Rust 中的基本数据类型——Rust语言基础06
文章目录
- 1. 前言
- 2. 标量类型(Scalar)
-
- 2.1. 整型(Integer)
- 2.2. Rust 的整数形式
- 2.3. 奇怪的问题(整数的溢出)
- 2.4. 浮点类型(Float)
- 2.5. 布尔类型(Bool)
- 2.6. 字符类型(Char)
- 3. 复合类型
-
- 3.1. 元组类型(Tuple)
- 3.2. 数组类型(Array)
- 3.3. 数组越界访问
- 4. 基本运算
- #附录 1:Rust 中的运算符
- #附录 2: 二进制补码
1. 前言
Rust 中的每个值都具有特定的数据类型,它告诉 Rust 指定了哪种数据,因此编译器知道如何处理这些数据。下面将研究两种数据类型子集:标量 (scalar) 和复合 (compound)。
请记住,Rust 是一种静态类型语言,这将意味着,编译程序时需要让编译器清楚所有变量的类型。而编译器通常也可以根据具体值和代码里如何使用来推测我们声明缺省类型的变量应该使用什么类型。但是当存在多种情况时,则必须在编写过程中注明变量类型,因此注明变量类型将会是一个好习惯。
2. 标量类型(Scalar)
标量 (scalar) 类型只能表示单个值。Rust 中有四种主要的标量类型:整型、浮点型、布尔型、字符型。(这与 C/C++ 的基本类型相同)
2.1. 整型(Integer)
整型则表示一个整数,之前我们已经见过一个整型类型 u32。其中 u 表示该整数是无符号的 (unsigned)。反之有符号的则会以 i 开头。
Rust 中的整数类型:
| 长度 | 有符号 | 无符号 |
|---|---|---|
| 8-bit | i8 |
u8 |
| 16-bit | i16 |
u16 |
| 32-bit | i32 |
u32 |
| 64-bit | i64 |
u64 |
| 128-bit | i128 |
u128 |
| arch | isize |
usize |
每种整数类型都分为两类,有符号、无符号,其每种整数类型都具有对应的长度,该长度则会限制了这种类型的可表示数值范围。
[注]:计算机中会以二进制补码的形式存储有符号数,后文的附录中将会详细对其解释。
以 8-bit 长度来说明问题:
u8 类型的整数由于其不需要考虑符号位,所有位都用来表示具体值,则其可表示的整数范围:[0, 28 - 1];
i8 类型的整数由于需要用最高位表示数据的正负性(最高位为 0 表示正数,为 1 表示负数),则其可表示的整数范围:[-(27), 27 - 1]。
依此类推则有:
每个无符号整数可表示的整数范围 [0, 2n - 1];
每个有符号整数可表示的整数范围 [-(2n-1), 2n-1 - 1]。
Rust 中有这样的整数类型 usize 和 isize,它们的长度取决于当前计算机的体系结构,在表格中用 arch 代替表示,如:当前的系统是 32 位架构,它们的长度则是 32 位;若当前系统是 64 位架构,它们的长度则是 64 位。
[注]:Rust 中使用 i32 作为默认的整数类型。————请记住这一点
2.2. Rust 的整数形式
Rust 中允许使用添加特定的字符来更清晰的描述整数数值。Rust 允许数字类型使用特定字符做后缀来指定类型(如,let num: u8 = 28u8;)。也可以在数字中添加下划线 _,可起到视觉分隔作用,是的数字更易阅读。(如,1_000_000、0xffff_ffff)
| 整数形式 | 示例 |
|---|---|
十进制(Decimal) |
27_149 |
十六进制(Hex) |
0xff_ff |
八进制(Octal) |
0o77 |
二进制(Binary) |
0b1111_0000 |
字节(Byte 仅 u8类型) |
b'A' / b'a' |
示例源码如下:
fn main() {
let dec_num = 27_149;
let hex_num = 0xaa_bb;
let oct_num = 0o7_666;
let bin_num = 0b1_0000;
let ch: u8 = b'A'; // 字母 A 的 ASCII 码值为 65
println!("The number of decimal: {dec_num}");
println!("The number of hex: {hex_num}");
println!("The number of octal: {oct_num}");
println!("The number of binary: {bin_num}");
println!("The character: {ch}");
}
运行结果:
imaginemiracle:variables$ cargo run
Compiling variables v0.1.0 (/home/imaginemiracle/Miracle/Code/rust_projects/variables)
Finished dev [unoptimized + debuginfo] target(s) in 0.20s
Running `target/debug/variables`
The number of decimal: 27149
The number of hex: 43707
The number of octal: 4022
The number of binary: 16
The character: 65
2.3. 奇怪的问题(整数的溢出)
Boy: 等等,说了这么多就是为了希望我可以正确的为整数赋值是吗?
Girl: 对呀~
Boy: 那万一我记不住,或者我要故意用错会发生什么?
Girl: Enmmm,你想怎么样?
Boy: 呐!我现在是知道了 u8 类型的取值范围是 [0, 28 - 1],那我非要给他赋值 28,或者更大的数呢?
Girl: 啊,你你你……,我也不知道了,那我们试试吧!
让我们就用下面这小段代码来做个小小的实验。
use std::io;
fn main() {
let mut number = String::new();
io::stdin()
.read_line(&mut number)
.expect("Failed to read line.");
let number: u8 = number.trim().parse().expect("It's a number.");
let test_number: u8 = number + 10;
println!("Input num: {}", number);
println!("The test num: {}", test_number);
}
练习的过程顺带也回顾一下之前的内容,获取标准输入,并将其转换为整数,再为其加上 10,并打印两个数字。我们先使用常规的 debug 模式来运行。
imaginemiracle:variables$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/variables`
12
Input num: 12
The test num: 22
OK,看起来没什么问题,让我们试着输入 u8 的最大值 255。
imaginemiracle:variables$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/variables`
255
thread 'main' panicked at 'attempt to add with overflow', src/main.rs:30:27
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
哇呜!Rust 慌了,不知道它该干什么了。让我们再尝试使用 release 模式运行。
imaginemiracle:variables$ cargo run --release
Finished release [optimized] target(s) in 0.00s
Running `target/release/variables`
255
Input num: 255
The test num: 9
咦!这时候会发现 Rust 不慌了,它明白自己在整数溢出的时候该怎么做。
原来 Rust 对于整数的溢出会出现两种处理行为:
Debug模式下:
当 Rust 遇到溢出时会直接报 panic 并终止程序运行。
Release模式下:
当 Rust 遇到溢出时会以 ”回环算法“(wrapping arithmetic) 处理溢出的数据。若数值超过存储范围,则根据整数类型的存储位数,从数值的低位重新计算该数值。
则将从超过得部分回归到最低位,重新开始计算该值。
简单来讲,最终的值 = 原值 % (可存储的最大值 + 1) 或 最终值 = 原值 % ( 2n )。
[注]:% 是求余符号,这里的 n 代表该类型所占位数。
例如:在 u8 类型的情况下,最大值应该为 255。
若赋值为 256,则会变为 256 % (28 - 1 + 1) = 0;
若赋值为 257,则会变为 257 % (28 - 1 + 1) = 1。

2.4. 浮点类型(Float)
与大多数编程语言一样 Rust 也拥有两种不同精度的浮点类型,用来表示单精度浮点类型的 f32,以及用来表示双精度浮点类型的 f64。f32 的数据使用 32 位来表示,f64 的数据使用 64 位来表示。Rust 中的默认浮点类型是 f64,因为现在的 CPU 几乎为 64 的,因此在处理 f64 和 f32 类型的数据时所耗的时间基本相同,但 f64 可表示的精度更高。
[注]:所有的浮点类型都是有符号的。
示例:
创建浮点类型变量。
fn main() {
let x = 3.14; // f64
let y: f32 = 3.14; // f32
}
2.5. 布尔类型(Bool)
和大多数编程语言一样,Rust 中的布尔类型(bool)可能的值有两个:true 和 false。bool 类型数值的内存大小为 1 Byte。
示例:
如何使用 bool 类型变量。
fn main() {
let t = true;
let f: bool = false; // with explicit type annotation
}
[注]:bool 类型的变量一般主要用于条件控制语句的控制条件。
2.6. 字符类型(Char)
Rust 中的 char 类型是该语言里最基本的字符类型。
示例:
fn main() {
let c = 'z';
let z: char = 'ℤ'; // with explicit type annotation
let heart_eyed_cat = '';
}
需要注意的是,字符与字符串的不同,字符是以单引号括起来的,而字符串是以双引号括起来。char 类型只可表示字符。
3. 复合类型
复合类型可以将多个值组合为一种类型。Rust 有两种原始的复合类型:元组和数组。
3.1. 元组类型(Tuple)
元组是将具有多种类型的多个值组合成一个复合类型的一般方法。元组具有固定长度:一旦声明,它们的大小就不能增长或缩小。
我们通过在括号内用一个逗号来分隔一组值来创建一个元组。元组中的每个位置都有一个类型,元组中不同值的类型不必相同。
示例:
创建元组。
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}
该变量 tup 绑定到整个元组,因为元组被视为单个复合类型。要从元组中获取单个值,我们可以使用模式匹配来解构元组值。
示例:
获取元组中的值。
fn main() {
let tup = (500, 6.4, 1);
let (x, y, z) = tup;
println!("The value of y is: {y}");
}
这段代码首先创建了一个元组,并将其绑定到变量 tup 上。接着使用模式匹配的方式利用 let 将 tup 解构,将其转换为三个单独的变量,x、y、z。该方法称为 “解构”(Destructuring)。最后打印出 y 的值。
另一种方法,可以通过在 . 后跟需要访问值的顺序来直接访问元组中的元素。
示例:
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}
该程序创建元组 x,然后使用它们各自的索引访问元组的每个元素。与大多数编程语言一样,元组中的第一个索引是 0。
3.2. 数组类型(Array)
另外一个可以存储多个值的方式则是数组类型。与元组不同的是,数组中的每个元素类型必须相同。与其他编程语言不同的是,Rust 中的数组具有固定长度。(即不可增加或减少)
示例:
创建数组类型。(不指定元素类型和数量)
fn main() {
let months = ["January", "February", "March", "April", "May", "June", "July",
"August", "September", "October", "November", "December"];
}
创建数组类型。(指定元素类型和数量)
fn main() {
let a: [i32; 5] = [1, 2, 3, 4, 5];
}
其中,i32 是每个元素的类型。分号后的数字 5 表示数组包含五个元素。
创建数组类型。(指定初始化值)
fn main() {
let a = [3; 5]; // just like this, let a = [3, 3, 3, 3, 3]
}
访问数组元素
堆栈可以为数组分配已知固定大小的单个内存块。可以使用元素的索引来访问数组中的元素。
[注]:这里的堆栈是我们常说的程序栈,存储静态分配的变量和全局变量。堆用来存储动态分配的变量。
示例:
访问数组元素。
fn main() {
let a = [1, 2, 3, 4, 5];
let first = a[0]; // first == 1
let second = a[1]; // second == 2
}
3.3. 数组越界访问
很多时候我们都会遇到这个问题——“数组越界访问”。在许多低级语言中,是“允许”数组越界访问,但这个操作很多时候来讲都是不安全的。我们来看看 Rust 是如何处理这个问题的。
示例:
实验代码
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
let mut index = String::new();
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
let index: usize = index
.trim()
.parse()
.expect("Index entered was not a number");
let element = a[index];
println!("The value of the element at index {index} is: {element}");
}
这段程序执行后,输入 0、1、2、3、4 都会得到正常的输出,我们会看到对应索引的数组元素。
假设我们输入一个超过数组范围的索引,来访问这个数组看看会发生什么。
imaginemiracle:data_type$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/data_type`
Please enter an array index.
6
thread 'main' panicked at 'index out of bounds: the len is 5 but the index is 6', src/main.rs:19:19
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
该程序在索引操作中使用无效值时导致运行时错误。程序退出并显示错误消息并且没有执行最后的 println! 语句。当尝试使用索引访问元素时,Rust 将检查给的索引是否小于数组长度。如果索引大于或等于长度,Rust 会报 panic 错误。这种检查必须在运行时进行,尤其是在这种情况下,因为编译器不可能知道用户稍后运行代码时将输入什么值。
这是 Rust 内存安全原则的一个示例。在许多低级语言中,并没有进行这种检查,并且当提供不正确的索引时,可以访问无效内存。Rust 通过立即退出而不是允许内存访问和继续来保护您免受此类错误的影响。
4. 基本运算
Rust 支持所有数字类型的基本数学运算:加法、减法、乘法、除法以及求余。整数除法向下舍入到最接近的整数。
示例:
fn main() {
// addition
let sum = 5 + 10;
// subtraction
let difference = 95.5 - 4.3;
// multiplication
let product = 4 * 30;
// division
let quotient = 56.7 / 32.2;
let floored = 2 / 3; // Results in 0
// remainder
let remainder = 43 % 5;
}
[注]:可以查看附录 1,了解 Rust 支持的所有运算符
#附录 1:Rust 中的运算符
| 操作符 | 例子 | 描述 | 是否可重载 |
|---|---|---|---|
! |
ident!(...), ident!{...},ident![...] |
宏扩展 | - |
! |
!expr |
按位或逻辑补码 | Not |
!= |
var != expr |
非质量比较 | PartialEq |
% |
expr % expr |
算术余数 | Rem |
%= |
var %= expr |
算术余数和赋值 | RemAssign |
& |
&expr,&mut expr |
引用 | - |
& |
&type, &mut type, &'a type,&'a mut type |
指针类型的引用 | - |
& |
expr & expr |
按位与 | BitAnd |
&= |
var &= expr |
按位与和赋值 | BitAndAssign |
&& |
expr && expr |
逻辑与 | - |
* |
expr * expr |
算术乘法 | Mul |
*= |
var *= expr |
算术乘法和赋值 | MulAssign |
* |
*expr |
取消引用 | Deref |
* |
*const type,*mut type |
指针 | - |
+ |
trait + trait,'a + trait |
复合类型约束 | - |
+ |
expr + expr |
算术加法 | Add |
+= |
var += expr |
算术加法和赋值 | AddAssign |
, |
expr, expr |
参数和元素分隔符 | - |
- |
- expr |
算术负号 | Neg |
- |
expr - expr |
算术减法 | Sub |
-= |
var -= expr |
算术减法和赋值 | SubAssign |
-> |
fn(…) -> type,|…| -> type |
函数和闭包返回类型 | - |
. |
expr.ident |
会员访问 | - |
.. |
.., expr.., ..expr,expr..expr |
右排范围文字 | PartialOrd |
..= |
..=expr,expr..=expr |
右包含范围文字 | PartialOrd |
.. |
..expr |
结构字面量更新语法 | - |
.. |
variant(x, ..),struct_type { x, .. } |
“其余的”模式绑定 | - |
... |
expr...expr |
(已弃用,改为使用 ..=)在模式中:包含范围模式 |
- |
/ |
expr / expr |
算术除法 | Div |
/= |
var /= expr |
算术除法和赋值 | DivAssign |
: |
pat: type,ident: type |
约束 | - |
: |
ident: expr | 结构字段初始化器 | - |
: |
'a: loop {…} | 循环标签 | - |
; |
expr; |
语句和项目终止符 | - |
; |
[…; len] |
固定大小数组语法的一部分 | - |
<< |
expr << expr |
左移 | Shl |
<<= |
var <<= expr |
左移和赋值 | ShlAssign |
< |
expr < expr |
小于比较 | PartialOrd |
<= |
expr <= expr |
小于等于比较 | PartialOrd |
= |
var = expr,ident = type |
分配/等价 | - |
== |
expr == expr |
平等比较 | PartialEq |
=> |
pat => expr |
部分匹配臂语法 | - |
> |
expr > expr |
大于比较 | PartialOrd |
>= |
expr >= expr |
大于等于比较 | PartialOrd |
>> |
expr >> expr |
右移 | Shr |
>>= |
var >>= expr |
右移和赋值 | ShrAssign |
@ |
ident @ pat |
模式绑定 | - |
^ |
expr ^ expr |
按位异或 | BitXor |
^= |
var ^= expr |
按位异或和赋值 | BitXorAssign |
| |
pat | pat |
模式替代品 | - |
| |
expr | expr |
按位或 | BitOr |
|= |
var |= expr |
按位或和赋值 | BitOrAssign |
|| |
expr || expr |
短路逻辑或 | - |
? |
expr? |
错误传播 | - |
#附录 2: 二进制补码
学过《计算机组成原理》的朋友们一定能说出一句朗朗上口的口号。
“正数的原反补相同;负数反码,符号位不变,其它取反;负数补码等于反码加一。”
我们熟知的补码等于反码加一,事实上并不是补码的定义,而只是补码的一种求法,也只是恰好补码等于反码加一。
补码的思想类似于我们常见的钟表,当现在的时钟指向是 6 点整,那么请问时钟在什么时间指向的是 3 点整。
答案有两种,第一,在与现在相隔 3 小时的过去时钟是指向 3 点整的。第二,在与现在相隔 9 小时的未来,时钟是指向 3 点整的。

即就是,对于时钟而言,这里的 6 - 3 等价于 6 + 9,最终指针都会到同一个位置。这样子我们会发现,这里减去一个数,可以等同于加上另一个数(这个加数加上减数则会正好等于时钟的最大值 12,也称为同余数),在时钟的例子中 12 称为模,当超过 12 后,将会重新开始计算。
为什么要把一个二进制数搞这么复杂?事实上二进制数的原码、反码以及补码的引入是为了解决计算机处理减法的问题。
我们来看一个例子就知道了。
假设我们所使用的环境是一个 8 位的机器,则其最大存储值为 28 - 1 = 255,也就是说,当存储到 256 时将会从 0 重新开始计算(因为最高位已经无法存储),那么,该环境下的模为 256。
现在在上面计算 16 + 8。
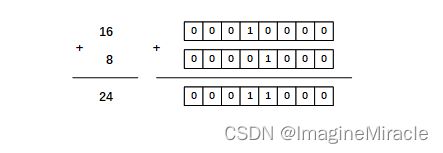
好,让我们以同样的方法计算 16 + (-8)。

很明显,这种计算方法计算的结果并不正确。
但是在在计算机环境中没有减法器怎么办。这个时候我们就利用时钟原理,减去一个数,我们可以找到另外一个数(同余数)与之相加后会得到相同的结果。
那么 -8 在这里的同余数是 28 - 8 = 248 (1111_1000)。
好,我们直接依葫芦画瓢,16 + (-8) = 16 + 248

可以看到这里计算出的结果应该是 9 位才可以表示的数值,但是在 8 位机的情况下最高位无法表示将会被舍去,那么此时的计算结果就应该是我们需要的正确答案 24。成了!
事实上其中的 248,正是 (-8) 的补码形式。(-8) 在 8 位机的表示方式应该为 1000_1000(最高位为符号位),(-8) 的补码应该为 1111_1000。
OK!到这里应该对补码也有了一定自己的认识了。
Boys and Girls!!!
准备好了吗?下一节我们要开始做个小练习了哦!
不!我还没准备好,让我先回顾一下之前的。
上一篇《Rust 中的变量(特性)——Rust语言基础05》
我准备好了,掛かって来い(放马过来)!
下一篇《Rust 中的函数——Rust语言基础07》
觉得这篇文章对你有帮助的话,就留下一个赞吧v*
请尊重作者,转载还请注明出处!感谢配合~
[作者]: Imagine Miracle
[版权]: 本作品采用知识共享署名-非商业性-相同方式共享 4.0 国际许可协议进行许可。
[本文链接]: https://blog.csdn.net/qq_36393978/article/details/125562556