Python爬虫爬取某会计师协会网站的指定文章(文末送书)

♂️ 个人主页:@艾派森的个人主页
✍作者简介:Python学习者
希望大家多多支持,我们一起进步!
如果文章对你有帮助的话,
欢迎评论 点赞 收藏 加关注+
目录
一、Python编写爬虫的优势
二、Python爬虫爬取会计师协会网站的指定文章
三、文末推荐与福利
一、Python编写爬虫的优势
- 易学易用:Python的语法简单明了,易于理解和学习,使得编写爬虫变得简单容易。
- 强大的第三方库:Python有很多强大的第三方库,如requests、BeautifulSoup、Scrapy、Selenium等,可以帮助我们轻松实现网页的请求、解析和数据的提取等功能。
- 跨平台性:Python可运行于Windows、Linux、macOS等多个操作系统上,使得在多个平台上编写和运行爬虫变得简单容易。
- 处理文本信息方便:Python对文本处理非常方便,支持多种文本编码,可以轻松实现数据的清洗和去重。
- 丰富的数据处理和分析工具:Python拥有众多的数据处理和分析工具,如NumPy、Pandas、Matplotlib等,可以对爬取的数据进行深入的分析和处理。
- 自动化:Python可以轻松实现自动化,可以自动执行爬取任务,定时发送邮件等,大大提高工作效率。
- 反爬虫机制容易应对:Python可以通过设置User-Agent、Cookie等方式来模拟浏览器行为,避免被目标网站的反爬虫机制识别和封锁。
二、Python爬虫爬取会计师协会网站的指定文章
由于业务原因,需要经常关注`“北京注册会计师协会”`网站`“最新公告”`栏目里的`“北京注册会计师协会专业技术委员会专家提示”`相关文章。不想每次进网站一个一个地点击,然后复制到word文件。如果能一次批量爬取,并存到word文件就好啦。
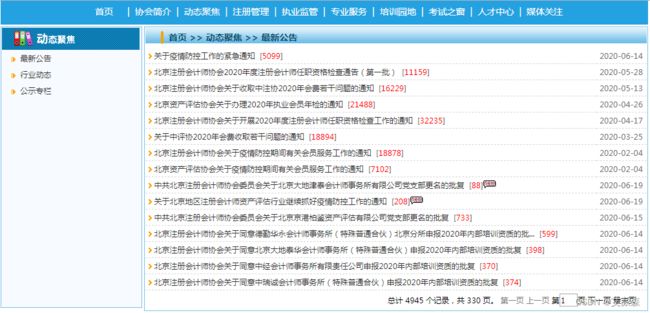
此处用到两个库,`“requests”`和`“beautifulsoup”`。`“requests”`用于发送HTTP请求,并获取网页的内容。`“beautifulsoup”`用于解析获取到的网页内容,非常简单又方便地为用户提供需要抓取的数据,比如文字内容,图片链接等。若未安装,则运行cmd,输入`pip install requests`及`pip install beautifulsoup4`。
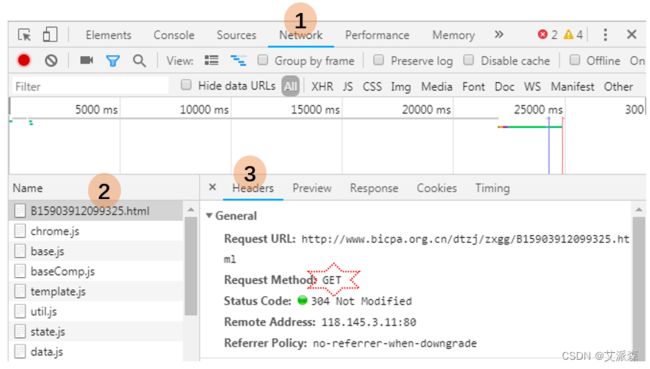
库准备好后,就可以开始爬虫之旅了。先随便选择一篇文章,点击进去,看看网页的情况。单个文章的网页的`Request Method`(请求方法)一般都是`get`。如果不确定,可以点击"Network",然后刷新页面,在左侧"Name"栏选第一个文件,然后再选"Headers"查看"Request Method"。由于请求方法是`get`,所以我们用`requests`获取链接信息的时候就要用`get`。将获取到的链接信息传递给`wb_data`变量,然后调用`BeautifulSoup`进行解析。此处,我们传入`BeautifulSoup`中的参数是`wb_data.content`,表示是二进制数据。还有一种是`wb_data.text`,表示是Unicode型的数据。由于使用`.text`,`soup`变量里的中文显示为乱码,所以此处使用`.content`。最后显示`soup`,就能看到这个网页里的信息。我们需要的文章标题和内容都在里面。
import requests
from bs4 import BeautifulSoup
url = 'http://www.bicpa.org.cn/dtzj/zxgg/B15903912099325.html'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.content)
soup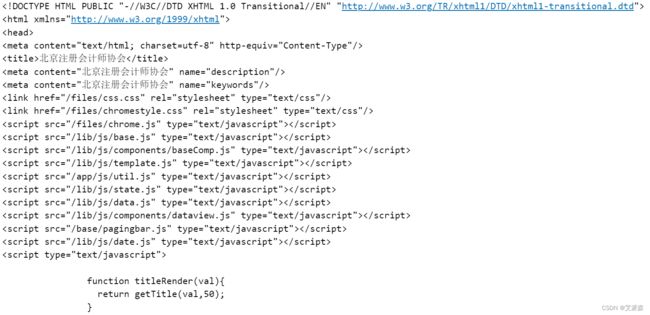
由于只想要标题和正文,所以直接在标题上点右键,选择“检查”(此处用谷歌Chrome浏览器)。浏览器右边出现如下窗口。可见标题对应的`class`为`headword`。因此,可以在soup中使用`select`方法,传入`.headword`获取这个`class`里的信息("."就表示按"class"选择)。我们可以看到标题连带一些语句信息就提取出来并存入了一个列表,这个列表中只有1个元素。
soup.select('.headword')![]()
然后使用`.text`方法将这个列表中的文本提取出来,并用`strip()`去掉首尾的空格,存到`title`变量。显示一下,就得到完整的标题。
#获取文章标题
title = soup.select('.headword')[0].text.strip()
title![]()
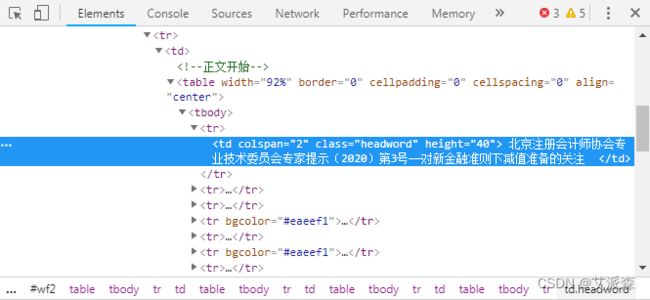
类似的方法,可以获取到正文文本。通过“检查”正文文本,发现正文位于`class = MsoNormal`下面。因此使用`soup.select(".MsoNormal")`按`class`选取,其中的"."就表示`class`。正文内容存到列表`content`,要提取其文本内容,需要遍历这个列表,然后分别按文本提取。还有一部分文章的正文位于`id = "art_content"`下面,则需要使用`soup.select("#art_content")`来获取,“#”就表示`id`。这样,我们就成功地提取出了一篇文章的内容。
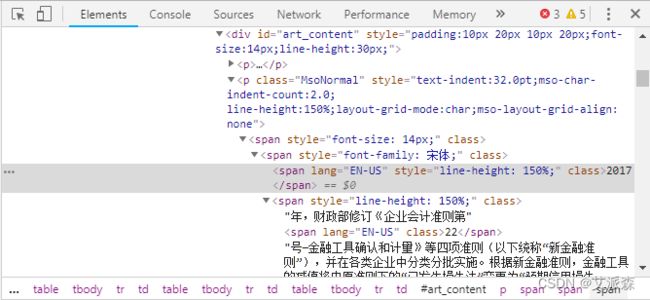
#获取正文文本
content = soup.select(".MsoNormal")
for i in content:
print(i.text)
是不是有点嘚瑟啊?慢着,别骄傲,万里长征才走完小小的一步。这个爬虫的难度在于获取所有4000多篇文章的链接。观察每篇文章的链接,没发现什么规律。而且通过点击“下一页”,网页的网址没有变化,始终是“http://www.bicpa.org.cn/dtzj/zxgg/index.html” 。这说明翻页时,网页是异步加载的,直接使用`get`方法去获取,是不能获取到那些文章链接的。
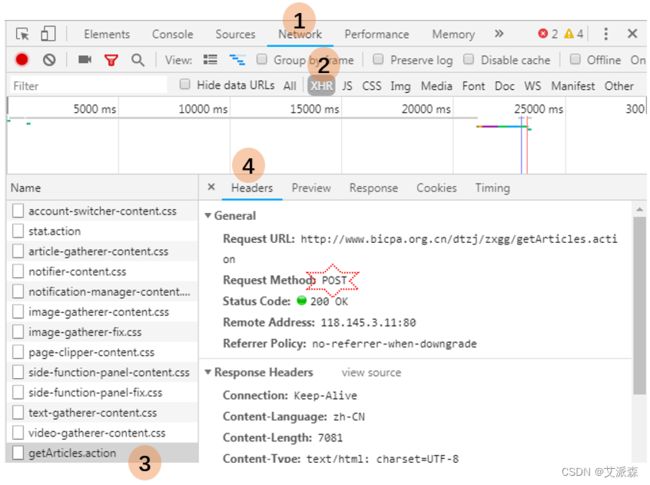
我们再从浏览器进到以上链接,点右键,选择“检查”。右边窗口出现如下界面,按顺序选择"Network","XHR",`Name`里面最下面的"getAtricles.action","Headers"。可以看到请求的URL,以及请求方法(是`POST`)。为什么要针对性地选"XHR"呢,因为它就是实现异步加载的,其全称是`XMLHttpRequest`。如果选"All"会显示所有,不利于快速锁定目标。还有问题,为什么是`Name`里面最下面那个?因为通过观察,发现网页在刷新的时候,文章列表最后出现,而且`Name`里面最后一个的名字翻译成中文,正好是“获取文章”。
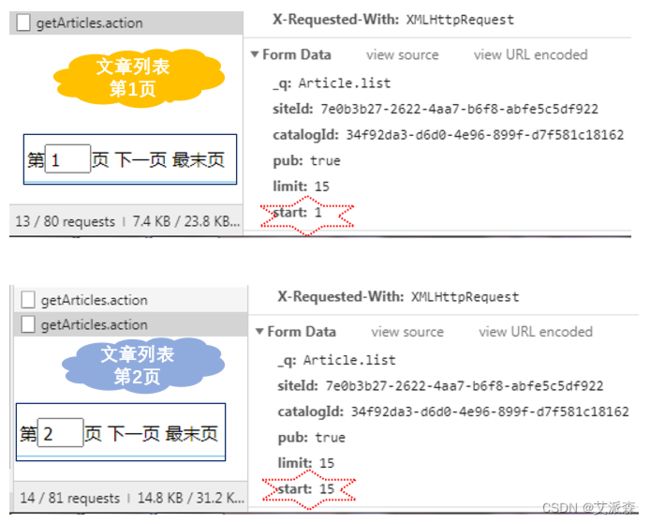
找到了获取文章列表的URL和请求方法,还需要知道其数据提交格式。将上图右边的滚动条拖到最下面,可以看到`Form Data`,这个就是数据提交格式了。注意`start`和`limit`的值,这个表示文章的开始数和最多文章数。第一次的`getAtricles.action`,`start`是1,`limit`是15,表示显示1~15篇文章,这个正是第一页显示的文章总数。然后我们手动点一下网页中的“下一页”,马上出现第二次`getAtricles.action`,这次`start`变成了15了,`limit`不变,因为文章显示页面只够显示15篇文章。这样我们就知道怎么通过Python去模拟浏览器请求数据了。
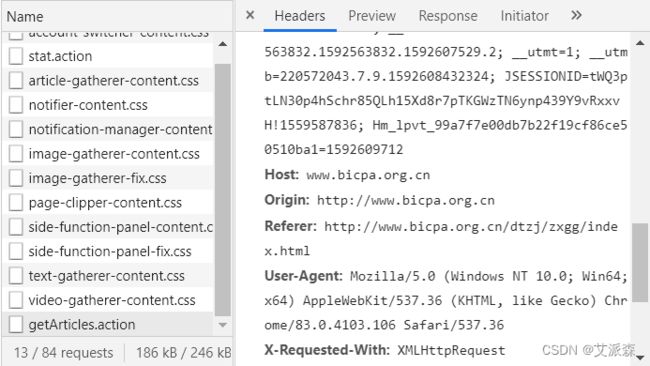
说干就干,先导入`requests`库,定义一个`header`,将下图`Headers`中的`User-Agent`连同后面一串字符复制过来。为什么要搞这个呢?是为了将程序伪装成一个浏览器,避免对方服务器发现是爬虫程序而拒绝访问。如果网站没有这些反爬虫设置,也可以不搞这个伪装。小心驶得万年船,搞起放心点。
然后将`Form Data`里的所有内容也复制过来,做成字典的格式,存入`form_data`字典,注意`start`和`limit`的值是整数,不能是字符串。这里直接将`limit`改成5000,一次性获取所有文章的链接信息,而不是像网页上点击那样,以15个为一段去获取。为什么是5000呢,因为文章总数是4946个,所以5000够用了。再复制`Resquest URL`,存入`url`变量。然后调用`requests.post`,传入`url`,`data`和`headers`参数,开始获取,最后显示其文本。
import requests
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'}
form_data = {'_q': 'Article.list',
'siteId': '7e0b3b27-2622-4aa7-b6f8-abfe5c5df922',
'catalogId': '34f92da3-d6d0-4e96-899f-d7f581c18162',
'pub': 'true',
'limit': 5000,
'start': 1}
#这是异步加载,请求方法是POST
url = "http://www.bicpa.org.cn/dtzj/zxgg/getArticles.action"
res = requests.post(url, data = form_data, headers = header)
res.text以上运行内容是一个超级大的字符串,里面存着4946篇文章的基本信息。我们需要使用`json`将其转换成Python能够处理的数据,以便从中提取需要的信息。在此之前,需要将字符串首尾无关数据去掉(下图红色部分),才能满足`json`能够识别的格式。

article_data0 =res.text.split("{success:true,datas:")[1] #去掉字符串前面的无用信息“{success:true,datas:”
article_data = article_data0.split(",total:")[0] #去掉字符串后面的无用信息“,total:4946}”
article_data我们观察`article_data`,它其实是一个超大字符串,如果将首尾的`'`去掉,它就是一个Python列表,列表中有很多字典,每个字典存储的就是每篇文章的基本信息。`json`的作用就是将这个超大字符串转换成Python能够识别的列表,这样我们才能从中提取需要的数据。将字符串`article_data`传入`json.loads()`即可完成转换。`loads`意思是`load string`,即加载字符串。转化后的数据存入`obj`,查看其类型,显示为`list`,即列表。然后我们看一下`obj`有多少数据,正好4946条,对应文章总数。用`obj[0]`显示第一条数据,真个眉清目秀啊。
import json
obj = json.loads(article_data)
type(obj)
len(obj) 
obj[0]
然后,我们就开始逐条将需要的信息抽取出来。我们需要的数据有`title`、`publishDate`、`primaryKey`和`url`,分别表示文章标题、发布时间、文章链接编号及文章链接。通过观察单篇文章的链接,都是“http://www.bicpa.org.cn” 加`url`,再加上`primaryKey`和“.html”。
由于我只对“专家提示”相关的文章感兴趣,所以用了一个`if`语句来限制,只有标题含有“委员会专家提示”字符的才获取其信息。获取的信息存入字典`article`,再加入总文章列表`articles`。最后查看其前5项。
#获取标题含有“委员会专家提示”的文章的标题,发布时间和链接
path = r"http://www.bicpa.org.cn"
articles = []
for info in obj:
if "委员会专家提示" in info['title']:
article = {
"标题": info['title'].strip(), #strip()去除首尾空格
"发布时间": info['publishDate'],
"链接": path + info['url'] + info['primaryKey']+".html"
}
articles.append(article)
articles[:5]
len(articles)
需要的信息获取完成后,就可以逐个爬取文章并写入word文档了。如下定义了一个函数`Get_article_to_word`,其中有两个参数,一个是`url`,即文章的链接;另一个是`date`,即文章的发布时间。
然后建了一个浏览器列表`user_agent_list`,里面放入了7个浏览器信息,以便在爬取文章的时候从里面随机选取,避免单个浏览器请求太快而被服务器拒绝访问。
在获取正文的时候,有些正文布局为“class = "MsoNormal"”;有些则是“id = "art_content"”;还有些是两者都有,“class”负责正文中表格的部分,“id”负责正文部分。因此建了两个变量,`content1`和`content2`,无论有无,将两个信息都获取。在写入到word文件时,先写`content2`的,再写`content1`的,这样能保证正文在前,表格在后。
#获取想要的文章并批量写入word文件
import requests
from bs4 import BeautifulSoup
import docx
from docx.shared import Pt #用于设定字体大小(磅值)
from docx.oxml.ns import qn #用于应用中文字体
import random
import time
def Get_article_to_word(url,date):
user_agent_list = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15"
]
header = {'User-Agent': user_agent_list}
header['User-Agent'] = random.choice(user_agent_list) #每篇文章随机选择浏览器,避免单个浏览器请求太快被服务器切断连接
wb_data = requests.get(url,headers = header)
soup = BeautifulSoup(wb_data.content)
title = soup.select('.headword')[0].text.strip()#获得标题
content1 = soup.select(".MsoNormal") #针对正文布局为 class = "MsoNormal"
content2 = soup.select("#art_content") #针对正文布局为 id = "art_content"
doc = docx.Document() #新建空白word文档
#设定全局字体
doc.styles['Normal'].font.name=u'宋体'
doc.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
#写入标题行,并设置字体格式
p = doc.add_paragraph()
r = p.add_run(title)
r.bold = True
r.font.size = Pt(18)
doc.add_paragraph(date) #写入日期
doc.add_paragraph(url) #写入文章链接
#写入正文
for i in content2:
doc.add_paragraph(i.text)
for i in content1:
doc.add_paragraph(i.text)
doc.save(f"文章\\{title}.docx")
#遍历所有文章的链接,调用以上函数执行
for art in articles:
Get_article_to_word(art["链接"],art["发布时间"])
print("{} 下载完成。".format(art['标题']))
if articles.index(art) % 30 == 29: #每获取30篇文章,暂停5秒,避免频繁请求被服务器切断连接
time.sleep(5)
print(f"共下载 {len(articles)} 篇文章。")
爬取的文章如下。好了,睡午觉去了。
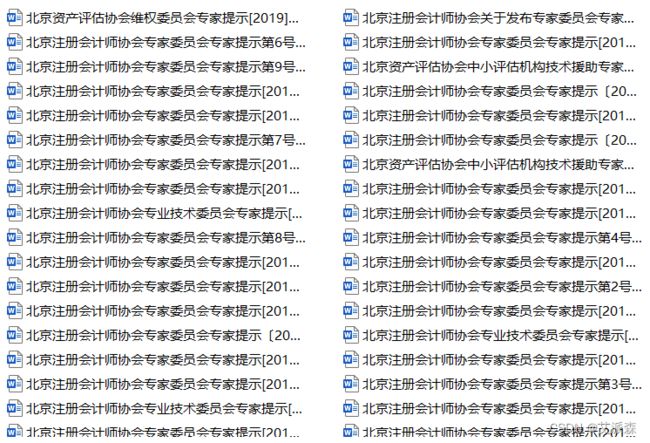
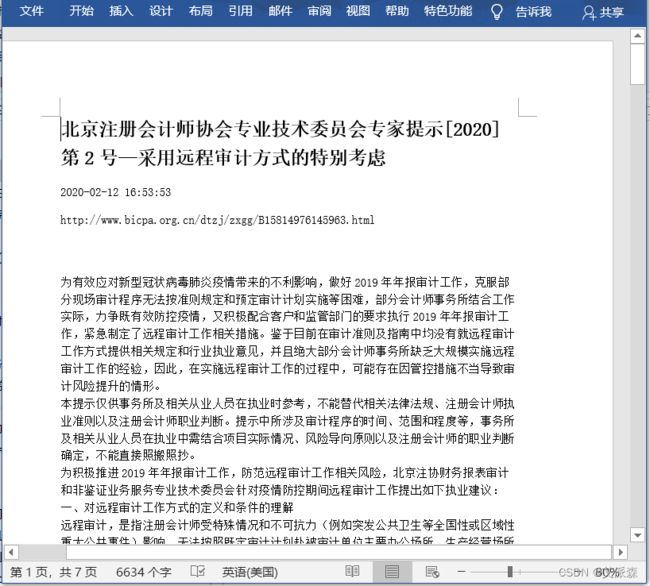
三、文末推荐与福利
《硅基物语 AI写作高手》免费包邮送出3本!

内容简介:
本书从写作与ChatGPT的基础知识讲起,结合创作者的实际写作经历与写作教学经历,重点介了用ChatGPT写作的基础技巧、进阶写作的方法、不同文体的写作方法、写作变现的秘诀,让读者系统地理解写作技巧与变现思路。本书包括如下内容:用ChatGPT重建写作思维、快速摘定选题、快速写出标题、高效收集索材、生成文章结构、写出优质文章、进行日常写作训练,以及用ChatGPT提升写作变现能力。本书适合零基础想学习写作、想利用ChatGPT提高写作能力的读者阅读。
本书适合零基础想学习写作、想利用ChatGPT提高写作能力的读者阅读。编辑推荐:
覆盖常用写作场景:写小说、写故事、写文案、写策划、写新媒体文章、写广告卖点……
提高写作效率:输入有效提问关键词,一键生成所需内容,稍加修改便成一篇完整文章,将写作效率成百倍提升。
扩大素材积累:作为天生的超大型素材库,只有你想不到的素材,没有AI无法提供的素材,极大充实素材库,让写作不再无内容可写。
快速进行文本精修:文稿写完只完成了第一步,修改校对仍是重中之重。AI自带语句精修功能,可对文稿的内容、结构、标点符号等进行全方位的修订,让稿件修改更轻松、更精细。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-10-16 20:00:00
京东购买链接:https://item.jd.com/13856373.html
当当网购买链接:http://product.dangdang.com/29626355.html
名单公布时间:2023-10-16 21:00:00