阿里数据技术专家的数据平台实战笔记

简介:2020 年注定是不同寻常的,突如其来的疫情按下了人们生活的暂停键。对于用户激增的 App 而言有喜有忧,如何快速沉淀数据资产,因为疫情是脉冲式的需求,等疫情结束之后,如何把这些激增的用户转化为留存是很大的挑战。对于非利好的 App,如何让数据成为护城河。回答这两个问题,数据智能平台的建设尤其重要。
背景
从友盟+公开的移动互联网数据报告来看,疫情期间移动互联网设备活跃度稳步提升。其中游戏行业增幅 15%,是 2019 年的 2 倍;影视增幅 8%,是去年的 3 倍左右;办公通讯上涨明显,增幅 150%,网上药店活跃设备增幅由负转正,增幅 61%;旅游与汽车的降幅是去年的 3-4 倍,分别下跌 55%及 29%。
疫情后的机会点:
1.拉新变留存。对于用户激增的 App 而言有喜有忧,因为疫情是一个脉冲式的需求,等疫情结束之后,如何把这些激增的用户转化为留存是一个很大的挑战。实时化的数据资产的沉淀成为挑战。这时候需要修炼好数据的内功,重视数据资产的沉淀,运营好自己的私域数据池。
2.智能化运营。有的数据的底料,我们可以更加的进行精细化的一些运营。比如分层运营,智能营销,实现业务的数据化,并且让数据指导业务的发展提供前提。
3.练好数据的内功。建设数据智能平台。数据也是资产,数据智能平台的建设,好比把矿石炼成 98 号的汽油,再通过清洁的能源向业务不断赋能的过程。
什么是数据智能平台
数据智能研发平台,是基于数据基础能力,打造专业、高效、安全的一站式智能研发平台。支持实时与离线数据集成、开发运维、工作流调度、数据质量、数据安全的全链路数据管理,满足数据治理、数据血缘、数据质量、安全管控,标签应用的需求。
面临的挑战
挑战主要集中在 4 个方面,从算力、数据、算法以及业务:
基础设施的建设不是一触而就的,需要大量的人力物力财力。主要是机房、机架、网络、带宽。
数据分成两个部分,基础数据以及标签的数据,那么基础数据存在的问题是缺乏统一的建设标准以及质量的评估。我们知道欧盟有很多的成员国,成员国之前是各自发行货币的,不利于整体经济的发展。数据也是一样,需要同样的标准去建设,促进数据的一个流通,这是基础数据存在的问题。对于标签数据而言,我们的生产管理服务应用整个链路是断裂的,无法最大的提高一个标签生产的效率。
算法工程上,烟囱式的垂直类的一个开发,比如说广告和搜索,它在特征到工程上面都是重复开发的。
业务上,数据的建设周期比较长,赶不上业务的一个发展。
体系介绍
底料篇
以友盟+为例。经过了 9 年专业的大数据的服务,积累下了 PC 网站的 APP 的数据以及广告监测类的数据。面临的一个问题,如何把大体量的数据稳定高质量的同步到计算平台,自研的一键的数据同步的工具,打通业务系统到大数据之间的元数据平台,同时业务系统的增删改也会通知到大数据测。
建设篇:

公共数据中心的建设,核心是为了解决指标一致性的问题。
按业务域和分析维度构建公共数据中心。什么叫业务板块?比如亚马逊,它是有电商和云两块业务的,那么这两块业务其实就是业务板块,我们一个抽取电商业务来看,有日志、交易、物流、广告等最基础的一些数据组成,这就叫做数据域。数据域是业务过程的集合,以交易为例,分付款,退拍下和退款,这三个业务过程共用的一个订单 ID,所以在一张事实表里。交易的过程有维度刻画,有商品、买家、卖家这些维度构成了维表,比如买家的昵称、注册的时间。维表冗余在实时表中的好处是减少大数据量的 join,保证数据的稳定高效的产出。通过建设可以让由矿石变成 92 号的汽油,这个时候数据就可以被使用了,这是基础数据建设的部分。
所有的运营产品、市场等业务的同学使用的数据全部叫做指标,这些指标全部是派生指标。跟大家一起拆解一个指标,叫最近 30 天会员在无线端的登录次数,那么最近 30 天就是时间周期,会员是统计粒度,统计粒度对应的最左边的维度信息。无线端就是业务限定,登录的次数就是原子指标。登录次数加业务限定就等于上面图表中最左边的业务过程。那这个指标拆解的过程怎么去映射到我们的技术数据,怎么关联呢?
再举两个例子。很多人可能简单自学 SQL 后,就可以自己跑数据:通常情况下,SQL 质量无法保证,如果查询的数据量非常大,可能后台几千台机器就转起来了。为避免类似情况发生,我们会在提交任务过程中做代码校验,对于性能问题、规范问题、代码质量问题都会给出必要的提示,比如 SQL 代码对于除数为 0 没有做代码兼容,比如我们的 DDL 语句中没有做数据生命周期的设置,比如 SQL 的 QUERY 中没有做分区的条件限制,甚至你的 SQL 代码别人已经计算过,可以复用结果不需要重新计算这些问题,我们都会给出精确到提示。
在数据研发过程中,代码编写可能只占工作量的 20%,那么大部分时间都去干吗了?是数据验证,代码修改前和代码修改后,数据到底差多少,差在哪儿?过去如果没有工具只能写一堆脚本,再去验证,效率极其低下,而且极易出错。现在有了“数据对比”工具,就可以通过简单的勾勾选选知道前后差异到底在哪?然后迅速给测试报告,保证整个研发过程的数据质量是有保障的。有了工具的建设,最后是运维。核心是要用最优的资源保障最重要的数据及时的产出。
标准化篇

以 IP to 地域为例,有阅读类的 App 做本地的资讯,这个服务在市场上面是很普遍的,但准确度只能做到 65%;再以游戏 App 为例,比如说品牌 /机型代表购买力,屏幕 /内存容量供开发者优化迭代产品。这些参数要是开发者去采集的话,会遇到特别多的问题,比如手机机型是 0011X,0011X 代表 iPhone11,那么集合于这两类的需求,这个时候就需要运用全域数据的能力,在高维的空间精准识别匹配信息。
反作弊篇

整个过程的反作弊怎么做?比如有一款视频类的 App 在做用户分层,一共 5 层,大多数精细化运营同学都会这么去做。第 1 层是超级用户,第 2 层是黑产设备。作弊数据对标签也是一种噪声,对于简单的机刷,用规则就可以识别出来。比如 IP 的黑名单库,设备的黑名单库。但是随着这些技术的日新月异,对于模拟器而言,要采用机器学习的方式,从行为数据中加以判断。还有种是“群控”,也就是羊毛党。第 3 层--第 5 层分别是高质量、中质量和低质量。
规则,IP 的黑名单库,设备的黑名单库。对于模拟器,采用机器学习的方式,从行为数据中加以判断,对于群控羊毛党采用图算法。多管齐下,滤掉 86%的一个假量。
打通篇

与此同时,互联网和传统行业一样都会存在着数据的孤岛,因为我们现在客户的触点是非常多的,比如说有传统的 PC 网站,有 App,有小程序。在跨端上面,比如两个小程序,A 上用户少,成交率高;B 上用户多,成交率低,要进行跨端的数据的运营。有 PC 和无线数据,PC 上面点了一个商品,App 上把相应商品或者相应的文章来推荐给用户,这样来看用户的留存将会得到极大的一个提升。设备聚合的主要场景是看小程序和 App 一共有多少用户。
标签篇

标签是通过行为分析认知用户的一个过程。是数据分析的一个起点,比如最近 30 天来过北京 2 次的人群,只要有业务价值,它就是一个标签。标签的分类,分有统计性和预测性,区别在统计型标签不需要样本集和准确度。那标签有什么作用呢?
一、市场细分和用户分群:市场营销领域的重要环节。比如在新品发布时,定位目标用户,切分市场。这是营销研究公司会经常用的方式。
二、数据化运营和用户分析。后台 PVUV 留存等数据,如果能够结合用户画像一起分析就会清晰很多,揭示数据趋势背后的秘密。
三、精准营销和定向投放。比如某产品新款上市,目标受众是白领女性,在广告投放前,就需要找到符合这一条件的用户,进行定向广告投放。 四、各种数据应用:例如推荐系统、预测系统。我们认为:未来所有应用一定是个性化的,所有服务都是千人千面的。而个性化的服务,都需要基于对用户的理解,前提就需要获得用户画像。
常用的一些标签体系(以下均为大数据预测结果): 第一类:人口属性。比如说性别、年龄、常驻地、籍贯,甚至是身高、血型,这些东西叫做人口属性。
第二类:社会属性。因为我们每个人在社会里都不是一个单独的个体,一定有关联关系的,如婚恋状态、受教育程度、资产情况、收入情况、职业,我们把这些叫做社会属性。
第三类,兴趣偏好。摄影、运动、吃货、爱美、服饰、旅游、教育等,这部分是最常见的,也是最庞大的,难以一一列举完。
第四类,意识认知。消费心理、消费动机、价值观、生活态度、个性等,是内在的和最难获取的。举个例子,消费心理 /动机。用户购物是为了炫耀,还是追求品质,还是为了安全感,这些都是不一样的。 如何判断标签体系的好坏?
在实际构建标签体系时,大家经常会遇到很多困惑,我列举 5 个常见问题:
第一、怎样的标签体系才是正确的?其实每种体系各有千秋,要结合实际应用去评估。
第二、标签体系需要很丰富么?标签是枚举不完的,可以横线延展、向下细分。也可以交叉分析,多维分析。如果没有自动化的方式去挖掘,是很难做分析的,太多的标签反而会带来使用上的障碍。
第三、标签体系需要保持稳定么?不是完全必要,标签体系就是产品 /应用的一部分,要适应产品的发展,与时俱进。比如, “新冠”这个词,今天却很热。我们是不是要增加一个标签,分析哪些人有购买新冠相关的防疫药品。有一种情况下,标签要保持稳定。如果你生产的标签有下游模型训练的依赖,即我们模型建完后,它的输入是要保持稳定的,不能今天是 ABC,明天是 BCD。在这种情况下,是不能轻易对标签体系做更改的。
第四个,树状结构 or 网状结构?树状结构和网状结构从名字上就可以看出其分别。网状结构,更符合现实,但是层次关系很复杂,对数据的管理和存储都有更高要求。知乎,如果仔细去看它的话题设置,其实是网状的。
网状的特点就是一个子话题,父级可以不止一个,可能有两个。比如儿童玩具,既可以是母婴下分分类,也可以是玩具下的分类,它就会存在两个父节点之下。树状结构相对简单,也是我们最常用的。网状结构在一些特定场景下,我们也会去用。但是实现和维护的成本都比较高。比如,有一个节点是第四级的,但它的两个父节点一个是二级,一个是三级,结构异化带来处理上的麻烦。
第五个,何为一个好的标签体系?应用为王,不忘初心。标签是为了用的,并不是为了好玩,最好保证标签体系的灵活和细致性。
智能篇:
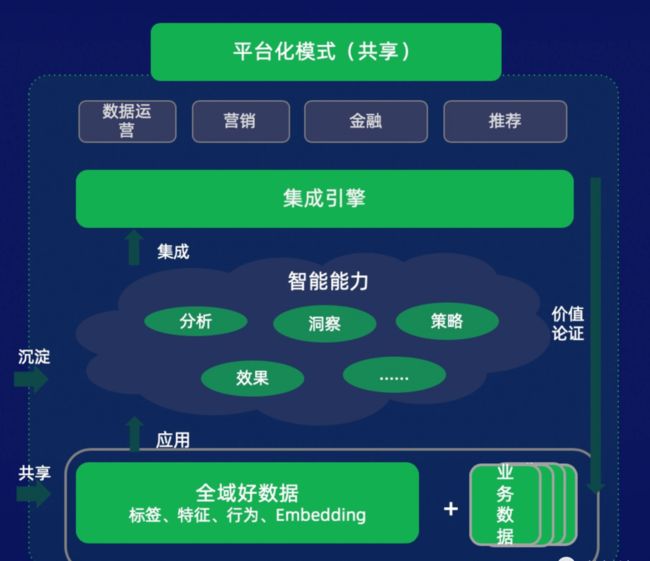
数据智能的建设指分析、洞察、策略、效果的工程化能力,有了这些智能的工程化能力,就能通过引擎向外暴露接口的方式来支持百花齐放的业务,支持所有开发者的业务,这就是友盟+采建管用一站式服务平台的整个建设过程,开发者可以借此为例,快速自建、或依靠友盟+的技术能力,丰富自己的数据智能平台 /数据银行的建设。
规划和感想
第一,快速建模的能力。实时自动的标签产出,或者结合业务场景的实时化,能最大保障智能化运营的及时性;
第二,不能只说这个用户对汽车感兴趣,而是需要细分到车型、价位,甚至他去买车时,会关注驾驶乘坐的舒适性、操控的灵活性,还是内饰的细节。
作者:友盟+数据技术专家 谭纯
推荐阅读:
程序员简历中的自己,牛逼了
世界的真实格局分析,地球人类社会底层运行原理
千万QPS毫秒响应:快手数据中台建设实践
阿里彻底去中台了,你真以为中台不行了?
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)
小米用户画像实战,48页PPT下载
网易大数据用户画像实践