C++ - 可变模版参数 - emplace相关接口函数 - 移动构造函数 和 移动赋值运算符重载 的 默认成员函数
可变模版参数
我们先来了解一下,可变参数。可变参数就是在定义函数的时候,某一个参数位置使用 "..." 的方式来写的,在库当中有一个经典的函数系列就是用的 可变参数:printf()系列就是用的可变参数:

如上图所示,printf()函数的第二个参数就是 可变参数(注意:可变参数 "..." 语法上在之前必须要有一个参数)。那么 第二个参数位置,就可以写很多个参数,在printf()函数内部就可以把第二参数位置的这些多个参数 解析出来。底层其实是用一个数组,把可变参数位置传入的实参接收的,printf()内部就会去访问这个数组,把这些参数取出来。
在 C++ 当中就需要有 可变的模版参数了。
我们说模版参数和 函数参数其实是很类似的:
- 模版参数 是 传递类似;
- 函数参数 是 传递对象;
那么 可变的模版参数其实就是传入多个类型,想要几个类型, 就传入几个类型。
可变模版参数的语法
// Args是一个模板参数包,args是一个函数形参参数包
// 声明一个参数包Args...args,这个参数包中可以包含0到任意个模板参数。
template
void ShowList(Args... args)
{} 在可变函数参数之后,要加上 Args ,这个 Args 其实是一个 模版参数包,而 在函数当中 args 是一个函数形参参数包,两者是不一样的,要注意区分。
当然,Args 这个名字可以自定义,想取什么名字都是可以的,但是我们一般命名为 Args。其实 Args 就是 这个可变参数的 模版参数名称,跟之前取 T, K 都是一样的。

如上图所示,在函数当中的 args 函数形参参数包,是用 Args 模版参数包构建出来的,如果 Args 当中只有一个类型,那么 args 当中就只会构建出一个形参,类比,如果 Args 当中只有两个类型,那么 args 当中就只会构建出两个形参。
可变参数包在函数当中的使用
那么,我们知道了 如果定义一个 可变模版参数,和 在函数参数列表当中传入 这个 可变模版参数,那么这个可变模版参数在函数当中如果使用呢?
template
void ShowList(T value, Args... args)
{
}
int main()
{
ShowList(1);
ShowList(1, 'A');
ShowList(1, 'A', std::string("sort"));
return 0;
} 如上面这个例子,在 ShowList()这个函数模拟,到底会实例化出多少个 函数出来,我们可以在函数内部使用 sizeof()对 args 函数形参参数包 进行 大小的打印,就可以知道,当前实例化出来的 函数,有多少个参数了:
void ShowList(T value, Args... args)
{
cout << sizeof(args) << endl;
}但是,直接像上述一样计算 args 的大小是不行的,编译器不给这样玩,我们需要在 sizeof和 (之前加上 "..." 才行;
上述编译报错:
“args”: 必须在此上下文中扩展参数包得像下面一样写:
void ShowList(T value, Args... args)
{
cout << sizeof...(args) << endl;
}输出:
0
1
2
那么,有人就像了,既然args 实现跟数组类似,那么我们可不可以直接取出 args 当中的数据呢?
答案是不行的,它不给直接取出args 的数据,必须要扩展上下文(具体在后面阐述):
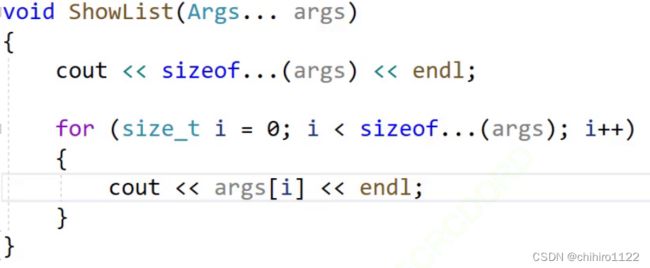
编译报错:
“args”: 必须在此上下文中扩展参数包利用模版参数的推演,取出 参数包当中的值
对于 扩展参数包,除了可以像上述一样 在前置加 "..." 的方式,扩展 参数包;
我们还可以利用编译器对模版参数的推演,来取出参数包当中的类型。
具体做法就是在 可变模版参数之前,多加一个 模版参数,利用编译器对这个模版参数的推演,扩展出 args 当中的类型:
// 递归终止函数
template
void ShowList(const T& t)
{
// 编译时递归推导的
// 结束时候的函数
cout << t << endl;
}
// 展开函数
template
void ShowList(T value, Args... args)
{
cout << value << " ";
ShowList(args...);
}
int main()
{
ShowList(1);
ShowList(1, 'A');
ShowList(1, 'A', std::string("sort"));
return 0;
} 如果之传入的一个参数,那么直接调用 第一个 ShowList(const T& val);如果传入的是多个参数,那么就会调用 void ShowList(T value, Args... args) 这个函数,在这个函数当中,就会把第一个参数 推导出来,打印,然后又去调用 void ShowList(T value, Args... args) 这个函数,但是在传入参数的时候值传入 参数包,相当于是把 第一个参数舍弃了,然后传参,这样再下一层函数,就会从参数包当中取出第一个数据。
直到,参数包当中数据区得只剩下 一个,那么就会调用 第一个 结合条件的函数。相当于是 利用 第一个模版参数 一直推导出 args 当中的类型。
但是,可变模版参数很少用到,上诉过程可以制作理解。
但是上述取出 args 的方法只能取出有参数的 例子,如果是无参传入的话,就会不匹配了,所以我们对结束函数进行改进,把结束函数改为 无参的 函数:
void ShowList()
{
cout << endl;
}还有一种新的方式:
template
void PrintArg(T t)
{
cout << t << " ";
}
//展开函数
template
void ShowList(Args... args)
{
int arr[] = { (PrintArg(args), 0)... };
cout << endl;
}
int main()
{
ShowList(1);
ShowList(1, 'A');
ShowList(1, 'A', std::string("sort"));
return 0;
} 这种展开参数包的方式,不需要通过递归终止函数,是直接在expand函数体中展开的, printarg不是一个递归终止函数,只是一个处理参数包中每一个参数的函数。这种就地展开参数包的方式实现的关键是逗号表达式。我们知道逗号表达式会按顺序执行逗号前面的表达式。
expand函数中的逗号表达式:(printarg(args), 0),也是按照这个执行顺序,先执行printarg(args),再得到逗号表达式的结果0。同时还用到了C++11的另外一个特性——初始化列表,通过初始化列表来初始化一个变长数组, {(printarg(args), 0)...}将会展开成((printarg(arg1),0),(printarg(arg2),0), (printarg(arg3),0), etc... ),最终会创建一个元素值都为0的数组int arr[sizeof...(Args)]。
由于是逗号表达式,在创建数组的过程中会先执行逗号表达式前面的部分printarg(args)打印出参数,也就是说在构造int数组的过程中就将参数包展开了,这个数组的目的纯粹是为了在数组构造的过程展开参数包。
如果不想用 逗号表达式的话,可以利用 printarg()函数的返回值,返回一个 0:
template
int PrintArg(T t)
{
cout << t << " ";
return 0;
}
//展开函数
template
void ShowList(Args... args)
{
int arr[] = { PrintArg(args)... };
cout << endl;
} empalce相关接口函数
我们先来看一个 可变模版参数的引用场景:
class Date
{
public:
Date(int year = 1, int month = 1, int day = 1)
:_year(year)
, _month(month)
, _day(day)
{
cout << "Date构造" << endl;
}
Date(const Date& d)
:_year(d._year)
, _month(d._month)
, _day(d._day)
{
cout << "Date拷贝构造" << endl;
}
private:
int _year;
int _month;
int _day;
};
template
Date* Create(Args... args)
{
Date* ret = new Date(args...);
return ret;
}
int main()
{
Date* p1 = Create();
Date* p2 = Create(2023);
Date* p3 = Create(2023, 9);
Date* p4 = Create(2023, 9, 27);
Date d(2023, 1, 1);
Date* p5 = Create(d);
return 0;
} 当 Data 当中的构造函数是这样写的时候:
Date(int year , int month , int day ) -> 外部函数当中传入三个参数:Date* p4 = Create(2023, 9, 27);
也就是,传入三个参数,那么 在 Create 当中的 参数包就会接受这三个参数,然后传入到 Data 构造函数当中;
如果传入的不是 三个参数( Date* p1 = Create(); Date* p2 = Create(2023); Date* p3 = Create(2023, 9);),就会报错。
但是,在上述例子当中吗,我们是吧 data 的构造函数当中的三个 参数都些都写成是 缺省的,所以在上述例子的当中才可以那么自由的使用 Create ()函数。
STL容器当中,还有 empalce相关接口函数:
cplusplus.com/reference/vector/vector/emplace_back/
cplusplus.com/reference/list/list/emplace_back/
template
void emplace_back (Args&&... args); 首先我们看到的emplace系列的接口,支持模版的可变参数,并且,函数当中的形参是万能引用,那么 emplace_back()接口相对于 insert()有那些提升呢?
int main()
{
std::list< std::pair > mylist;
// emplace_back支持可变参数,拿到构建pair对象的参数后自己去创建对象
// 那么在这里我们可以看到除了用法上,和push_back没什么太大的区别
mylist.emplace_back(10, 'a');
mylist.emplace_back(20, 'b');
mylist.emplace_back(make_pair(30, 'c'));
mylist.push_back(make_pair(40, 'd'));
mylist.push_back({ 50, 'e' });
for (auto e : mylist)
cout << e.first << ":" << e.second << endl;
return 0;
} push_back ()函数,需要传入一个 make_pair ()构造一个 pair 对象传入,才能进行尾插;但是 在 emplace_back()接口,就直接传入参数,它会被 参数包接受,然后在 解析出来。但是,上述除了 在用法上不同,实际上和 push_back()是差不多的。
int main()
{
// 下面我们试一下带有拷贝构造和移动构造的bit::string,再试试呢
// 我们会发现其实差别也不到,emplace_back是直接构造了,push_back
// 是先构造,再移动构造,其实也还好。
std::list< std::pair > mylist;
mylist.emplace_back(10, "sort");
mylist.emplace_back(make_pair(20, "sort"));
mylist.push_back(make_pair(30, "sort"));
mylist.push_back({ 40, "sort" });
return 0;
} 也就是说, emplace_back()能做到,直接引用参数来对其中的结点进行构造;但是 push_back()必须先进行构造,然后在进行拷贝构造。
按照上述来看,emplace_back()还是有优化的,但是别忘了 ,C++11 之后是可以使用 移动拷贝的,想上述 push_back()先构造,在进行拷贝构造,就会被直接优化为 空间的 两个指针的交换,这个代价就太低了,相对来说,emplace_back()就不够看了。

移动构造函数 和 移动赋值运算符重载 的 默认成员函数
在C++ 11之前,有 6 大默认成员函数:
- 构造函数
- 析构函数
- 拷贝构造函数
- 拷贝赋值重载
- 取地址重载
- const 取地址重载
C++11 增加有值引用之后,就有了移动语义的概念,所谓移动语义就是 移动构造函数 和 移动赋值运算符重载函数,两函数。
那么所以默认成员函数的话,我们写了,那好说,就使用我们定义的 函数;如果我们没有写,那么编译器就会自动生成一个,这个自动生成是什么条件下的才会自动生成的?
- 如果你没有自己实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个。那么编译器会自动生成一个默认移动构造。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调用移动构造,没有实现就调用拷贝构造。
- 如果你没有自己实现移动赋值重载函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自动生成一个默认移动赋值。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动赋值,如果实现了就调用移动赋值,没有实现就调用拷贝赋值。(默认移动赋值跟上面移动构造完全类似)
- 如果你提供了移动构造或者移动赋值,编译器不会自动提供拷贝构造和拷贝赋值。
这里和 之前默认成员函数一样,对于浅拷贝(也就是只拷贝内置类型),那么我们可以放心大胆的交给编译器去自动生成,就够用了;如果是深拷贝(比如自己开得有 堆空间),那么就需要我们自己定义 移动构造函数 和 移动赋值运算符重载函数。
如果我们都实现析构函数 、拷贝构造、拷贝赋值重载 但是我们又想编译器自己生成一个 移动构造函数 或者是 移动赋值重载函数 的话,我们可以这样写:
string(Person&& p) = default;上述只给出了 移动构造函数 的方式,移动赋值重载函数 的方式也是类似的。
这样可以让编译器前置生成一个 移动构造函数 或者是 移动赋值重载函数