(2021,中文,双向生成,端到端,双向稀疏注意力)ERNIE-ViLG:双向视觉语言生成的统一生成预训练
ERNIE-ViLG: Unified Generative Pre-training for Bidirectional Vision-Language Generation
公众号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
1. 简介
2. 相关工作
2.1 视觉语言预训练
2.2 视觉语言生成
3. 方法
3.1 双向图像-文本生成的统一生成框架
3.1.1 图像离散表示
3.1.2 双向生成模型
3.1.3 文本到图像的合成
3.1.4 图像到文本的生成
3.2 ERNIE-ViLG的大规模预训练
3.2.1 大规模图文数据集采集
3.2.2 大规模生成模型的分布式训练策略
4. 实验
4.1 设置
4.2 文本到图像的合成
4.3 图像标题
4.4 生成式视觉问答
5. 分析
6. 结论
参考
S. 总结
S.1 主要贡献
S.2 架构和方法
0. 摘要
传统的图像文本生成任务方法主要分别处理自然双向生成任务,重点是设计特定于任务的框架以提高生成样本的质量和保真度。 最近,视觉语言预训练模型极大地提高了图像到文本生成任务的性能,但用于文本到图像合成任务的大规模预训练模型仍然不发达。 在本文中,我们提出了 ERNIE-ViLG,这是一种使用 Transformer 模型进行双向图像文本生成的统一生成预训练框架。 基于图像量化模型,我们将图像生成和文本生成表示为以文本/图像输入为条件的自回归生成任务。 双向图像文本生成建模简化了视觉和语言之间的语义对齐。 对于文本到图像的生成过程,我们进一步提出了一种端到端的训练方法来共同学习视觉序列生成器和图像重建器。 为了探索双向文本-图像生成的大规模预训练前景,我们在包含 1.45 亿(中文)图像-文本对的大规模数据集上训练了 100 亿个参数的 ERNIE-ViLG 模型,该模型实现了文本到图像和图像到文本任务的最佳性能,在 MS-COCO 上实现文本到图像合成的 FID 为 7.9,在 COCO-CN 和 AIC-ICC 上获得图像标题的最佳结果。
1. 简介
“我不理解我无法创造的东西,。” ——理查德·费曼
跨模态生成旨在将一种模态映射或翻译为另一种模态,要求模型完全 “理解” 源模态并忠实地 “创建”(生成)与源具有高度语义一致性的目标模态 [1]。
- 作为多模态机器学习研究的重要组成部分,跨模态生成任务(音频-语言 [2, 3]、视觉-语言 [4, 5, 6, 7, 8, 9]、音频-视觉 [10, 11])引起了人们的极大关注。
- 在本文中,我们关注视觉-语言生成任务,主要包括图像标题(用自然语言描述图像的视觉内容)和文本到图像合成(创建与文本描述保持语义一致的图像) 。
- 作为计算机视觉和自然语言处理的交叉点,视觉-语言生成任务引起了 NLP 和 CV 社区的极大兴趣,并在过去几年中取得了巨大进展。
当然,文本图像生成任务是双向的,合理的模型应该具有图像标题和文本到图像合成的能力。 然而,由于语言生成和图像生成的生成架构不同,解决这两个任务的方法是分开开发的。
- 传统的图像标题方法主要采用编码器-解码器架构[4],其中文本以序列生成方式生成。 图像首先被编码为一个或多个向量,然后利用解码器(例如 LSTM)根据编码器结果生成语言标记。
- 最近,基于 Transformer 的视觉语言预训练模型 [7, 12] 受益于大规模图像文本对齐数据集的预训练,显着提高了图像标题的性能。
- 另一方面,主要的文本到图像合成方法是生成对抗网络(GAN)[13] 变体,其中 ConvNet 被用作生成器的基本架构。 虽然已经提出了各种方法来提高生成图像的质量和分辨率,例如 StackGAN [14]、XMC-GAN [8],但生成具有多个对象的复杂场景的图像仍然很困难。
受图像自回归模型 [15, 16] 的启发,最近的工作 [9, 17] 提出将文本到图像的合成表示为序列到序列问题,其中图像标记是通过离散 VAE 学习的 [ 18, 9]。 他们在同一个 transformer 中对文本标记和图像标记进行建模,并且在图像质量和构建复杂场景的能力方面显示出巨大的改进。 文本到图像的生成过程通常采用两阶段管道,由生成器(生成图像标记)和重构器(从生成的图像标记构建图像)组成,它们是单独训练的。
最近,研究人员尝试将双向图像文本生成任务统一在单个模型中。
- Cho 等人 [19] 尝试增强现有的视觉语言预训练模型的文本到图像生成能力,通过对预训练图像特征使用 K 均值聚类生成图像离散标记,并以非自回归方式生成图像序列。
- 基于这种方法,Huang 等人 [20] 将这两个任务都制定为序列生成任务,并进一步提出序列级训练任务以提高性能。 尽管它们将两个任务统一在一个 transformer 中,但它们采用非自回归采样来生成图像,这可以实现快速推理速度,但由于消除了目标标记之间依赖关系的显式建模,因此与自回归生成模型相比,性能是次优的。
在本文中,我们提出了 ERNIE-ViLG,一种使用 Transformer 模型进行双向图像文本生成的统一预训练方法。
- 基于图像量化技术 [18,9,21],图像到文本和文本到图像的生成都是在同一 transformer 内以自回归方式处理的。 我们进一步提出了一种用于文本到图像合成的端到端预训练方法,该方法使得传统上独立的两阶段生成器和重建器联合训练。
- 为了探索双向文本图像生成的大规模预训练前景,我们在包含 1.45 亿个高质量中文图像文本对的大规模数据集上预训练了具有 100 亿参数的模型。 它在文本到图像合成和图像标题任务方面都表现出了卓越的性能。 具体来说,它在 MS-COCO 上实现了文本到图像合成的最佳 FID,并在两个中文图像标题数据集上获得了最先进的性能。
- 此外,我们在具有挑战性的生成式视觉问答(VQA)任务上对 ERNIE-ViLG 进行了评估,出色的性能表明我们的双向生成模型已经捕获了跨视觉语言模态的语义对齐,并且还可以迁移到处理复杂的图像文本生成之外生成任务 。
总的来说,我们的贡献包括:
- 我们提出了 ERNIE-ViLG,一种用于双向图像文本生成任务的统一生成预训练方法,其中图像和文本生成都被表述为自回归生成任务。 我们提出了第一个基于图像离散表示的文本到图像合成的端到端训练方法,该方法增强了生成器和重建器,并且优于传统的两阶段方法。
- 我们训练了 100 亿参数的 ERNIE-ViLG 模型,并在文本到图像和图像到文本生成任务上获得了优异的性能,在 MS-COCO 上为文本到图像合成设置了新的 SOTA 结果,并在两个流行的中文数据集的图像标题任务上获得了 SOTA 结果。
- 生成式 VQA 任务的卓越性能表明,我们的双向生成模型捕获了视觉和语言模态之间复杂的语义对齐。
2. 相关工作
2.1 视觉语言预训练
视觉语言预训练(Vision-Language Pre-training,VLP)模型 [22,7,23,24,25,26,27] 极大地提高了各种视觉语言任务的性能,例如 VQA 和跨模态检索。
- 利用 Transformer 架构(双流或单流)来融合视觉模态和语言模态,他们提出了各种预训练任务,从传统的掩蔽语言建模(masked language modeling,MLM)、掩蔽区域预测(masked region prediction,MRP)、图像文本 匹配(image-text matching,ITM)到词区域对齐 [23]、场景图预测 [24]、多模态条件文本生成 [28]、Prefix-LM [29] 等。
- 预训练数据集也是 VLP 研究的一个重要关注点,早期的工作利用百万级噪声图像-文本数据集(例如 Conceptual Captions [30])和人类标记数据集(例如 COCO Captions [31]),而最近的工作则利用数亿和近十亿级噪声图像-文本数据集 [29] 扩大了预训练规模 。
虽然大多数 VLP 方法侧重于视觉语言理解任务的预训练,但一些工作已经注意到预训练对于提高跨模态生成任务(主要是图像字幕任务)性能的重要性。
- Zhou 等人 [7] 提出了第一个统一模型来提高理解和生成任务的性能,其中双向和序列到序列预训练任务利用不同的注意力掩模。
- Wang 等人 [29] 提出了 prefix-LM 预训练任务,类似于图像标题,仅利用语言建模目标。
- Hu 等人 [32] 从图像标题的数据和模型角度研究预训练的缩放行为。
虽然由于大规模图像文本数据集的预训练,图像到文本生成任务已经取得了很大进展,但文本到图像合成任务预训练的好处尚未得到充分探索。
- Cho 等人 [19] 建议增强 VLP 模型的图像生成能力,该能力基于离散视觉表示并针对文本到图像合成进行微调。
- Wu 等人 [33] 尝试构建一个针对图像和视频合成任务的统一编码器-解码器预训练框架。
ERNIE-ViLG 专注于图像到文本和文本到图像生成任务的预训练,并将预训练目标简化为图像和文本的自回归序列到序列生成任务。
2.2 视觉语言生成
图像到文本生成。
- 图像标题的典型方法采用编码器-解码器架构,将图像到文本问题表述为具有图像上下文的文本序列生成任务。
- Vinyals 等人 [4] 提出了一种简单的基于 LSTM 的架构,其中图像被编码为单个向量并用作单层 LSTM 的初始隐藏状态。
- 利用注意力机制,人们提出了各种方法 [34,6,35] 来提高视觉图像和生成的文本序列之间的相关性,其中图像被编码为多个特征,并通过跨模态注意力来指导生成过程。
- 最近,研究人员探索了基于 Transformer 的图像标题模型的潜力 [30,36,7]。 Zhou 等人 [7] 建议使用统一的 Transformer 架构来融合视觉和文本模态,以进行编码和解码。
- 随后,Li 等人 [12] 建议将使用对象检测器从图像中提取的对象标签包含到输入中,以增强图像和文本之间的语义对齐。
文本到图像合成。
- 自从使用生成对抗网络(GAN)[13] 生成图像,基于 GAN 的方法一直是文本到图像合成中最流行的方法。
- Reed 等人 [5] 首先扩展条件 GAN 以从语言描述生成图像。
- 此后,Zhang 等人 [14] 提出 StackGAN 以多阶段方式生成高分辨率图像。
- Zhu 等人 [37] 建议使用动态记忆网络来精练图像内容。
- Zhang 等人 [8] 建议结合对比学习来提高生成图像对文本输入的保真度。
- 最近,受到逐像素图像生成的自回归生成模型 [16] 的启发,基于 transformer 的方法 [9, 17] 在文本到图像的合成方面显示出了有希望的结果。 基于通过各种离散 VAE [18, 21] 学习到的离散图像标记,他们尝试在单个 transformer 框架中对图像标记和文本标记进行建模,对于文本输入和图像目标遵循单向的方式。
3. 方法
在本节中,我们将介绍用于双向视觉语言生成的统一生成预训练框架以及用于文本到图像合成训练的端到端方法。 此外,我们还详细介绍了大规模图像文本数据集的收集以及预训练 100 亿参数模型的分布式训练策略。
3.1 双向图像-文本生成的统一生成框架

如图 1 所示,ERNIE-ViLG 采用统一的双向图像-文本生成框架。
- 图像由矢量量化变分自动编码器(vector quantization variational autoencoder,VQVAE)[18] 表示为离散表示序列。 图像离散序列用作参数共享 transformer 的输入(输出),用于自回归图像到文本(文本到图像)的生成。
- 具体来说,对于图像到文本的生成,transformer 将图像离散序列作为输入来生成相应的文本序列。 相反,对于文本到图像的合成,文本被输入到 transformer 以生成相应的视觉离散序列,然后使用图像离散序列来重建图像。
- 除了传统的两阶段管道方法之外,我们还提出了一种联合训练离散表示序列生成和图像重建模块的端到端训练方法,以增强文本到图像合成的能力。
3.1.1 图像离散表示
离散表示最近在图像生成任务中取得了显着的改进,因为它可以更好地适应自回归建模。 VQVAE [18] 提出使用矢量量化将图像表示为潜在离散序列。 它比像素聚类具有更强的语义表示能力。 VQVAE 通过编码器 E 对原始图像 x ∈ R^(H*W*3) 进行编码,并用码本 C 将其量化为 z。z 是具有 h*w 索引的离散序列,并用于通过解码器 G 和 C 重建 x。训练期间的损失函数如公式 1-2 所示。

整体损失函数包含两部分。 L_VQV AE 的第一项是重建损失。 最后两项旨在使 E(x)(编码器输出)和 z_emb(从码本查找离散序列后的嵌入)彼此接近。 sg[·] 表示停止梯度(stop-gradient)操作,q[·] 表示矢量量化。 x 和 ^x 是原始图像和重建图像。 离散序列 z 作为双向生成模型的输入(或输出),其长度 n 为 h*w。
3.1.2 双向生成模型
对于生成模型,我们使用多层 transformer 编码器来执行图像到文本和文本到图像的生成任务。
- 与仅解码 [9, 17] 或单独的编码器-解码器 [33] 架构不同,ERNIE-ViLG 的编码器和解码器共享参数并使用特定的自注意力掩码来控制上下文,如 UniLM [38] 和 ERNIE- GEN [39],其中允许源标记注意所有源标记,并且允许目标标记注意源标记及其左侧的目标标记。
- 双向生成预训练任务在同一模型中精确建模,我们认为共享模型空间有助于在视觉和语言模态之间建立更好的语义对齐。
使用 VQVAE 编码器从图像中离散化的视觉标记 {z_1, ..., z_n} 和使用 WordPiece 标记器从文本标记化的文本标记 {t_1, ..., t_m} 被连接并输入到 transformer 模型中。 因此,在训练过程中,模型采用输入流 {t_1, ..., t_m, z_1, ..., z_n} 用于文本到图像生成任务,以自回归方式预测图像标记,采用输入流 {z_1, ..., z_n, t_1, ..., t_m} 用于图像到文本生成任务。 我们使用以下多任务损失来学习图像文本双向生成任务。
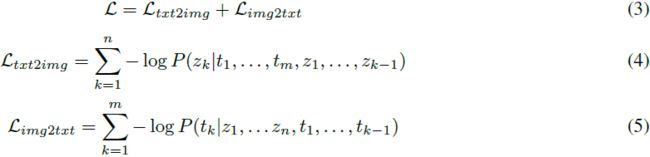
请注意,视觉序列 z 的长度 n 通常很大(通常大于1024)以减少图像的信息损失,这导致 Transformer 模型在训练和推理过程中的计算成本和内存消耗相对较高。
- 如图 2 所示,我们利用与 [9] 中类似的稀疏注意力机制。
- 具体来说,我们对第 i 个 transformer 层采用行注意力(i mod 4 != 2)、列注意力(i mod 4 = 2)和卷积注意力(最后一层)。 我们在训练时将行注意力和列注意力实现为块式注意力。
- 几个初步的实验验证了这种稀疏注意力的实现可以在训练过程中大约提高 25% 的速度并节省 50% 的 GPU 内存,同时保持损失的收敛与密集注意力一致。 而且预测方面的改进更为显着。
- 虽然 [9] 中的稀疏注意力是为单向建模而设计的,但我们将它们调整为用于图像到文本生成的视觉输入标记的双向建模方式,如图 2(b)所示。

3.1.3 文本到图像的合成
基于图像离散序列的文本到图像合成通常在两阶段流程中处理:离散表示序列生成和图像重建。 如图 1 中的红色路径,在码本中查找生成的离散序列以获得 3D 张量 z_emb ∈ R^(h*w*d)。 然后 z_emb 被发送到重建的解码器以恢复成图像。 生成器和重建器是独立训练的。
除了传统的两阶段管道模式外,在 ERNIE-ViLG 的框架下,文本到图像的合成还可以使用我们新提出的端到端训练方法,如图 1 中的绿色路径。 最后一个 Transformer 层输出的图像标记的隐藏嵌入被非线性映射到 z_emb。 由于避免了不可导出的 ID 映射操作,因此梯度可以从重构器向后传播到生成器。 因此,可以进行端到端的训练。
该方法旨在:
- 为重建器提供更多上下文特征。 与码本中的上下文无关嵌入相比,隐藏嵌入由深度模型编码,包含更多图像语义。 它还通过注意力交互来感知文本信息。
- 通过重建任务增强生成器。 隐藏嵌入接收来自生成和重建的抽象和原始监督信号。 它可以帮助生成器更好地了解图像表示。
我们的实验表明,与两级管道相比,端到端训练可以改进生成器和重建器。 详细的实验结果见第 5 节。
3.1.4 图像到文本的生成
对于图像到文本的生成任务,首先使用编码器和 VQVAE 的码本将图像离散化为视觉标记。 然后将图像标记输入 Transformer 以自回归生成文本标记。 在我们当前的实现中,量化模块在图像到文本生成训练任务期间进行预训练和固定,同时它们也可以与生成模型联合更新,我们将在未来的工作中对此进行探索。
3.2 ERNIE-ViLG的大规模预训练
为了探索双向文本-图像生成的大规模预训练前景,我们训练了一个 100 亿参数的 ERNIE-ViLG 模型,这是一个用于图像到文本和文本到图像生成的 48 层 Transformer 编码器 。 大规模预训练的核心问题包括训练数据的收集和分布式并行训练。
3.2.1 大规模图文数据集采集
为了预训练具有从基本实体到复杂场景的双向文本图像生成通用能力的生成模型,我们构建了一个由超过 1.45 亿个高质量中文图像-文本对组成的大规模图像-文本数据集。 我们的数据集来源如下:
- 中文网页。 我们从各个中文网页中抓取了 8 亿条原始的与图像配对的中文替代文本描述(Chinese alt-text descriptions),进行了多个过滤步骤,总共收获了 7000 万条文本-图像对。 过滤规则主要包括: (1) 文本长度:alt-text 的字数小于 15。 (2) 文本内容:alt-text 必须至少包含 1 个名词,且不包含特殊字符。 (3) 图文相似度:替代文本与图像的相似度得分(由内部图文匹配模型计算,得分范围为 0.0 至 1.0)大于 0.5。
- 图像搜索引擎。 我们从内部图像搜索引擎收集了大约 6000 万条查询文本和相应的用户点击图像。 查询和用户点击的图像之间通常存在很强的相关性。
- 公共图像文本数据集。我们从两个公共数据集 CC [30] 和 CC12M [40] 中收集了总共 1500 万个文本图像对。 这些数据集中的标题通过百度翻译 API 翻译成中文。
3.2.2 大规模生成模型的分布式训练策略
100 亿参数的 ERNIE-ViLG 是基于 PaddlePaddle 平台 [41] 实现的。 训练如此大规模的模型需要解决严峻的挑战,例如有限的设备内存和计算效率。 此外,将 10B 生成模型安装到单个 GPU 中要求相当高,而且考虑到我们的双向模型结构使激活和梯度的内存消耗加倍,这变得更具挑战性。
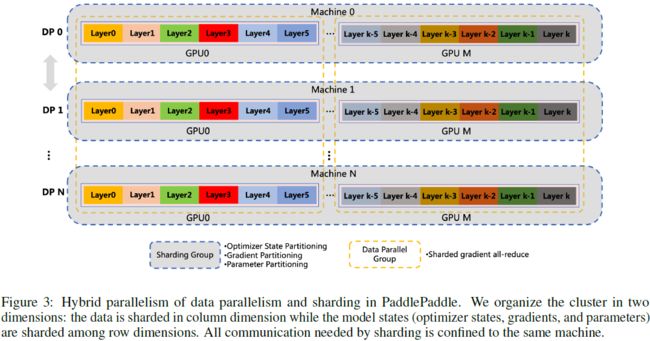
如图 3 所示,我们采用组分片数据并行(Group Sharded data parallelism)技术 [42, 43],通过跨多个设备划分优化器状态、梯度和参数来消除内存冗余。 此外,还应用激活重新计算 [44] 和混合精度 [45] 来减少 GPU 内存占用并提高吞吐量。 此外,引入了 Optimizer-offload [46] 将分片优化器状态和主参数交换到 CPU,这大大减少了 GPU 内存占用。 此外,我们将优化器卸载与梯度累积相结合,降低 CPU 和 GPU 之间的通信频率,从而提供更高的计算效率。
4. 实验
我们预训练了 100 亿参数的 ERNIE-ViLG 模型并验证了其生成能力。 我们对传统的双向图像文本任务进行了实验:文本到图像合成和图像标题。 此外,为了进一步验证我们模型的跨模态理解能力,我们将 ERNIE-ViLG 转移到具有挑战性的生成式 VQA 任务中,以评估我们的模型在视觉和语言模态中捕获的对齐情况。
4.1 设置
我们使用 VQGAN [21](VQVAE 的增强变体)作为我们的 “图像标记器”。 通过添加对抗性训练和感知损失,VQGAN 可以从离散表示中恢复更清晰、更真实的图像。 我们采用 f = 8,词汇表大小 = 8192 的 VQGAN 模型,其中 f 表示边长(side-length)的缩减因子。 我们通过中心裁剪将原始图像预处理为 256 * 256,因此视觉离散标记序列 n 的长度为 1024(h*w,h = w = 32)。
对于生成器,我们使用多层 Transformer 编码器来执行图像到文本和文本到图像生成任务,该编码器由 48 个 Transformer 层、4096 个隐藏单元和 64 个注意力头组成,总共有 100 亿个参数。 考虑到基于 GAN 的模型训练的不稳定性,我们在训练该模型时选择两阶段文本到图像合成模式,并直接使用 VQGAN 的解码器作为图像重建器。
4.2 文本到图像的合成
为了生成给定文本的图像,我们遵循与 [9] 中相同的采样策略,并使用内部(in-house)基于对比学习的图像文本匹配模型对生成的图像进行重新排序。 我们在零样本和微调设置下对常用的文本到图像合成数据集进行 ERNIE-ViLG 自动评估。 此外,我们还开展人工评估活动来直接评估生成的图像的质量。
自动评估。对于自动评估,我们将 ERNIE-ViLG 与 MSCOCO [49] 上的其他强方法进行比较。 MS-COCO 是一个公开的文本到图像合成基准,这对于包含许多涉及常见对象的复杂场景来说具有挑战性。 继之前的工作之后,我们从验证集中随机采样了 30,000 张图像,并通过百度翻译 API 将其相应的标题翻译成中文。 对于生成的图像,我们对样本进行重新排序,并选择 60 个样本中的最佳样本进行零样本实验,以便与 [17] 进行公平比较,并在微调时选择 10 个样本中的最佳样本。 采用 Fréchet Inception Distance (FID) [50] 进行图像质量评估(与之前的作品相同,我们采用来自 https://github.com/MinfengZhu/DM-GAN 的评估代码)。
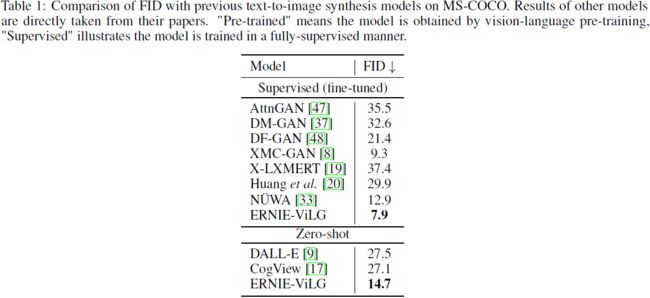
表 1 所示的结果将我们的模型与之前的工作进行了比较。 在零样本设置下,ERNIE-ViLG 大幅超越了 120 亿参数模型 DALL-E,FID 显着提高了12.8,甚至可以与全监督模型相媲美。 它证实 ERNIE-ViLG 获得了图像和文本之间的通用语义对齐,即使对于复杂的开放域场景也是如此。 在对特定领域的数据集进行微调后,ERNIE-ViLG 在 MS-COCO 上取得了最先进的结果,与基于最佳 Transformer 的方法和基于最佳 GAN 的方法分别将 FID 指标提高了 5.0 和 1.4 。
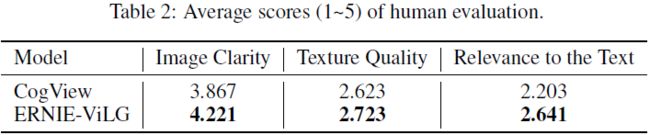
人类评估为了获得对我们的模型在零样本设置中生成的图像质量的直接评估,我们构建了一个用于人类评估的多样化数据集,其中包含针对各种情况的 500 个文本。 从各个方面收集文本句子,以充分探索 ERNIE-ViLG 的通用能力,例如对象的详细属性、以合理的方式组合多个对象等。有关此数据集的更多详细信息,请参阅附录 A。 评估时,要求三名评估员从三个角度(图像清晰度、图像纹理、文本与图像之间的相关性)评估每张图像,质量分数范围为 1 到 5。我们重新排序,并对于每个文本,从 60 个生成的样本中选择最好的并与 CogView (给定文本,CogView 生成的图像是从其官方网站手动抓取的)进行比较。 平均评估结果列于表 2 中。ERNIE-ViLG 从所有三个角度都获得了比 CogView [17] 更高的质量分数,这表明我们的模型获得了更好的零样本文本到图像生成能力。

定性结果 ERNIE-ViLG 已经获得了各种场景的生成能力,从基本对象到复杂的对象组合。 一些示例如图 4 所示。从示例中可以看出,ERNIE-ViLG 不仅可以绘制给定文本描述中提到的实体,还可以将它们以合理的方式与背景组合在一起。 令人惊讶的是,我们还发现 ERNIE-ViLG 拥有两项特殊技能。 首先,ERNIE-ViLG 只需添加文字提示即可生成不同风格的图像,无需像 CogView 那样进行微调(图 5)。 其次,我们的模型可以根据中国古诗生成逼真的图像,这显示出对简短和抽象描述的良好理解。 诗中的真实观念层次分明,意境描写得很好(图6)。
4.3 图像标题
为了充分评估 ERNIE-ViLG 的图像标题能力,我们进行了自动评估,以便与以前的方法进行公平比较,并通过人类判断来评估生成的标题的质量。
自动评估。我们在两个常用的中文图像字幕数据集 AIC-ICC [51] 和 COCO-CN [52] 上进行了实验。 对于 AIC-ICC,我们按照与 [53] 相同的做法,在训练分割上微调 ERNIE-ViLG,并在验证分割上进行评估。 对于 COCO-CN 上的实验,我们使用标准的训练/验证/测试分割并报告测试分割的结果。 我们采用广泛使用的指标 BLEU@4、METEOR、ROUGE-L 和 CIDERr 进行所有评估。
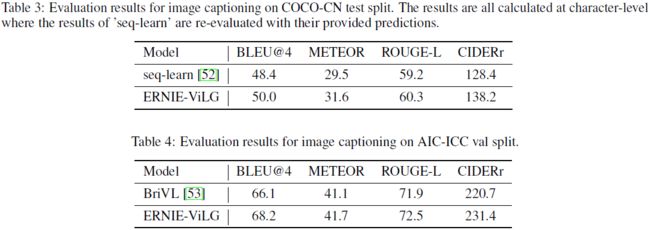
如表 3 和表 4 所示,ERNIE-ViLG 在两个数据集上均取得了最佳结果。 具体来说,与基于预训练的方法 [53] 相比,我们在 AIC-ICC 上获得了 2.1 BLEU@4 的显着改进。
人工评估。我们还开展了人工评估活动,以评估 ERNIE-ViLG 生成的标题的质量。 给定图像和生成的预测,要求评估者从三个角度评估标题质量:流畅性(标题是否流畅)、相关性(标题是否与给定图像相关)和丰富性(标题是否充分描述了图像的全部内容),分数从 0 到 2(越高越好)。 我们从 COCO-CN 测试集中随机选择 200 张图像,并根据零样本 ERNIE-ViLG 模型和微调模型进行预测。

评估结果如表 5 所示。微调后的 ERNIE-ViLG 模型获得的平均得分为 1.62。 我们还发现零样本 ERNIE-ViLG 模型获得了较高的流畅度分数,接近微调模型的分数,但它们之间的相关性分数和丰富度分数差距很大。 我们认为这是因为网络爬取的预训练数据集往往有噪音,并且大多数标题的描述性较差,而人工标记的标题数据集(例如 COCO-CN)中的标题通常具有描述性,可以捕获 图像的所有细节。 图 7 中展示了一些示例。
4.4 生成式视觉问答
在文献中,视觉问答任务通常转换为预定义候选答案集上的多标签分类问题。 然而,在现实应用中很难定义一组封闭的候选答案,这使得这种简化在研究和实际应用之间仍然存在差距。 在本文中,我们研究了开放式生成视觉问答任务,其中模型需要在给定图像和问题的情况下直接生成答案。 此任务的理想生成模型需要基于视觉和语言理解在图像和问题之间建立语义连接,并生成流畅的文本答案。 我们在公共 FMIQA [54] 数据集上进行了实验,该数据集具有自由式和多样化的问答注释。 对于评估,我们既进行图灵测试 [54](要求人类评估者判断答案是否由机器生成),又进行人类判断的答案质量评估(分数从 0 到 2,越高越好)。

由于测试集尚未正式发布,我们从 FMIQA 验证分组中随机选择 200 个样本进行评估。 我们在训练分割上对 ERNIE-ViLG 进行微调,并使用微调后的模型对样本进行预测。 与 [54] 相比,我们还对人工标记的答案进行评估,以消除不同评估者的偏差。 评估结果如表 6 所示。ERNIE-ViLG 的图灵文本通过率为 78.5%,显着超过 mQA [54],答案得分为 1.495,这清楚地验证了我们的模型已经捕获了跨视觉和语言模态的语义对齐。
5. 分析
为了评估我们提出的端到端文本到图像合成方法带来的好处,我们使用精简版 Transformer 作为图像离散表示生成器进行实验,该版本具有约 3 亿个参数(24 个 Transformer 层,1024 个隐藏单元) 和 16 个注意力头)。 考虑到 GAN 训练过程的不稳定性,我们利用 dVAE [9],而不是 VQGAN,将图像离散化为视觉序列,并根据视觉标记构建图像。 对于重建器,我们使用与 dVAE 相同的网络架构。 我们开发了一个多任务学习过程,为生成损失和重建损失分配相同的权重。 该模型在 CC 和 CC12M 的合并数据集上进行训练,并在零样本设置的 MS-COCO 验证集上进行评估。
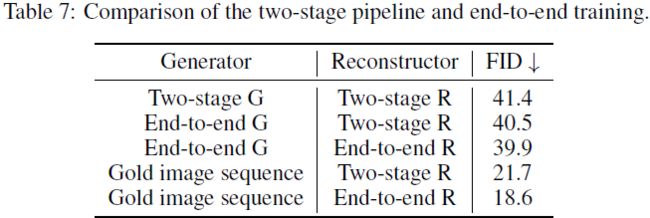
我们将端到端训练方法的结果与两阶段管道基线进行比较,如表 7 所示。对于两阶段管道,我们训练文本到图像生成器,并直接使用 dVAE 的解码器作为重建器。Two-stage G(R) 是指单独训练的生成器(重建器),end-to-end G(R) 是指端到端训练的生成器(重建器)。 与两级管道相比,我们的端到端方法实现了 1.5 的 FID 显着改进。 我们发现,将端到端训练的生成器(end-to-end G)和 dVAE 解码器(two-stage R))相结合也带来了与两阶段管道相比 0.9 的 FID 改进,但落后于端到端方法。 这表明我们提出的端到端方法可以提高生成器(two-stage G & two-stage R vs end-to-end G & two-stage R)和重建器(end-to-end G & two-stage R vs end-to-end G & end-to-end R)。
我们还将通过 dVAE离散化的真实图像的视觉序列(gold image sequence)输入到两个重建器中进行比较。 实验结果(表7中的最后两行)表明,端到端训练的重建器在从真实图像离散表示重建方面具有更明显的优势。 我们认为端到端训练在具有 100 亿个参数的 ERNIE-ViLG 上会更有效,因为更强大的生成器生成的图像离散表示更接近真实分布,并且更大模型的隐藏嵌入为重建器提供了更有用的特征。 由于 GAN 和大规模生成模型的训练都不稳定,我们基于 VQGAN 的 100 亿参数模型还没有使用端到端的训练。 我们将解决未来工作中的不稳定问题,并通过端到端训练来改进 100 亿参数的 ERNIE-ViLG。
6. 结论
我们提出 ERNIE-ViLG 将双向图像文本生成任务统一在一个生成模型中,并提出一种用于文本到图像合成的端到端训练方法。 ERNIE-ViLG 在大规模图像文本数据集上进行了预训练,捕获了双向视觉语言生成的功能,并在各种跨模态生成任务上实现了卓越的性能,包括文本到图像合成、图像标题和生成式视觉问答。 总的来说,我们的模型进一步推进了图像到文本和文本到图像生成任务的统一预训练。
参考
Zhang H, Yin W, Fang Y, et al. Ernie-vilg: Unified generative pre-training for bidirectional vision-language generation[J]. arXiv preprint arXiv:2112.15283, 2021.
S. 总结
S.1 主要贡献
本文提出 ERNIE-ViLG,这是一种使用 Transformer 模型进行双向生成(图像-文本,文本-图像)的统一生成预训练框架。基于图像量化模型,将生成表示为以输入文本 / 图像为条件的自回归生成任务。 双向生成建模简化了视觉和语言之间的语义对齐。
本文提出一种端到端的训练方法来同时训练视觉序列生成器和图像重建器,该方法增强了生成器和重建器,并且优于传统的两阶段方法。
调整用于单向建模的稀疏注意力机制以适应本文的双向建模方案,这种稀疏注意力的实现可以在训练过程中提高速度并节省内存,同时保持损失的收敛与密集注意力一致,而且可以改进预测。
S.2 架构和方法
ERNIE-ViLG 采用的统一双向图像文本生成框架如图 1 所示。
- 图像由 VQVAE 表示为离散表示序列。 图像离散序列用作参数共享 transformer 的输入(输出),用于自回归图像到文本(文本到图像)的生成。
- 与仅解码或单独的编码器-解码器架构不同,ERNIE-ViLG 的编码器和解码器共享参数并使用特定的自注意力掩码来控制上下文,其中允许源标记注意所有源标记,允许目标标记注意源标记及其左侧的目标标记。
- 对于文本到图像合成任务,除了采用以往的两阶段流程(离散表示序列生成和图像重建,如图 1 中的红色路径),还可采用本文的端到端训练方法(如图 1 中的绿色路径),与两阶段流程相比,端到端训练可以改进生成器和重建器。