信息安全-威胁检测-flink广播流BroadcastState双流合并应用在过滤安全日志

威胁检测-flink双流合并应用在过滤安全日志
要解决什么问题
威胁检测的场景囊括了各种服务器(前端服务、java、go、php、数据库等各种不同种类的服务器),并且日常从服务器中采集的日志种类又达到数十种之多,从这些日志里面我们要做威胁分析存在各种难点,首先第一步就是要从这些日志里面提取出真正有威胁的日志,把那些没有危险的日志过滤掉,那么挑战就来了,如何过滤掉那些我们可信的日志,比如MySQL服务器上的日志里面,我们需要把我们自己log-agent进程对应的日志去掉。
怎么解决
先看我们整体的处理流程,
- 采集工具从服务器采集到日志后,先讲日志写入本地日志文件;
- 然后再采用常用的日志组件如logstash、filebeat等工具将日志文件中的内容写入到远程的日志服务;
- 日志服务将日志写入MQ;
- flink消费者从MQ消费到日志,对日志进行清洗(过滤、补全);
- 最后将日志数据打入威胁检测实时仓库原始层;
该流程重点是在第4步,flink消费者从source拿到日志数据后,需要对数据进行过滤,但是flink正在告诉运行,如何才能动态的对flink添加数据过滤的规则;
具体流程如下:
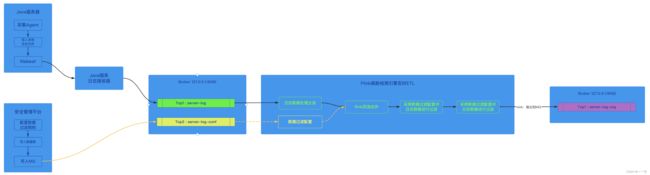
flink双流合并过滤日志数据写入实时数仓的原始层
我们的解决方案是采用flink双流合并的功能来解决配置下发至flink集群的问题;
flink集群启动时,从数据库加载当前数据过滤的配置并初始化至内存,当主流source的数据过来后,对数据应用过滤配置,从而实现数据过滤的目的;
flink集群正在运行时,由于flink集群不能动态更新。所以我们在安管平台对数据过滤的配置文件变更后,通过java服务写入至MQ,topic:server-log-conf,在flink代码中新增一个配置流source,并且将主流source和配置流source进行merge操作;
双流merge时,从配置流获取到有变化的配置信息,并将配置信息更新至内存中。对主流过来的新的数据应用最新的配置信息进行数据过滤;
解决问题的关键代码
定义配置流
MapStateDescriptor CONF_MAP_DESCRIPTOR = new MapStateDescriptor<> ("conf-map-descriptor"
,BasicTypeInfo.STRING_TYPE_INFO
,BasicTypeInfo.STRING_TYPE_INFO);
FlinkKafkaConsumer confConsumer = createConfStream(env);//创建配置流消费者
BroadcastStream confStream = env.addSource(confConsumer)
.setParallelism(1)
.name("server-log-conf")
.broadcast(CONF_MAP_DESCRIPTOR);//配置流加入到环境,并定义为广播流量 数据过滤器
public class ServerLogFilter {
private static final Logger logger = Logger.getLogger(ServerLogFilter.class);
private static ExpressRunner runner = new ExpressRunner();//这里定义的QLExpression过滤表达式
private static IExpressContext context = new DefaultContext();//规则执行上下文
private static List errors = new ArrayList();//错误收集器
private static List rules = new ArrayList() {
{
add(" obj.type=='exec' && obj.cmd like '%server_log_agent%' ");
}
};
public void setRule(String nRules) {
//rules = nRules.split() 这里将规则按分隔符拆分后替换rules
}
public boolean filter(ServerLog sl) {
for (String rule : rules) {
try {
if (inRule(sl, rule)) {
return true;
}
} catch (Exception ex) {
logger.error("hasInRules", ex);
}
}
return false;
}
public boolean inRule(ServerLog sl, String expression) throws Exception {
expressContext.put("obj", sl);
Boolean result = (Boolean) runner.execute(expression, context, errors, true, false);
return result;
}
} 配置流合并到主流,并将配置信息重置到内存
ServerLogFilter filter = new ServerLogFilter();
private DataStream merge(DataStream mainStream, BroadcastStream confStream) {
//将配置流广播到主流
DataStream mergedStream = mainStream.connect(confStream).process(new BroadcastProcessFunction() {
int limits;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
limits = 0;
}
@Override
public void processElement(String s, ReadOnlyContext readOnlyContext, Collector collector) {
if (!filter.filter(JSON.parseObject(s , ServerLog.class))) {
collector.collect(s);
}
}
@Override
public void processBroadcastElement(String rules, Context context, Collector collector) {
// 这里rules 就是配置信息
if (StringUtils.isNullOrWhitespaceOnly(rules)) {
return;
}
try {
filter.setRule(rules); //重置数据过滤的配置
} catch (Exception ex) {
logger.error(String.format("merge.processBroadcastElement:%s", ex.toString()));
}
}
});
return mergedStream;
} 知识补充-BroadcastState 的介绍
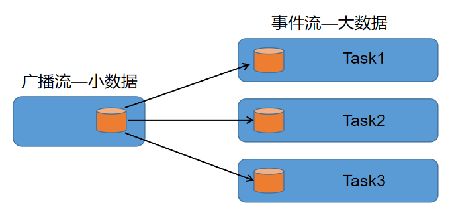
广播状态(Broadcast State)是 Operator State 的一种特殊类型。如果我们需要将配置 、规则等低吞吐事件流广播到下游所有 Task 时,就可以使用 BroadcastState。下游的 Task 接收这些配置、规则并保存为 BroadcastState,所有Task 中的状态保持一致,作用于另一个数据流的计算中。
简单理解:一个低吞吐量流包含一组规则,我们想对来自另一个流的所有元素基于此规则进行评估。
场景:动态更新计算规则。
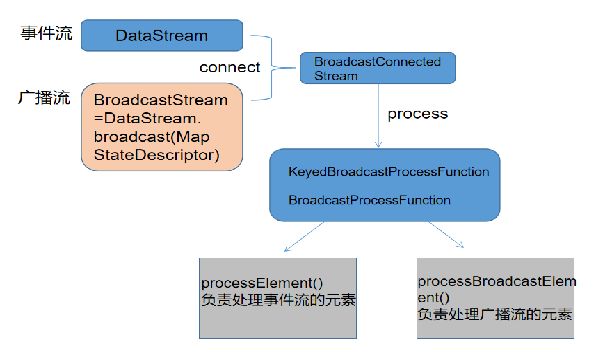
广播状态与其他操作符状态的区别在于:
- 它有一个 map 格式,用于定义存储结构
- 它仅对具有广播流和非广播流输入的特定操作符可用
- 这样的操作符可以具有不同名称的多个广播状态
知识补充-BroadcastState 操作流程
文中 QLExpression的使用在下文中以给出使用方法和代码,请参考;
信息安全-威胁检测引擎-常见规则引擎底座性能比较_一一空的博客-CSDN博客近期需要用到规则引擎来做数据处理和威胁检测引擎,所以对市面上常见的集中常见的规则引擎常用的几种技术方案做了调研,我采用同样的规则,分别采用下面规则引擎执行100万次、1000万次、5000万次,每个场景执行3次取平均值得出如下表格的结果,从性能测试结果来看,groovy胜出,性能最佳https://blog.csdn.net/philip502/article/details/125061035