超星系统登录,信息爬取
超星系统登录,信息爬取
经历过上一年的疫情的大学生,一部分大学生可能对超星有一个深刻的认识,而我写这个项目的想法来自我的导师,做一个可以爬取超星课程学生成绩,可以随机组卷(前提是自己题库里有题),该项目可以做到统计题库试题类型以及试题数量,同时可以模板组卷以及一键群发消息,省去了许多的点点点。
下面步入整体。
首先就是登录:
登录
超星登录链接(点这里),这个是超星现在登录的一个节界面,当然还有另一个界面(点这个是另一个),我选择这个是因为这个可以实现扫码登录,学号或工号登录(我称他为机构登录),手机号码与密码登录,还有一个就是手机号与验证码登录(不过我没搞上它),反正是登录样式比较多。

我们看一下这个页面,有两种登录方式,我们首先分析手机号密码登录登录,我们输入一个错误的账号密码,看看它的请求,

我们可以发现上图uname是我们手机号,那个password显然就是我们密码。但是它被加密,其实这个加密不难,很简单,它就是一个base64加密:看下图就知道了。

如上图,base64编码后得到的结果跟我们抓包得到的一样。剩下就简单了,post一下就好了,下面我们分析另一个登录方式扫码登录,细心地朋友会发现在抓包时有个请求getauthstatus,

它其实就与扫码登录有关。经过我的分析,它是在不过请求的,不过请求一段时间二维码就会失效。不要担心它失效,它的时间其实挺长的。我们扫码登录首先就是获取二维码,这个其实很简单,在登录页面网页源码里面就可以得到二维码的链接,我们下载一下,然后展示就ok了。
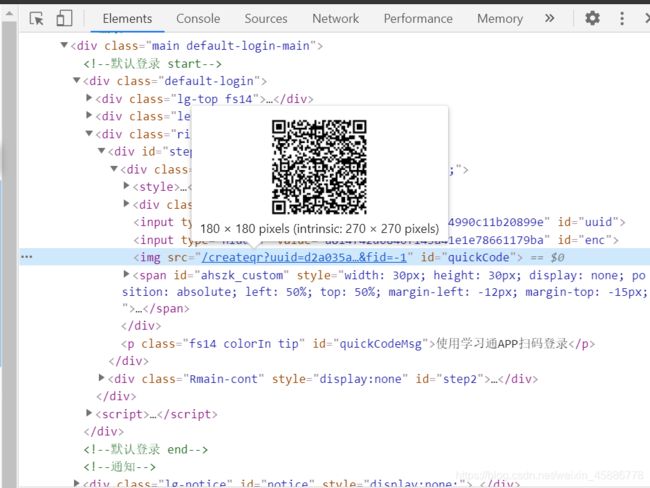
那下面就是getauthstatus请求了。我们看一下getauthstatus请求,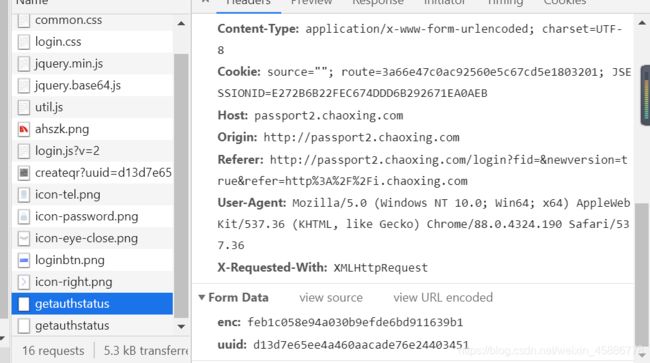
我们发现它需要参数enc与uuid,我们全局搜索一下,它就在登录网页源码里面,也就是刚刚那个二维码链接的上面。

上面截图红框框里面就是了。对于这个扫码登录我的思路就是先下载二维码,然后展示,同时不断发送getauthstatus,同时getauthstatus也会返回我们数据,通过数据我们可以判断登录状态,当我扫码后会返回我们用户名,当我们移动端确认后,我们同样会获取返回信息,这时我们就请求一个统用的链接http://i.chaoxing.com/,允许这个请求重新定向就会登录到我们超星登录成功后页面。当然只是请求到的。
接下来我们分析学号或工号登录,

它其实在其它方式登录。不过该方式涉及验证码。我就想到验证码识别,我也找到一个训练验证码模型,不过我电脑训练总是失败,不知道为什么。所以就只能手动了。那我们就乱输入一下,抓一下包。

我们会发现uname为账号,numcode为验证码,password是密码加密,当然,密码加密还是base64加密,这里有一个就是fid,其实它每个学校的一个id。然后我们请求一下就好了。
在这里我仅仅讲的是登录,在我的代码中,我用的是session会话,在登录成功后会进行cookie的保存,当一定时间内我们只需要登录一次,然后每次用到时会检查cookie,有效就会进行下面的操作,无效,就会重新登录,然后再进行操作。
登录已经解决,下面就是信息爬取。
成绩统计
![]()
首先我们眼获取课程的url,这个url其实在我们登录后的页面里面,我们正则或者xpath就可以获取。在这里我用的是正则,当我获取课程链接后,我们请求课程链接,然后就是获取统计的url(如上图灰色块里的统计)。我们再次正则出来就好了,在这里我要重点说一下,我们要把统计链接里的courseId,classId,enc, cpi,openc
4个参数匹配出,变成全局变量,它们不仅下现在有用,在后面群发信息,模板或者随机组卷也会用到。下面利用上面的一下参数组成的url请求,获取源码,然后匹配出来要的信息,我把这些信息写入字典,key为名字,value为一些成绩。然后用pandas转化为excel表就好了。没有什么难度
群发信息
群发信息其实也是通过抓包,看是什么形式,其实也很简单,当然也会用到上面4个参数的一些参数。
随机组卷或模板组卷
在这里我说一下,我本来想打算用go语言的chromedp包这个包,但是这个上面有个难度,就是对于弹窗确认。这个我找了想过文档没找到。这个可以操控chrome浏览器,不需要任何驱动。不想我现在用的selenium,它要配置驱动,还要设置环境变量Path,并且有点慢,没有chromedp快。同时这里要再次登录,同样也是我保存了cookies,登录一次后,一段时间时间后不用再登录。我想过统一selenium与request的cookies,但是目前没有想到好的方式。不过这个登录支持超星登录的所有方式,剩下就是一下click,sendkey了,具体看我源码。
登录源码:
import base64
import os
import platform
import re
import subprocess
import sys
import time
from http import cookiejar
import muggle_ocr
import requests
from PIL import Image
# 超星登录
class chaoxing_login(object):
def __init__(self):
self.session = requests.session()
self.session.cookies = cookiejar.LWPCookieJar(filename='core/chaoxing_cookies.txt')
self.login_headers = {
'Origin': 'http://passport2.chaoxing.com',
'Referer': 'http://passport2.chaoxing.com/login?loginType=3&newversion=true&fid=-1&refer=http%3A%2F%2Fi.chaoxing.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Host': 'passport2.chaoxing.com',
}
# 登录完成的请求头
self.login_complete_headers = {
'Host': 'i.chaoxing.com',
'Referer': 'http://passport2.chaoxing.com/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
}
self.account_url = 'http://passport2.chaoxing.com/unitlogin'
# 机构登录data
self.account_data = {
'fid': '学校id',
'uname': '',
'numcode': '',
'password': '',
'refer': 'http%3A%2F%2Fi.chaoxing.com',
't': 'true',
}
self.phone_url = 'http://passport2.chaoxing.com/fanyalogin'
# 手机号登录data
self.phone_data = {
'fid': '-1',
'uname': '',
'password': '',
'refer': 'http%3A%2F%2Fi.chaoxing.com',
't': 'true',
'forbidotherlogin': '0',
}
self.QR_code_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'Host': 'passport2.chaoxing.com',
'Referer': 'http://passport2.chaoxing.com/login?fid=&newversion=true&refer=http%3A%2F%2Fi.chaoxing.com',
'Upgrade-Insecure-Requests': '1',
}
self.session.headers = self.login_headers
# 图片展示
def show_img(self, file_name):
userPlatform = platform.system()
if userPlatform == 'Darwin': # Mac
subprocess.call(['open', file_name])
elif userPlatform == 'Linux': # Linux
subprocess.call(['xdg-open', file_name])
else: # Windows
os.startfile(file_name)
# 13位时间戳
def get_time_stamp(self):
time_stamp = str(int(time.time() * 1000))
return time_stamp
# 获取验证码
def get_captcha(self):
print('验证码获取中......')
captcha_url = "http://passport2.chaoxing.com/num/code?{}".format(self.get_time_stamp())
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36",
}
response = self.session.get(url=captcha_url, headers=headers)
if response.status_code == 200:
print('获取验证码成功')
content = response.content
with open("core\chaoxing_captcha.png", "wb") as f:
f.write(content)
self.show_img(file_name='core\chaoxing_captcha.png')
else:
print('抱歉,获取验证码失败\n'
'程序将自动终止,请重新打开程序')
sys.exit()
# 密码加密
def password_encrypt(self, password):
password = base64.b64encode(password.encode())
password = password.decode()
return password
# 检查cookies
def check_cookies(self):
self.session.headers = self.login_complete_headers
try:
# 加载cookies
self.session.cookies.load(ignore_discard=True)
url = "http://i.chaoxing.com/"
response = self.session.get(url=url, allow_redirects=True)
if response.status_code == 200:
# print(response.text)
return True
else:
return False
except FileNotFoundError:
return "无cookie文件"
# 账号密码输入
def input(self):
uname = input('请输入账户:')
password = input('请输入密码:')
password = self.password_encrypt(password)
if self.num == '1':
self.account_data['uname'] = uname
self.account_data['password'] = password
self.get_captcha()
numcode = input('请输入验证码:')
self.account_data['numcode'] = numcode
elif self.num == '2':
self.phone_data['uname'] = uname
self.phone_data['password'] = password
# 扫码登入所需的uuid,enc
def get_uuid_enc(self):
url = 'http://passport2.chaoxing.com/login'
params = {
'fid': '',
'newversion': 'true',
'refer': 'http://i.chaoxing.com',
}
response = self.session.get(url=url, params=params)
text = response.text
self.uuid = re.findall('随机组卷及模板组局源码(selenium)
import json
import os
import platform
import subprocess
import sys
from math import ceil
from time import sleep
from lxml import etree
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
class login():
def __init__(self):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless') #隐藏浏览器
chrome_options.add_argument(
'--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36') # 设置请求头的User-Agent
chrome_options.add_argument('--disable-infobars') # 禁用浏览器正在被自动化程序控制的提示
self.driver = webdriver.Chrome(options=chrome_options,executable_path='core\chromedriver.exe')
self.login_url = "http://passport2.chaoxing.com/login?fid=&newversion=true&refer=http%3A%2F%2Fi.chaoxing.com"
def phone_login(self):
phone = input('请输入手机号:')
self.driver.find_element_by_css_selector("#phone").send_keys(phone)
password = input('请输入密码:')
self.driver.find_element_by_css_selector("#pwd").send_keys(password)
self.driver.find_element_by_css_selector("#loginBtn").click()
def jigou_login(self):
# 点击其它登录
self.driver.find_element_by_xpath('//*[@id="otherlogin"]').click()
sleep(1)
self.driver.find_element_by_xpath('//*[@id="inputunitname"]').send_keys('浙大宁波理工学院')
sleep(0.75)
uname = input('请输入学号或者工号:')
self.driver.find_element_by_xpath('//*[@id="uname"]').send_keys(uname)
sleep(0.75)
password = input('请输入密码:')
self.driver.find_element_by_xpath('//*[@id="password"]').send_keys(password)
sleep(0.75)
self.driver.find_element_by_xpath('//*[@id="numVerCode"]').screenshot('core\chaoxing_captcha.png')
file_name = 'core\chaoxing_captcha.png'
self.show_img(file_name)
txtSecretCode = input('请输入验证码:')
self.driver.find_element_by_xpath('//*[@id="vercode"]').send_keys(txtSecretCode)
self.driver.find_element_by_xpath('//*[@id="loginBtn"]').click()
def show_img(self, file_name):
userPlatform = platform.system()
if userPlatform == 'Darwin': # Mac
subprocess.call(['open', file_name])
elif userPlatform == 'Linux': # Linux
subprocess.call(['xdg-open', file_name])
else: # Windows
os.startfile(file_name)
def QR_login(self):
self.driver.find_element_by_xpath('//*[@id="quickCode"]').screenshot('core\QR.png')
file_name = 'core\QR.png'
self.show_img(file_name)
def check_state(self):
self.driver.get('http://i.chaoxing.com/')
sleep(1)
f = '账号管理' in self.driver.page_source
if f == True:
print('登录成功')
return True
else:
print('登录失败')
return False
def save_cookie(self):
cookie_list = self.driver.get_cookies()
jsonCookies = json.dumps(cookie_list)
with open('core\chaoxing_cookies.json', 'w') as f:
f.write(jsonCookies)
print('保存cookie成功')
def read_cookie(self):
with open('core\chaoxing_cookies.json', 'r') as f:
list_cookie = json.loads(f.read())
return list_cookie
def check_cookie(self, list_cookie):
self.driver.get(self.login_url)
self.driver.delete_all_cookies()
for cookie in list_cookie:
self.driver.add_cookie(cookie)
sleep(2)
self.driver.get(self.login_url)
sleep(1)
self.driver.get('http://i.chaoxing.com/')
f = self.check_state()
if f == True:
print('cookie有效')
return True
else:
print('cookie无效')
return False
def check_file(self):
f = os.path.exists('core\chaoxing_cookies.json')
if f == True:
list_cookie = self.read_cookie()
f = self.check_cookie(list_cookie)
if f == True:
return True
else:
return False
return False
def login(self):
self.driver.maximize_window()
self.driver.get(self.login_url)
f = self.check_file()
if f == False:
while True:
print('请选择登录方式:\n'
'1为电话号码登录\n'
'2为学号或者工号登录\n'
'3为扫码登录\n'
'4为验证码登录\n'
'输入其它字符为退出')
num = input('请输入数字:')
if num == '1':
self.phone_login()
elif num == '2':
self.jigou_login()
elif num == '3':
self.QR_login()
elif num == '4':
pass
else:
sys.exit()
f = self.check_state()
if f == True:
self.save_cookie()
break
else:
pass
return self.driver
class exam():
def __init__(self):
self.driver = login().login()
self.dict = {}
self.subject_xpath_dict = {
"单选题": {'delete': '//*[@id="typetrid1"]/span[2]/a', 'score': '//*[@id="0_score"]',
'subject_num': '//*[@id="0_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"多选题": {'delete': '//*[@id="typetrid2"]/span[2]/a', 'score': '//*[@id="1_score"]',
'subject_num': '//*[@id="1_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"填空题": {'delete': '//*[@id="typetrid3"]/span[2]/a', 'score': '//*[@id="2_score"]',
'subject_num': '//*[@id="2_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"判断题": {'delete': '//*[@id="typetrid4"]/span[2]/a', 'score': '//*[@id="3_score"]',
'subject_num': '//*[@id="3_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"简答题": {'delete': '//*[@id="typetrid5"]/span[2]/a', 'score': '//*[@id="4_score"]',
'subject_num': '//*[@id="4_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"名词解释": {'delete': '//*[@id="typetrid6"]/span[2]/a', 'score': '//*[@id="5_score"]',
'subject_num': '//*[@id="5_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"论述题": {'delete': '//*[@id="typetrid7"]/span[2]/a', 'score': '//*[@id="6_score"]',
'subject_num': '//*[@id="6_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"计算题": {'delete': '//*[@id="typetrid8"]/span[2]/a', 'score': '//*[@id="7_score"]',
'subject_num': '//*[@id="7_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"分录题": {'delete': '//*[@id="typetrid9"]/span[2]/a', 'score': '//*[@id="9_score"]',
'subject_num': '//*[@id="9_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"资料题": {'delete': '//*[@id="typetrid10"]/span[2]/a', 'score': '//*[@id="10_score"]',
'subject_num': '//*[@id="10_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"连线题": {'delete': '//*[@id="typetrid11"]/span[2]/a', 'score': '//*[@id="11_score"]',
'subject_num': '//*[@id="11_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"排序题": {'delete': '//*[@id="typetrid13"]/span[2]/a', 'score': '//*[@id="13_score"]',
'subject_num': '//*[@id="13_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"完型填空": {'delete': '//*[@id="typetrid14"]/span[2]/a', 'score': '//*[@id="14_score"]',
'subject_num': '//*[@id="14_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"阅读理解": {'delete': '//*[@id="typetrid15"]/span[2]/a', 'score': '//*[@id="15_score"]',
'subject_num': '//*[@id="15_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"程序题": {'delete': '//*[@id="typetrid17"]/span[2]/a', 'score': '//*[@id="17_score"]',
'subject_num': '//*[@id="17_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"口语题": {'delete': '//*[@id="typetrid18"]/span[2]/a', 'score': '//*[@id="18_score"]',
'subject_num': '//*[@id="18_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"听力题": {'delete': '//*[@id="typetrid19"]/span[2]/a', 'score': '//*[@id="19_score"]',
'subject_num': '//*[@id="19_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"共用选项题": {'delete': '//*[@id="typetrid20"]/span[2]/a', 'score': '//*[@id="20_score"]',
'subject_num': '//*[@id="20_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
"其它": {'delete': '//*[@id="typetrid21"]/span[2]/a', 'score': '//*[@id="8_score"]',
'subject_num': '//*[@id="8_TypeDiv"]/li[2]/div[2]/div[1]/p[2]/input[2]'},
}
self.choice_dict = {
"单选题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[1]/input',
"多选题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[2]/input',
"填空题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[3]/input',
"判断题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[4]/input',
"简答题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[5]/input',
"名词解释": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[6]/input',
"论述题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[7]/input',
"计算题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[8]/input',
"分录题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[9]/input',
"资料题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[10]/input',
"连线题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[11]/input',
"排序题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[12]/input',
"完型填空": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[13]/input',
"阅读理解": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[14]/input',
"程序题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[15]/input',
"口语题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[16]/input',
"听力题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[17]/input',
"共用选项题": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[18]/input',
"其它": '//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[1]/label[19]/input',
}
def template_exam(self, url, paper_num):
# 输入试卷标题
print('标题字符数为4到40个字符')
while True:
title = input('请输入标题:')
if len(title) >= 4 and len(title) <= 40:
break
else:
print('输入有误,标题标题字符数为4到40个字符')
for p in range(paper_num):
try:
self.driver.get(url)
self.driver.refresh()
# 清理文本输入框
self.driver.find_element_by_xpath('//*[@id="title"]').clear()
# 输入标题
self.driver.find_element_by_xpath('//*[@id="title"]').send_keys(title)
# 输入试卷数目
self.driver.find_element_by_xpath('//*[@id="pageNum"]').send_keys(1)
# 点击保存
self.driver.find_element_by_xpath('//*[@id="actionTab"]/a[1]').click()
sleep(2)
# 定位到弹窗
alert = self.driver.switch_to.alert
sleep(1)
# 确认组卷进行确定
alert.accept()
print("第{}张试卷组卷成功!!!".format(p + 1))
except:
print("第{}张试卷组卷失败!!!".format(p + 1))
sleep(2)
def random_exam(self, url):
self.driver.get(url)
sleep(1.5)
# 前往资料库
self.driver.find_element_by_xpath('/html/body/div[4]/div[2]/div[1]/div[2]/ul/li[4]/a').click()
# 切换资料库页面
self.driver.switch_to.window(self.driver.window_handles[-1])
# 前往题库
self.driver.find_element_by_xpath('//*[@id="RightCon"]/div/div/div[1]/ul/li[2]/a').click()
html = self.driver.page_source
page_num = self.get_pageNum_subject(html)
print("正在统计第1页题目")
self.statistical(html)
for p in range(2, page_num + 1):
print("正在统计第{}页题目".format(p))
self.driver.find_element_by_xpath(
'//div[@id="pagination"]/a[@οnclick="changePageAdd({})"]'.format(p)).click()
html = self.driver.page_source
self.statistical(html)
sleep(1.5)
self.driver.find_element_by_xpath('//*[@id="RightCon"]/div/div/div[1]/ul/li[4]/a').click()
# 等待"创建试卷"关键句出现
sleep(1)
WebDriverWait(self.driver, 3).until(EC.visibility_of_element_located((By.LINK_TEXT, "创建试卷")))
# 点击创建试卷
self.driver.find_element_by_xpath('//*[@id="qform"]/a[3]').click()
# 等待"下一步"关键句出现
sleep(1)
WebDriverWait(self.driver, 3).until(EC.visibility_of_element_located((By.LINK_TEXT, "下一步")))
# 点击自动创建试卷按钮
self.driver.find_element_by_xpath('//*[@id="chooseForm"]/div/p[2]/label/input').click()
# 点击下一步
self.driver.find_element_by_xpath('//*[@id="chooseForm"]/div/div/a').click()
# 等待更多题型加载
sleep(1)
WebDriverWait(self.driver, 3).until(EC.visibility_of_element_located((By.LINK_TEXT, "更多题型")))
# 切换页面为当前
self.driver.switch_to.window(self.driver.window_handles[-1])
# 试卷数量设置为1
self.driver.find_element_by_xpath('//*[@id="pageNum"]').send_keys(1)
# 设置试卷标题
print("请注意试卷标题至少为4个字符")
title = input("请输入试卷标题:")
self.driver.find_element_by_xpath('//*[@id="title"]').send_keys(title)
sleep(2)
# 随机试卷初始化含有以下三种类型,把它们全部删除
origin_list = ['单选题', '多选题', '填空题']
for i in origin_list:
self.driver.find_element_by_xpath(self.subject_xpath_dict[i]['delete']).click()
sleep(2)
print("------------------------------")
print("您题库含有试题及数量如下:")
self.type_list = []
x = 0
for key, value in self.dict.items():
if value != 0:
self.type_list.append(key)
print("序号:{},您有 {}:{}道".format(x, key, value))
x += 1
print("------------------------------")
# 选择课程:
print("请输入你要选择试题的序号,输入负数代表结束!")
choice_list = []
while True:
num = int(input("请输入数字:"))
if num >= 0:
choice_list.append(num)
else:
break
self.choice_subject(choice_list)
sleep(1)
print("下面是每个题型的总分以及题型数量的信息填写,请您分配好分数\n同时试卷默认总分为100\n如果计算出总分不为100,将会自动按照比例更改分数\n并满足总分为100")
self.input_info(choice_list)
n = input('是否同时保存为模板\n'
'是输入1\n'
'否输入0\n'
'请输入:')
# 确定同时保持为模板
if n == '1':
self.driver.find_element_by_xpath('//*[@id="savePaperTemplateCheck"]').click()
sleep(2)
# 点击保存
self.driver.find_element_by_xpath('//*[@id="actionTab"]/a[1]').click()
sleep(2)
# 定位到弹窗
alert = self.driver.switch_to.alert
sleep(1)
# 确认组卷进行确定
alert.accept()
sleep(2)
# 输入每个题型的分数和数目
def input_info(self, choice_list):
score_list = []
for num in choice_list:
score = input("请输入{}总分数:".format(self.type_list[num]))
score_list.append(int(score))
self.driver.find_element_by_xpath(self.subject_xpath_dict[self.type_list[num]]['score']).send_keys(score)
sleep(0.75)
subject_num = input('请输入{}的题目数:'.format(self.type_list[num]))
self.driver.find_element_by_xpath(self.subject_xpath_dict[self.type_list[num]]['subject_num']).send_keys(
subject_num)
sleep(0.75)
Sum = sum(score_list)
if Sum != 100:
print('试卷总分不为一百,正在进行更改')
for num in range(len(score_list)):
if num != len(score_list) - 1:
# 按照比例进行分配
score_list[num] = int((score_list[num] / Sum) * 100)
else:
score_list[num] = 100 - sum(score_list[:-1])
else:
pass
n = 0
for num in choice_list:
score = score_list[n]
self.driver.find_element_by_xpath(self.subject_xpath_dict[self.type_list[num]]['score']).clear()
sleep(0.25)
self.driver.find_element_by_xpath(self.subject_xpath_dict[self.type_list[num]]['score']).send_keys(score)
n += 1
sleep(0.75)
print('更改完成')
# 题型选择
def choice_subject(self, choice_list):
# 点击更多题型
self.driver.find_element_by_xpath('//*[@id="newMore"]').click()
for num in choice_list:
# 对每个题型打上对号
self.driver.find_element_by_xpath(self.choice_dict[self.type_list[num]]).click()
# 点击确定
self.driver.find_element_by_xpath(
'//*[@id="setPaperStructure"]/div[1]/div/div[2]/div[2]/a[1]/span').click()
# 题库信息统计
def statistical(self, html):
html = etree.HTML(html)
tr_list = html.xpath('//*[@id="tableId"]/tr')
for tr in tr_list:
key = tr.xpath('td[3]/text()')
if key != []:
key = key[0].strip()
self.dict[key] += 1
else:
pass
# 对网页处理
def get_pageNum_subject(self, html):
html = etree.HTML(html)
str_num = html.xpath('//*[@id="RightCon"]/div/div/div[4]/span[2]/text()')[0]
page_num = ceil(int(str_num) / 20)
# print(page_num)
option_list = html.xpath('//*[@id="qTypeSelect"]/option')
for i in range(1, len(option_list)):
key = option_list[i].xpath('text()')[0].strip()
self.dict[key] = 0
return page_num
爬取入口源码
import datetime
import os
import re
import sys
import time
import pandas as pd
from docx import Document
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docx.shared import Pt, RGBColor, Cm
from lxml import etree
from exam import exam
from login import chaoxing_login
class Chaoxing_spider():
def __init__(self):
self.session = chaoxing_login().login()
self.my_teach_headers = {
'Host': 'mooc1-1.chaoxing.com',
# 'Referer': 'http://mooc1-1.chaoxing.com/visit/interaction?s=e9059bca0eca12ef882b78f6a497cdc9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'Host': 'mooc1-1.chaoxing.com',
}
self.class_dic = {}
self.statistics_info_dic = {}
self.schoolid = '18638' # 自己学校Id,学校不同Id不同
# 获取班级链接及名字,并存入一个字典
def get_class_url_name(self):
params = {
'isAjax': 'true'
}
url = 'http://mooc1-1.chaoxing.com/visit/courses/teach'
self.session.headers = self.my_teach_headers
response = self.session.get(url=url, params=params)
# print(response.text)
text = response.text
href_name = re.findall('', text)
for i in href_name:
href, name = i
href = 'https://mooc1-1.chaoxing.com' + href.replace("'", "").replace('"', '')
name = name.replace("'", "").replace('"', '')
self.class_dic[name] = href
return ''
# 获取成绩统计的信息,并获取信息的题头
def get_statistics_info(self):
title_url = 'https://mooc1-1.chaoxing.com/moocAnalysis/analysisScore?classId={}&courseId={}&ut=t&cpi={}&openc={}'.format(
self.classId, self.courseId, self.cpi, self.openc)
r = self.session.get(url=title_url)
text = r.text
html = etree.HTML(text)
th_list = html.xpath('//tr[@id="commonthead"]/th')
title_list = []
for th in th_list:
i = th.xpath('span/text()')
if len(i) == 1:
title_list.append(i[0])
else:
title_list.append(i[0] + i[1])
# 创建字典
for i in title_list:
self.statistics_info_dic[i] = []
# print(self.statistics_info_dic)
data = {
'courseId': self.courseId,
'classId': self.classId,
'pageSize': '30',
'sw': '',
'pageNum': '1',
'fid': '0',
'sortType': '',
'order': '',
'test': '0',
'isSimple': '0',
'openc': self.openc,
}
self.session.headers = {
'Host': 'mooc1-1.chaoxing.com',
'Origin': 'https://mooc1-1.chaoxing.com',
'Referer': self.statistics_url,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
url = 'https://mooc1-1.chaoxing.com/moocAnalysis/analysisScoreData'
p = 1
while True:
data['pageNum'] = str(p)
p += 1
response = self.session.post(url=url, data=data)
# print(response.text)
text = response.text
if text == '':
break
else:
self.statistics_info_handle(text, title_list)
def save_statistics_info(self):
self.get_statistics_info()
# 保存文件
df = pd.DataFrame(self.statistics_info_dic)
print(df)
file_path = r'data\statistics\{}.xlsx'.format(self.class_name + str(int(time.time() * 1000)))
b = os.path.exists(file_path)
if b == False:
print('{}excel文件正在保存......'.format(self.class_name))
df.to_excel(file_path)
print('{}excel文件保存成功.'.format(self.class_name))
else:
print('路径为:{}\n'
'excel文件存在,无法保存\n'
'程序将自动退出'.format(file_path))
sys.exit()
# 根据信息标头对每个人信息进行提取
def statistics_info_handle(self, text, title_list):
# print(title_list)
html = etree.HTML(text)
# 把每次提取到的成绩存入info_lint
info_list = []
for i in range(1, len(title_list) + 1):
if i == 1:
info = html.xpath('//tr/td[1]/span/@title')
# print(info)
else:
info = html.xpath('//tr/td[{}]/span/text()'.format(i))
for j in range(len(info)):
info[j] = info[j].replace('\t', '').replace('\n', '').replace('\r', '').strip()
# print(info)
info_list.append(info)
# print(info)
# print(info_list)
dic = dict(zip(title_list, info_list))
for i in title_list:
self.statistics_info_dic[i] = self.statistics_info_dic[i] + dic[i]
# print(self.statistics_info_dic)
# 模板试卷
def template_exam(self):
base_url = 'https://mooc1-1.chaoxing.com/exam/loadPaperTemplate'
params = {
'courseId': self.courseId,
'start': '0',
'examsystem': '0',
'isCustomPaper': 'false',
'cpi': self.cpi,
'openc': self.openc,
'qbanksystem': '0',
'qbankbackurl': '',
}
response = self.session.get(url=base_url, params=params)
text = response.text
html = etree.HTML(text)
tr_list = html.xpath('//tbody[@id="tableId"]/tr')
name_url_list = []
n = 0
for tr in tr_list:
name = tr.xpath('td[1]/text()')[0]
url_info = tr.xpath('td[5]/a/@onclick')[0]
template_url = 'https://mooc1-1.chaoxing.com' + re.findall('"(.*?)"', url_info)[0]
name_url_list.append((name, template_url))
print('序号:{} 名字:{}'.format(n, name))
n += 1
print('输入负数将退出!')
while True:
num = int(input("请输入你要选择模板的序号:"))
if num < len(name_url_list) and num >= 0:
template_url = name_url_list[num][1]
break
elif num >= len(name_url_list):
print('输入数字有误!')
else:
sys.exit()
paper_num = int(input("请输入要组成试卷数量:"))
exam().template_exam(template_url, paper_num)
# 试卷库
def exam_library(self):
url = 'https://mooc1-1.chaoxing.com/exam/reVerSionPaperList'
params = {
'courseId': self.courseId,
'classId': self.classId,
'ut': 't',
'examsystem': '0',
'cpi': self.cpi,
'openc': self.openc,
}
response = self.session.get(url=url, params=params)
text = response.text
href_name_list = re.findall('(.*?)', text)
for i in href_name_list:
href, name = i
url = '{}{}'.format('https://mooc1-1.chaoxing.com', href)
content = self.session.get(url).content
html = etree.HTML(content)
url = 'https://mooc1-1.chaoxing.com' + html.xpath('//*[@id="RightCon"]/div[2]/ul/li/div[2]/p/a/@href')[0]
self.download_paper(url, name)
def download_paper(self, url, name):
paper_dict = {}
print('-' * 20)
response = self.session.get(url)
text = response.text
# 每个答题信息
list = re.findall('(.*?)', text, re.S)
for i in list:
html = etree.HTML(i)
# 题目大标题
subject_title = html.xpath('//h2/text()|//h2/em/text()')
# print(subject_title)
# 把题目大标题变为元组
subject_list_tuple = tuple(subject_title)
# 大标题作为第一层key
paper_dict[subject_list_tuple] = {}
# 题目列表
subject_list = html.xpath('//div[@class="TiMu"]/div[@name="certainTitle"]')
for subject in subject_list:
# 题目信息
subject_detailed = subject.xpath(
'div[1]/i/text()|div[1]/div/text()|div[1]/div/p/text()|div[1]/div/img/@src')
# print(subject_detailed)
# 把题目信息添加
subject_detailed_tuple = tuple(subject_detailed)
paper_dict[subject_list_tuple][subject_detailed_tuple] = {}
# 选项
option_list = subject.xpath('ul/li')
paper_dict[subject_list_tuple][subject_detailed_tuple]['选项'] = []
if option_list != []:
for option in option_list:
option1 = option.xpath('i/text()')
option1_content_list = option.xpath('div/a/text()|div/a/img/@src|div/a/p/text()')
option1.extend(option1_content_list)
paper_dict[subject_list_tuple][subject_detailed_tuple]['选项'].append(option1)
# print(option1)
# 答案
answer_list = subject.xpath(
'div[2]/div[1]/span/div/text()|div[2]/div[1]/span/div/img/@src|div[2]/span/text()|div[2]/div[1]/span/div/p/img/@src')
if answer_list != []:
if len(answer_list) == 1:
answer_list = answer_list[0].replace('正确答案:', '').strip()
# print('答案', answer_list)
else:
answer_list1 = []
for i in range(len(answer_list)):
m = answer_list[i].strip()
if m != '':
answer_list1.append(m)
answer_list = answer_list1
# print('答案', answer_list)
paper_dict[subject_list_tuple][subject_detailed_tuple]['答案或分析'] = answer_list
else:
analysis_list = subject.xpath('div[3]/span/img/@src')
# print('分析', analysis_list)
paper_dict[subject_list_tuple][subject_detailed_tuple]['答案或分析'] = analysis_list
time_stamp = int(time.time())
year = datetime.datetime.now().year
month = datetime.datetime.now().month
def paper():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36', }
self.session.headers = headers
# 试卷document
document = Document(r'core\template.docx')
document.styles['Normal'].font.name = u'宋体'
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
document.styles['Normal'].font.color.rgb = RGBColor(0, 0, 0)
if month <= 7:
title0 = '浙江大学宁波理工学院{}–{}学年第二学期'.format(year, year + 1)
else:
title0 = '浙江大学宁波理工学院{}–{}学年第一学期'.format(year, year + 1)
paragraph0 = document.add_paragraph('')
run = paragraph0.add_run(title0)
run.font.size = Pt(18) # 18为小二
run.bold = True # 字体加黑
# 设置行距
paragraph_format = paragraph0.paragraph_format
paragraph_format.line_spacing = 1.5 # 1.5倍行距
# 居中
paragraph0.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
title1 = '《{}》课程期末考试试卷 (A或B)'.format(self.class_name)
paragraph1 = document.add_paragraph('')
run1 = paragraph1.add_run(title1)
run1.font.size = Pt(15) # 15为小三
run1.bold = True # 字体加黑
# 设置行距
paragraph_format = paragraph1.paragraph_format
paragraph_format.line_spacing = 1.5 # 1.5倍行距
# 居中
paragraph1.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
paragraph2 = document.add_paragraph('')
run2 = paragraph2.add_run("开课单位:____________,考试形式:闭(开、半开)卷,允许带_________入场\n"
"考试日期:____________年____月____日,考试所需时间:_______分钟\n"
"考生姓名:_______学号:_______考生所在学院(系):______专业班级______")
run2.line_spacing = 1.5 # 1.5倍行距
run2.font.size = Pt(12) # 12为小四
# 设置行距
paragraph_format = paragraph2.paragraph_format
paragraph_format.line_spacing = 1.5 # 1.5倍行距
# 表格
table = document.add_table(rows=4, cols=len(paper_dict) + 2, style='Table Grid')
table.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 表头
table.rows[2].cells[0].text = '得分'
table.rows[3].cells[0].text = '评卷人'
hc0 = table.rows[0].cells
hc1 = table.rows[1].cells
hc0[0].text = '题序'
hc1[0].text = '题型'
n = 1
for key, _ in paper_dict.items():
texparagraph0, text1 = key[0].split('、')
hc0[n].text = texparagraph0
hc1[n].text = text1
n += 1
hc0[n].text = '总分'
for m in range(4):
# for n in range(len(paper_dict)+2):
table.rows[m].height = Cm(1)
# 合并单元格
table.cell(1, len(paper_dict) + 1).merge(table.cell(3, len(paper_dict) + 1))
# 第一层key代表大题目标题
for key, value in paper_dict.items():
paragraph = document.add_paragraph(key[0] + key[1])
paragraph_format = paragraph.paragraph_format
paragraph_format.line_spacing = 1.5 # 1.5倍行距
# print(key)
# 第二层key为大题中每个小题的题干信息
for key, value in value.items():
# print(key)
# 题干
'''开启一个新段落'''
paragraph = document.add_paragraph('')
run = document.paragraphs[-1].add_run()
# 设置行距
paragraph_format = paragraph.paragraph_format
paragraph_format.line_spacing = 1.5 # 1.5倍行距
for i in key:
if '.png' in i:
response = self.session.get(i)
content = response.content
with open('core\paper.png', 'wb') as f:
f.write(content)
run.add_picture('core\paper.png')
else:
run.add_text(i)
# print(value)
# 选项
choice_list = value['选项']
if choice_list != []:
for choice in choice_list:
'''开启一个新段落'''
paragraph = document.add_paragraph('')
run = document.paragraphs[-1].add_run()
# 设置行距
paragraph_format = paragraph.paragraph_format
paragraph_format.line_spacing = 1.5 # 1.5倍行距
for i in choice:
if '.png' in i:
response = self.session.get(i)
content = response.content
with open('core\paper.png', 'wb') as f:
f.write(content)
run.add_picture('core\paper.png')
else:
run.add_text(i)
document.save('data/paper/{}_{}.docx'.format(name, time_stamp))
def answer():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36', }
self.session.headers = headers
# 答案document
document = Document()
for key, value in paper_dict.items():
document.add_heading(key[0], 1)
for key, value in value.items():
# 开启一个新段落
document.add_paragraph('')
run = document.paragraphs[-1].add_run()
run.add_text('{},'.format(key[0]))
answer_list1 = value['答案或分析']
for i in answer_list1:
if '.png' in i:
response = self.session.get(i)
content = response.content
with open('core\paper.png', 'wb') as f:
f.write(content)
run.add_picture('core\paper.png')
else:
run.add_text(i)
document.save('data/paper/{}_{}答案.docx'.format(name, time_stamp))
print('试卷 {} 正在下载'.format(name))
paper()
print('试卷 {} 下载完成'.format(name))
print('试卷 {} 答案正在下载'.format(name))
answer()
print('试卷 {} 答案下载完成'.format(name))
# 试卷随机组成
def random_exam(self, url):
exam().random_exam(url)
def mkdir(self):
b = os.path.exists('data')
if b == False:
os.makedirs('data')
b = os.path.exists('data/paper')
if b == False:
os.makedirs('data/paper')
b = os.path.exists('data/statistics')
if b == False:
os.makedirs('data/statistics')
def send_info(self):
base_url = 'https://mooc1-1.chaoxing.com/teachingClassManage/teachingClassList'
params = {
'courseId': self.courseId,
'ut': 't',
'classId': self.classId,
'show': '1',
'schoolid': self.schoolid,
'cpi': self.cpi,
'openc': self.openc,
}
response = self.session.get(url=base_url, params=params)
content = response.content
html = etree.HTML(content)
studentId_list = html.xpath('//tbody[@id="allstu"]/tr/td[1]/input/@value')
studentIds = ''
for studentId in studentId_list:
studentIds += studentId + ','
studentIds = studentIds[:-1]
title = input('请输入标题:')
while True:
content = input('请输入内容(字数不能超过1000):')
num = len(content)
if num <= 1000:
break
else:
print('输入字符超过1000字符!请重新输入')
base_url = 'https://mooc1-1.chaoxing.com/schoolCourseInfo/sendNoticeToStudent'
data = {
'courseId': self.courseId,
'clazzId': self.classId,
'studentIds': studentIds,
'title': title,
'content': content,
'enc': self.enc,
'attachment': '',
}
response = self.session.post(url=base_url, data=data)
status_code = response.status_code
if status_code == 200:
print('信息发送成功!')
else:
print('信息发送失败!')
# 课程选择及获取courseId, classId, cpi, openc四个参数
def choice_class(self):
self.mkdir()
self.get_class_url_name()
n = 0
print('-' * 20)
print('序号 课程')
for name in self.class_dic.keys():
print('{} {}'.format(n, name))
n += 1
print('-' * 20)
class_name_list = [class_name for class_name in self.class_dic.keys()]
size = len(class_name_list)
num = int(input("如果输入负数程序将退出\n请输入你要获取成绩的课程的序号:"))
if num >= 0:
while True:
if num < size:
break
else:
print('警告===》输入序号有误请重新选择')
num = int(input("请重新输入你要获取成绩的课程的序号:"))
class_name = class_name_list[num]
self.class_name = class_name
url = self.class_dic[class_name]
self.session.headers = self.headers
response = self.session.get(url=url, allow_redirects=True)
text = response.text
# 统计成绩链接
base_statistics_url = re.findall('' , text)
if base_statistics_url == []:
print('您没有权限对==》{}《==课程操作'.format(class_name))
print('程序将自我退出.......')
print('程序退出成功......')
sys.exit()
else:
self.statistics_url = 'https://mooc1-1.chaoxing.com' + base_statistics_url[0]
self.courseId, self.classId, self.enc, self.cpi, self.openc = \
re.findall(
r'.*?courseId=(\w*[0-9]\w*)&classId=(\w*[0-9]\w*).*?&enc=(\w*[0-9]\w*).*?&cpi=(\w*[0-9]\w*)&openc=(\w*[0-9]\w*)',
self.statistics_url)[0]
def choice():
num = input('0为成绩爬取\n'
'1为下载试卷\n'
'2为试卷的模板组卷\n'
'3为自定义组卷\n'
'4为发通知信息\n'
'其它字符代表退出\n'
' 请输入数字:')
if num == '0':
self.save_statistics_info()
self.statistics_info_dic = {}
print('任务完成!\n'
'将返回主界面。')
elif num == '1':
self.exam_library()
print('任务完成!\n'
'将返回主界面。')
elif num == '2':
self.template_exam()
print('任务完成!\n'
'将返回主界面。')
elif num == '3':
print("正在运行,请稍等!")
self.random_exam(url)
print('任务完成!\n'
'将返回主界面。')
elif num == '4':
print("正在运行,请稍等!")
self.send_info()
print('任务完成!\n'
'将返回主界面。')
else:
sys.exit()
while True:
choice()
print('-' * 20)
else:
print('程序将要退出......')
print('程序退出成功......')
sys.exit()
cx_spider = Chaoxing_spider()
cx_spider.choice_class()
好了这一期到此为止。觉得我写的还凑合就关注一下Ajian,顺便关注一下我的微信公众号(spiders),也可以扫一下下面的二维码。
