31 | 误删数据后除了跑路,还能怎么办?
文章目录
- MySQL45讲
-
- 实践篇
-
- 31 | 误删数据后除了跑路,还能怎么办?
-
- 误删行
- 误删库 / 表
- 延迟复制备库
- 预防误删库 / 表的方法
- rm 删除数据
MySQL45讲
实践篇
31 | 误删数据后除了跑路,还能怎么办?
误删数据情景分类:
- 使用 delete 语句误删数据行;
- 使用 drop table 或者 truncate table 语句误删数据表;
- 使用 drop database 语句误删数据库;
- 使用 rm 命令误删整个 MySQL 实例。
误删行
如果使用 delete 语句误删了数据行,可以用 Flashback 工具通过闪回把数据恢复回来。
Flashback 恢复数据的原理,是修改 binlog 的内容,拿回原库重放。而能够使用这个方案的前提是,需要确保 binlog_format=row 和 binlog_row_image=FULL。
每一个数据行更改事件会包含两份影像(image)。
- 一份是 before image,是指被更改前的列(值);
- 一份是 after image,是指被更改后的列(值)。
默认配置下,mysql 会在 before image 和 after image 中记录更改数据行的所有列。
当删除一条数据行时,仅仅只有 before image。
当插入一条数据行时,仅仅只有after image。
当更新一条数据行时,才会同时记录 before image和 after image。
参数 binlog_row_image(默认值是 FULL) 有如下配置:
- FULL:在 before image 和 after image 中,记录所有的列值;
- MINIMAL:在 before image 和 after image 中,仅仅记录被更改的以及能够唯一识别数据行的列值;
- NOBLOB :在 before image 和 after image 中,记录所有的列值,但是 BLOB 与 TEXT 列除外(如未更改)。
具体恢复数据时,对单个事务做如下处理:
- 对于 insert 语句,对应的 binlog event 类型是 Write_rows event,把它改成 Delete_rows
event 即可; - 同理,对于 delete 语句,也是将 Delete_rows event 改为 Write_rows event;
- 而如果是 Update_rows 的话,binlog 里面记录了数据行修改前和修改后的值,对调这两行的位置即可。
如果误操作不是一个,而是多个,比如下面三个事务:
(A)delete ...
(B)insert ...
(C)update ...
要把数据库恢复回这三个事务操作之前的状态,用 Flashback 工具解析 binlog 后,写回主库的命令是:
(reverse C)update ...
(reverse B)delete ...
(reverse A)insert ...
具体操作参考binlog2sql。
如果误删数据涉及到了多个事务的话,需要将事务的顺序调过来再执行。
不建议直接在主库上执行这些操作。恢复数据比较安全的做法,是恢复出一个备份,或者找一个从库作为临时库,在这个临时库上执行这些操作,然后再将确认过的临时库的数据,恢复回主库。
因为,一个在执行线上逻辑的主库,数据状态的变更往往是有关联的。可能由于发现数据问题的时间晚了一点儿,就导致已经在之前误操作的基础上,业务代码逻辑又继续修改了其他数据。所以,如果这时候单独恢复这几行数据,而又未经确认的话,就可能会出现对数据的二次破坏。
除了误删数据的事后处理办法,更重要是要做到事前预防。 建议如下:
- 将 sql_safe_updates 参数设置为 on。这样一来,如果忘记在 delete 或者 update 语句中写 where 条件,或者 where 条件里面没有包含索引字段的话,这条语句的执行就会报错。
- 代码上线前,必须经过 SQL 审计。
使用 delete 命令删除的数据,可以用 Flashback 来恢复。而使用 truncate/drop table 和 drop database 命令删除的数据,则没办法通过 Flashback 来恢复。
因为,即使配置了 binlog_format=row,执行 truncate/drop table 和 drop database 命令时,记录的 binlog 还是 statement 格式。 binlog 里面就只有一个 truncate/drop 语句,这些信息不能恢复出数据。
误删库 / 表
这种情况下,要想恢复数据,就需要使用全量备份,加增量日志的方式了。这个方案要求线上有定期的全量备份,并且实时备份 binlog。
在这两个条件都具备的情况下,假如有人中午 12 点误删了一个库,恢复数据的流程如下:
- 取最近一次全量备份,假设这个库是一天一备,上次备份是当天 0 点;
- 用备份恢复出一个临时库;
- 从日志备份里面,取出凌晨 0 点之后的日志;
- 把这些日志,除了误删除数据的语句外,全部应用到临时库。
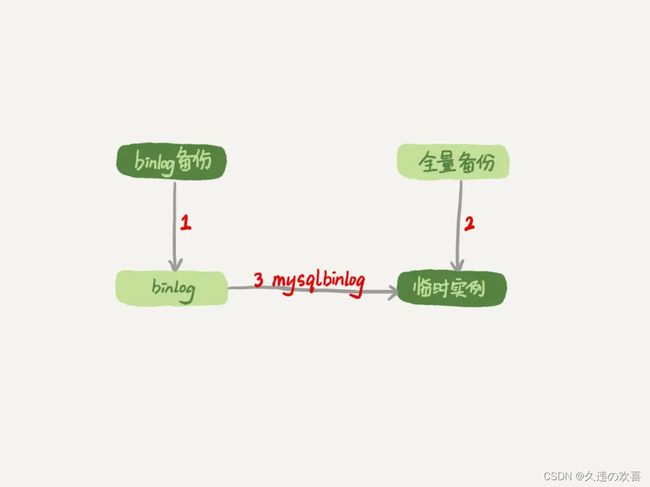
- 为了加速数据恢复,如果这个临时库上有多个数据库,可以在使用 mysqlbinlog 命令时,加上一个 –database 参数,用来指定误删表所在的库。
- 在应用日志的时候,需要跳过 12 点误操作的那个语句的 binlog:
如果原实例没有使用 GTID 模式,只能在应用到包含 12 点的 binlog 文件的时候,先用 –stop-position 参数执行到误操作之前的日志,然后再用 –start-position 从误操作之后的日志继续执行;
如果实例使用了 GTID 模式,假设误操作命令的 GTID 是 gtid1,那么只需要执行 set gtid_next=gtid1;begin;commit; 先把这个 GTID 加到临时实例的 GTID 集合,之后按顺序执行 binlog 的时候,就会自动跳过误操作的语句。
即使这样,使用 mysqlbinlog 方法恢复数据还是不够快,主要原因有两个:
- 如果是误删表,最好就是只恢复出这张表,也就是只重放这张表的操作,但是 mysqlbinlog 工具并不能指定只解析一个表的日志;
- 用 mysqlbinlog 解析出日志应用,应用日志的过程就只能是单线程。
一种加速的方法是,在用备份恢复出临时实例之后,将这个临时实例设置成线上备库的从库:
- 在 start slave 之前,先通过执行change replication filter replicate_do_table = (tbl_name) 命令,就可以让临时库只同步误操作的表;
- 使用并行复制技术,来加速整个数据恢复过程。
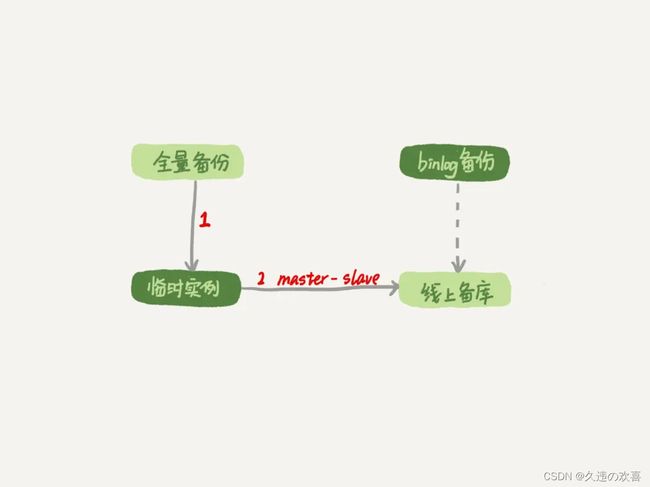
图中 binlog 备份系统到线上备库有一条虚线,是指如果由于时间太久,备库上已经删除了临时实例需要的 binlog 的话,可以从 binlog 备份系统中找到需要的 binlog,再放回备库中。
假设当前临时实例需要的 binlog 是从 master.000005 开始的,但是在备库上执行 show binlogs 显示的最小的 binlog 文件是 master.000007,意味着少了两个 binlog 文件。这时,就需要去 binlog 备份系统中找到这两个文件。把之前删掉的 binlog 放回备库的操作步骤如下:
- 从备份系统下载 master.000005 和 master.000006 这两个文件,放到备库的日志目录下;
- 打开日志目录下的 master.index 文件,在文件开头加入两行,内容分别是“./master.000005”和“./master.000006”;
- 重启备库,目的是要让备库重新识别这两个日志文件;
- 现在这个备库上就有了临时库需要的所有 binlog,建立主备关系,就可以正常同步了。
不论是把 mysqlbinlog 工具解析出的 binlog 文件应用到临时库,还是把临时库接到备库上,这两个方案的共同点是:误删库或者表后,恢复数据的思路主要就是通过备份,再加上应用 binlog 的方式。
延迟复制备库
通过利用并行复制可以加速恢复数据的过程,但是这个方案仍然存在“恢复时间不可控”的问题。
如果一个库的备份特别大,或者误操作的时间距离上一个全量备份的时间较长,比如一周一备的实例,在备份之后的第 6 天发生误操作,那就需要恢复 6 天的日志,这个恢复时间就是要按天来计算。
如果有非常核心的业务,不允许太长的恢复时间,可以考虑搭建延迟复制的备库(MySQL 5.6 版本引入)。
延迟复制的备库是一种特殊的备库,通过 CHANGE MASTER TO MASTER_DELAY = N 命令,可以指定这个备库持续保持跟主库有 N 秒的延迟。
比如把 N 设置为 3600,这就代表如果主库上有数据被误删,并且在 1 小时内发现了这个误操作命令,这个命令就还没有在这个延迟复制的备库执行。这时候到这个备库上执行 stop slave,再通过上面介绍的方法,跳过误操作命令,就可以恢复出需要的数据。
预防误删库 / 表的方法
- 第一条建议:账号分离。这样做的目的是,避免写错命令。 比如:
- 只给业务开发同学 DML 权限,而不给 truncate/drop 权限。而如果业务开发人员有 DDL 需求的话,也可以通过开发管理系统得到支持。
- 即使是 DBA 团队成员,日常也都规定只使用只读账号,必要的时候才使用有更新权限的账号。
- 第二条建议:制定操作规范。这样做的目的,是避免写错要删除的表名。 比如:
- 在删除数据表之前,必须先对表做改名操作。然后,观察一段时间,确保对业务无影响以后再删除这张表。
- 改表名的时候,要求给表名加固定的后缀(比如加 _to_be_deleted),然后删除表的动作必须通过管理系统执行。并且,管理系删除表的时候,只能删除固定后缀的表。
rm 删除数据
对于一个有高可用机制的 MySQL 集群来说,只要不是恶意地把整个集群删除,而只是删掉了其中某一个节点的数据的话,HA 系统就会开始工作,选出一个新的主库,从而保证整个集群的正常工作。最后,在这个节点上把数据恢复回来,再接入整个集群。
DBA 有自动化系统,SA(系统管理员)也有自动化系统,所以也许一个批量下线机器的操作,会让整个 MySQL 集群的所有节点都全军覆没。
应对这种情况,尽量把备份跨机房,或者最好是跨城市保存。