刷题学习 —数据结构(树、图)
第七章 树
1.求树的深度
class Solution {
public int maxDepth(TreeNode root) {
if(root == null)return 0;
return Math.max(maxDepth(root.left),maxDepth(root.right)) + 1;
}
}
思路:递归。
将root.left和root.right看作最后一步,取他们的最大值加1,就是树的深度
2.平衡树
自顶置底地递归:
class Solution {
public boolean isBalanced(TreeNode root) {
if(root == null)return true;
return Math.abs(treedepth(root.left) - treedepth(root.right)) < 2 &&
isBalanced(root.left) && isBalanced(root.right);
}
public int treedepth(TreeNode root){
if(root == null)return 0;
return Math.max(treedepth(root.left),treedepth(root.right))+1;
}
}
思路:
左子树和右子树的深度绝对值不超过1且左右子树都已经是平衡树了,选择用递归,这是自顶置底的方法
自底置顶地递归:
class Solution {
public boolean isBalanced(TreeNode root) {
return recur(root) != -1;
}
public int recur(TreeNode root){
if(root == null)return 0;
int left = recur(root.left);
if(left == -1)return -1;
int right = recur(root.right);
if(right == -1)return -1;
return Math.abs(left - right) < 2 ? Math.max(left,right)+1 : -1;
}
}
recur方法只被调用了一次,所以更快更好
思路:回溯检查子树是不是平衡树,不是平衡树直接返回-1,回到主函数也就是false
3.二叉树的直径
给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点。
class Solution {
public int diameterOfBinaryTree(TreeNode root) {
max = 0;
treeDepth(root);
return max;
}
int max;
public int treeDepth(TreeNode root){
if(root == null)return 0;
int left = treeDepth(root.left);
int right = treeDepth(root.right);
max = Math.max(max,left + right);
return 1 + Math.max(left,right);
}
}
思路:递归
在统计每个节点(即每次递归)时,记录当前节点最大直径,最后返回max
4.翻转二叉树★
自己第一个写出的递归!
class Solution {
public TreeNode invertTree(TreeNode root) {
if(root == null || (root.right == null && root.left == null))return root;
TreeNode node;
node = invertTree(root.left);
root.left = invertTree(root.right);
root.right = node;
return root;
}
}
思路:用一个新节点保存当前节点的左节点,当前节点的左节点设置为当前节点的右节点,再把当前节点的右节点设置成保存好的节点,返回即可
结果:

5.合并二叉树★
两棵树粘一起,自己完成的第二道递归!

class Solution {
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
TreeNode root = new TreeNode();
if(root1 == null && root2 == null){
return null;
}else if(root1 != null && root2 == null){
return root1;
}else if(root1 == null && root2 != null){
return root2;
}else {
root.val = root1.val + root2.val;
root.left = mergeTrees(root1.left,root2.left);
root.right = mergeTrees(root1.right,root2.right);
}
return root;
}
}
思路:
- 当前节点的值是两根节点的和
- 当前节点的左节点是处理好的两树左节点的和
- 当前节点的右节点是处理好的两树右节点的和
- 返回根节点即可
结果:

6.路径总和
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum ,判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。
class Solution {
public boolean hasPathSum(TreeNode root, int targetSum) {
if(root == null)return false;
if(root.left == null && root.right == null)return targetSum == root.val;
return hasPathSum(root.left,targetSum - root.val) || hasPathSum(root.right,targetSum - root.val);
}
}
思路:递归
- root为空返回null,只有root,就看targetsum和root.val是否相同
- 当前节点的左或右节点,在目标值减掉根节点的值的情况下是否有合适的路径
7.统计路径和等于一个数的路径数量
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
递归写法:
class Solution {
public int pathSum(TreeNode root, int targetSum) {
if(root == null)return 0;
int res = rootsum(root,targetSum);
res += pathSum(root.left,targetSum) + pathSum(root.right,targetSum);
return res;
}
public int rootsum(TreeNode root,int targetsum){
int res = 0;
if(root == null)return 0;
if(root.val == targetsum)res++;
res += rootsum(root.left,targetsum - root.val) + rootsum(root.right,targetsum - root.val);
return res;
}
}
?前缀和递归写法:
class Solution {
int count = 0;
HashMap<Integer,Integer> map = new HashMap<>();
int preSum = 0;
int targetSum;
public int pathSum(TreeNode root, int targetSum) {
this.targetSum = targetSum;
map.put(0,1);
dfs(root);
return count;
}
public void dfs(TreeNode node) {
if (null==node){
return;
}
int currentSum = preSum + node.val;
preSum = currentSum;
count += map.getOrDefault(currentSum-targetSum,0);
map.put(currentSum,map.getOrDefault(currentSum,0)+1);
dfs(node.left);
preSum = currentSum;
dfs(node.right);
map.put(currentSum,map.get(currentSum)-1);
}
}
8.判断一棵树是否包含子树
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
if(root == null)return false;
if(subRoot == null)return true;
return issametree(root,subRoot) || isSubtree(root.left,subRoot) || isSubtree(root.right,subRoot);
}
//判断树是否相等
public boolean issametree(TreeNode s,TreeNode t){
if(s == null && t == null)return true;
if(s == null || t == null)return false;
if(s.val != t.val)return false;
return issametree(s.left,t.left) && issametree(s.right,t.right);
}
思路:
- 需要构造判断树是否相等的方法,两个数都空,说明相等,有一个不是空的就不等
- 两树的值不等,也就不相等,继而向下找,两树的左和两树的右同时相等才算两树相等
- 回到判断子树的方法,根节点如果空就肯定没有子树,子树为空,原树肯定有叶子节点
- 向下找,先判断两树相等,或者根的左子树和子树相等,或者根的右子树和子树相等,有一个成立,说明存在这么一个子树
9.树的对称
public boolean isSymmetric(TreeNode root) {
if(root == null)return true;
return issame(root.left,root.right);
}
public boolean issame(TreeNode tree1,TreeNode tree2){
if(tree1 == null && tree2 == null)return true;
if(tree1 == null || tree2 == null)return false;
if(tree1.val != tree2.val)return false;
return issame(tree1.left,tree2.right) && issame(tree1.right,tree2.left);
}
思路:
- 判断左节点的左子树和右节点的右子树 且 左节点的右子树和右节点的左子树是否相等
- 镜像的方法中直接判断根的左右节点是否相
10.二叉树的最小深度
class Solution {
public int minDepth(TreeNode root) {
if(root == null)return 0;
int left = minDepth(root.left);
int right = minDepth(root.right);
if(left == 0 || right == 0)return left + right + 1;//有一边为空的话就不算最小深度,必须有节点
return Math.min(left,right) + 1;
}
}
思路:
- 根节点是空的,说明最小路径为0
- 取出左子树的最小路径,取出右子树的最小路径
- 有一个为0,那么最短路径为left + right + 1,因为毕竟有一个是0嘛
- 最后返回左右里最小的路径,+1还包括根节点
11.统计左叶子节点的和
class Solution {
public int sumOfLeftLeaves(TreeNode root) {
if(root == null)return 0;
if(isleaf(root.left))return sumOfLeftLeaves(root.right) + root.left.val;
return sumOfLeftLeaves(root.right) + sumOfLeftLeaves(root.left);
}
public boolean isleaf(TreeNode node){
if(node == null)return false;
return node.left == null && node.right == null;
}
}
思路:
- 首先做的事是判断根节点的左节点是不是为左叶子节点,是的话就返回右边那部分的值加上自己左叶子节点的值
- 不是左叶子节点就返回左右部分的左叶子节点的值
12.相同节点值的最大路径长度
任意相同节点之间的最大路径
class Solution {
int res = 0;
public int longestUnivaluePath(TreeNode root) {
if(root == null)return 0;
longestpath(root);
return res;
}
public int longestpath(TreeNode root){
if(root == null)return 0;
int left = longestpath(root.left);
int right = longestpath(root.right);
left = root.left != null && root.left.val == root.val ? left + 1 : 0;
right = root.right != null && root.right.val == root.val ? right + 1 : 0;
res = Math.max(res,left + right);
return Math.max(left,right);
}
}
思路:
- 定义全局变量res
- 定义dfs方法搜索路径,找到左右路径数之后,更新变量的值
- 返回的是当前节点左子树或者右子树中最长路径的值
二叉树路径问题
一般可分为两种:自顶向下和非自顶向下
自顶向下
从某一个节点(不一定是根节点),从上向下寻找路径,到某一个节点(不一定是叶节点)
这类题通常可以用深度优先搜索(DFS)或者广度优先搜索(BFS)
自顶向下寻找指定路径的题的解题模板(可以这么思考):
int path = 0;
public void dfs(TreeNode root,int path){
if(root == null)return;
if (root.left != null && root.right != null){
//到了叶子节点怎么处理
}
dfs(root.left,path); //继续递归
dfs(root.right,path);
}
自顶向下寻找给定和的路径的题的解题模板(可以这么思考):
int path = 0;
public void dfs(TreeNode root,int sum,int path){
if(root == null)return;
sum -= root.val;
if (root.left != null && root.right != null && sum == 0){
//到了叶子节点怎么处理
}
dfs(root.left,sum,path); //继续递归
dfs(root.right,sum,path);
}
1、如果是找路径和等于给定target的路径的,那么可以不用新增一个临时变量cursum来判断当前路径和,
只需要用给定和target减去节点值,最终结束条件判断target==0即可
2、是否要回溯:二叉树的问题大部分是不需要回溯的,原因如下:
二叉树的递归部分:dfs(root.left),dfs(root.right)已经把可能的路径穷尽了,
因此到任意叶节点的路径只可能有一条,绝对不可能出现另外的路径也到这个满足条件的叶节点的;
而对比二维数组(例如迷宫问题)的DFS,for循环向四个方向查找每次只能朝向一个方向,并没有穷尽路径,
因此某一个满足条件的点可能是有多条路径到该点的
并且visited数组标记已经走过的路径是会受到另外路径是否访问的影响,这时候必须回溯
3、找到路径后是否要return:
取决于题目是否要求找到叶节点满足条件的路径,如果必须到叶节点,那么就要return;
但如果是到任意节点都可以,那么必不能return,因为这条路径下面还可能有更深的路径满足条件,还要在此基础上继续递归
4、是否要双重递归(即调用根节点的dfs函数后,继续调用根左右节点的pathsum函数):看题目要不要求从根节点开始的,还是从任意节点开始
非自顶向下
非自顶向下的题的解题模板(可以这么思考):
int res = 0;
public int maxPath(TreeNode root){
if(root == null)return 0;
int left = maxpath(root.left);
int right = maxpath(root.right);
res = Math.max(res, left + right + root.val); //更新全局变量
return Math.max(left, right); //返回左右路径较长者
}
这类题型DFS注意点:
1、left,right代表的含义要根据题目所求设置,比如最长路径、最大路径和等等
2、全局变量res的初值设置是0还是INT_MIN要看题目节点是否存在负值,如果存在就用INT_MIN,否则就是0
3、注意两点之间路径为1,因此一个点是不能构成路径的
4、设计一个辅助函数maxPath,调用自身求出以一个节点为根节点的左侧最长路径left和右侧最长路径right,那么经过该节点的最长路径就是left+right
13.
14.二叉树中第二小的节点
一个节点要么具有 0 个或 2 个子节点,如果有子节点,那么根节点是最小的节点。
深度优先搜索:
class Solution {
int ans;
int rootvalue;
public int findSecondMinimumValue(TreeNode root) {
ans = -1;
rootvalue = root.val;
dfs(root);
return ans;
}
public void dfs(TreeNode node){
if(node == null)return;
if(ans != -1 && node.val >= ans)return;
if(node.val > rootvalue)ans = node.val;
dfs(node.left);
dfs(node.right);
}
}
思路:
- 根据题的特点可知,根节点是最小的节点,所以只要找到比根节点大的,采用深度优先搜索倒着找,最后找到的就是最小的比根节点值大的ans。先保存根节点的值,初始化 ans = -1,未找到的话,返回ans即可
- 节点为空或者此时的ans已经不是-1且当前节点的值大于ans就不用更新了,因为ans取的是越来越小的值,但最后比根节点大就行
- 如果当前节点的值大于根结点的值就更新一次ans,ans越来越小,最后取一个最小的但是比根结点的值大
- 向左右分别递归
递归写法:
class Solution {
public int findSecondMinimumValue(TreeNode root) {
if(root == null)return -1;
if(root.left == null && root.right == null)return -1;
int leftval = root.left.val;
int rightval = root.right.val;
if(leftval == root.val)leftval = findSecondMinimumValue(root.left);
if(rightval == root.val)rightval = findSecondMinimumalue(root.right);
if(leftval != -1 && rightval != -1)return Math.min(leftval,rightval);
if(leftval != -1)return leftval;
return rightval;
}
}
思路:
- 根节点空或者只有根节点的话,是不存在第二小的值的,直接返回-1
- 取出当前节点的左右子节点的值,如果这两个值和根结点的值相等,就更新子节点处理好的值
- 最后如果两边都不是-1,取最小的那个
- 如果左不是-1就返回左的,否则就是右边符合第二小
15.(15-25)二叉树的层序遍历
class Solution {
public List<List<Integer>> resList = new ArrayList<>();
public List<List<Integer>> levelOrder(TreeNode root) {
levelorder(root);
return resList;
}
public void levelorder(TreeNode node){
if(node == null)return;
Queue<TreeNode> que = new LinkedList<>();
que.offer(node);
while (!que.isEmpty()){
List<Integer> list = new ArrayList<>();
int len = que.size();
while (len > 0) {
TreeNode tmpNode = que.poll();
list.add(tmpNode.val);
if(tmpNode.left != null)que.offer(tmpNode.left);
if(tmpNode.right != null)que.offer(tmpNode.right);
len--;
}
resList.add(list);
}
}
}
思路:
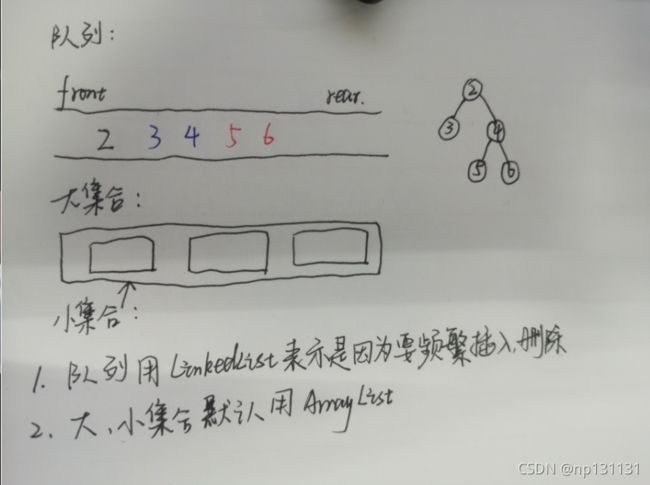
- 先将根节点加入到队列中,只要当前的队列是空的,记录当前队列的长度,进入这个长度的循环
- 取出队列的头,把队列的头的值加到小集合里,如果当前节点没有子节点就直接减长度出循环;如果有子节点,就把子节点加入队列
- 每次小集合装好后,记得把小的集合装入大集合中
- 最后进行层序遍历,返回全局变量,即大集合
!!!层序遍历模板:
public static int minDepth(TreeNode root) {
Queue<TreeNode> que = new LinkedList<>();
/**
创建队列!,用于将节点入队,先进先出原则,确保了层序遍历的顺序
有时也需要用双端队列,双端队列就需要注意其下的方法pollFirst、peekFirst,pollLast,peekLast的区别
Deque que = new LinkedList<>();
*/
//ArrayList> reslist = new ArrayList<>();层序遍历时存储每层的大集合
if(root == null)return 0;//判断根节点为空的情况
que.offer(root);//先将根节点入队
while (!que.isEmpty()) {//只要队列不为空进入循环
int len = que.size();//取队列的长度
//ArrayList itemlist = new ArrayList<>();
//层序遍历的小集合
while (len > 0) {//根据队列中结点的个数,将每个节点的子节点通过循环加入到队列中
//有时也用for循环,好处是可以跳过本节点,根据需要选择for循环
TreeNode node = que.poll();//将队列的第一个节点抛出
//itemlist.add(node.val);层序遍历需要把抛出的节点值记录到小集合中
//子节点入队
if(node.left != null)que.add(node.left);
if(node.right != null)que.add(node.right);
//!!!while循环记得递减循环次数
len--;
}
//reslist.add(itemlist);层序遍历每一层后,都要将小集合装入到大集合中
}
return 0;//根据题目需求改变核心,返回所需变量
}
16.二叉树的层次遍历 II(考点:层序遍历)
从底层层序遍历
class Solution {
public List<List<Integer>> levelOrderBottom(TreeNode root) {
ArrayList<List<Integer>> res = new ArrayList<>();
Queue<TreeNode> que = new LinkedList<>();
if(root == null)return res;
que.offer(root);
while (!que.isEmpty()) {
int len = que.size();
ArrayList<Integer> list = new ArrayList<>();
while (len > 0) {
TreeNode poll = que.poll();
list.add(poll.val);
if(poll.left != null)que.offer(poll.left);
if(poll.right != null)que.offer(poll.right);
len--;
}
res.add(list);
}
ArrayList<List<Integer>> reslist = new ArrayList<>();
for (int i = res.size() - 1; i >= 0; i--) {//再把它反过来即可
reslist.add(res.remove(i));
}
return reslist;
}
}
17.二叉树的右视图(考点:层序遍历)
将二叉树最右面的节点全部输出
class Solution {
public List<Integer> rightSideView(TreeNode root) {
Deque<TreeNode> que = new LinkedList<>();
List<Integer> reslist = new ArrayList<>();
if(root == null)return reslist;
que.offer(root);
while (!que.isEmpty()) {
int len = que.size();
for (int i = 0; i < len; i++) {
TreeNode node = que.pollFirst();
if(node.left != null)que.offerLast(node.left);
if(node.right != null)que.offerLast(node.right);
if(i == len - 1)reslist.add(node.val);
}
}
return reslist;
}
}
思路:
层序遍历,输出每一层,到每一层最后一个元素的时候将其装入集合中
18.二叉树的层平均值(考点:层序遍历)
计算每一层的节点值的平均值
class Solution {
public List<Double> averageOfLevels(TreeNode root) {
ArrayList<Double> reslist = new ArrayList<>();
Queue<TreeNode> queue = new LinkedList<>();
if(root == null)return reslist;
queue.add(root);
while (!queue.isEmpty()){
double len = queue.size();
double time = len;
double sum = 0;
while (len > 0) {
TreeNode node = queue.poll();
sum += node.val;
if(node.left != null)queue.add(node.left);
if(node.right != null)queue.add(node.right);
len--;
}
double avg = sum / time;
reslist.add(avg);
}
return reslist;
}
}
思路:层序遍历
每遍历完一层进行一次平均值计算
19.N 叉树的层序遍历(考点:层序遍历)
将之前的二叉树的层序遍历改成了N叉树
class Solution {
public List<List<Integer>> levelOrder(Node root) {
List<List<Integer>> reslist = new ArrayList<>();
Queue<Node> que = new LinkedList<>();
if(root == null)return reslist;
que.add(root);
while (!que.isEmpty()) {
int len = que.size();
LinkedList<Integer> itemlist = new LinkedList<>();
while (len > 0) {
Node node = que.poll();
itemlist.add(node.val);
if(node.children != null){
for (int i = 0; i < node.children.size(); i++) {
que.add(node.children.get(i));
}
}
len--;
}
reslist.add(itemlist);
}
return reslist;
}
}
思路:层序遍历
- 考虑主要是节点数比以前多
- 取到当前队列头的节点,遍历他的所有结点,将他所有的节点装入队列,每装好一次,就将其小集合加入到结果集中
20.在每个树行中找最大值(考点:层序遍历)
找出每一行树的最大值
class Solution {
public List<Integer> largestValues(TreeNode root) {
ArrayList<Integer> reslist = new ArrayList<>();
Queue<TreeNode> que = new LinkedList<>();
if(root == null)return reslist;
que.add(root);
while (!que.isEmpty()) {
int len = que.size();
int max = Integer.MIN_VALUE;
while (len > 0) {
TreeNode node = que.poll();
max = Math.max(max,node.val);
if(node.left != null)que.add(node.left);
if(node.right != null)que.add(node.right);
len--;
}
reslist.add(max);
}
return reslist;
}
}
思路:层序遍历
初始化最大值为integer型的最小数,遍历每个节点时,判断其是否为最大值
最后返回最大值的集合即可
21.填充每个节点的下一个右侧节点指针Ⅰ(考点:层序遍历)
给每个节点附上它的右指针
class Solution {
public Node connect(Node root) {
Queue<Node> que = new LinkedList<>();
if(root == null)return root;
que.offer(root);
while (!que.isEmpty()) {
int len = que.size();
Node node = que.poll();
if(node.left != null)que.add(node.left);
if(node.right != null)que.add(node.right);
for (int i = 1; i < len; i++) {
Node poll = que.poll();
if(poll.left != null)que.add(poll.left);
if(poll.right != null)que.add(poll.right);
node.next = poll;
node = poll;
}
}
return root;
}
}
思路:层序遍历
- 先取出队头的节点,把他的子节点加入到队列中
- 再取出下一个节点,for循环从1开始,确保了最右侧节点不进入循环达到右指针为空的目的,其余节点poll的右节点便是node
- 附右指针操作完成后,返回根节点即可
22.填充每个节点的下一个右侧节点指针 II(考点:层序遍历)

这道题用层序遍历的方法做的话,在原理上和上一道题代码是一样的
23.二叉树的最大深度(考点:层序遍历)
采用层序遍历记录二叉树的最大深度
class Solution {
public int maxDepth(TreeNode root) {
Queue<TreeNode> que = new LinkedList<>();
if(root == null)return 0;
que.offer(root);
int depth = 0;
while (!que.isEmpty()) {
int len = que.size();
depth++;
while (len > 0) {
TreeNode node = que.poll();
if(node.left != null)que.add(node.left);
if(node.right != null)que.add(node.right);
len--;
}
}
return depth;
}
}
思路:层序遍历
记录使队列不为空的次数,就相当于记录了节点层数,也可以视作是小集合的个数
24.二叉树的最小深度(考点:层序遍历)
采用层序遍历记录二叉树的最小深度
class Solution {
public int minDepth(TreeNode root) {
Queue<TreeNode> que = new LinkedList<>();
if(root == null)return 0;
que.offer(root);
int mindepth = 0;
while (!que.isEmpty()) {
int len = que.size();
mindepth++;
while (len > 0) {
TreeNode node = que.poll();
if(node.left == null && node.right == null)return mindepth;
if(node.left != null)que.add(node.left);
if(node.right != null)que.add(node.right);
len--;
}
}
return 0;
}
}
思路:层序遍历
在层序遍历的过程中,如果存在没有子节点的节点,可以立即停止遍历,记录此时根节点到此节点的深度,这样就得到了二叉树的最小深度
结果:

25.找树左下角的值(考点:层序遍历)
题目的突破点在于,所寻找的节点是树最底层的最左侧节点,所以采用层序遍历
class Solution {
public int findBottomLeftValue(TreeNode root) {
Queue<TreeNode> que = new LinkedList<>();
que.offer(root);
while (!que.isEmpty()) {
root = que.poll();
if(root.right != null)que.add(root.right);
if(root.left != null)que.add(root.left);
}
return root.val;
}
}
思路:层序遍历
- 之前层序遍历的添加顺序是从左到右,现在需要最左侧节点,就从右到左添加
- 并且可以直接赋给根节点,最后队列剩的就是底层最左叶节点,输出根结点的值就是答案
26.二叉树非递归遍历
1.二叉树的前序遍历(非递归版–迭代法)
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
ArrayList<Integer> list = new ArrayList<>();
if(root == null)return list;
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
if(node == null)continue;//由于有的子节点是空的,所以存在null,要pop掉,防止空指针
list.add(node.val);
stack.push(node.right);//栈的进出顺序是反的,所以前序遍历压右节点入栈
stack.push(node.left);
}
return list;
}
}
思路:
- 先入根节点,只要栈不空,先取出根节点,再把根节点值记录
- 栈的进出顺序是反的,所以前序遍历先压右再左
- 出栈后即为前序遍历顺序
2.二叉树的中序遍历(非递归版–迭代法)
class Solution {
public List<Integer> inorderTraversal(TreeNode root){
Stack<TreeNode> stack = new Stack<>();
ArrayList<Integer> list = new ArrayList<>();
if(root == null)return list;
TreeNode cur = root;
while (!stack.isEmpty() || cur != null) {
if (cur != null) {//一直向左找
stack.push(cur);
cur = cur.left;
}else {//如果当前的左孩子是空的,就把当前节点(中节点)记录,再向右找
cur = stack.pop();
list.add(cur.val);
cur = cur.right;
}
}
return list;
}
}
思路:
- 只要当前取到的节点不是空的,就向左一直找,并沿途将所有左边的节点入栈
如果当前的节点是空的,就将当前节点赋值为栈顶结点,记录它的值,再向他的右边找 - 只要节点取得为空或者栈空了说明所有节点已经被访问并记录过了
3.二叉树的后序遍历(非递归版–迭代法)
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
ArrayList<Integer> list = new ArrayList<>();
if(root == null)return list;
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
if(node == null)continue;//由于有的子节点是空的,所以存在null,要pop掉,防止空指针
list.add(node.val);
stack.push(node.left);
stack.push(node.right);//栈的进出顺序是反的,所以前序遍历压右节点入栈
}
Collections.reverse(list);
return list;
}
}
思路:
只需修改前序遍历的三行代码
前序遍历时根左右,后序遍历是左右根,将前序遍历时,添加左右子节点的顺序调换,就是根右左。然后反转集合就是,左右根,即为后序遍历顺序
27.完全二叉树的节点个数
①迭代法:
class Solution {
public int countNodes(TreeNode root) {
if(root == null)return 0;
if(root.left == null && root.right == null)return 1;
if(root.left != null && root.right == null)return 1 + countNodes(root.left);
if(root.left == null && root.right != null)return 1 + countNodes(root.right);
return 1 + countNodes(root.left) + countNodes(root.right);
}
}
思路:
- 在当前节点不是空的情况下,分三种情况:当前节点是叶子节点,就返回自己的个数1
- 当前节点只有左子节点或者只有右子节点,就返回自己的个数并且加上统计后的(递归过来的)左子节点或者统计过后的右子节点
- 当前节点有左右子节点,自己1个加上左右子树的节点个数即为答案
②层序遍历计数法:
class Solution {
public int countNodes(TreeNode root) {
Queue<TreeNode> que = new LinkedList<>();
int count = 0;
if(root == null)return 0;
que.offer(root);
while (!que.isEmpty()) {
int len = que.size();
while (len > 0) {
count++;
TreeNode node = que.poll();
if(node.left != null)que.add(node.left);
if(node.right != null)que.add(node.right);
len--;
}
}
return count;
}
}
思路:
按照层序遍历的思想,每遍历一个节点就记录,最后返回个数即可
③根据完全二叉树的特点递归法:
class Solution {
public int countNodes(TreeNode root) {
if(root == null)return 0;
int left = countdepth(root.left);
int right = countdepth(root.right);
if(left == right){
return (1 << left) + countNodes(root.right);
}else{
return (1 << right) + countNodes(root.left);
}
}
public int countdepth(TreeNode node){
int depth = 0;
while(node != null){
node = node.left;
depth++;
}
return depth;
}
}
思路:
- 根据完全二叉树的特点,最大深度可以从最底层的最左子节点确定,因此可以根据左子树和右子树的最大深度判断左子树还是右子树是满二叉树,因为满二叉树可以根据公式直接计算得到
- 先构造计算子树最大深度的方法,获取到左右子树的最大深度
- 如果深度相同,说明左子树是满二叉树,否则右子树是满二叉树
- 根据这一特点,直接计算出对应满二叉树的节点个数,再加上递归查找到的对面节点的个数。注意满二叉树计算公式是count = 2 ^ depth - 1,因为此时算的是根节点的深度,还要加上根节点本身,所以只需要计算2 ^ depth,即1 << depth
28.二叉搜索树
1. 修剪二叉搜索树
给定节点值的范围,凡是超出范围的节点,全部进行修剪
class Solution {
public TreeNode trimBST(TreeNode root, int low, int high) {
if(root == null)return root;
if(root.val > high)return trimBST(root.left,low,high);
if(root.val < low)return trimBST(root.right,low,high);
root.left = trimBST(root.left,low,high);
root.right = trimBST(root.right,low,high);
return root;
}
}
思路:
- 二叉搜索树这种特殊结构,是左子节点小于根节点,右子节点大于根节点
- 当前节点如果小于边界了,那它的左子树必然小于边界,它的右子树必然大于当前节点,所以此时去掉当前节点,把当前节点的右子树接到上一个节点去
- 同理如果当前节点大于边界了,可以排除他的右子树,直接接当前节点的左子树
- 最后,根节点的左子节点接处理好的左子树,右子节点接处理好的右子树
2.二叉搜索树中第K小的元素
①中序遍历法:
class Solution {
int cnt = 0;
int val;
public int kthSmallest(TreeNode root, int k) {
infixOrder(root,k);
return val;
}
public void infixOrder(TreeNode node,int k){
if(node == null)return;
infixOrder(node.left,k);
cnt++;
if (cnt == k) {
val = node.val;
return;
}
infixOrder(node.right, k);
}
}
思路:
- 二叉搜索树的中序遍历是从小到大的,由此特点可知,对二叉搜索树进行中序遍历
- 遍历的过程中,记录当前遍历的节点的值,如果当前节点的值等于看,说明寻找到第k小了
②递归法:
class Solution {
public int kthSmallest(TreeNode root, int k) {
int leftNum = count(root.left);
if(leftNum + 1 == k)return root.val;
if(leftNum > k - 1)return kthSmallest(root.left,k);
return kthSmallest(root.right,k - leftNum - 1);
}
public int count(TreeNode node){
if(node == null)return 0;
return 1 + count(node.left) + count(node.right);
}
}
思路:
- 计算左子树中的节点总数leftNum
- 如果leftNum +1=k,说明查找的节点为根节点
- 如果leftNum >=k,说明查找的节点在左子树中
- 否则查找的节点在右子树中,在右子树中查找第k-lnum-1大的节点(因为递归进去是按照左子树的逻辑寻找节点的,所以此时寻找的数要改变)
3.二叉搜索树中的搜索
给定二叉搜索树(BST)的根节点和一个值。 你需要在BST中找到节点值等于给定值的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 NULL。
class Solution {
public TreeNode searchBST(TreeNode root, int val) {
if(root == null)return null;
if(root.val == val)return root;
if(root.val > val)return searchBST(root.left,val);
return searchBST(root.right,val);
}
}
思路:
- 由于二叉搜索树的特点,先确定终止条件
- 只要当前节点是要搜索的节点返回即可
- 大于当前节点的值向右递归,小于当前结点的值向左递归
4.验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树
①递归法:
class Solution {
public boolean isValidBST(TreeNode root){
return helper(root,Long.MIN_VALUE, Long.MAX_VALUE);
}
public boolean helper(TreeNode node,long lower,long upper){
if(node == null)return true;
if(node.val <= lower || node.val >= upper){
return false;
}
return helper(node.left,lower,node.val) && helper(node.right,node.val,upper);
}
}
思路:
- 由题目给出的信息我们可以知道:**如果该二叉树的左子树不为空,则左子树上所有节点的值均小于它的根节点的值; 若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值;它的左右子树也为二叉搜索树。**因此可以构建一个拥有上界和下界的函数
- 通过递归地判断每个节点值是否在前一个节点允许的范围内,从而得到结果
②中序遍历递归法:
*/
class Solution {
long pre = Long.MIN_VALUE;
public boolean isValidBST(TreeNode root){
return inorder(root);
}
public boolean inorder(TreeNode node){
if(node == null)return true;
boolean l = inorder(node.left);
if(node.val <= pre)return false;
pre = node.val;
boolean r = inorder(node.right);
return l && r;
}
}
思路:
由于二叉搜索树的特点是中序遍历是从小到大的,所以按中序遍历来判断每个节点,如果节点值比前一个大,说明不是二叉搜索树
5.二叉搜索树的最小绝对差
给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。
差值是一个正数,其数值等于两值之差的绝对值。
①中序遍历递归法:
class Solution {
ArrayList<Integer> list = new ArrayList<>();
public int getMinimumDifference(TreeNode root) {
if(root == null)return 0;
infixorder(root);
int min = Integer.MAX_VALUE;
for (int i = 0,j = 1; i < list.size() && j < list.size(); i++,j++) {
min = Math.min(min,list.get(j) - list.get(i));
if (min == 1)return 1;
}
return min;
}
public void infixorder(TreeNode node){
if(node.left != null){
infixorder(node.left);
}
list.add(node.val);
if(node.right != null){
infixorder(node.right);
}
}
}
思路:
- 很简单,二叉搜索树中序遍历有序,所以用集合记录
- 遍历集合相近数的差,差是1直接返回
②中序遍历迭代法:
class Solution {
public int getMinimumDifference(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
int min = Integer.MAX_VALUE;
TreeNode cur = root;
TreeNode pre = null;
while (!stack.isEmpty() || cur != null) {
if (cur != null) {
stack.push(cur);
cur = cur.left;
}else {
cur = stack.pop();
if(pre != null)min = Math.min(min,cur.val - pre.val);
pre = cur;
cur = cur.right;
}
}
return min;
}
}
思路:
- 中序遍历迭代写法
- 记录前一个节点,每次判断一下当前节点与前结点的差值。最后返回最小差值
6. 二叉搜索树中的众数
给定一个有相同值的二叉搜索树(BST),找出 BST 中的所有众数(出现频率最高的元素)
①暴力解法:
class Solution {
HashMap<Integer, Integer> map = new HashMap<>();
public int[] findMode(TreeNode root) {
if(root == null)return null;
infixorder(root);
int max = 0;
//计算众数
Set<Map.Entry<Integer, Integer>> entrySet = map.entrySet();
for (Map.Entry<Integer, Integer> entry : entrySet) {
max = Math.max(max,entry.getValue());
}
//计算众数的个数
int num = 0;
for (Map.Entry<Integer, Integer> entry : entrySet) {
if(entry.getValue() == max)num++;
}
//数组长度为1和不为1的分情况讨论
if(num == 1){
for (Map.Entry<Integer, Integer> entry : entrySet) {
if(max == entry.getValue())return new int[]{entry.getKey()};
}
return null;
}else {
int[] arr = new int[num];
int index = 0;
for (Map.Entry<Integer, Integer> entry : entrySet) {
if(entry.getValue() == max){
arr[index] = entry.getKey();
index++;
}
}
return arr;
}
}
public void infixorder(TreeNode node){
if (node.left != null) {
infixorder(node.left);
}
map.put(node.val,map.getOrDefault(node.val,0) + 1);
if (node.right != null) {
infixorder(node.right);
}
}
}
中序递归暴力解法不论述,有注解
7.二叉搜索树的最近公共祖先
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
①递归法:
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root == null || root == p || root == q)return root;
if((p.val > root.val && q.val < root.val) || (p.val < root.val && q.val > root.val))return root;
if(p.val > root.val && q.val > root.val)return lowestCommonAncestor(root.right,p,q);
if(p.val < root.val && q.val < root.val)return lowestCommonAncestor(root.left,p,q);
return root;
}
}
思路:
- 同35的思路差不多:确定递归终止条件
- 如果两节点一个比根节点大,一个比根节点小,那么他们的最近祖先肯定是根节点
- 如果都比根节点大,说明祖先在右子树里,返回递归处理好的右子树即可
- 如果都比根节点小,说明祖先在左子树里,返回递归处理好的左子树即可
②迭代法:
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
while (root != null){
if(root.val > p.val && root.val > q.val){
root = root.left;
}else if(root.val < p.val && root.val < q.val){
root = root.right;
}else {
return root;
}
}
return null;
}
}
思路:
只要当前节点值比p和q同时大或者同时小,就向右或者向左找,直到两个节点是某个结点的各一边,说明这个节点是它们的祖先节点
8.二叉搜索树中的插入操作
给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据 保证 ,新值和原始二叉搜索树中的任意节点值都不同。
①递归法:
class Solution {
public TreeNode insertIntoBST(TreeNode root, int val) {
if(root == null)return new TreeNode(val);
if(val < root.val)root.left = insertIntoBST(root.left,val);
if(val > root.val)root.right = insertIntoBST(root.right,val);
return root;
}
}
思路:
- 终止递归条件比较特殊,本题为何终止,是因为到了要添加节点的位置,所以root == null时要挂节点
- 根据与根节点的值判断,不断递归,root的左右子树接处理好的左右子树,返回root即可
②迭代法:
class Solution {
public TreeNode insertIntoBST(TreeNode root, int val) {
if(root == null)return new TreeNode(val);
TreeNode newroot = root;
TreeNode pre = null;
while (root != null) {
pre = root;
if (val > root.val) {
root = root.right;
}else {
root = root.left;
}
}
if (pre.val > val) {
pre.left = new TreeNode(val);
}else {
pre.right = new TreeNode(val);
}
return newroot;
}
}
思路:
- 终止条件也是找到节点的位置后,需要创建节点
- 先保存一下根节点,再定义一个前节点,不断向下找,找到添加的位置后,根据值的大小添加至前节点的左或右
9.删除二叉搜索树中的节点
给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
//浏览一圈也找不到,或者找到了,删除并返回null
if(root==null) return null;
//还没到最后一个,继续查找
if(root.val>key){
root.left = deleteNode(root.left, key);
}else if(root.val<key){
root.right = deleteNode(root.right, key);
}else{
//找到了,root有右孩子,则返回右孩子作为父节点
if(root.left==null) return root.right;
//找到了,root有左孩子,则返回左孩子作为父节点
else if(root.right==null) return root.left;
//找到了,root有左右孩子,则遍历右孩子的最左边的节点
TreeNode cur = root.right;
while(cur!=null && cur.left!=null){
cur = cur.left;
}
//把root的左孩子放到右孩子的最左边的节点的左孩子
cur.left = root.left;
root = root.right;
}
return root;
}
}
思路:删除节点需要先查找,再删除。有五种情况:
- 找了一圈,直至root到null也没找到,则返回null
- 找到了,root为叶子节点,删除则返回null
- 找到了,root有左孩子,删除则返回左孩子
- 找到了,root有右孩子,删除则返回右孩子
- 找到了,root有左右孩子,则将左孩子放到右孩子的最左边的叶子节点上,返回右孩子
10.将有序数组转换为二叉搜索树
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
class Solution {
public TreeNode sortedArrayToBST(int[] nums) {
return dfs(nums,0,nums.length -1);
}
public TreeNode dfs(int[] nums,int s,int e){
if(s > e)return null;
int mid = s + (e - s) / 2;
TreeNode node = new TreeNode(nums[mid]);
node.left = dfs(nums,s,mid - 1);
node.right = dfs(nums,mid + 1,e);
return node;
}
}
思路:
- 本质就是中序遍历构造二叉搜索树,所以要进行深度遍历进行构造
- 首先就要确定根节点,数组为偶数时会产生两种不同的二叉搜索树,所以造成了问题的不唯一
- 以中间的值为分割点,左边的数组构成了左子树,右边的数组构成了右子树
- 深度遍历,不断改变区间进行递归,处理好的左右子树接到新节点上即可
11. 把二叉搜索树转换为累加树
给定一个二叉搜索树,请将它的每个节点的值替换成树中大于或者等于该节点值的所有节点值之和。
class Solution {
int pre;
public TreeNode bstToGst(TreeNode root) {
if(root == null)return null;
infixorder(root);
return root;
}
public void infixorder(TreeNode node){
if(node.right != null){
infixorder(node.right);
}
node.val += pre;
pre = node.val;
if(node.left != null){
infixorder(node.left);
}
}
}
思路:
- 二叉搜索树进行反中序遍历,即右根左
- 记录前一个节点的值,遍历时加等前一个节点的值
- 此时已经构成复合题目的累加树
12.有序链表转换二叉搜索树
给定一个单链表,其中的元素按升序排序,将其转换为高度平衡的二叉搜索树。
class Solution {
public TreeNode sortedListToBST(ListNode head) {
//终止递归条件
if(head == null){
return null;
}else if(head.next == null){
return new TreeNode(head.val);
}
//快慢指针定中间节点
ListNode low = head,fast = head,pre = null;
while (fast != null && fast.next != null){
pre = low;
low = low.next;
fast = fast.next.next;
}
pre.next = null;
//递归构建节点
TreeNode node = new TreeNode(low.val);
node.left = sortedListToBST(head);
node.right = sortedListToBST(low.next);
return node;
}
}
思路:
- 按照有序数组构造二叉搜索树的思路,所以要找到中心节点
- 运用快慢指针找到中心节点,构造pre用来切断链表
- 目的是为了进行左右递归创造节点,将head从pre切开,head变为pre左边部分,low为pre右边部分
13.两数之和 IV - 输入 BST
给定一个二叉搜索树 root 和一个目标结果 k,如果 BST 中存在两个元素且它们的和等于给定的目标结果,则返回 true。
①暴力解法:
class Solution {
ArrayList<Integer> list = new ArrayList<>();
public boolean findTarget(TreeNode root, int k) {
if(root == null)return false;
infixorder(root);
for (int i = 0; i < list.size(); i++) {
for (int j = i + 1; j < list.size(); j++) {
if(k == list.get(i) + list.get(j))return true;
}
}
return false;
}
public void infixorder(TreeNode node){
if(node.left != null)infixorder(node.left);
list.add(node.val);
if(node.right != null)infixorder(node.right);
}
}
思路:
- 中序遍历树,记录所有节点值
- 双循环查找所有集合中的元素,有无和为k的
29.输出所有二叉树路径(考点:回溯)
①递归法:

class Solution {
public List<String> binaryTreePaths(TreeNode root) {
ArrayList<String> reslist = new ArrayList<>();
if(root == null)return reslist;
ArrayList<Integer> list = new ArrayList<>();
traversal(root,reslist,list);
return reslist;
}
public void traversal(TreeNode node,List<String> list,List<Integer> paths){
paths.add(node.val);
//叶子节点
if(node.left == null && node.right == null){
StringBuilder sb = new StringBuilder();
for (int i = 0; i < paths.size() - 1; i++) {
sb.append(paths.get(i)).append("->");
}
sb.append(paths.get(paths.size() - 1));
list.add(sb.toString());
return;
}
if(node.left != null){
traversal(node.left,list,paths);
paths.remove(paths.size() - 1);
}
if(node.right != null){
traversal(node.right,list,paths);
paths.remove(paths.size() - 1);
}
}
}
思路:
- 定义一个用于记录路径的集合,一个记录路径的节点值值的集合,将根节点和两集合传入回溯方法
- 对于回溯方法:先将根节点的值记录路径节点集合
- 分三种情况讨论:当前节点是叶子节点,即为当前回溯方法的终止条件
- 当前节点是叶子节点:将路径节点值依次取出拼串,最后取出叶子节点值再拼串,将该字符串装入结果集中
- 如果当前节点的左子节点不为空,递归向左执行,此时递归之后,还要删掉最后一个节点,因为要回溯!
- 如果当前节点的右子节点不为空,递归向右执行,此时递归之后,还要删掉最后一个节点,因为要回溯!
②迭代法:
class Solution {
public List<String> binaryTreePaths(TreeNode root) {
ArrayList<String> list = new ArrayList<>();
Stack<Object> stack = new Stack<>();
if(root == null)return list;
stack.push(root);
stack.push(root.val + "");
while(!stack.isEmpty()){
String path = (String)stack.pop();
TreeNode node = (TreeNode)stack.pop();
if(node.left == null && node.right == null){
list.add(path);
}
if(node.left != null){
stack.push(node.left);
stack.push(path + "->" + node.left.val);
}
if(node.right != null){
stack.push(node.right);
stack.push(path + "->" + node.right.val);
}
}
return list;
}
}
思路:
- 定义结果集,定义一个可以存放Object类的栈用于记录路径,因为栈这种结构适合模仿递归回溯的操作,递归向下一条路径记录后,弹出栈顶的元素,即可保留除叶子节点之外的路径,这样可以在保留原有的路径基础上更换或者添加新的叶子节点
- 将节点先放入栈,以保证取出节点用于向下寻找路径。将节点值放入栈,用于拼接路径的字符串
- 当栈不为空时,取出当前路径,再取出当前节点,如果此时的节点是叶子节点,就将当前路径录入结果集
- 如果当前节点有左子节点,当前节点入栈,包含当前节点和当前节点的左子节点的路径字符串也入栈
- 如果当前节点有右子节点,当前节点入栈,包含当前节点和当前节点的右子节点的路径字符串也入栈
30.相同的树
class Solution {
public boolean isSameTree(TreeNode p, TreeNode q) {
if (p == null && q == null)return true;
if(p == null || q == null)return false;
if(p.val != q.val)return false;
return isSameTree(p.left, q.left)&&isSameTree(q.right, p.right);
}
}
思路:
- 终止条件在于两树为空时的判断
- 当前两节点的值不相等时返回false
- 输出两个根节点的左右子节点的判断值
31. 从中序与后序遍历序列构造二叉树(考点:构建树)
根据一棵树的中序遍历与后序遍历构造二叉树。
class Solution {
HashMap<Integer,Integer> memo = new HashMap<>();
int[] post;
public TreeNode buildTree(int[] inorder, int[] postorder) {
for (int i = 0; i < inorder.length; i++) {
memo.put(inorder[i],i);
}
post = postorder;
return helper(0,inorder.length - 1,0,postorder.length - 1);
}
private TreeNode helper(int is, int ie, int ps, int pe) {
if(ie < is || pe < ps)return null;
int root = post[pe];
int rootIndex = memo.get(root);
TreeNode node = new TreeNode(root);
node.left = helper(is,rootIndex - 1,ps,ps + rootIndex - is - 1);
node.right = helper(rootIndex + 1,ie,ps + rootIndex - is,pe - 1);
return node;
}
}
图解:
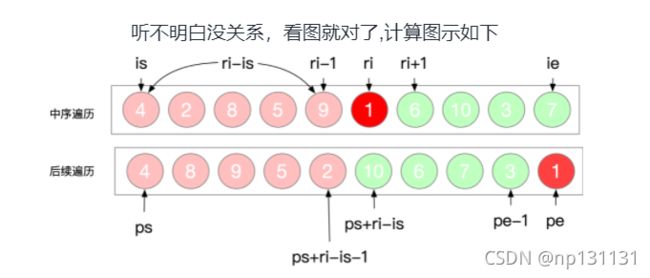
思路:
- 中序后序遍历确定一棵树,是通过将后序遍历的最后一个数取出,作为分割点去分中序遍历
- 从而中序遍历的左右子序列区间就是左子树和右子树,递归下去,就能构建一棵二叉树
- 重点在于区间的划分,取得分割点也就是当前结点的值。解释:因为左子树是一个变量,所以需要计算一下左子树的长度,那么左子树的后续数组的起始索引就是ps,ps + ri - is(左子树长度) - 1。
- 在就是用hash表来存储节点的值及其索引,便于构建当前节点
32. 从中序与前序遍历序列构造二叉树(考点:构建树)
根据一棵树的中序遍历与前序遍历构造二叉树。
class Solution {
HashMap<Integer,Integer> memo = new HashMap<>();
int[] pre;
public TreeNode buildTree(int[] preorder, int[] inorder) {
for (int i = 0; i < inorder.length; i++) {
memo.put(inorder[i],i);
}
pre = preorder;
return helper(0,preorder.length - 1,0,inorder.length - 1);
}
private TreeNode helper(int ps, int pe, int is, int ie) {
if(ie < is || pe < ps)return null;
int root = pre[ps];
TreeNode node = new TreeNode(root);
int rootIndex = memo.get(root);
node.left = helper(ps + 1,rootIndex - is + ps,is,rootIndex - 1);
node.right = helper(rootIndex - is + ps + 1,pe,rootIndex + 1,ie);
return node;
}
}
图解:

思路:同前题一样
注意:前序和后序不能唯⼀确定⼀颗⼆叉树!!!
33.最大二叉树(考点:构建树)
给定一个不含重复元素的整数数组 nums 。一个以此数组直接递归构建的 最大二叉树 定义如下:
二叉树的根是数组 nums 中的最大元素。
左子树是通过数组中 最大值左边部分 递归构造出的最大二叉树。
右子树是通过数组中 最大值右边部分 递归构造出的最大二叉树。
class Solution {
HashMap<Integer, Integer> map = new HashMap<>();
public TreeNode constructMaximumBinaryTree(int[] nums) {
if(nums == null || nums.length == 0)return null;
for (int i = 0; i < nums.length; i++) {
map.put(nums[i],i);
}
return helper(nums,0,nums.length - 1);
}
public TreeNode helper(int[] nums,int left,int right){
//1.确定终止条件
if(left > right)return null;
//2.确定最大值以及最大值索引
int root = getMax(nums,left,right);
int ri = map.get(root);
//3.创建新节点
TreeNode node = new TreeNode(root);
node.left = helper(nums,left,ri - 1);
node.right = helper(nums,ri + 1,right);
return node;
}
public int getMax(int[] arr,int s,int e) {
int[] smallarr = Arrays.copyOfRange(arr, s, e + 1);
Arrays.sort(smallarr);
return smallarr[smallarr.length - 1];//返回最大值
}
}
思路:采用上面构建树的整体思想
- 定义哈希表存放所有节点值和节点的索引,定义带有索引的新方法来辅助构建新树
- 首先确定终止条件,其次确定最大值以及最大值索引,最后创建新节点
- 注意取最大值时,是取的全闭合范围内的小数组
34.路径总和(考点:回溯)
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
class Solution {
public List<List<Integer>> pathSum(TreeNode root, int targetSum) {
ArrayList<List<Integer>> reslist = new ArrayList<>();
LinkedList<Integer> path = new LinkedList<>();
if(root == null)return reslist;
traversal(root,targetSum,reslist,path);
return reslist;
}
private void traversal(TreeNode node, int targetSum,ArrayList<List<Integer>> reslist,LinkedList<Integer> path) {
if(node == null)return;
path.offer(node.val);
//叶子节点(即终止条件)
if(node.left == null && node.right == null){
if(node.val == targetSum)reslist.add(new ArrayList<>(path));
return;
}
//向左递归并回溯
if(node.left != null){
traversal(node.left,targetSum - node.val,reslist,path);
path.pollLast();
}
//向右递归并回溯
if(node.right != null){
traversal(node.right,targetSum - node.val,reslist,path);
path.pollLast();
}
}
}
思路:
想想这棵树只有三个节点
①
/ \
② ③
一上来就得把当前节点放到path中。
当前节点进入队列之后会遇到三种情况。
- 当前节点是叶子节点。没有左右节点。
如果符合就加入结果集。不符合就当没事发生,return 宣告这条路径已遍历结束。 - 当前节点是非叶子节点,其左节点不为空
就要以②作为根节点,目标值 - 根节点的值作为新的目标值进行下一轮的递归。
递归返回,说明该路径已经遍历结束,递归之后需要对路径进行回溯。
递归函数刚进去就是把当前节点进队列 path.offer(root.val);,那么回溯就是要把当前节点出队列path.pollLast();。 - 当前节点是非叶子节点,其右节点不为空。
就要以③作为根节点,目标值 - 根节点的值作为新的目标值进行下一轮的递归。
递归返回,说明该路径已经遍历结束,递归之后需要对路径进行回溯。
递归函数刚进去就是把当前节点进队列 path.offer(root.val);,那么回溯就是要把当前节点出队列path.pollLast();
35.二叉树的最近公共祖先(考点:回溯)
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root == null || root == p || root == q)return root;
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p, q);
if(left != null && right != null)return root;
if(left == null && right != null)return right;
return left;
}
}
思路:
- 两个结点的公共祖先,首先想到自底向上寻找比较方便,所以采用后序遍历,后序遍历首先访问叶子节点,所以用到递归以及回溯
- 递归的终止条件要考虑清楚
- 先取出递归完成后的左子树和右子树
- 此时递归完成传回来的左右子树都为空,那说明没有祖先节点,那root自己就是
- 此时递归完成传回来的左右子树有一个为空,说明不空的那个树是空树的祖先节点,那返回非空的树(节点)即可
36.实现 Trie (前缀树)(考点:Trie 树)
将字符串中的所有字符按照树的结构存储起来,以便提高字符串的前缀查找速度
class Trie {
private class Node{
Node[] childs = new Node[26];
boolean isLeaf;
}
private Node root = new Node();
public Trie() {}
public void insert(String word) {
insert(word,root);
}
private void insert(String word,Node node) {
if(node == null)return;
if(word.length() == 0){
node.isLeaf = true;
return;
}
int index = indexForChar(word.charAt(0));
if (node.childs[index] == null) {
node.childs[index] = new Node();
}
insert(word.substring(1),node.childs[index]);
}
public boolean search(String word) {
return search(word, root);
}
private boolean search(String word,Node node){
if(node == null)return false;
if(word.length() == 0)return node.isLeaf;
int index = indexForChar(word.charAt(0));
return search(word.substring(1),node.childs[index]);
}
public boolean startsWith(String prefix) {
return startsWith(prefix,root);
}
private boolean startsWith(String prefix,Node node) {
if (node == null)return false;
if (prefix.length() == 0)return true;
int index = indexForChar(prefix.charAt(0));
return startsWith(prefix.substring(1),node.childs[index]);
}
private int indexForChar(char c) {
return c - 'a';
}
}
思路:
需要构建节点,而且节点还需要一个能判断是否为叶子节点的属性
根据传入的字符记录每个字符的索引值
无论是根据搜索字符串,还是搜索字符串前缀,都可根据索引值,以及字串,不断递归寻找答案
37.键值映射(考点:Trie 树)
实现一个 MapSum 类,支持两个方法,insert 和 sum.并以键值对的形式完成字符串的查找等操作
class MapSum {
private class Node {
Node[] child = new Node[26];
int value;
}
private Node root = new Node();
public MapSum() {}
public void insert(String key, int val) {
insert(key, root, val);
}
private void insert(String key, Node node, int val) {
if (node == null) return;
if (key.length() == 0) {
node.value = val;
return;
}
int index = indexForChar(key.charAt(0));
if (node.child[index] == null) {
node.child[index] = new Node();
}
insert(key.substring(1), node.child[index], val);
}
public int sum(String prefix) {
return sum(prefix, root);
}
private int sum(String prefix, Node node) {
if (node == null) return 0;
if (prefix.length() != 0) {
int index = indexForChar(prefix.charAt(0));
return sum(prefix.substring(1), node.child[index]);
}
int sum = node.value;
for (Node child : node.child) {
sum += sum(prefix, child);
}
return sum;
}
private int indexForChar(char c) {
return c - 'a';
}
}
38. 前缀树实现过滤敏感词
- 首先对字符串进行空值判断,定义三个指针(前缀树的工作指针、左指针、右指针),用StringBuilder记录过滤后的文本
- 只要右指针没到最后就一直循环拼串,此时取出右指针所指的字符
- 先判断是不是符号,如果是符号且工作指针在根节点,就记录此时的符号并跳过
- 取当前字符的子节点,如果是空值,就说明到该字符的字符串不是敏感词拼当前字符串;如果当前字符是叶子节点,说明从左指针到当前字符的字符串是敏感词,就把这段代替掉,左指针跳转到当前右指针的下一位;其余情况都是仅右指针右移一个。
- 最后还要把最后的非敏感词词汇加入到文本中
public String filter(String text){
if(StringUtils.isBlank(text)){
reutrn null;
}
TireNode tempNode = rootNode;
int begin = 0;
int end = 0;
StringBuilder sb = new StringBuilder();
while(end < text.length()){
char c = text.charAt(end);
if(isSymbol){
if(tempNode = rootNode){
sb.append(c);
begin++;
}
end++;
continue;
}
tempNode = tempNode.getSubNodes(c);
if(tempNode = null){
sb.append(text.charAt(begin));
end = ++begin;
tempNode = rootNode;
}else if(tempNode.isKeywordEnd()){
sb.append(REPLACEMENT);
begin = ++end;
tempNode = rootNode;
}else{
end++;
}
}
sb.append(text.substring(begin));
return sb.toString();
}
题目思路快速回顾





报错总结:
- 一般出现空指针报错,是因为某个环节或者报错的位置出现了变量存在空的情况没有解决的
- 一般出现角标越界,可能是取边界出了问题,注意当前的区间是左闭右开还是左开右闭或者全闭合的
- 一般出现提交答案出现超出时间限制,对于递归的题来说,可能是逻辑正确,但是终止递归条件没写对
树结构总结
1.树的类型
主要以满二叉树和完全二叉树两种形式为主,二叉搜索(排序)树、平衡二叉树(AVL)、霍夫曼树、多路查找树(B树、B+树、B*树)
2.树的存储方式
顺序存储二叉树(数组实现)和链式存储二叉树(链表实现)
3.遍历方式
①递归遍历
前中后序遍历:经典三步代码搞定
②层序遍历
- 先将根节点加入到队列中,只要当前的队列是空的,记录当前队列的长度,进入这个长度的循环
- 取出队列的头,把队列的头的值加到小集合里,如果当前节点没有子节点就直接减长度出循环;如果有子节点,就把子节点加入队列
- 每次小集合装好后,记得把小的集合装入大集合中
- 最后进行层序遍历,返回全局变量,即大集合
!!!层序遍历模板:
public static int minDepth(TreeNode root) {
Queue<TreeNode> que = new LinkedList<>();
/**
创建队列!,用于将节点入队,先进先出原则,确保了层序遍历的顺序
有时也需要用双端队列,双端队列就需要注意其下的方法pollFirst、peekFirst,pollLast,peekLast的区别
Deque que = new LinkedList<>();
*/
//ArrayList> reslist = new ArrayList<>();层序遍历时存储每层的大集合
if(root == null)return 0;//判断根节点为空的情况
que.offer(root);//先将根节点入队
while (!que.isEmpty()) {//只要队列不为空进入循环
int len = que.size();//取队列的长度
//ArrayList itemlist = new ArrayList<>();
//层序遍历的小集合
while (len > 0) {//根据队列中结点的个数,将每个节点的子节点通过循环加入到队列中
//有时也用for循环,好处是可以跳过本节点,根据需要选择for循环
TreeNode node = que.poll();//将队列的第一个节点抛出
//itemlist.add(node.val);层序遍历需要把抛出的节点值记录到小集合中
//子节点入队
if(node.left != null)que.add(node.left);
if(node.right != null)que.add(node.right);
//!!!while循环记得递减循环次数
len--;
}
//reslist.add(itemlist);层序遍历每一层后,都要将小集合装入到大集合中
}
return 0;//根据题目需求改变核心,返回所需变量
}
③迭代遍历
- 前序和后序的迭代遍历法几乎是相同的,用栈实现,将前序遍历里入栈的顺序颠倒一下,前序遍历是根左右,颠倒之后是根右左,将得到的集合翻转就是后序遍历的左右根。
- 中序遍历迭代法与前后序不同,还要考虑中结点是否被访问过
④顺序存储二叉树的遍历方式
考虑到数组存储要根据索引存储,所以根据二叉树的存储公式。可写为:
//前序遍历
public void preOrder(int index){
if(arr==null||arr.length==0){
System.out.println("该顺序二叉树为空,无法遍历");
}
System.out.print(arr[index]+" ");
if((index*2+1)<arr.length){//向左递归遍历
preOrder((index*2+1));
}
if((index*2+2)<arr.length){//向右递归遍历
preOrder((index*2+2));
}
}
4.二叉树的关系
- 对于顺序存储,不需要维护有序性,但查询效率低;而有序(链式)存储,查询效率高,但由于插入删除需要维护有序性,因此效率低。二叉排序树结合了二者的优势,不仅查询效率高,插入和删除效率也高。平衡二叉树是二叉排序树的升级和优化,排序树通过左、右或者双旋转变成平衡二叉树,当给一个升序数组时,转为二叉排序树就更像一个单链表,查询速度还比单链表慢,所以体现不出二叉排序树的优势,而平衡二叉树很好地解决了这个不足。树结构的查询效率高,并且可以保持有序,这使得数据库索引使用非常便利。在实际情况下,我们不得不考虑另外一个现实问题,磁盘IO,因为数据库的索引通常十分庞大,需要以文件形式存储,而磁盘IO的存取次数就是评价一个数据库索引优劣的关键性指标。
- 树的查找是由树的高度决定的,所以在二叉查找树中,最坏的情况下,磁盘的IO次数等于索引树的高度,而二叉查找树的性质决定了,大数据量的情况下树的高度必然会很高,所以为了减少磁盘IO次数,我们需要将瘦高的树变得矮胖,这也是B-tree的特征之一。
- 二叉树作为一种数据结构,还是要被实际使用的。当节点少的时候,没什么问题。如果节点很多,就需要进行多次 i/o 操作(海量数据存在数据库或文件中),所以构建二叉树时,速度就会有影响。而且二叉树的高度也会很大,降低操作速度,此时就需要B树这种数据结构。B-tree 树即 B 树,B 即 Balanced,平衡的意思。B-tree这个数据结构一般用于数据库的索引,综合效率较高。
而 B+树更适合文件索引系统,B 树和 B+树各有自己的应用场景,不能说 B+树完全比 B 树好 - B树和B+树的区别:以一个m阶树为例。
1、关键字的数量不同;B+树中分支结点有m个关键字,其叶子结点也有m个,其关键字只是起到了一个索引的作用,但是B树虽然也有m个子结点,但是其只拥有m-1个关键字。
2、存储的位置不同;B+树中的数据都存储在叶子结点上,也就是其所有叶子结点的数据组合起来就是完整的数据,但是B树的数据存储在每一个结点中,并不仅仅存储在叶子结点上。
3、分支结点的构造不同;B+树的分支结点仅仅存储着关键字信息和儿子的指针(这里的指针指的是磁盘块的偏移量),也就是说内部结点仅仅包含着索引信息。
4、查询不同;B树在找到具体的数值以后,则结束,而B+树则需要通过索引找到叶子结点中的数据才结束,也就是说B+树的搜索过程中走了一条从根结点到叶子结点的路径。 - B*树是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针。
第八章 图
1.判断是否为二分图
相邻节点不能是同一个数组的,可以采用染色法,即对每一个节点标注,如果相邻节点是相同的颜色就返回false
class Solution {
private boolean flag = true; //是否是二分图
private int[] colors; //每个节点的着色情况,0为未着色,其余两种颜色用1和-1表示
public boolean isBipartite(int[][] graph) {
int n = graph.length;
colors = new int[n]; //初始化为0,表示未着色
for (int i = 0; i < n && flag; i++) { //防止有孤立节点,应该遍历所有节点着色,若flag已经不成立则可以直接退出循环
if (colors[i] == 0) dfs(i, 1, graph); //如果未着色,就对其进行处理
}
return flag;
}
public void dfs(int v, int color, int[][] graph) { //v代表节点编号,color代表将要染的颜色
if (colors[v] != 0) { //如果该结点已经染过色
if (colors[v] != color) flag = false; //已经染的色和将要染的色冲突,说明二分图不成立
return;
}
colors[v] = color; //染上颜色
for (int w :graph[v]) {
dfs(w, -color, graph); //给该节点的邻接节点染上相反的颜色
}
}
}
思路:
如注解