大众点评svg反爬
python爬虫——大众点评svg反爬(仅供学习使用)
学爬虫有大半年,仅仅会一些基础的爬虫,对一些反爬有深度的反爬就over了,最近在学svg反爬与字体反爬,然后用大众点评练一下。当然会有代码跑起来效率不高的的地方以及错误,大家可以指点。
前言
大众点评是一款非常受大众喜爱的一个第三方的美食相关的点评网站。从网站内可以推荐吃喝玩乐优惠信息,提供美食餐厅、酒店旅游、电影票、家居装修、美容美发、运动健身等各类生活服务,通过海量真实消费评论的聚合,帮助大家选到服务满意商家。因此,该网站的数据也就非常有价值。优惠,评价数量,好评度等数据也就非常受数据公司的欢迎。
1.分析
图片1

我们可以看到我所画红色圈圈的地方,评论有些被遮挡了,不显示,怎么办,很气人,要放弃吗?不可能的。然后我就问了一下度娘,她说在蓝色圈圈那个曲线处,这时我们选中代码,也就是黑色线处,然后右击蓝色线处的,然后open in new tab,然后打开下面这个页面。当然我们也要copy这个链接,在网页代码中搜索(ctrl+F),会发现找不到,我们把 ‘http:’去掉
搜索会找到的。到时我们可以xpath到。
图片2
然后我用谷歌插件美化一下,变成下面模样,感觉看着很舒服
图片3

background: -num1 px -num2px.我们可以发现num1都是14倍数(一个汉字的宽度,在图片1中蓝色圈中可以看到 width : 14px,有可能与x相关;’num2很有可能是y,但是不一定是y值,是y周围的数,我们可以找到特定规律找到y值。
同时我们可以看第一张图片里面网页代码,与评论有关的标签都是svgmtsi所以在我们美化的css代码页面(也就是第三张),先ctrl+F一下进行搜索,果然找到了它,并且还有链接,哎呦,不错呀,心中小喜。我们把链接复制一下,在前面加http:,然后变成这个模样==》http://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/8379576b648e1338a56600ef56fbb993.svg,我们打开它,是下面这个样子。
图片4

我们来开一下网页代码
图片5

图片6
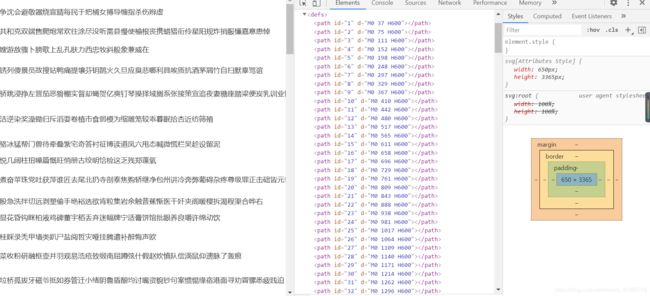
图片5,6中网页代码中标签defs的子标签path与标签text的子标签textPath数量都一样都是1-81。我们可以猜测这两者有关系,并且textPath中的textLength等于的数字是14,那该数字除以14有可能是代表汉字的横坐标x。我们继续分析,在标签text中d=“M0 num H600”(num代表里面的数字),我们用num减去23恰好等于num2,所以我找了多个汉字进行试验,确实是。
我们来顺一下思路:
num/14代表x,num2+23也就是y为svg源码path标签中id数或者textPath标签href中去#号的数,我们先定位y,然后在定位x,就能找到我们svg映射关系,可以用字典表示。
下面上代码,我们试试。
2.引入库
requests库相对于urllib3库是非常强大的,验证了那句青出于蓝而胜于蓝;lxml库在这里主要用于xpath;re当然是强大的正则了,我以前爬虫是主要是xpath,正则是真的不行,然后为了svg,我狠狠的补了一把re。
import requests
from lxml import etree
import re
3.开始爬取:
我们先得到css的url,
#得到css url
url = 'http://www.dianping.com/shop/G7sHtVJBI8fWn45Q/review_all'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 填入自己的cookies,
'Host': 'www.dianping.com',
'Referer': 'http://www.dianping.com/shop/G7sHtVJBI8fWn45Q',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36',
}
response=requests.get(url=url,headers=headers)
response.encoding='utf-8' #编码用utf-8
#这里我把html下载下来,为了后面好分析,如果一直请求会被封
with open('Ajian.html','w',encoding='utf-8') as f:
f.write(response.text)
content=response.content
html=etree.HTML(content)
css_url='http:'+html.xpath('/html/head/link[4]/@href')[0]
print(css_url)
下面我们通过css_url获取cvg的url:
#这里请求头可以用pyhon的,当然看个人习惯
headers1={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36'
}
css_response=requests.get(url=css_url,headers=headers1)
response.encoding='utf-8'
# print(css_response.text)
#这里我对 css网页也进行了保存
with open(r'Ajian.css','w',encoding='utf-8') as f:
f.write(css_response.text)
#这里xpath无法用,我们可以用正则
svg_group=re.search(r'svgmtsi\[class\^="(\w+)"].*?background-image: url\((.*?)\);', css_response.text)
#key_letter是为了获取属性class的值,在后面我们会用到它,用完你会发现评论中属性class的值都是iz开头,这里会根据点评svg的变化自动变化。
key_letter=svg_group.group[1]
svg_url='http:'+svg_group[2]
print(key_letter)
print(svg_url)
获取svg:
svg_response=requests.get(url=svg_url,headers=headers1)
with open('Ajian.svg','w',encoding='utf-8') as f:
f.write(svg_response.text)
# print(svg_response.text)
接下来我们开始进行获取评论,把映射关系用字典表示出来:
(说实话这里搞得有点麻烦不过,可以再优化的)
首先把y与svg每行的汉字用字典建立关系,也就是字典dic。
然后再通过x吧评论中属性class的值与对应的汉字建立字典关系。
with open('Ajian.svg','r',encoding='utf-8') as f:
svg_html=f.read()
list1=re.findall(r'id="(\d+)" d="M0 (\d+) ',svg_html)
# print(list1)
href_list=['#'+i[0] for i in list1]
y_list=[]
for i in list1:
y_list.append(str(int(i[1])-23))
# print(y_list)
# print(href_list)
# print(len(y_list),len(href_list))
dic1={}
key_letter='iz'
with open('Ajian.css','r',encoding='utf-8') as f:
css_html=f.read()
for i in dic.keys():
tuple_list=re.findall('\.('+key_letter+'\w+)\{background:-(\d+)\.0px -'+i+'\.0px;\}',css_html)
# print(tuple_list)
for m in tuple_list:
x=int(int(m[1])/14)
dic1[m[0]]=dic[i][x]
# print(dic1)
接下来我们要回到图一源码中先用正则把评论的代码取到,然后进行替换:
with open('Ajian.html','r',encoding='utf-8') as f:
html=f.read()
comment_list=re.findall('\s+(.*?)\s+',html)
# print(comment_list)
for i in comment_list:
key_list=re.findall(',i)
for img in img_list:
i=i.replace(img,'')
print(i)
4结果展示:

可以看到还是有一些杂质,但是还是与评论对比,还是可以的
总结
这个感觉挺难的,但是不要怕,还是可以搞出来的。要相信自己哦,大众点评变化很快,可能今天还能爬,明天就不能用了,所以我的这种只能解决里面的思路。
我这里有许多可以改进的地方,望大家指出。
本人搞爬虫仅仅是为了兴趣,
参考链接https://cloud.tencent.com/developer/article/1698225
https://zhuanlan.zhihu.com/p/111126062
https://blog.csdn.net/qq_41562377/article/details/105539643?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160474038419724839212978%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=160474038419724839212978&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_v2~rank_v28-9-105539643.pc_search_result_cache&utm_term=%E5%A4%A7%E4%BC%97%E7%82%B9%E8%AF%84%E7%88%AC%E8%99%AB&spm=1018.2118.3001.4449