-scale deformable attention,encoder的输入输出均为多尺度的feature map,保持相同的分辨率;
- Decoder:有cross-attention和self-attention两种模块,只把cross-attention替换为multi-scale deformable attention,self-attention保留不变。cross attention中的参考点,是由object query【300×C】经过线性映射+sigmoid得到的。
- Prediction heads:检测头部输出的是参考点的偏移量,文中说这样可以降低一些训练难度。
引用
- 目标检测综述(RCNN系列/YOLO系列(v1-v5)
- YOLOX优点介绍与解析
- YOLOV6主要创新点
- YOLOv7主要改进点详解
- 目标检测中的anchor-base与anchor-free
- 什么是anchor-based 和anchor free?
- SSD算法解析
- 基于Transformer的ViT、DETR、Deformable DETR原理详解
- 源码解析目标检测的跨界之星 DETR
- transformer系列——detr详解
- DETR详解
- DETR系列
- Deformable DETR讲解