C++入门第一课——命名空间、输入输出、缺省参数
目录
1、命名空间
1.1 命名空间的定义
1.2 命名空间的使用
1.3 命名空间定义的补充
2、输入与输出
3、缺省参数
3.1 全缺省参数
3.2 半缺省参数
3.3 缺省参数的补充
1、命名空间
学了C之后,在进行C编程时,开始,代码量不够多时,几行几句代码,很少遇到命名的函数名或者变量的名不会和C自带的库函数名有冲突,当时代码连足够多或无意中时,不免有重定义的情况。
#include
#include
int rand = 10;
int main()
{
printf("%d\n", rand);
return 0;
} 
为什么会重定义呢?原因是
1.1 命名空间的定义
定义命名空间,需要用到namespace关键字,在其之后要跟上命名空间的名字(随便取),然后再接一对大括号({}),大括号中可以定义命名空间的成员。
namespace test// 在全局域定义一个命名空间
{
// 在命名空间中可以定义变量、类型、函数...
int x = 3;
struct Student
{
//.......
};
void func()
{
//........
}
}
// 不会与命名空间的成员发生冲突
int x = 6;
struct Student
{
};
int main()
{
return 0;
}命名空间它不会修改其成员的生命周期,例如上面的代码当中,命名空间中的变量x、类型Student、函数func,他们的生命周期都是跟随程序的。命名空间就好像一道警戒线,将其中的成员保护起来 ,也就是说即使在同一作用域下定义与命名空间中相同名字的变量(或类型或函数),也不会造成冲突。那么命名空间的作用就是提供一个新的限定域,这个限定域与作用域有所区别,作用域指的是在当前域下的成员只能工作在本域范围内,而限定域不会修改成员的生命周期,只是防止在同一作用域下,相同名字的成员引发的命名冲突。(例如上面的代码在全局域中定义了多个相同名字的成员,但因为有命名空间的保护,不会造成命名冲突)。
1.2 命名空间的使用
使用命名空间中的成员,有三种方式:
一、 在使用某个成员时,在其之前加上[命名空间名::成员名]。其中" :: "为作用域限定符。
#include
namespace test// 在全局域定义一个命名空间
{
// 在命名空间中可以定义变量、类型、函数...
int x = 3;
struct Student
{
};
void func()
{
printf("test::func()\n");
}
}
// 不会与命名空间的成员发生冲突
int x = 6;
struct Student
{
};
void func()
{
printf("func()\n");
}
int main()
{
int x = 9;
printf("%d\n", x);//使用x时,编译器从当前开始往上查找x
printf("%d\n", ::x);//"::"指定在全局域中找x
printf("%d\n", test::x);//使用命名空间中的x
struct Student s1;// 使用全局域的Student类型定义变量
struct test::Student s2;// 使用全局域的test命名空间中的Student类型定义变量
func();// 调用全局域的func函数
test::func();// 调用全局域中test命名空间中的func函数
return 0;
}
二、使用[using namespace 命名空间名]将命名空间中的所有成员"释放"。
#include
namespace test
{
void func()
{
printf("test::func()\n");
}
}
using namespace test;// 将命名空间中的成员"释放"
int main()
{
func();// 直接使用命名空间中的成员
return 0;
} 三、使用[using 命名空间名::成员名]将命名空间中的某一成员"释放"。
#include
namespace test
{
int x = 3;
void func()
{
printf("test::func()\n");
}
}
using test::x;// 将命名空间中的x"释放"
int main()
{
printf("%d\n", x);
test::func();// 未释放的成员必须用"::"访问
return 0;
} 1.3 命名空间定义的补充
命名空间只能在全局域中定义,但可以定义任意次:
namespace test
{
int x = 3;
}
namespace test
{
int y = 5;
}
namespace test
{
int z = 9;
}
int main()
{
//namespace temp// 错误,局部域不允许定义
//{
// int a = 8;
//}
return 0;
}这些多次"重复定义"的命名空间,会在编译阶段自动合并。那么C++将其标准库里面的东西全部封在了一个名为 std 的命名空间当中,当我们把多个头文件引入源文件时,编译器在预处理阶段将这些头文件展开,然后在编译阶段合并这些名为 std 命名空间。
命名空间可以嵌套定义,即使嵌套定义相同名称的命名空间也不会触发语法错误(不过正常人应该不会这么干):
#include
namespace test
{
int x = 3;
namespace temp
{
int x = 6;
}
namespace test
{
int x = 4;
}
}
int main()
{
printf("%d\n", test::x);
printf("%d\n", test::temp::x);
printf("%d\n", test::test::x);
return 0;
} 命名空间在工程当中是常用的模块化编程手段,通常发生在项目组协作完成项目时,组与组之间互相不知道定义了什么变量、函数、类型,而使用命名空间,能够有效解决命名冲突的问题,进而提升工作效率。
2、输入与输出
有了命名空间的铺垫,才能"严格意义"上写出第一个C++程序:
#include
using namespace std;
int main()
{
cout << "hello C++" << endl;
return 0;
} 这段程序编译运行之后,能够在控制台上输出 " hello C++ " 字符串(Windows下使用Visual Studio 2022)。其中,cout我们称为标准输出对象,它是一个对象(C++是一门面向对象编程的语言),"<<"运算符我们称为流插入运算符。其中cout中的"c"代表英文console(翻译为控制台),cout 可以理解为控制台输出。我们每想要输出一个对象(可以是变量、字符串等等)到控制台上,在对象之前都必须使用"<<"运算符,也就是说,每一个想要输出到控制台上的对象,都必须匹配一个流插入运算符。endl表换行(end line,结束当前行)。
我们做一个小修改:
#include // 我们的第一个C++标准库
using namespace std;
int main()
{
char buffer[64] = { 0 };
cin >> buffer;
cout << buffer << endl;
return 0;
} 这段程序如同C语言使用 scanf 函数从控制台获取一个字符串到buffer中去(遇到空格为截止),然后再将 buffer 里的数据输出到控制台。cin 我们称为标准输入对象,其中">>"运算符我们称为流提取运算符,也就是说,每一个想要从控制台获取某些数据的对象都必须匹配一个流提取运算符。
我们需要注意,虽然上面的"<<"和">>"在C++中被赋予了新的定义,但它不与重载了"<<"或">>"运算符的对象(先别管这里,大概懂我意思就行)一起使用时,它就保留了原来的功能:
#include
using namespace std;
int main()
{
int x = 3;
x = x << 1;//这里还是位移运算符
cout << x << endl;//这里便是流插入运算符
return 0;
} 我们应该注意一个非常有趣的现象,cout 和 cin 貌似并不需要我们指定任何对象的类型,它似乎天然地知道我们的对象类型(自动识别类型),不再需要像C语言当中需要指定%d、%c、%f等等格式。这里我无法做出解释,但是请你不要放弃,请继续往后看,相信你一定会有答案。当然,C++提供的输入输出是可以支持浮点数的精度控制、格式控制的,但我并不建议大家使用(有这闲工夫干嘛不直接printf?)。
相信读者一定注意到了C++的头文件没有".h"后缀,但是C++并不是天然这样设计的。其实在早期的C++中,头文件也是需要添加".h"后缀的,不过这就绕到了我们本篇开头的话题——命名冲突,因为C++早期的设计初衷就是弥补C语言的缺陷与不足,所以当C++标准委员会发现了这个问题之后,就开始升级C++了, 由此命名空间就诞生了,为了新旧版本的头文件区分,索性直接将头文件需要".h"后缀的写法给去掉了。不过在一些较为"上古"的编译器中(例如VC6.0),C++的头文件是可以添加".h"后缀的,当然,现在的编译器都不支持这种写法了(即使支持也不建议用)。
3、缺省参数
缺省参数是用在函数声明或定义时为函数的参数指定一个缺省值,缺省值也叫默认值。当调用了指定缺省值的函数时,且调用时没有实参,那么函数的参数的值将使用缺省值;而如果调用了指定缺省值的函数时,但调用时指定了实参,那么函数的参数将使用实参。
#include
using namespace std;
void func(int x = 3)
{
cout << x << endl;
}
int main()
{
func();// 没有指定实参,func函数的x参数使用它的缺省值
func(5);// 指定了实参,func函数的x参数使用这个实参
return 0;
} 
3.1 全缺省参数
顾名思义,全缺省参数指的是函数的每个参数都有一个缺省值。假设有一参数为三个的函数,它的每个参数都有缺省值,那么在调用它时,可以选择传递0个实参、1个实参、2个实参、3个实参。
#include
using namespace std;
void func(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << " ";
cout << "b = " << b << " ";
cout << "c = " << c << endl;
}
int main()
{
func();
func(100);
func(100, 200);
func(100, 200, 300);
return 0;
} 
需要注意的是,函数调用的实参和函数的参数的位置是一一对应的。也就是说实参传递给函数的参数时一定是从左往右传递的,中间不可跳过。举一个很简单的例子,我们想要函数参数a和c使用实参,而参数b使用缺省值,很抱歉,这是不可能的。以下图来体会实参和函数的参数的对应关系:
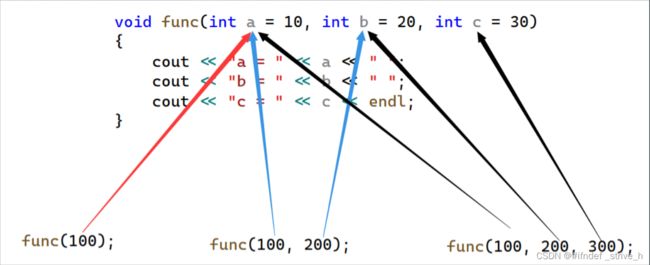
3.2 半缺省参数
半缺省参数指的是函数的形参至少有一个参数没有缺省值,并且没有缺省值的参数必须是在有缺省值参数的左边。
// 没有缺省值的参数在有缺省值参数的左边
void func1(int a, int b = 20, int c = 30)// 正确半缺省
{
cout << "a = " << a << " ";
cout << "b = " << b << " ";
cout << "c = " << c << endl;
}
// 没有缺省值参数在有缺省值参数的右边
void func2(int a = 10, int b, int c = 30)// 错误半缺省
{
cout << "a = " << a << " ";
cout << "b = " << b << " ";
cout << "c = " << c << endl;
}
// 没有缺省值参数在有缺省值参数的右边
void func3(int a = 10, int b = 20, int c)// 错误半缺省
{
cout << "a = " << a << " ";
cout << "b = " << b << " ";
cout << "c = " << c << endl;
}3.3 缺省参数的补充
非常值得注意的一点是,在函数的声明和定义中,缺省参数不能同时出现。因为一旦同时出现,编译器就会陷入"纠结",引发报错。在函数既有声明又有定义的场景中,C++规定,只能在函数声明中给定缺省参数。
#include
using namespace std;
void func(int x = 6);// 只能在声明中给定缺省参数
int main()
{
func();
return 0;
}
void func(int x)
{
cout << x << endl;
} 还需要注意,缺省值必须是常量或全局变量。
那么,缺省参数到底有何意义?我们以一个简单的例子想必就能明白:
struct Stack
{
int* a;
int size;
int capacity;
};
// 如果我们确实不清楚要把多少个数据存入栈中
// 初始化时就以4开始,后面慢慢扩容
void capacity_init(struct Stack* st,int cap = 4)
{
//...做一些扩容的工作
st->capacity = cap;
// ...
}
int main()
{
struct Stack st;
capacity_init(&st);// 不确定存多少个数据,使用缺省值然后扩容
capacity_init(&st, 100);// 如果我们已经确定要存100个数据,就不需要再扩容增加消耗了
return 0;
}