JUC第二十五讲:JUC线程池-CompletableFuture 实现原理与实践
JUC第二十五讲:JUC线程池-CompletableFuture实现原理与实践
CompletableFuture由 Java 8 提供,是实现异步化的工具类,上手难度较低,且功能强大,支持通过函数式编程的方式对各类操作进行组合编排。相比于ListenableFuture,CompletableFuture有效提升了代码的可读性,解决了“回调地狱”的问题。本文是JUC第二十五讲,主要讲述CompletableFuture 的原理与实践。
文章目录
- JUC第二十五讲:JUC线程池-CompletableFuture实现原理与实践
-
- 背景
- 1、为何需要并行加载
- 2、并行加载的实现方式
-
- 2.1、同步模型
- 2.2、NIO异步模型
- 2.3、为什么会选择CompletableFuture?
- 3、CompletableFuture使用与原理
-
- 3.1、CompletableFuture的背景和定义
-
- 1、CompletableFuture解决的问题
- 2、CompletableFuture 的定义
- 3.2、CompletableFuture 的使用
-
- 1、零依赖:CompletableFuture的创建
- 2、一元依赖:依赖一个CF
- 3、二元依赖:依赖两个CF
- 4、多元依赖:依赖多个CF
- 3.3、CompletableFuture原理
-
- 1、CompletableFuture的设计思想
- 2、整体流程
- 3、小结
- 4、实践总结 ☆
-
- 4.1、线程阻塞问题
-
- 1、代码执行在哪个线程上?
- 4.2、线程池须知
-
- 1、异步回调要传线程池 ☆
- 2、线程池循环引用会导致死锁
- 3、异步RPC调用注意不要阻塞IO线程池
- 4.3、其他
-
- 1、异常处理
- 2、沉淀的工具方法介绍
- 4.4、异步编排在商品中心的应用
- 4.5、异步编排在中间件的应用
- Action1:MQ有没有提供异常捕获回调方法呢?
- 5、项目结果:异步化收益
- 6、参考文献
- 7、名词解释及备注
- 8、附录
-
- 8.1、自定义函数
- 8.2、CompletableFuture 处理工具类
- 8.3、异常提取工具类
- 8.4、打印日志
- 8.5、日志处理实现类
- 8.6、打印日志方式
- 8.7、异常情况返回默认值
- 8.8、默认返回值应用示例
- 本文作者
- Action1:问题1:按理说cf的result应该是volatile ? 问题2:为什么要用stack来实现依赖的存储,queue不行吗?
- Action2:CompletableFuture 在其中只是起到了写起来更方便,可读性更高的作用吧?减少线程损耗靠的是 NIO,以前的实现方式也一样是一个独立线程池吧,所以引入这个的意义大概就是更好的可读性和更好的编排?
- Action3:ComplatableFuture 在Java9才有超时处理,Java8下我们用applyToEither + scheduledThreadPool 实现,请问你们怎么处理呢?
- Action4:go语言是如何实现异步编排的?
背景
随着订单量的持续上升,美团外卖各系统服务面临的压力也越来越大。作为外卖链路的核心环节,商家端提供了商家接单、配送等一系列核心功能,业务对系统吞吐量的要求也越来越高。而商家端API服务是流量入口,所有商家端流量都会由其调度、聚合,对外面向商家提供功能接口,对内调度各个下游服务获取数据进行聚合,具有鲜明的I/O密集型(I/O Bound)特点。在当前日订单规模已达千万级的情况下,使用同步加载方式的弊端逐渐显现,因此我们开始考虑将同步加载改为并行加载的可行性。
1、为何需要并行加载
外卖商家端API服务是典型的 I/O密集型(I/O Bound)服务。除此之外,美团外卖商家端交易业务还有两个比较大的特点:
- 服务端必须一次返回订单卡片所有内容:根据商家端和服务端的“增量同步协议注1”,服务端必须一次性返回订单的所有信息,包含订单主信息、商品、结算、配送、用户信息、骑手信息、餐损、退款、客服赔付(参照下面订单卡片截图)等,需要从下游三十多个服务中获取数据。在特定条件下,如第一次登录和长时间没登录的情况下,客户端会分页拉取多个订单,这样发起的远程调用会更多。
- 商家端和服务端交互频繁:商家对订单状态变化敏感,多种推拉机制保证每次变更能够触达商家,导致App和服务端的交互频繁,每次变更需要拉取订单最新的全部内容。
在外卖交易链路如此大的流量下,为了保证商家的用户体验,保证接口的高性能,并行从下游获取数据就成为必然。
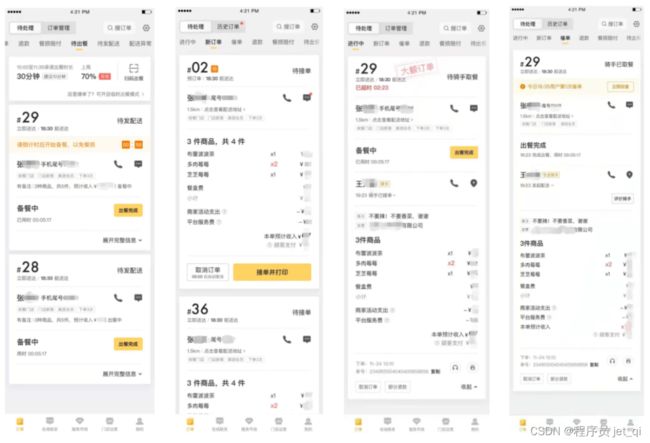
2、并行加载的实现方式
并行从下游获取数据,从IO模型上来讲分为同步模型和异步模型。
2.1、同步模型
从各个服务获取数据最常见的是同步调用,如下图所示:
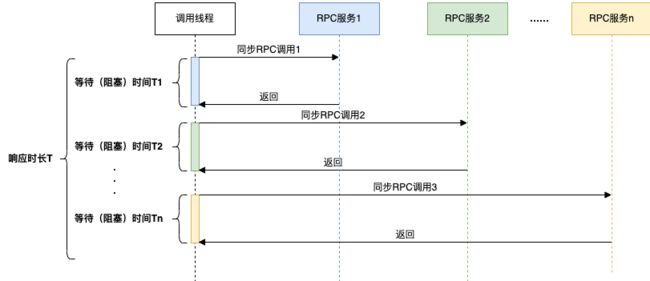
- 在同步调用的场景下,接口耗时长、性能差,接口响应时长T > T1+T2+T3+……+Tn,这时为了缩短接口的响应时间,一般会使用线程池的方式并行获取数据,商家端订单卡片的组装正是使用了这种方式。
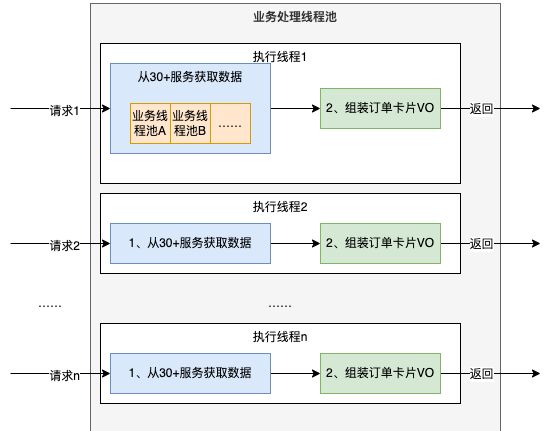
这种方式由于以下两个原因,导致资源利用率比较低:
- CPU资源大量浪费在阻塞等待上,导致CPU资源利用率低。在Java 8之前,一般会通过回调的方式来减少阻塞,但是大量使用回调,又引发臭名昭著的回调地狱问题,导致代码可读性和可维护性大大降低。
- 为了增加并发度,会引入更多额外的线程池,随着CPU调度线程数的增加,会导致更严重的资源争用,宝贵的CPU资源被损耗在上下文切换上,而且线程本身也会占用系统资源,且不能无限增加。
同步模型下,会导致硬件资源无法充分利用,系统吞吐量容易达到瓶颈。
2.2、NIO异步模型
我们主要通过以下两种方式来减少线程池的调度开销和阻塞时间:
- 通过RPC NIO异步调用的方式可以降低线程数,从而降低调度(上下文切换)开销,如Dubbo的异步调用可以参考《dubbo调用端异步》一文。
- 通过引入CompletableFuture(下文简称CF)对业务流程进行编排,降低依赖之间的阻塞。本文主要讲述CompletableFuture的使用和原理。
2.3、为什么会选择CompletableFuture?
我们首先对业界广泛流行的解决方案做了横向调研,主要包括Future、CompletableFuture、RxJava、Reactor。它们的特性对比如下:
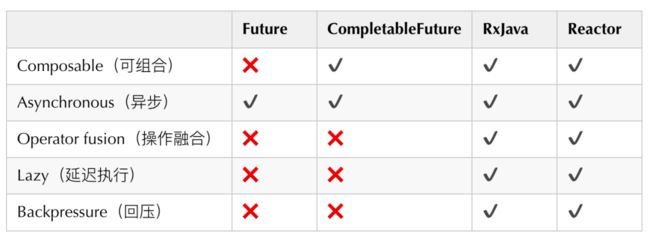
- 可组合:可以将多个依赖操作通过不同的方式进行编排,例如CompletableFuture提供 thenCompose、thenCombine 等各种then开头的方法,这些方法就是对“可组合”特性的支持。
- 操作融合:将数据流中使用的多个操作符以某种方式结合起来,进而降低开销(时间、内存)。
- 延迟执行:操作不会立即执行,当收到明确指示时操作才会触发。例如Reactor只有当有订阅者订阅时,才会触发操作。
- 回压:某些异步阶段的处理速度跟不上,直接失败会导致大量数据的丢失,对业务来说是不能接受的,这时需要反馈上游生产者降低调用量。
RxJava与Reactor显然更加强大,它们提供了更多的函数调用方式,支持更多特性,但同时也带来了更大的学习成本。而我们本次整合最需要的特性就是 “异步”、“可组合”,综合考虑后,我们选择了学习成本相对较低的 CompletableFuture。
3、CompletableFuture使用与原理
3.1、CompletableFuture的背景和定义
1、CompletableFuture解决的问题
CompletableFuture 是由Java 8引入的,在Java8之前我们一般通过Future实现异步。
- Future用于表示异步计算的结果,只能通过阻塞或者轮询的方式获取结果,而且不支持设置回调方法,Java 8之前若要设置回调一般会使用guava的 ListenableFuture,回调的引入又会导致臭名昭著的回调地狱(下面的例子会通过ListenableFuture 的使用来具体进行展示)。
- CompletableFuture 对 Future进行了扩展,可以通过设置回调的方式处理计算结果,同时也支持组合操作,支持进一步的编排,同时一定程度解决了回调地狱的问题。
下面将举例来说明,我们通过 ListenableFuture、CompletableFuture 来实现异步的差异。假设有三个操作step1、step2、step3存在依赖关系,其中step3的执行依赖step1和step2的结果。
Future(ListenableFuture)的实现(回调地狱)如下:
ExecutorService executor = Executors.newFixedThreadPool(5);
ListeningExecutorService guavaExecutor = MoreExecutors.listeningDecorator(executor);
ListenableFuture<String> future1 = guavaExecutor.submit(() -> {
//step 1
System.out.println("执行step 1");
return "step1 result";
});
ListenableFuture<String> future2 = guavaExecutor.submit(() -> {
//step 2
System.out.println("执行step 2");
return "step2 result";
});
ListenableFuture<List<String>> future1And2 = Futures.allAsList(future1, future2);
Futures.addCallback(future1And2, new FutureCallback<List<String>>() {
@Override
public void onSuccess(List<String> result) {
System.out.println(result);
ListenableFuture<String> future3 = guavaExecutor.submit(() -> {
System.out.println("执行step 3");
return "step3 result";
});
Futures.addCallback(future3, new FutureCallback<String>() {
@Override
public void onSuccess(String result) {
System.out.println(result);
}
@Override
public void onFailure(Throwable t) {
}
}, guavaExecutor);
}
@Override
public void onFailure(Throwable t) {
}}, guavaExecutor);
CompletableFuture 的实现如下:
ExecutorService executor = Executors.newFixedThreadPool(5);
// supplyAsync 表示执行一个异步方法
CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {
System.out.println("执行step 1");
return "step1 result";
}, executor);
CompletableFuture<String> cf2 = CompletableFuture.supplyAsync(() -> {
System.out.println("执行step 2");
return "step2 result";
});
cf1.thenCombine(cf2, (result1, result2) -> {
System.out.println(result1 + " , " + result2);
System.out.println("执行step 3");
return "step3 result";
// thenAccept 表示执行成功后再串联另外一个异步方法
}).thenAccept(result3 -> System.out.println(result3));
显然,CompletableFuture 的实现更为简洁,可读性更好。
2、CompletableFuture 的定义
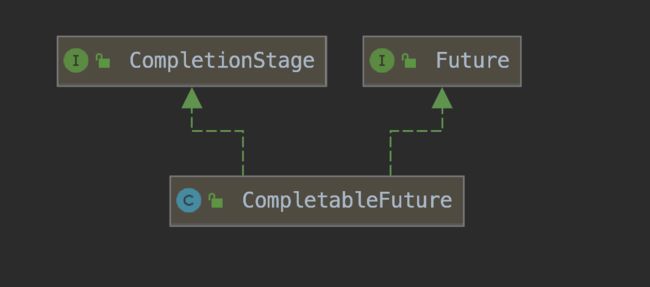
CompletableFuture 实现了两个接口(如上图所示):Future、CompletionStage。Future表示异步计算的结果,CompletionStage 用于表示异步执行过程中的一个步骤(Stage),这个步骤可能是由另外一个 CompletionStage 触发的,随着当前步骤的完成,也可能会触发其他一系列 CompletionStage 的执行。从而我们可以根据实际业务对这些步骤进行多样化的编排组合,CompletionStage接口正是定义了这样的能力,我们可以通过其提供的thenAppy、thenCompose 等函数式编程方法来组合编排这些步骤。
3.2、CompletableFuture 的使用
下面我们通过一个例子来讲解 CompletableFuture 如何使用,使用CompletableFuture也是构建依赖树的过程。一个CompletableFuture 的完成会触发另外一系列依赖它的 CompletableFuture 的执行:
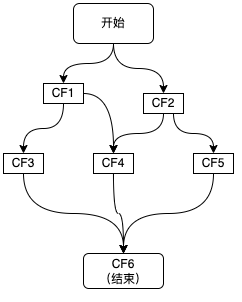
如上图所示,这里描绘的是一个业务接口的流程,其中包括CF1\CF2\CF3\CF4\CF5共5个步骤,并描绘了这些步骤之间的依赖关系,每个步骤可以是一次RPC调用、一次数据库操作或者是一次本地方法调用等,在使用CompletableFuture进行异步化编程时,图中的每个步骤都会产生一个CompletableFuture对象,最终结果也会用一个CompletableFuture来进行表示。
根据CompletableFuture依赖数量,可以分为以下几类:零依赖、一元依赖、二元依赖和多元依赖。
1、零依赖:CompletableFuture的创建
我们先看下如何不依赖其他 CompletableFuture 来创建新的 CompletableFuture:
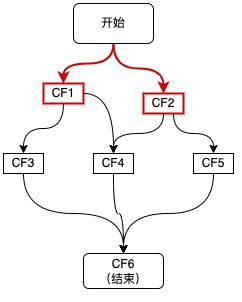
如上图红色链路所示,接口接收到请求后,首先发起两个异步调用CF1、CF2,主要有三种方式:
ExecutorService executor = Executors.newFixedThreadPool(5);
//1、使用 runAsync 或 supplyAsync 发起异步调用
CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {
return "result1";
}, executor);
//2、CompletableFuture.completedFuture() 直接创建一个已完成状态的 CompletableFuture
CompletableFuture<String> cf2 = CompletableFuture.completedFuture("result2");
//3、先初始化一个未完成的CompletableFuture,然后通过complete()、completeExceptionally(),完成该CompletableFuture
CompletableFuture<String> cf = new CompletableFuture<>();
cf.complete("success");
第三种方式的一个典型使用场景,就是将回调方法转为 CompletableFuture,然后再依赖 CompletableFuture 的能力进行调用编排,示例如下:
@FunctionalInterface
public interface ThriftAsyncCall {
void invoke() throws TException;
}
/**
* 该方法为美团内部 rpc 注册监听的封装,可以作为其他实现的参照
* OctoThriftCallback 为thrift回调方法
* ThriftAsyncCall 为自定义函数,用来表示一次thrift调用(定义如上)
*/
public static <T> CompletableFuture<T> toCompletableFuture(final OctoThriftCallback<?,T> callback, ThriftAsyncCall thriftCall) {
//新建一个未完成的CompletableFuture
CompletableFuture<T> resultFuture = new CompletableFuture<>();
//监听回调的完成,并且与CompletableFuture同步状态
callback.addObserver(new OctoObserver<T>() {
@Override
public void onSuccess(T t) {
resultFuture.complete(t);
}
@Override
public void onFailure(Throwable throwable) {
resultFuture.completeExceptionally(throwable);
}
});
if (thriftCall != null) {
try {
thriftCall.invoke();
} catch (TException e) {
resultFuture.completeExceptionally(e);
}
}
return resultFuture;
}
2、一元依赖:依赖一个CF
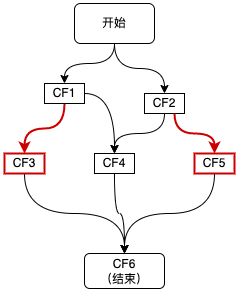
如上图红色链路所示,CF3,CF5分别依赖于CF1和CF2,这种对于单个 CompletableFuture 的依赖可以通过 thenApply、thenAccept、thenCompose 等方法来实现,代码如下所示:
CompletableFuture<String> cf3 = cf1.thenApply(result1 -> {
//result1为CF1的结果
//......
return "result3";
});
CompletableFuture<String> cf5 = cf2.thenApply(result2 -> {
//result2为CF2的结果
//......
return "result5";
});
3、二元依赖:依赖两个CF
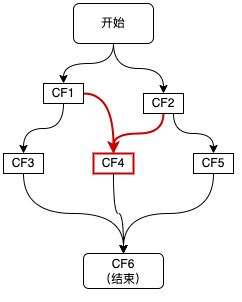
如上图红色链路所示,CF4同时依赖于两个CF1和CF2,这种二元依赖可以通过 thenCombine 等回调来实现,如下代码所示:
CompletableFuture<String> cf4 = cf1.thenCombine(cf2, (result1, result2) -> {
//result1和result2分别为cf1和cf2的结果
return "result4";
});
4、多元依赖:依赖多个CF
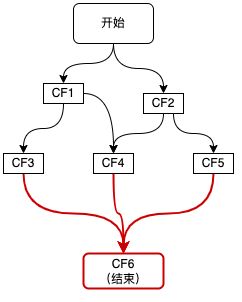
如上图红色链路所示,整个流程的结束依赖于三个步骤CF3、CF4、CF5,这种多元依赖可以通过allOf或anyOf方法来实现,区别是当需要多个依赖全部完成时使用allOf,当多个依赖中的任意一个完成即可时使用anyOf,如下代码所示:
CompletableFuture<Void> cf6 = CompletableFuture.allOf(cf3, cf4, cf5);
CompletableFuture<String> result = cf6.thenApply(v -> {
// 这里的join并不会阻塞,因为传给thenApply的函数是在CF3、CF4、CF5全部完成时,才会执行。
result3 = cf3.join();
result4 = cf4.join();
result5 = cf5.join();
// 根据result3、result4、result5组装最终result;
return "result";
});
3.3、CompletableFuture原理
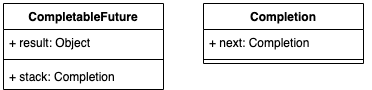
CompletableFuture 中包含两个字段:**result **和 stack。result用于存储当前CF的结果,stack(Completion)表示当前CF完成后需要触发的依赖动作(Dependency Actions),去触发依赖它的CF的计算,依赖动作可以有多个(表示有多个依赖它的CF),以栈(Treiber stack)的形式存储,stack表示栈顶元素。
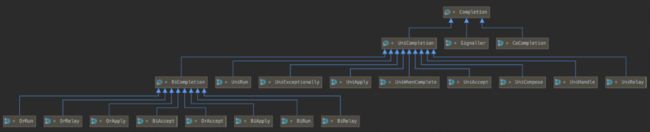
这种方式类似 “观察者模式”,依赖动作(Dependency Action)都封装在一个单独Completion子类中。下面是Completion类关系结构图。CompletableFuture 中的每个方法都对应了图中的一个 Completion 的子类,Completion 本身是观察者的基类。
- UniCompletion 继承了Completion,是一元依赖的基类,例如thenApply的实现类UniApply就继承自UniCompletion。
- BiCompletion 继承了UniCompletion,是二元依赖的基类,同时也是多元依赖的基类。例如 thenCombine 的实现类 BiRelay 就继承自BiCompletion。
1、CompletableFuture的设计思想
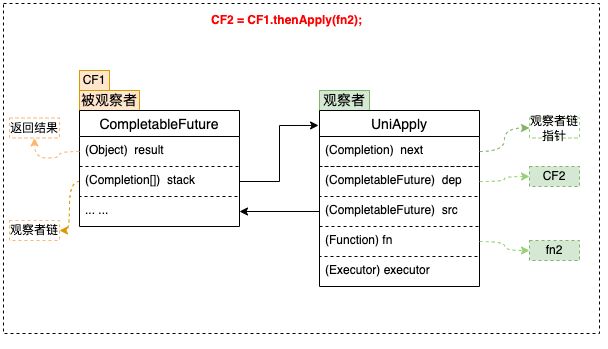
按照类似“观察者模式”的设计思想,原理分析可以从“观察者”和“被观察者”两个方面着手。由于回调种类多,但结构差异不大,所以这里单以一元依赖中的thenApply为例,不再枚举全部回调类型。如下图所示:
1 被观察者
- 每个 CompletableFuture 都可以被看作一个被观察者,其内部有一个Completion类型的链表成员变量stack,用来存储注册到其中的所有观察者。当被观察者执行完成后会弹栈stack属性,依次通知注册到其中的观察者。上面例子中步骤fn2就是作为观察者被封装在UniApply中。
- 被观察者CF中的result属性,用来存储返回结果数据。这里可能是一次RPC调用的返回值,也可能是任意对象,在上面的例子中对应步骤fn1的执行结果。
2 观察者
CompletableFuture 支持很多回调方法,例如 thenAccept、thenApply、exceptionally 等,这些方法接收一个函数类型的参数f,生成一个Completion类型的对象(即观察者),并将入参函数f赋值给Completion的成员变量fn,然后检查当前CF是否已处于完成状态(即result != null),如果已完成直接触发fn,否则将观察者Completion加入到CF的观察者链stack中,再次尝试触发,如果被观察者未执行完则其执行完毕之后通知触发。
- 观察者中的dep属性:指向其对应的 CompletableFuture,在上面的例子中 dep指向CF2。
- 观察者中的src属性:指向其依赖的 CompletableFuture,在上面的例子中 src指向CF1。
- 观察者 Completion 中的fn属性:用来存储具体的等待被回调的函数。这里需要注意的是不同的回调方法(thenAccept、thenApply、exceptionally等)接收的函数类型也不同,即fn的类型有很多种,在上面的例子中fn指向fn2。
2、整体流程
1、一元依赖
这里仍然以thenApply为例来说明一元依赖的流程:
- 将观察者Completion注册到CF1,此时CF1将Completion压栈。
- 当CF1的操作运行完成时,会将结果赋值给CF1中的result属性。
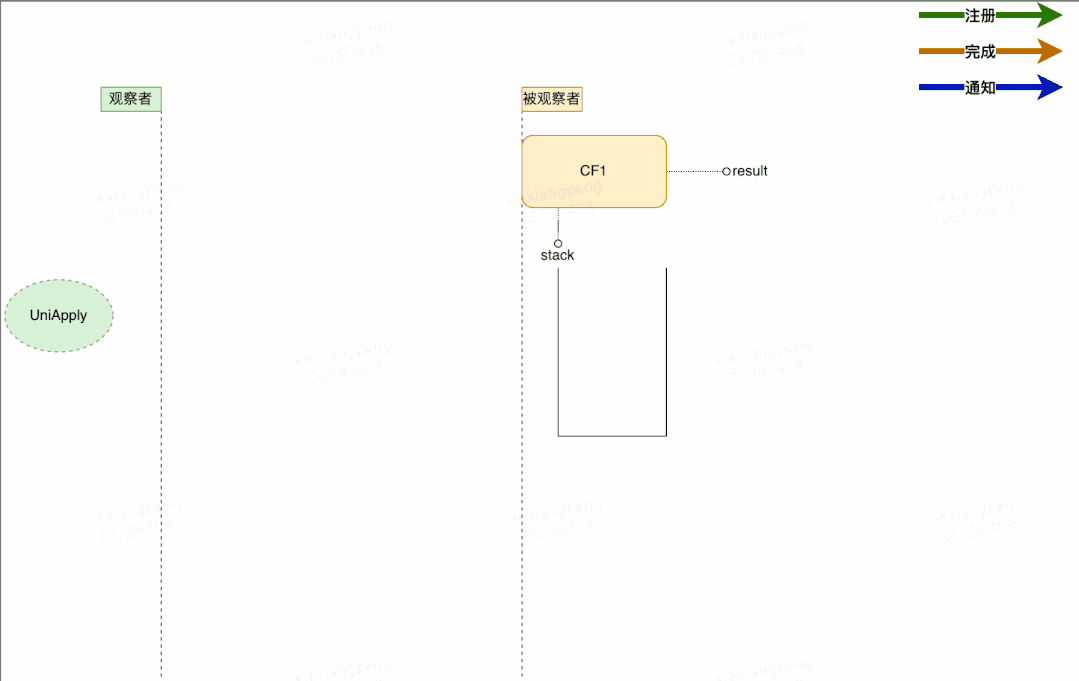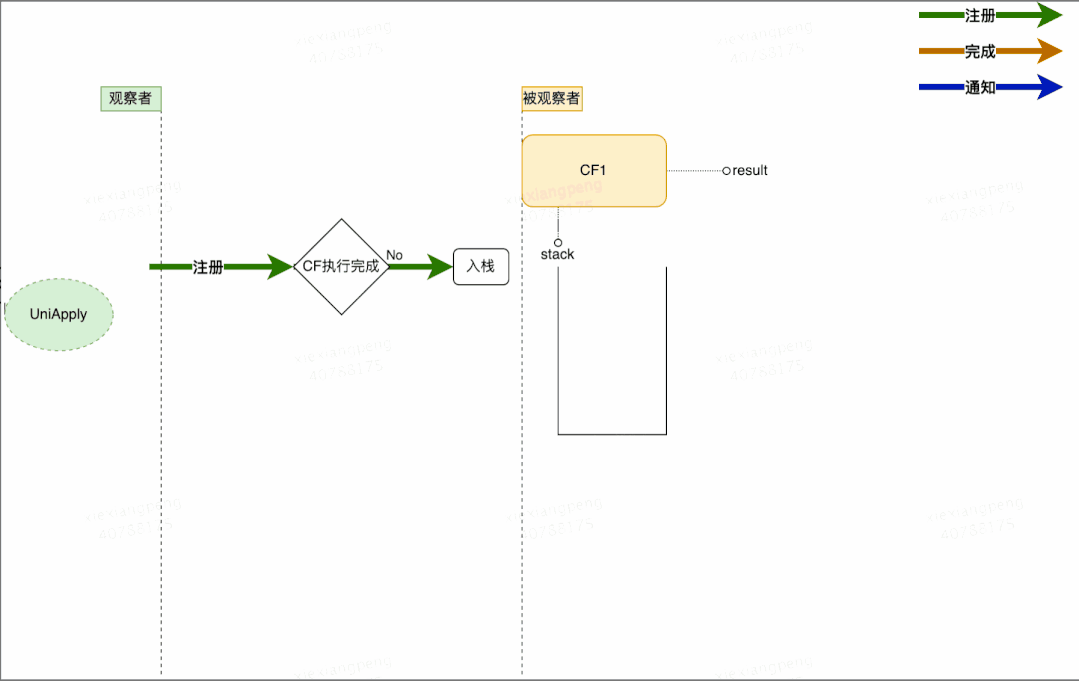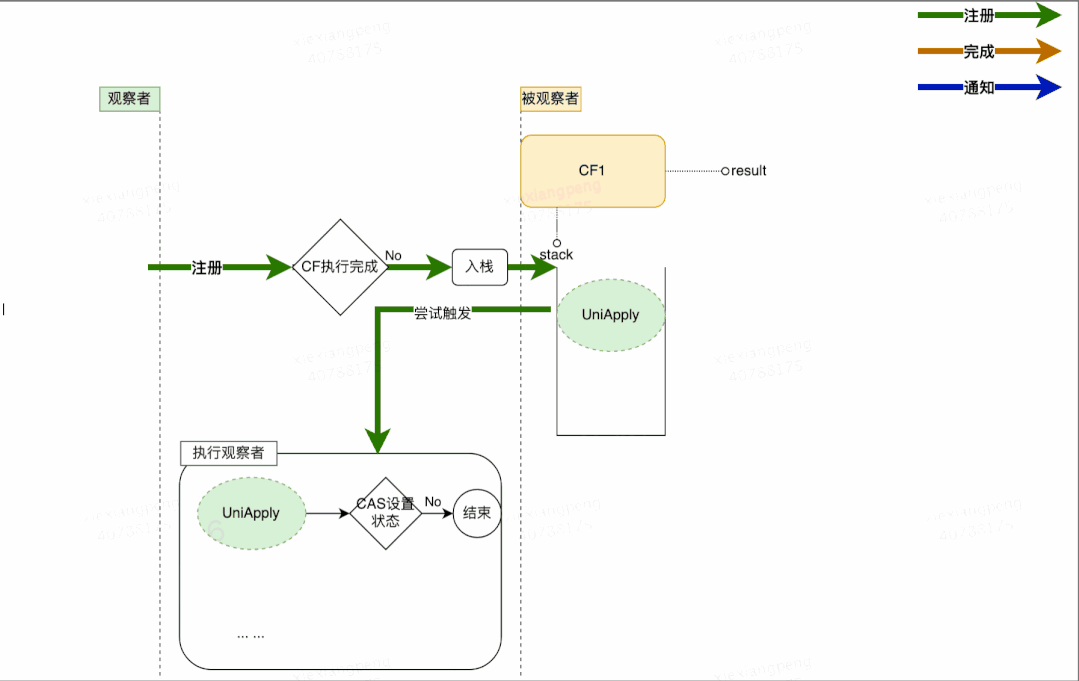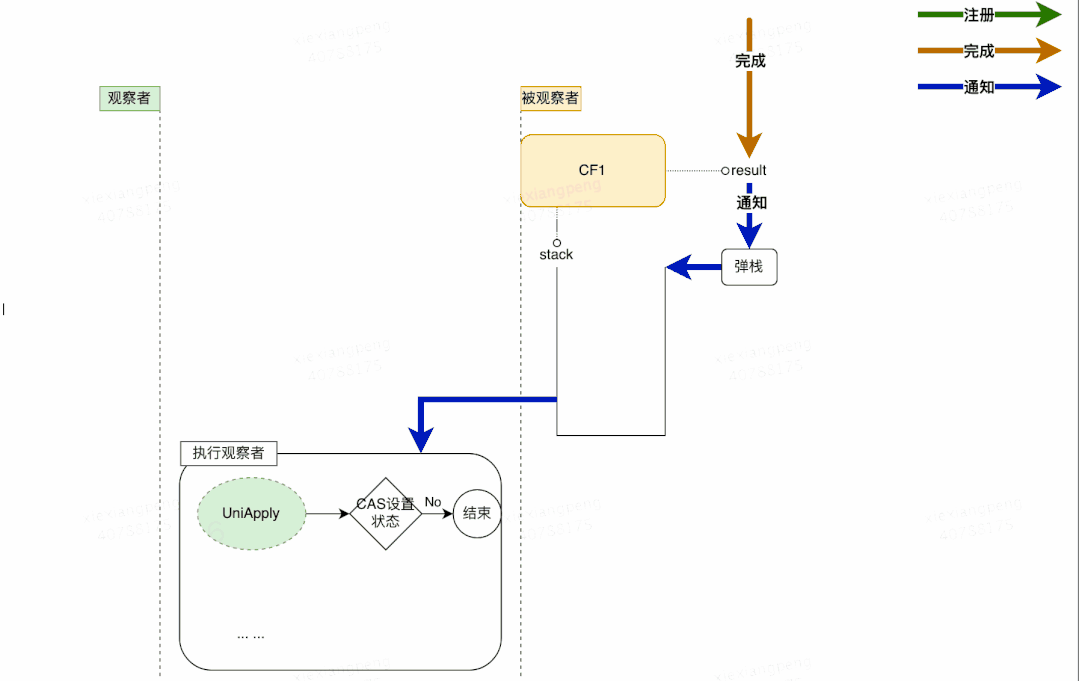
- 依次弹栈,通知观察者尝试运行。
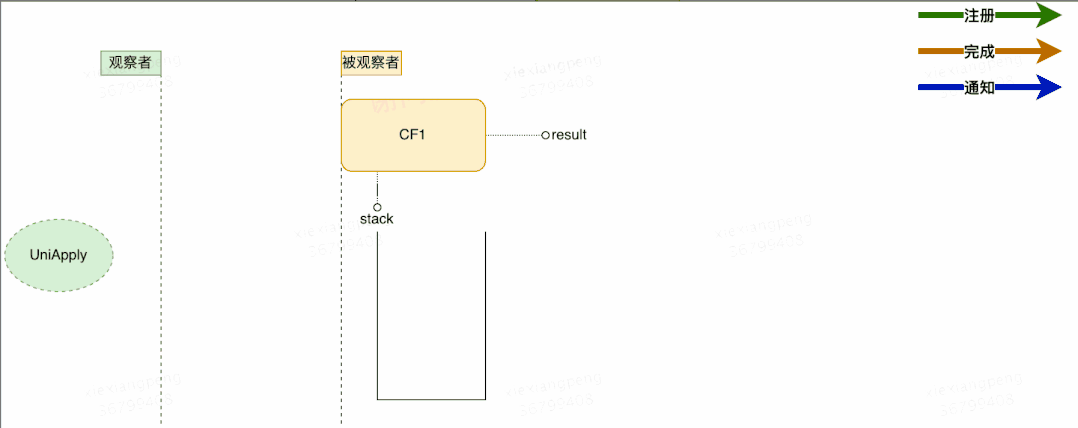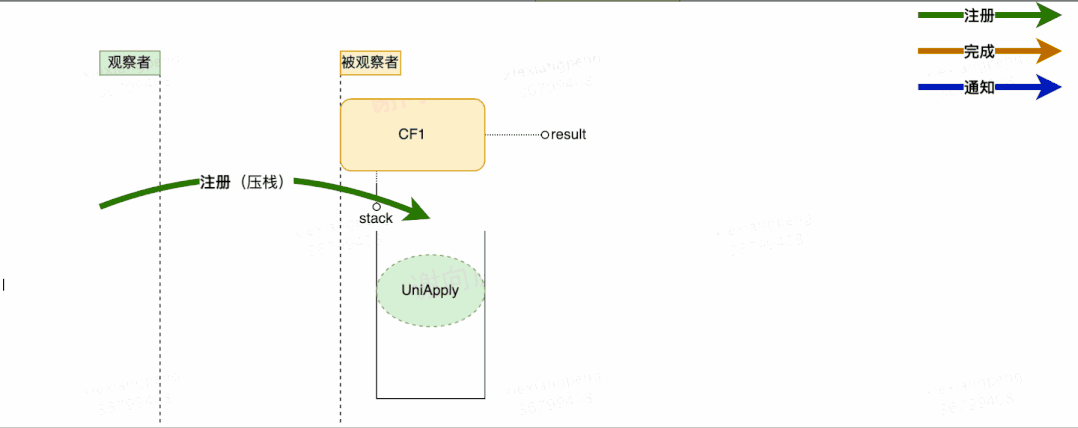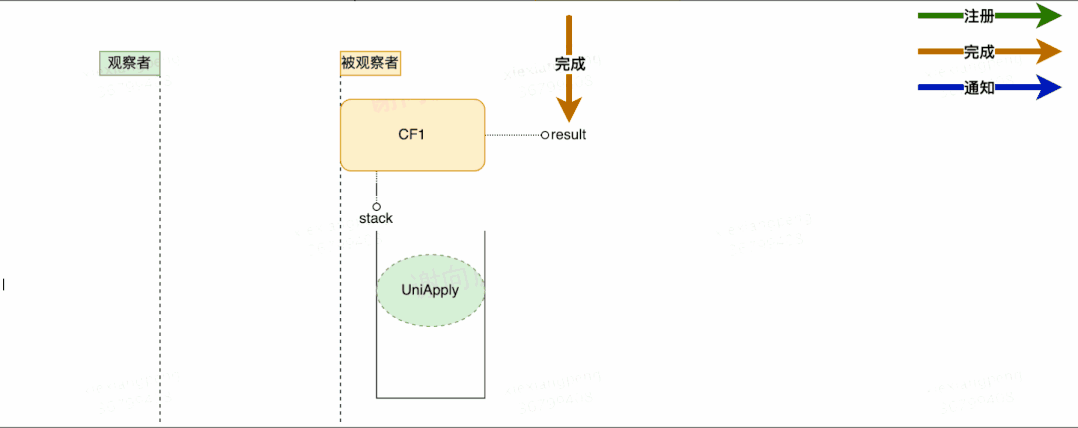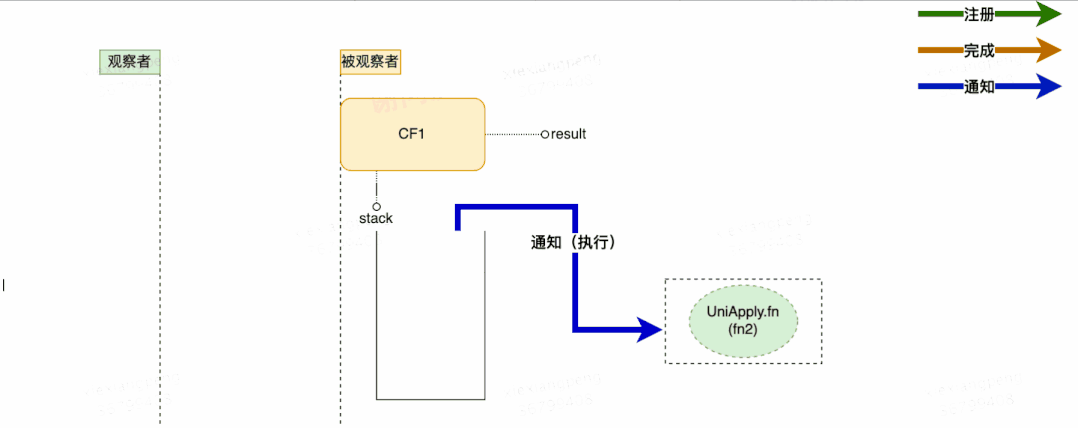
初步流程设计如上图所示,这里有几个关于注册与通知的并发问题,大家可以思考下:
Q1:在观察者注册之前,如果CF已经执行完成,并且已经发出通知,那么这时观察者由于错过了通知是不是将永远不会被触发呢 ?
A1:不会。在注册时检查依赖的CF是否已经完成。如果未完成(即result == null)则将观察者入栈,如果已完成(result != null)则直接触发观察者操作。
Q2:在”入栈“前会有”result == null“的判断,这两个操作为非原子操作,CompletableFuture的实现也没有对两个操作进行加锁,完成时间在这两个操作之间,观察者仍然得不到通知,是不是仍然无法触发?

A3:CompletableFuture 的实现是这样解决该问题的:观察者在执行之前会先通过CAS操作设置一个状态位,将status由0改为1。如果观察者已经执行过了,那么CAS操作将会失败,取消执行。
通过对以上3个问题的分析可以看出,CompletableFuture 在处理并行问题时,全程无加锁操作,极大地提高了程序的执行效率。我们将并行问题考虑纳入之后,可以得到完善的整体流程图如下所示:
CompletableFuture 支持的回调方法十分丰富,但是正如上一章节的整体流程图所述,他们的整体流程是一致的。所有回调复用同一套流程架构,不同的回调监听通过策略模式实现差异化。
2、二元依赖
我们以thenCombine为例来说明二元依赖:
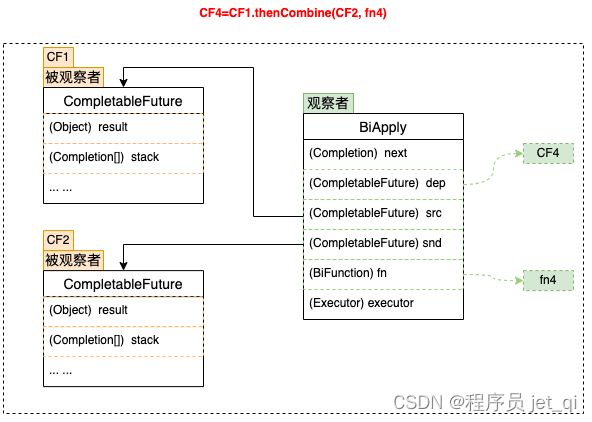
thenCombine操作表示依赖两个 CompletableFuture。其观察者实现类为BiApply,如上图所示,BiApply通过src和snd两个属性关联被依赖的两个CF,fn属性的类型为 BiFunction。与单个依赖不同的是,在依赖的CF未完成的情况下,thenCombine会尝试将BiApply压入这两个被依赖的CF的栈中,每个被依赖的CF完成时都会尝试触发观察者BiApply,BiApply会检查两个依赖是否都完成,如果完成则开始执行。这里为了解决重复触发的问题,同样用的是上一章节提到的CAS操作,执行时会先通过CAS设置状态位,避免重复触发。
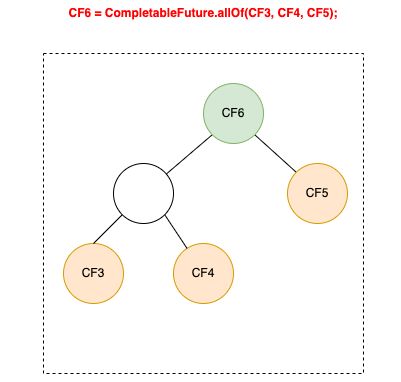
3 多元依赖
依赖多个 CompletableFuture 的回调方法包括allOf、anyOf,区别在于allOf观察者实现类为BiRelay,需要所有被依赖的CF完成后才会执行回调;而anyOf观察者实现类为OrRelay,任意一个被依赖的CF完成后就会触发。二者的实现方式都是将多个被依赖的CF构建成一棵平衡二叉树,执行结果层层通知,直到根节点,触发回调监听。
3、小结
本章节为 CompletableFuture 实现原理的科普,旨在尝试不粘贴源码,而通过**结构图、流程图以及搭配文字描述 **把CompletableFuture的实现原理讲述清楚。把晦涩的源码翻译为“整体流程”章节的流程图,并且将并发处理的逻辑融入,便于大家理解。
4、实践总结 ☆
在商家端API异步化的过程中,我们遇到了一些问题,这些问题有的会比较隐蔽,下面把这些问题的处理经验整理出来。希望能帮助到更多的同学,大家可以少踩一些坑。
4.1、线程阻塞问题
1、代码执行在哪个线程上?
要合理治理线程资源,最基本的前提条件就是要在写代码时,清楚地知道每一行代码都将执行在哪个线程上。下面我们看一下CompletableFuture的执行线程情况。
CompletableFuture实现了CompletionStage接口,通过丰富的回调方法,支持各种组合操作,每种组合场景都有同步和异步两种方法。
同步方法(即不带Async后缀的方法)有两种情况。
- 如果注册时被依赖的操作已经执行完成,则直接由当前线程执行。
- 如果注册时被依赖的操作还未执行完,则由回调线程执行。
异步方法(即带 Async 后缀的方法):可以选择是否传递线程池参数 Executor 运行在指定线程池中;当不传递 Executor 时,会使用ForkJoinPool 中的共用线程池 CommonPool(CommonPool 的大小是CPU核数-1,如果是IO密集的应用,线程数可能成为瓶颈)。
例如:
ExecutorService threadPool1 = new ThreadPoolExecutor(10, 10, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(100));
CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() -> {
System.out.println("supplyAsync 执行线程:" + Thread.currentThread().getName());
//业务操作
return "";
}, threadPool1);
// 同步方法
// 场景1:如果future1中的业务操作已经执行完毕并返回,则该thenApply直接由当前main线程执行;
// 场景2:future1待执行,将会由执行以上业务操作的threadPool1 中的线程执行。
future1.thenApply(value -> {
System.out.println("thenApply 执行线程:" + Thread.currentThread().getName());
return value + "1";
});
// 异步方法
// 场景1:使用 ForkJoinPool 中的共用线程池 CommonPool
future1.thenApplyAsync(value -> {
//do something
return value + "1";
});
//场景2:使用指定线程池
future1.thenApplyAsync(value -> {
//do something
return value + "1";
}, threadPool1);
4.2、线程池须知
1、异步回调要传线程池 ☆
前面提到,异步回调方法可以选择是否传递线程池参数 Executor,这里我们建议强制传线程池,且根据实际情况做线程池隔离。
当不传递线程池时,会使用ForkJoinPool中的公共线程池CommonPool,这里所有调用将共用该线程池,核心线程数=处理器数量-1(单核核心线程数为1),所有异步回调都会共用该CommonPool,核心与非核心业务都竞争同一个池中的线程,很容易成为系统瓶颈。手动传递线程池参数可以更方便的调节参数,并且可以给不同的业务分配不同的线程池,以求资源隔离,减少不同业务之间的相互干扰。
2、线程池循环引用会导致死锁
public Object doGet() {
ExecutorService threadPool1 = new ThreadPoolExecutor(10, 10, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(100));
CompletableFuture cf1 = CompletableFuture.supplyAsync(() -> {
//do sth
return CompletableFuture.supplyAsync(() -> {
System.out.println("child");
return "child";
}, threadPool1).join();//子任务
}, threadPool1);
return cf1.join();
}
如上代码块所示,doGet方法第三行通过supplyAsync向threadPool1请求线程,并且内部子任务又向threadPool1请求线程。threadPool1大小为10,当同一时刻有10个请求到达,则threadPool1被打满,子任务请求线程时进入阻塞队列排队,但是父任务的完成又依赖于子任务,这时由于子任务得不到线程,父任务无法完成。主线程执行cf1.join()进入阻塞状态,并且永远无法恢复。
为了修复该问题,需要将父任务与子任务做线程池隔离,两个任务请求不同的线程池,避免循环依赖导致的阻塞。
3、异步RPC调用注意不要阻塞IO线程池
服务异步化后很多步骤都会依赖于异步RPC调用的结果,这时需要特别注意一点,如果是使用基于NIO(比如Netty)的异步RPC,则返回结果是由IO线程负责设置的,即回调方法由IO线程触发,CompletableFuture同步回调(如thenApply、thenAccept等无Async后缀的方法)如果依赖的异步RPC调用的返回结果,那么这些同步回调将运行在IO线程上,而整个服务只有一个IO线程池,这时需要保证同步回调中不能有阻塞等耗时过长的逻辑,否则在这些逻辑执行完成前,IO线程将一直被占用,影响整个服务的响应。
4.3、其他
1、异常处理
由于异步执行的任务在其他线程上执行,而异常信息存储在线程栈中,因此当前线程除非阻塞等待返回结果,否则无法通过try\catch捕获异常。CompletableFuture 提供了异常捕获回调 exceptionally,相当于同步调用中的try\catch。使用方法如下所示:
@Autowired
private WmOrderAdditionInfoThriftService wmOrderAdditionInfoThriftService;//内部接口
public CompletableFuture<Integer> getCancelTypeAsync(long orderId) {
//业务方法,内部会发起异步rpc调用
CompletableFuture<WmOrderOpRemarkResult> remarkResultFuture = wmOrderAdditionInfoThriftService.findOrderCancelledRemarkByOrderIdAsync(orderId);
return remarkResultFuture
//通过 exceptionally 捕获异常,打印日志并返回默认值
.exceptionally(err -> {
log.error("WmOrderRemarkService.getCancelTypeAsync Exception orderId={}", orderId, err);
return 0;
});
}
有一点需要注意,CompletableFuture 在回调方法中对异常进行了包装。大部分异常会封装成CompletionException后抛出,真正的异常存储在cause属性中,因此如果调用链中经过了回调方法处理那么就需要用Throwable.getCause() 方法提取真正的异常。但是,有些情况下会直接返回真正的异常(Stack Overflow的讨论),最好使用工具类提取异常(参考晓断的代码),如下代码所示:
@Autowired
private WmOrderAdditionInfoThriftService wmOrderAdditionInfoThriftService;//内部接口
public CompletableFuture<Integer> getCancelTypeAsync(long orderId) {
//业务方法,内部会发起异步rpc调用
CompletableFuture<WmOrderOpRemarkResult> remarkResultFuture = wmOrderAdditionInfoThriftService.findOrderCancelledRemarkByOrderIdAsync(orderId);
return remarkResultFuture
//这里增加了一个回调方法thenApply,如果发生异常thenApply内部会通过 new CompletionException(throwable) 对异常进行包装
.thenApply(result -> {
//这里是一些业务操作
})
// 通过 exceptionally 捕获异常,这里的err已经被thenApply包装过,因此需要通过 Throwable.getCause() 提取异常
.exceptionally(err -> {
log.error("WmOrderRemarkService.getCancelTypeAsync Exception orderId={}", orderId, ExceptionUtils.extractRealException(err));
return 0;
});
}
上面代码中用到了一个自定义的工具类 ExceptionUtils,用于 CompletableFuture的异常提取,在使用 CompletableFuture做异步编程时,可以直接使用该工具类处理异常。实现代码如下:
public class ExceptionUtils {
public static Throwable extractRealException(Throwable throwable) {
// 这里判断异常类型是否为CompletionException、ExecutionException,如果是则进行提取,否则直接返回。
if (throwable instanceof CompletionException || throwable instanceof ExecutionException) {
if (throwable.getCause() != null) {
return throwable.getCause();
}
}
return throwable;
}
}
2、沉淀的工具方法介绍
在实践过程中我们沉淀了一些通用的工具方法,在使用CompletableFuture开发时可以直接拿来使用,详情参见“附录”。
4.4、异步编排在商品中心的应用
场景1:使用异步编排优化商品详情页
场景2:推送SPU获取商品条码
场景3:商品审核前,封装获取批量审核的商品数据
场景4:获取服务商品管理列表
场景5:校验存在风险的SPU
场景6:构建前台类目树时,异步刷新redis里的失效时间
场景7:平台商品创建前组装商品数据
场景8:平台商品审核前组装商品数据
场景9:异步校验风险商品
场景10:商品发布时,并行填充类目规则:类目属性、填充发布方式、填充spu强控信息
场景11:查询类目使用情况
4.5、异步编排在中间件的应用
1、Dubbo 通过RPC NIO异步调用的方式可以降低线程数,从而降低调度(上下文切换)开销,
- Dubbo的异步调用可以参考《dubbo调用端异步》一文。
Action1:MQ有没有提供异常捕获回调方法呢?
5、项目结果:异步化收益
通过异步化改造,美团商家端API系统的性能得到明显提升,与改造前对比的收益如下:
- 核心接口吞吐量大幅提升,其中订单轮询接口改造前TP99为754ms,改造后降为408ms。
- 服务器数量减少1/3。
6、参考文献
- CompletableFuture (Java Platform SE 8 )
- java - Does CompletionStage always wrap exceptions in CompletionException? - Stack Overflow
- exception - Surprising behavior of Java 8 CompletableFuture exceptionally method - Stack Overflow
- 文档 | Apache Dubbo
7、名词解释及备注
注1:“增量同步” 是指商家客户端与服务端之间的订单增量数据同步协议,客户端使用该协议获取新增订单以及状态发生变化的订单。
注2:本文涉及到的所有技术点依赖的Java版本为JDK 8,CompletableFuture支持的特性分析也是基于该版本。
8、附录
8.1、自定义函数
@FunctionalInterface
public interface ThriftAsyncCall {
void invoke() throws TException;
}
8.2、CompletableFuture 处理工具类
/**
* CompletableFuture封装工具类
*/
@Slf4j
public class FutureUtils {
/**
* 该方法为美团内部rpc注册监听的封装,可以作为其他实现的参照
* OctoThriftCallback 为thrift回调方法
* ThriftAsyncCall 为自定义函数,用来表示一次thrift调用(定义如上)
*/
public static <T> CompletableFuture<T> toCompletableFuture(final OctoThriftCallback<?,T> callback, ThriftAsyncCall thriftCall) {
CompletableFuture<T> thriftResultFuture = new CompletableFuture<>();
callback.addObserver(new OctoObserver<T>() {
@Override
public void onSuccess(T t) {
thriftResultFuture.complete(t);
}
@Override
public void onFailure(Throwable throwable) {
thriftResultFuture.completeExceptionally(throwable);
}
});
if (thriftCall != null) {
try {
thriftCall.invoke();
} catch (TException e) {
thriftResultFuture.completeExceptionally(e);
}
}
return thriftResultFuture;
}
/**
* 设置CF状态为失败
*/
public static <T> CompletableFuture<T> failed(Throwable ex) {
CompletableFuture<T> completableFuture = new CompletableFuture<>();
completableFuture.completeExceptionally(ex);
return completableFuture;
}
/**
* 设置CF状态为成功
*/
public static <T> CompletableFuture<T> success(T result) {
CompletableFuture<T> completableFuture = new CompletableFuture<>();
completableFuture.complete(result);
return completableFuture;
}
/**
* 将List> 转为 CompletableFuture>
*/
public static <T> CompletableFuture<List<T>> sequence(Collection<CompletableFuture<T>> completableFutures) {
return CompletableFuture.allOf(completableFutures.toArray(new CompletableFuture<?>[0]))
.thenApply(v -> completableFutures.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList())
);
}
/**
* 将List>> 转为 CompletableFuture>
* 多用于分页查询的场景
*/
public static <T> CompletableFuture<List<T>> sequenceList(Collection<CompletableFuture<List<T>>> completableFutures) {
return CompletableFuture.allOf(completableFutures.toArray(new CompletableFuture<?>[0]))
.thenApply(v -> completableFutures.stream()
.flatMap(listFuture -> listFuture.join().stream())
.collect(Collectors.toList())
);
}
/*
* 将 List>> 转为 CompletableFuture>
* @Param mergeFunction 自定义key冲突时的 merge 策略
*/
public static <K, V> CompletableFuture<Map<K, V>> sequenceMap (
Collection<CompletableFuture<Map<K, V>>> completableFutures, BinaryOperator<V> mergeFunction) {
return CompletableFuture
.allOf(completableFutures.toArray(new CompletableFuture<?>[0]))
.thenApply(v -> completableFutures.stream()
.map(CompletableFuture::join)
.flatMap(map -> map.entrySet().stream())
.collect(Collectors.toMap(Entry::getKey, Entry::getValue, mergeFunction)));
}
/**
* 将List> 转为 CompletableFuture>,并过滤调null值
*/
public static <T> CompletableFuture<List<T>> sequenceNonNull(Collection<CompletableFuture<T>> completableFutures) {
return CompletableFuture.allOf(completableFutures.toArray(new CompletableFuture<?>[0]))
.thenApply(v -> completableFutures.stream()
.map(CompletableFuture::join)
.filter(e -> e != null)
.collect(Collectors.toList())
);
}
/**
* 将List>> 转为 CompletableFuture>,并过滤调null值
* 多用于分页查询的场景
*/
public static <T> CompletableFuture<List<T>> sequenceListNonNull(Collection<CompletableFuture<List<T>>> completableFutures) {
return CompletableFuture.allOf(completableFutures.toArray(new CompletableFuture<?>[0]))
.thenApply(v -> completableFutures.stream()
.flatMap( listFuture -> listFuture.join().stream().filter(e -> e != null))
.collect(Collectors.toList())
);
}
/**
* 将List>> 转为 CompletableFuture>
* @Param filterFunction 自定义过滤策略
*/
public static <T> CompletableFuture<List<T>> sequence(Collection<CompletableFuture<T>> completableFutures,
Predicate<? super T> filterFunction) {
return CompletableFuture.allOf(completableFutures.toArray(new CompletableFuture<?>[0]))
.thenApply(v -> completableFutures.stream()
.map(CompletableFuture::join)
.filter(filterFunction)
.collect(Collectors.toList())
);
}
/**
* 将List>> 转为 CompletableFuture>
* @Param filterFunction 自定义过滤策略
*/
public static <T> CompletableFuture<List<T>> sequenceList(Collection<CompletableFuture<List<T>>> completableFutures,
Predicate<? super T> filterFunction) {
return CompletableFuture.allOf(completableFutures.toArray(new CompletableFuture<?>[0]))
.thenApply(v -> completableFutures.stream()
.flatMap( listFuture -> listFuture.join().stream().filter(filterFunction))
.collect(Collectors.toList())
);
}
/**
* 将 CompletableFuture> 的list转为 CompletableFuture>。 多个map合并为一个map。 如果key冲突,采用新的value覆盖。
*/
public static <K, V> CompletableFuture<Map<K, V>> sequenceMap(
Collection<CompletableFuture<Map<K, V>>> completableFutures) {
return CompletableFuture
.allOf(completableFutures.toArray(new CompletableFuture<?>[0]))
.thenApply(v -> completableFutures.stream().map(CompletableFuture::join)
.flatMap(map -> map.entrySet().stream())
.collect(Collectors.toMap(Entry::getKey, Entry::getValue, (a, b) -> b)));
}}
8.3、异常提取工具类
public class ExceptionUtils {
/**
* 提取真正的异常
*/
public static Throwable extractRealException(Throwable throwable) {
if (throwable instanceof CompletionException || throwable instanceof ExecutionException) {
if (throwable.getCause() != null) {
return throwable.getCause();
}
}
return throwable;
}
}
8.4、打印日志
@Slf4j
public abstract class AbstractLogAction<R> {
protected final String methodName;
protected final Object[] args;
public AbstractLogAction(String methodName, Object... args) {
this.methodName = methodName;
this.args = args;
}
protected void logResult(R result, Throwable throwable) {
if (throwable != null) {
boolean isBusinessError = throwable instanceof TBase || (throwable.getCause() != null && throwable
.getCause() instanceof TBase);
if (isBusinessError) {
logBusinessError(throwable);
} else if (throwable instanceof DegradeException || throwable instanceof DegradeRuntimeException) {//这里为内部rpc框架抛出的异常,使用时可以酌情修改
if (RhinoSwitch.getBoolean("isPrintDegradeLog", false)) {
log.error("{} degrade exception, param:{} , error:{}", methodName, args, throwable);
}
} else {
log.error("{} unknown error, param:{} , error:{}", methodName, args, ExceptionUtils.extractRealException(throwable));
}
} else {
if (isLogResult()) {
log.info("{} param:{} , result:{}", methodName, args, result);
} else {
log.info("{} param:{}", methodName, args);
}
}
}
private void logBusinessError(Throwable throwable) {
log.error("{} business error, param:{} , error:{}", methodName, args, throwable.toString(), ExceptionUtils.extractRealException(throwable));
}
private boolean isLogResult() {
//这里是动态配置开关,用于动态控制日志打印,开源动态配置中心可以使用nacos、apollo等,如果项目没有使用配置中心则可以删除
return RhinoSwitch.getBoolean(methodName + "_isLogResult", false);
}
}
8.5、日志处理实现类
/**
* 发生异常时,根据是否为业务异常打印日志。
* 跟 CompletableFuture.whenComplete 配合使用,不改变 completableFuture 的结果(正常OR异常)
*/
@Slf4j
public class LogErrorAction<R> extends AbstractLogAction<R> implements BiConsumer<R, Throwable> {
public LogErrorAction(String methodName, Object... args) {
super(methodName, args);
}
@Override
public void accept(R result, Throwable throwable) {
logResult(result, throwable);
}
}
8.6、打印日志方式
completableFuture.whenComplete(
new LogErrorAction<>("orderService.getOrder", params));
8.7、异常情况返回默认值
使用了Builder设计模式
/**
* 当发生异常时返回自定义的值
*/
public class DefaultValueHandle<R> extends AbstractLogAction<R> implements BiFunction<R, Throwable, R> {
private final R defaultValue;
/**
* 当返回值为空的时候是否替换为默认值
*/
private final boolean isNullToDefault;
/**
* @param methodName 方法名称
* @param defaultValue 当异常发生时自定义返回的默认值
* @param args 方法入参
*/
public DefaultValueHandle(String methodName, R defaultValue, Object... args) {
super(methodName, args);
this.defaultValue = defaultValue;
this.isNullToDefault = false;
}
/**
* @param isNullToDefault
* @param defaultValue 当异常发生时自定义返回的默认值
* @param methodName 方法名称
* @param args 方法入参
*/
public DefaultValueHandle(boolean isNullToDefault, R defaultValue, String methodName, Object... args) {
super(methodName, args);
this.defaultValue = defaultValue;
this.isNullToDefault = isNullToDefault;
}
@Override
public R apply(R result, Throwable throwable) {
logResult(result, throwable);
if (throwable != null) {
return defaultValue;
}
if (result == null && isNullToDefault) {
return defaultValue;
}
return result;
}
public static <R> DefaultValueHandle.DefaultValueHandleBuilder<R> builder() {
return new DefaultValueHandle.DefaultValueHandleBuilder<>();
}
public static class DefaultValueHandleBuilder<R> {
private boolean isNullToDefault;
private R defaultValue;
private String methodName;
private Object[] args;
DefaultValueHandleBuilder() {
}
public DefaultValueHandle.DefaultValueHandleBuilder<R> isNullToDefault(final boolean isNullToDefault) {
this.isNullToDefault = isNullToDefault;
return this;
}
public DefaultValueHandle.DefaultValueHandleBuilder<R> defaultValue(final R defaultValue) {
this.defaultValue = defaultValue;
return this;
}
public DefaultValueHandle.DefaultValueHandleBuilder<R> methodName(final String methodName) {
this.methodName = methodName;
return this;
}
public DefaultValueHandle.DefaultValueHandleBuilder<R> args(final Object... args) {
this.args = args;
return this;
}
public DefaultValueHandle<R> build() {
return new DefaultValueHandle<R>(this.isNullToDefault, this.defaultValue, this.methodName, this.args);
}
public String toString() {
return "DefaultValueHandle.DefaultValueHandleBuilder(isNullToDefault=" + this.isNullToDefault + ", defaultValue=" + this.defaultValue + ", methodName=" + this.methodName + ", args=" + Arrays.deepToString(this.args) + ")";
}
}
}
8.8、默认返回值应用示例
- 使用了handle() 方法来处理最终的结果,其中包含了异步函数中的错误处理。
completableFuture.handle(new DefaultValueHandle<>("orderService.getOrder", Collections.emptyMap(), params));
本文作者
长发、旭孟、向鹏,均来自美团外卖商家组技术团队。
Action1:问题1:按理说cf的result应该是volatile ? 问题2:为什么要用stack来实现依赖的存储,queue不行吗?
问题1:对,result是volatile修饰的,volatile只能保证可见性,不能保证一致性约束。
问题2:queue出入队修改不同节点,在竞争较多的场景吞吐量更高。stack出入栈只修改头节点,在出栈时先前入栈的对象的存储很可能还没有被CPU缓存淘汰,缓存的命中率会更高。而CompletableFuture的使用场景一般不会有频繁竞争,所以这里用stack的结构性能更优。
Action2:CompletableFuture 在其中只是起到了写起来更方便,可读性更高的作用吧?减少线程损耗靠的是 NIO,以前的实现方式也一样是一个独立线程池吧,所以引入这个的意义大概就是更好的可读性和更好的编排?
减少线程数依赖底层的nio多路复用的能力,除此之外主要基于以下两点考虑:
-
1、将「线程池异步」和「NIO异步(一般是回调)」在编程模式上统一成CF,利用CF的编排能力消除依赖服务之间的阻塞,在依赖较多的场景下,收益会更明显。
-
2、CF能更好的支持函数式编程,将一些通用处理(日志、异常、监控等)抽成可复用的函数,提升复用性。
Action3:ComplatableFuture 在Java9才有超时处理,Java8下我们用applyToEither + scheduledThreadPool 实现,请问你们怎么处理呢?
我们没有依赖 ComplatableFuture 的超时处理,底层是用的RPC框架的超时能力,实现原理也是类似的。
Action4:go语言是如何实现异步编排的?
首先,先声明一个结构体。其中有三个成员:第一个wg用于多线程同步;第二个res用于存放执行结果;第三个err用于存放相关的错误。
type Promise struct {
wg
sync.WaitGroup
res string
err error
}
然后,定义一个初始函数,来初始化 Promise 对象。其中可以看到,需要把一个函数f传进来,然后调用wg.Add(1)对 waitGroup 做加一操作,新开一个 Goroutine 通过异步去执行用户传入的函数f(),然后记录这个函数的成功或错误,并把 waitGroup 做减一操作。
func NewPromise(f func() (string, error)) *Promise {
p := &Promise{}
p.wg.Add(1)
go func() {
p.res, p.err = f()
p.wg.Done()
}()
return p
}
然后,我们需要定义 Promise 的 Then 方法。其中需要传入一个函数,以及一个错误处理的函数。并且调用wg.Wait()方法来阻塞(因为之前被wg.Add(1)),一旦上一个方法被调用了wg.Done(),这个 Then 方法就会被唤醒。
func (p *Promise) Then(r func(string), e func(error)) (*Promise){
go func() {
p.wg.Wait()
if p.err != nil {
e(p.err)
return
}
r(p.res)
}()
return p
}
下面,我们定义一个用于测试的异步方法。这个方面很简单,就是在数数,然后,有一半的机率会出错。
func exampleTicker() (string, error) {
for i := 0; i < 3; i++ {
fmt.Println(i)
<-time.Tick(time.Second * 1)
}
rand.Seed(time.Now().UTC().UnixNano())
r:=rand.Intn(100)%2
fmt.Println(r)
if r != 0 {
return "hello, world", nil
} else {
return "", fmt.Errorf("error")
}
}
下面,我们来看看我们实现的 Go 语言 Promise 是怎么使用的。代码还是比较直观的,我就不做更多的解释了。
var p = NewPromise(exampleTicker)
p.Then(func(result string) { fmt.Println(result); doneChan <- 1 },
func(err error) { fmt.Println(err); doneChan <-1 })
<-doneChan
- 可读性太差了