go的学习--数据类型--网络编程
go的学习
- 1、背景
- 2、go的介绍
- 3、go适用的项目类型
- 4、go学习框架
- 汇总一览表
- 字符串 string
-
- 字符串修改
- 字符串方法
- 占位符
- 数组和切片 array和slice
-
- array定长数组
- slice切片
- 切片的扩容策略
- new函数
- make函数
- 映射 map
-
- 判断键存在的写法
- 遍历字典
- 删除键值对
- map的实现原理
-
- map的主要组成结构
- 成为map的键的规则
- go的map不是线程安全的,但是sync.map是线程安全的
- 结构体
-
- 匿名结构体
- 结构体的匿名字段
- 结构体的“继承”
- 结构体字段的可见性
- 几个面试题
- 接口
-
- 类型与接口的关系
-
- 一个类型实现多个接口
- 多个类型实现同一接口
- 接口的类型断言和非接口的类型转换
-
- 接口的类型断言
- 非接口的类型转换
- defer延迟函数
-
- defer与return的执行顺序
- defer与panic的执行顺序
- 网络编程
-
- TCP
- UDP
- TCP粘包
go够基础数据类型包含以下:
- 值类型
- 布尔类型
- 固定长度数组
- 数字类型
- 引用类型(指针类型)
- slice 切片类型(序列数组)
- map 映射
- chan 管道
1、背景
由于公司的项目全部转型。从python全部切换用go重新规划搭建。那么从今天开始也要开始看看go语言
为转型做准备。
2、go的介绍
go语言(golang)是由google开发的开源编程语言。go在多核并发上拥有原生的设计优势,从底层支持原生支持并发,无需第三方库、开发者的编程技巧和开发经验。
它主要的目标就是 兼容动态语言的开发敏捷性和c/c++等编译性语言的性能和安全性
go的并发是基于goroutine的,简称go程,go程类似于线程,但并非线程。它是一种用户态线程。go运行时会参与调度go程,并将go程合理分配到每个CPU。最大限度使用CPU性能。开启一个go程消费非常小(约2kb内存)。
3、go适用的项目类型
- 服务端开发
- 分布式系统,微服务
- 网络编程
- 区块链开发
- 内存kv数据库,如boltDB、levelDB
- 云平台
4、go学习框架
- go基础
- 基础数据类型
- 基础语法
- 函数
- 流程控制
- 方法
- 面向对象
- 网络编程
- 并发编程
- 数据库操作
- 常用标准库
- 框架
- beego框架
- gin框架
- Iris框架
- Echo框架
- 微服务
- go高级
汇总一览表
Go 语言数据类型包含基础类型和复合类型两大类。
基础数据类型包括:布尔型、整型、浮点型、复数型、字符型、字符串型、错误类型。
复合数据类型包括:指针、数组、切片、字典、通道、结构体、接口。
| 类型 | 长度(字节) | 默认值 | 说明 |
|---|---|---|---|
| bool | 1 | false | |
| byte | 1 | 0 | uint8 |
| rune | 4 | 0 | int32 |
| int , uint | 4或8 | 0 | 32位或者64位 |
| int8 , uint8 | 1 | 0 | 有符号8位整型(-128-127) 支持的是数字区间-128-127,无符号8位整型(0-255) 支持的是数字区间0-255 |
| int16 , uint16 | 2 | 0 | 有符号16位整型(-32768-32767) 支持的是数字区间-32768-32767,无符号16位整型(0-65535) 支持的是数字区间0-65535 |
| int32 , uint32 | 4 | 0 | 有符号32位整型(-2147483648-2147483647) 支持的是数字区间-2147483648-2147483647,无符号32位整型(0-4294967295) 支持的是数字区间0-4294967295 |
| int64 , uint64 | 8 | 0 | 有符号64位整型(-9223372036854775808-9223372036854775807) 支持的是数字区间-9223372036854775808-9223372036854775807,无符号64位整型(0-18446744073709551615) 支持的是数字区间0-18446744073709551615 |
| float32 | 4 | 0.0 | IEEE-754 32位浮点型数 IEEE-754代表浮点数国际标准 |
| float64 | 8 | 0.0 | IEEE-754 64位浮点型数 IEEE-754代表浮点数国际标准 |
| complex64 | 8 | 32 位实数和虚数 | |
| complex128 | 16 | 64 位实数和虚数 | |
| uintptr | 4或8 | 存储指针的uint32或uint64整数。主要用于存放指针 | |
| array | 固定长度数组,值类型 | ||
| struct | 结构体,值类型 | ||
| string | “” | utf-8字符串,值类型 | |
| slice | nil | 切片,引用类型 | |
| map | nil | 映射,引用类型 | |
| channel | nil | 通道,引用类型 | |
| interface | nil | 接口,接口类型 | |
| function | nil | 函数 |
总结来说:
8位总长度:2^8=256
16位总长度:2^16=65536
32位总长度:2^32=4294967296
64位总长度:2^64=18446744073709551616
byte类型或者uint8类型代表了ASCII的一个字符
rune类型或者int32类型代表了UTF-8字符
当需要处理中文日文等其他符合字符时需要用到rune
这里数字类型不再赘述
字符串 string
UTF8编码下一个中文汉字由3-4个字节组成,所以不能使用len法遍历,应该使用range。具体如下:
str.go
package main
import "fmt"
func main() {
s := "pninjn.com游戏"
for i := 0;i < len(s); i++{
fmt.Printf("%v(%c)", s[i], s[i])
}
fmt.Println("\n")
for _, r := range s{
fmt.Printf("%v(%c)", r, r)
}
fmt.Println("\n")
}
/*
112(p)110(n)105(i)110(n)106(j)110(n)46(.)99(c)111(o)109(m)230(æ)184(¸)184(¸)230(æ)136()143()
112(p)110(n)105(i)110(n)106(j)110(n)46(.)99(c)111(o)109(m)28216(游)25103(戏)
*/
字符串底层是一个byte数组,所以可以个[]byte类型相互转换。字符串是不能修改的,它是byte字节组成,所以字符串的长度是byte字节的长度。rune类型用来表示utf-8字符,一个rune字符由一个或多个byte组成。
字符串修改
要修改字符串,需要先将其转换成[]rune或[]byte。完成后再转换成string。无论哪种转换,都会重新分配内存,并复制字节数组。
package main
import "fmt"
func main() {
s := "pninjn.com"
byteS := []byte(s)
byteS[9] = 'K'
fmt.Println(string(byteS))
s1 := "天地孤影任我行"
runeS := []rune(s1)
runeS[0] = '版'
fmt.Println(string(runeS))
}
/*
pninjn.coK
版地孤影任我行
*/
字符串方法
| 方法 | 说明 |
|---|---|
| len(str) | 求长度 |
| +或者fmt.Sprintf() | 拼接字符串 |
| strings.Split() | 分割 |
| strings.Contains() | 判断是否包含 |
| 这里举例说明部分,更全面的请阅读源码,这里不再赘述 |
package main
import (
"fmt"
"strings"
)
func main() {
s := "pninjn.com|天地孤吟任我行"
// 求长度
sLen := len(s)
fmt.Println(sLen)
// 拼接字符串
s1 := "这是一个数组"
sS1 := s + s1
fmt.Printf(sS1)
fmt.Println("\n")
ssS1 := fmt.Sprintf("%s%s", s, s1)
fmt.Println(ssS1)
index := strings.Index(s, "com")
fmt.Println(index)
}
/*
32
pninjn.com|天地孤吟任我行这是一个数组
pninjn.com|天地孤吟任我行这是一个数组
7
*/
占位符
# 定义示例类型和变量
type Human struct {
Name string
}
var people = Human{Name:"zhangsan"}
普通占位符
占位符 说明 举例 输出
%v 相应值的默认格式。 Printf("%v", people) {zhangsan},
%+v 打印结构体时,会添加字段名 Printf("%+v", people) {Name:zhangsan}
%#v 相应值的Go语法表示 Printf("%#v", people) main.Human{Name:"zhangsan"}
%T 相应值的类型的Go语法表示 Printf("%T", people) main.Human
%% 字面上的百分号,并非值的占位符 Printf("%%") %
布尔占位符
占位符 说明 举例 输出
%t true 或 false。 Printf("%t", true) true
整数占位符
占位符 说明 举例 输出
%b 二进制表示 Printf("%b", 5) 101
%c 相应Unicode码点所表示的字符 Printf("%c", 0x4E2D) 中
%d 十进制表示 Printf("%d", 0x12) 18
%o 八进制表示 Printf("%d", 10) 12
%q 单引号围绕的字符字面值,由Go语法安全地转义 Printf("%q", 0x4E2D) '中'
%x 十六进制表示,字母形式为小写 a-f Printf("%x", 13) d
%X 十六进制表示,字母形式为大写 A-F Printf("%x", 13) D
%U Unicode格式:U+1234,等同于 "U+%04X" Printf("%U", 0x4E2D) U+4E2D
浮点数和复数的组成部分(实部和虚部)
占位符 说明 举例 输出
%b 无小数部分的,指数为二的幂的科学计数法,
与 strconv.FormatFloat 的 'b' 转换格式一致。例如 -123456p-78
%e 科学计数法,例如 -1234.456e+78 Printf("%e", 10.2) 1.020000e+01
%E 科学计数法,例如 -1234.456E+78 Printf("%e", 10.2) 1.020000E+01
%f 有小数点而无指数,例如 123.456 Printf("%f", 10.2) 10.200000
%g 根据情况选择 %e 或 %f 以产生更紧凑的(无末尾的0)输出 Printf("%g", 10.20) 10.2
%G 根据情况选择 %E 或 %f 以产生更紧凑的(无末尾的0)输出 Printf("%G", 10.20+2i) (10.2+2i)
字符串与字节切片
占位符 说明 举例 输出
%s 输出字符串表示(string类型或[]byte) Printf("%s", []byte("Go语言")) Go语言
%q 双引号围绕的字符串,由Go语法安全地转义 Printf("%q", "Go语言") "Go语言"
%x 十六进制,小写字母,每字节两个字符 Printf("%x", "golang") 676f6c616e67
%X 十六进制,大写字母,每字节两个字符 Printf("%X", "golang") 676F6C616E67
指针
占位符 说明 举例 输出
%p 十六进制表示,前缀 0x Printf("%p", &people) 0x4f57f0
其它标记
占位符 说明 举例 输出
+ 总打印数值的正负号;对于%q(%+q)保证只输出ASCII编码的字符。
Printf("%+q", "中文") "\u4e2d\u6587"
- 在右侧而非左侧填充空格(左对齐该区域)
# 备用格式:为八进制添加前导 0(%#o) Printf("%#U", '中') U+4E2D
为十六进制添加前导 0x(%#x)或 0X(%#X),为 %p(%#p)去掉前导 0x;
如果可能的话,%q(%#q)会打印原始 (即反引号围绕的)字符串;
如果是可打印字符,%U(%#U)会写出该字符的
Unicode 编码形式(如字符 x 会被打印成 U+0078 'x')。
' ' (空格)为数值中省略的正负号留出空白(% d);
以十六进制(% x, % X)打印字符串或切片时,在字节之间用空格隔开
0 填充前导的0而非空格;对于数字,这会将填充移到正负号之后
golang没有 '%u' 点位符,若整数为无符号类型,默认就会被打印成无符号的。
数组和切片 array和slice
array定长数组
- 数组:是同一种数据类型的固定长度的序列。
- 数组定义:var a [len]int,比如:var a [5]int,数组长度必须是常量,且是类型的组成部分。一旦定义,长度不能变。
- 访问越界,如果下标在数组合法范围之外,则触发访问越界,会panic
- 数组是值类型,赋值和传参会复制整个数组,而不是指针。因此改变副本的值,不会改变本身的值
- 支持 “==”、“!=” 操作符,因为内存总是被初始化过的。
- 指针数组 [n]*T,数组指针 *[n]T。
package main
import "fmt"
func main() {
name := [5][2]string{{"a", "b"}, {"c", "d"}, {"e", "f"}, {"g", "h"}, {"i", "j"}}
fmt.Println(name)
for i := 1; i <= 9; i++ {
for j := 1; j <= i; j++ {
fmt.Printf("%d*%d=%d ", j, i, j*i)
}
fmt.Println("\n")
}
name[0][0] = "imgpo"
fmt.Println(name)
}
/*
[[a b] [c d] [e f] [g h] [i j]]
1*1=1
1*2=2 2*2=4
1*3=3 2*3=6 3*3=9
1*4=4 2*4=8 3*4=12 4*4=16
1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
[[imgpo b] [c d] [e f] [g h] [i j]]
*/
a := [3]int{1, 2} // 未初始化元素值为 0。
b := [...]int{1, 2, 3, 4} // 通过初始化值确定数组长度。
c := [5]int{2: 100, 4: 200} // 使用索引号初始化元素。
slice切片
- 切片:切片是数组的一个引用,因此切片是引用类型。但自身是结构体,值拷贝传递。
- 切片的长度可以改变,因此,切片是一个可变的数组。
- 切片遍历方式和数组一样,可以用len()求长度。表示可用元素数量,读写操作不能超过该限制。
- cap可以求出slice最大扩张容量,不能超出数组限制。0 <= len(slice) <= len(array),其中array是slice引用的数组。
- 切片的定义:var 变量名 []类型,比如 var str []string var arr []int。
- 如果 slice == nil,那么 len、cap 结果都等于 0。
s := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := s[2: 4]
fmt.Println(s1, len(s1), cap(s1)) //[2 3] 2 8
s2 := s1[7:8]
fmt.Println(s2, len(s2), cap(s2)) //[9] 1 1
fmt.Printf("%p, %p, %p", &s, &s1, &s2) //0xc0000a4018, 0xc0000a4030, 0xc0000a4060
/*
从以上可以看出,切片新切出来的切片是和原切片不同的指针地址。新切片的len和cap随之发生变化。
len即元素个数,cap是从切的起始下标开始到原切片结束。
*/
//但通常情况下我们使用make动态创建引用类型
ss := make([]int, 9, 9)
fmt.Println(ss, len(ss), cap(ss)) //[0 0 0 0 0 0 0 0 0] 9 9
需要注意的问题
//从切片 切出新的切片
s := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := s[:]
fmt.Printf("%p, %p, %v, %v\n", s, s1, s, s1) // 0xc0000160f0, 0xc0000160f0, [0 1 2 3 4 5 6 7 8 9], [0 1 2 3 4 5 6 7 8 9]
s[0] = 9999
fmt.Printf("%p, %p, %v, %v\n", s, s1, s, s1) // 0xc0000160f0, 0xc0000160f0, [9999 1 2 3 4 5 6 7 8 9], [9999 1 2 3 4 5 6 7 8 9]
s1[1] = 1111111
fmt.Printf("%p, %p, %v, %v\n", s, s1, s, s1) // 0xc0000160f0, 0xc0000160f0, [9999 1111111 2 3 4 5 6 7 8 9], [9999 1111111 2 3 4 5 6 7 8 9]
// 从数组 切除新的切片
s := [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := s[:]
fmt.Printf("%p, %p, %v, %v\n", &s, &s1, s, s1) //0xc0000b4000, 0xc0000a4018, [0 1 2 3 4 5 6 7 8 9], [0 1 2 3 4 5 6 7 8 9]
s[0] = 9999
fmt.Printf("%p, %p, %v, %v\n", &s, s1, s, s1) //0xc0000b4000, 0xc0000b4000, [9999 1 2 3 4 5 6 7 8 9], [9999 1 2 3 4 5 6 7 8 9]
s1[1] = 1111111
fmt.Printf("%p, %p, %v, %v\n", &s, s1, s, s1) //0xc0000b4000, 0xc0000b4000, [9999 1111111 2 3 4 5 6 7 8 9], [9999 1111111 2 3 4 5 6 7 8 9]
/*
总结来说:无论是从数组还是从切片 切出新的切片,返回的引用就是底层数组的地址
而内存中还要开辟空间来保存新的切片的地址。所以切片的地址和底层数组的地址是不一样的。
*/
现在我们来看下切片的实现原理和数据结构
切片本身并不是动态数组或者数组指针。他内部实现的数据结构通过指针应用底层数组,设定相关的属性将数据读写操作限定在指定的区域内。切片本身是一个只读对象,其工作机制类似于数组指针的一种封装。
切片是对数组一个连续片段的引用,所以切片是一个引用类型。这个片段可以使整个数组或者子数组。需要注意的是,终止索引标识的项不包含在切片内。切片提供了一个与指向数组的动态窗口。
切片的数据结构定义如下:
type slice struct {
array unsafe.Pointer
len int
cap int
}
切片本身是一种结构体,由3部分组成,Pointer是指向底层数组的指针,len代表当前切片的长度,cap是当前切片的容量。cap总是大于等于len。
手动构造一个slice
package main
import (
"fmt"
"reflect"
"unsafe"
)
func main() {
var o []byte
s := make([]byte, 200)
ptr := unsafe.Pointer(&s[0]) //将切片的第一个元素的指针转换成万能指针
sliceHeader := (*reflect.SliceHeader)((unsafe.Pointer(&o))) // 将nil切片类型改为struct类型
sliceHeader.Cap = 10
sliceHeader.Len = 10
sliceHeader.Data = uintptr(ptr) //转变代表指针的数字,可以进行运算。
fmt.Println(*sliceHeader) //{824634220544 10 10} 这里的824634220544代表指针
}
切片的扩容策略
如果切片的容量小于 1024 个元素,于是扩容的时候就翻倍增加容量。总容量从原来的4个翻倍到现在的8个。
一旦元素个数超过 1024 个元素,那么增长因子就变成 1.25 ,即每次增加原来容量的四分之一。
注意:扩容扩大的容量都是针对原来的容量而言的,而不是针对原来数组的长度而言的
这里是扩容的核心源码
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
for newcap < cap {
newcap += newcap / 4
}
}
}
这里再讲一下new和map的区别
new函数
new得到的是一个类型的指针,并且该指针对应的值为该类型的零值。
new函数参数和返回值
func new(Type) *Type
可以看出参数是一个类型,返回的时这个类型的指针
a := new(int)
fmt.Printf("%T\n", a) // *int
b := make(map[string]int, 10)
b["测试"] = 10
fmt.Println(b) //map[测试:10]
make函数
make也是用于内存分配,区别于new,他只用于slice、map、chan的内存创建,而且他返回的类型就是这三个类型本身,而不是他们的指针,因为这三种就是引用类型,所以没必要返回他们的指针。
new和make的区别
1、都是用来做内存分配的
2、make只用于slice、map、chan的初始化,返回的还是这三个引用类型本身
3、而new用于类型的内存分配,并且内存的只为类型零值,返回的是指向类型的指针
映射 map
map是一种无序的基于key-value的数据结构,go中的map是引用类型,必须初始化才能使用
map的语法定义。 map[KeyType]ValueType
map类型的变量初始值为nil,需要使用make()函数分配内存
语法 make(map[KeyType]ValueType, [cap]) cap表示容量
判断键存在的写法
value, ok := map[key]
package main
import "fmt"
func main() {
b := make(map[string]int, 1)
b["测试"] = 10
fmt.Println(b) // map[测试:10]
// 判断字典的某个键是否存在
v, ok := b["d"]
fmt.Println(v, ok) // 0 false
v1, ok1 := b["测试"]
fmt.Println(v1, ok1) // 10 true
}
遍历字典
package main
import (
"fmt"
)
func main() {
b := make(map[string]int, 1)
b["测试"] = 10
b["张无忌"] = 20
b["赵敏"] = 20
b["弗拉基米尔"] = 10000
fmt.Println(len(b))
// 使用for range 遍历map
for k, v := range b{
fmt.Println(k, v)
}
// 只遍历key
for v := range b{
fmt.Println(v)
}
// 只遍历value
for _, v := range b{
fmt.Println(v)
}
}
/*
4
弗拉基米尔 10000
测试 10
张无忌 20
赵敏 20
弗拉基米尔
测试
张无忌
赵敏
10
20
20
10000
*/
删除键值对
delete(map, key)
package main
import (
"fmt"
)
func main() {
b := make(map[string]int, 1)
b["测试"] = 10
b["张无忌"] = 20
b["赵敏"] = 20
b["弗拉基米尔"] = 10000
fmt.Println(len(b)) // 4
// 删除键值对
delete(b, "测试")
fmt.Println(b) // map[弗拉基米尔:10000 张无忌:20 赵敏:20]
}
map的实现原理
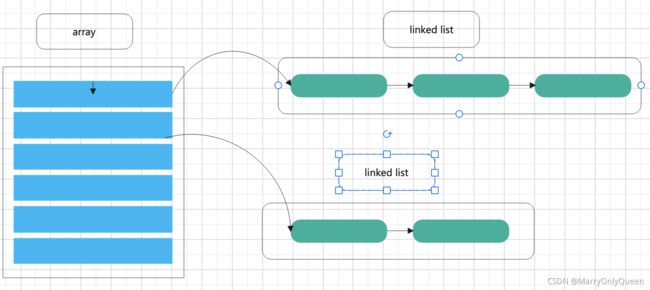
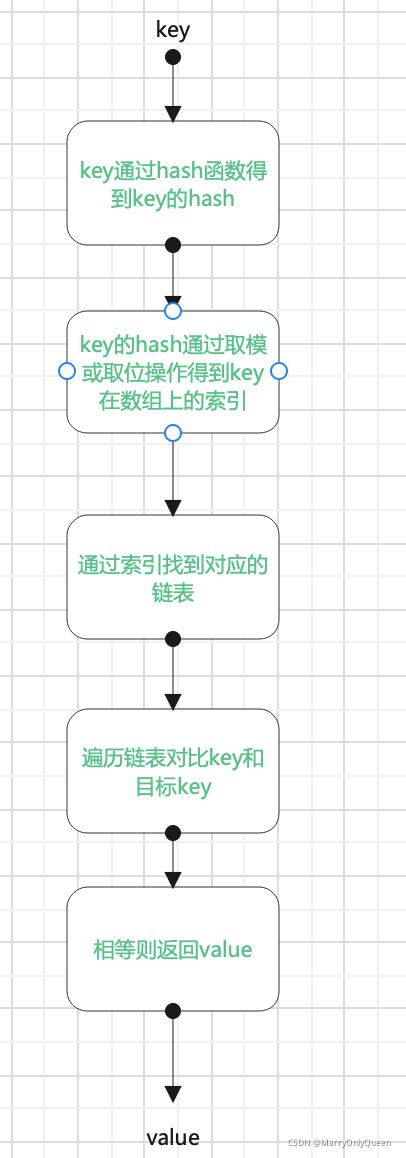
map就是一种通过key来获取value的一种数据结构,其底层存储方式为数组,key重复会进行value覆盖。我们通过key进行hash运算然后对数组的长度取余,得到key存储在数组的下标,最后将key和value组成一个结构体,放入到数组下标
map包含两个主要结构
- 数组:数组里的值指向一个链表
- 链表:解决hash冲突,并存储键值对
结构如下图示:
获取一个key值的值过程如下:
map的主要组成结构
源码中map的结构是hmap
位置在 src/runtime/map.go
// A header for a Go map.
type hmap struct {
count int // 元素(键值对)个数,调用 len(map) 时,直接返回此值
flags uint8 //状态标识,比如正在被写、buckets和oldbuckets正在被遍历、等量扩容
B uint8 // buckets 的对数 log_2 len(buckets)=2^B
noverflow uint16 // 溢出桶里bmap大致的数量
hash0 uint32 // 哈希因子
buckets unsafe.Pointer // 指向 buckets 数组(连续空间),数组的类型为[]bmap,即存储键值对的结构。这个字段称之为正常桶。大小为 2^B, 如果元素个数为0,就为 nil
oldbuckets unsafe.Pointer // 等量扩容的时候,buckets 长度和 oldbuckets 相等, 双倍扩容的时候,buckets 长度会是 oldbuckets 的两倍。扩容时,存放之前的buckets
nevacuate uintptr // 分流次数,成倍扩容分流操作计数的字段
extra *mapextra // 溢出桶结构,正常桶里面某个bmap存满了,会使用这里的内存空间存放键值对
}
//看一下溢出桶的结构
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and elem do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and elem do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
说明一下,B 是 buckets 数组的长度的对数,也就是说 buckets 数组的长度就是 2^B。bucket 里面存储了 key 和 value
buckets是一个指针,最终指向的是一个结构体
结构体的位置在src/runtime/map.go
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
但是这只是表面的结构,编译期间会加料,动态创建一个新的结构
type bmap struct {
topbits [8]uint8 // 长度为8的数组,[]uint8,元素为:key获取的hash的高8位,遍历时对比使用,提高性能。
keys [8]keytype // 长度为8的数组,[]keytype,元素为:具体的key值
elems [8]valuetype //长度为8的数组,[]elemtype,元素为:键值对的key对应的值
pad uintptr //对其内存使用的,不是每个bmap都会有这个字段,需要满足一定条件
overflow uintptr //指向hmap.extra.overflow溢出桶里的bmap,上面的字段topbits、keys、elems长度为8,最多存8组键值对,存满了就往指向的这个bmap里存
}
bmap就是我们说的桶,同里面最多装8个key,这些key之所以会落入一个桶,是因为他们经过哈希计算后,哈希结果是“一类”的。在桶内,又会根据key计算出的hash值的高8位来决定key到底落在桶的哪个位置。
用图示表示hmap和bmap的关联关系:
最后总结一下关系网:
map的结构是hmap,它记录了map的一些基本属性以及存储key-value数组的buckets指针。而buckets的底层其实就是bmap类型的数组(正常桶),bmap包含了真正存储k-v结构的两个数组,以及提升遍历map时的高8位hash,正常存储8个情况下,bmap不会出现溢出桶情况。溢出桶情况下bmap的overflow指向溢出桶hmap.extra.overflow里的bmap。由此构成链表。
需要注意的点
slice和map作为参数传参的区别在于
//创建slice返回时slice结构体,而创建map返回的是指针
// 创建slice的函数
func makeslice(et *_type, len, cap int) slice
// slice的结构体
// runtime/slice.go
type slice struct {
array unsafe.Pointer // 元素指针
len int // 长度
cap int // 容量
}
// runtime/map.go
//创建map的函数
func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap
go中的函数传参都是值传递,在函数内部参数会被copy到本地。*hmap copy完之后仍然指向同一个map,因此函数内部的操作会影响实参。而silce被copy后,将会成为一个新的slice,对他的操作不会影响到实参
成为map的键的规则
go中只要是可比较的类型都可以作为key。除了slice、map、functions、以及任何包涵不可比类型的任何元素类型,其他都是ok的
go的map不是线程安全的,但是sync.map是线程安全的
结构体
go语言中没有类的概念,也不支持“类”的继承等面相对象的概念。go中通过结构体的内嵌再配合接口比面向对象具有更高的扩展性和灵活性
使用type和struct关键字来定义结构体。具体代码如下:
type student struct {
name string
age int
}
语言内置的基础数据类型是用来描述一个值的,而结构体是用来描述一组值的。比如一个人有名字、年龄和居住城市等,本质上是一种聚合型的数据类型
匿名结构体
在定义一些临时数据结构等场景下还可以使用匿名结构体。
代码如下:
package main
import (
"fmt"
)
func main() {
var user struct{Name string; Age int}
user.Name = "pprof.cn"
user.Age = 18
fmt.Printf("%#v\n", user)
}
结构体的匿名字段
结构体允许成员字段在声明时没有字段名而只有类型,这种没有名字的字段就称为你名字段
package main
import "fmt"
type student struct {
string
int
name string
}
func main() {
s1 := student{
"弗拉基米尔",
10,
"opppo",
}
fmt.Printf("%#v\n", s1)
fmt.Println(s1.string, s1.int, s1.name) // 弗拉基米尔 10 opppo
}
匿名字段默认采用类型名作为字段名,结构体要求字段名必须唯一,因此一个结构体中同种类型的匿名字段只能有一个
结构体的“继承”
package main
import "fmt"
type student struct {
name string
}
func (a *student) game() {
fmt.Printf("%s会打游戏\n", a.name)
}
type Sub struct {
skill string
*student //通过匿名结构体嵌套实现继承
}
func (ss *Sub) swim() {
fmt.Printf("%s会游泳\n", ss.name)
}
func main() {
s1 := &Sub{
skill: "grpc",
student: &student{ //注意嵌套的是结构体指针
name: "伊泽瑞尔",
},
}
s1.game() //伊泽瑞尔会打游戏
s1.swim() //伊泽瑞尔会游泳
}
结构体字段的可见性
结构体中字段大写开头表示可公开访问,小写表示私有(仅在定义当前结构体的包中可访问)。
几个面试题
package main
import "fmt"
type student struct {
name string
age int
}
func main() {
m := make(map[string]*student)
stus := []student{
{name: "pprof.cn", age: 18},
{name: "测试", age: 23},
{name: "博客", age: 28},
}
var stu student
for _, stu = range stus {
m[stu.name] = &stu
}
for k, v := range m {
fmt.Println(k, "=>", v.name)
}
}
/*
pprof.cn => 博客
测试 => 博客
博客 => 博客
可以看出的指针都是指向了同一个结构体。即{name: "博客", age: 28},所以打印的都是博客
*/
map的有序输出
package main
import (
"fmt"
"sort"
)
func main() {
map1 := make(map[int]string, 5)
map1[1] = "www.topgoer.com"
map1[2] = "rpc.topgoer.com"
map1[5] = "ceshi"
map1[3] = "xiaohong"
map1[4] = "xiaohuang"
sli := []int{}
for k, _ := range map1 {
sli = append(sli, k)
}
sort.Ints(sli)
for i := 0; i < len(map1); i++ {
fmt.Println(map1[sli[i]])
}
}
接口
1、 go没有类,但是在type上定义method,这样效果和类用起来很类似
2、 如果说类是对数据和方法的抽象和封装,那么接口就是对类的抽象
3、 golang中没有class的概念,而是通过interface类型转换支持在动态类型中常见的鸭子类型从而运行时达到多态的效果
go语言中接口是一种类型,一种抽象的类型;它是一组method的集合,是鸭子类型的一种体现;go的接口是一种类型
下面实现一个接口
package main
import "fmt"
func main() {
var peo People = &Student{}
think := "sb"
fmt.Println(peo.Speak(think))
peo2 := Student{}
fmt.Println(peo2.Speak2(think))
}
type People interface {
Speak(string) string
}
type Student struct{}
func (stu *Student) Speak(think string) (talk string) {
if think == "sb" {
talk = "你是个大帅比"
} else {
talk = "您好"
}
return
}
func (stu Student) Speak2(think string) (talk string) {
if think == "sb" {
talk = "你是个大帅比"
} else {
talk = "您好"
}
return
}
这里说说接口的值接收者和指针接收者的区别
如果将上面的代码改为
package main
import "fmt"
func main() {
var peo People = Student{} // 这里接受的是值
think := "sb"
fmt.Println(peo.Speak(think)) // 此时Speak只接收指针类型
//peo2 := Student{}
//fmt.Println(peo2.Speak2(think), peo2.Speak(think))
}
type People interface {
Speak(string) string
}
type Student struct{}
func (stu *Student) Speak(think string) (talk string) {
if think == "sb" {
talk = "你是个大帅比"
} else {
talk = "您好"
}
return
}
func (stu Student) Speak2(think string) (talk string) {
if think == "sb" {
talk = "你是个大帅比"
} else {
talk = "您好"
}
return
}
/*
直接报错如下
# command-line-arguments
./str.go:6:6: cannot use Student{} (type Student) as type People in assignment:
Student does not implement People (Speak method has pointer receiver)
原因就是实现People接口的是*Student指针类型,所以不能接受值类型
*/
值接收者和指针接收者对原数据的影响
package main
import "fmt"
type people struct {
name string
age int
}
func (p people) age_incr_1() {
p.age += 1
}
func (p *people) age_decr_1() {
p.age += 1
}
func main() {
p1 := people{age: 18}
p2 := &people{age: 18}
fmt.Printf("p1结构体初始化为%v\n", p1) // p1结构体初始化为{ 18}
fmt.Printf("p2结构体初始化为%v\n", p2) // p2结构体初始化为&{ 18}
p1.age_decr_1()
p2.age_incr_1()
fmt.Printf("p1调用指针接受者函数为%v\n", p1) // p1调用指针接受者函数为{ 19}
fmt.Printf("p2调用值接收者函数为%v\n", p2) // p2调用值接收者函数为&{ 18}
}
类型与接口的关系
一个类型实现多个接口
package main
import "fmt"
func main() {
peo := Student{}
peo.Jump("寂寞")
peo.Speak("本草纲目")
}
type People interface {
Speak(string)
}
type human interface {
Jump(string)
}
type Student struct{}
func (stu Student) Speak(s string) {
fmt.Printf("说了个%s", s)
}
func (stu Student) Jump(s string) {
fmt.Printf("跳了个%s", s)
}
// 跳了个寂寞说了个本草纲目
多个类型实现同一接口
package main
import "fmt"
func main() {
peo := Student{}
peo1 := Student1{}
peo2 := Student2{}
peo.Speak("本草纲目\n") // 说了个本草纲目
peo1.Speak("北方的女王\n") // 说了个北方的女王
peo2.Speak("南方姑娘\n") // 说了个南方姑娘
}
type People interface {
Speak(string)
}
type Student struct{}
type Student1 struct{}
type Student2 struct{}
func (stu Student) Speak(s string) {
fmt.Printf("说了个%s", s)
}
func (stu Student1) Speak(s string) {
fmt.Printf("说了个%s", s)
}
func (stu Student2) Speak(s string) {
fmt.Printf("说了个%s", s)
}
接口的类型断言和非接口的类型转换
接口的类型断言
package main
import "fmt"
func main() {
var i interface{} = 100
s, ok := i.(int)
fmt.Println(s, ok)
fmt.Printf("%T\n", s)
f, ok := i.(float32)
fmt.Println(f, ok)
fmt.Printf("%T\n", f)
}
/*
100 true
int
0 false
float32
*/
使用type-switch
package main
import "fmt"
func main() {
var i interface{} = 100
switch x := i.(type) {
case string:
fmt.Printf("it is string %v", x)
case int:
fmt.Printf("it is int %v", x)
case bool:
fmt.Printf("it is bool")
case float64:
fmt.Printf("it is float64")
default:
fmt.Printf("it is gui")
}
}
// it is int 100
非接口的类型转换
package main
import "fmt"
func main() {
peo := 10
c := float64(peo)
fmt.Printf("源类型 %=T,类型转换后%=T", peo, c)
}
// 源类型 %!=(int=10)T,类型转换后%!=(float64=10)T
非接口变量才能类型转换,接口变量才能类型断言
defer延迟函数
- 特性一:延迟调用
- 特性二:先入后出
defer与return的执行顺序
return 会先给返回值赋值,在返回
package main
import (
"fmt"
)
func main() {
fmt.Println(f1()) // 1
fmt.Println(f2()) // 5
fmt.Println(f3()) // 0
}
/*
执行过程:
r = 0-->defer r++ --> 1
*/
func f1() (r int){
defer func(){
r++
}()
return 0
}
/*
执行过程:
r = 5-->defer t=t+5 --> 因为r没有操作 所以返回值5
那么如果吧defer里的t换成r呢 结果是不是应该就是10了。答案 就是10
*/
func f2() (r int) {
t:=5
defer func() {
t = t+5
}()
return t
}
/*
执行过程:
r = 0-->defer r=t+5 --> 但是因为这里是传参,那么结果还是0,
因为golang的参数传递是 值传递
*/
func f3() (r int) {
defer func(r int) {
r = r+5
}(r)
return 0
}
defer与panic的执行顺序
先执行defer结束在执行panic
- 情景1
func main() {
defer fmt.Println(1)
defer fmt.Println(2)
defer fmt.Println(3)
panic("adsadsd")
}
/*
3
2
1
panic: adsadsd
goroutine 1 [running]:
main.main()
/Users/gaozenghui/go/src/learngo/study.go:35 +0xf4
*/
- 情景2
这种情况panic后的defer不会执行,并且编译器会将后面的标黄,会提示 Unreachable code 即不会读取的代码
func main() {
defer fmt.Println(1)
defer fmt.Println(2)
panic("adsadsd")
defer fmt.Println(3)
}
/*
2
1
panic: adsadsd
goroutine 1 [running]:
main.main()
/Users/gaozenghui/go/src/learngo/study.go:34 +0xb3
*/
网络编程
TCP
server
package main
import (
"bufio"
"fmt"
"net"
)
func main() {
// 网络轮询器(I/O处理)
// 这里以网络io为例
listen, err := net.Listen("tcp", "127.0.0.1:20000")
if err != nil {
fmt.Println("listen failed, err:", err)
return
}
for {
conn, err := listen.Accept() // 建立连接
if err != nil {
fmt.Println("accept failed, err:", err)
continue
}
go process(conn) // 启动一个goroutine处理连接
}
}
func process(conn net.Conn) {
defer conn.Close() // 关闭连接
for {
reader := bufio.NewReader(conn)
var buf [128]byte
n, err := reader.Read(buf[:]) // 读取数据
if err != nil {
fmt.Println("read from client failed, err:", err)
break
}
recvStr := string(buf[:n])
fmt.Println("收到client端发来的数据:", recvStr)
conn.Write([]byte(recvStr)) // 发送数据
}
}
client
package main
import (
"bufio"
"fmt"
"net"
"os"
"strings"
)
func main() {
conn, err := net.Dial("tcp", "127.0.0.1:20000")
if err != nil {
fmt.Println("err :", err)
return
}
defer conn.Close() // 关闭连接
inputReader := bufio.NewReader(os.Stdin)
for {
input, _ := inputReader.ReadString('\n') // 读取用户输入
inputInfo := strings.Trim(input, "\r\n")
if strings.ToUpper(inputInfo) == "Q" { // 如果输入q就退出
return
}
_, err = conn.Write([]byte(inputInfo)) // 发送数据
if err != nil {
return
}
buf := [512]byte{}
n, err := conn.Read(buf[:])
if err != nil {
fmt.Println("recv failed, err:", err)
return
}
fmt.Println(string(buf[:n]))
}
}
UDP
server
package main
import (
"fmt"
"net"
)
func main() {
listen, err := net.ListenUDP("udp", &net.UDPAddr{
IP: net.IPv4(0, 0, 0, 0),
Port: 30000,
})
if err != nil {
fmt.Println("listen failed, err:", err)
return
}
defer listen.Close()
for {
var data [1024]byte
n, addr, err := listen.ReadFromUDP(data[:]) // 接收数据
if err != nil {
fmt.Println("read udp failed, err:", err)
continue
}
fmt.Printf("data:%v addr:%v count:%v\n", string(data[:n]), addr, n)
_, err = listen.WriteToUDP(data[:n], addr) // 发送数据
if err != nil {
fmt.Println("write to udp failed, err:", err)
continue
}
}
}
client
package main
import (
"fmt"
"net"
"time"
)
func main() {
socket, err := net.DialUDP("udp", nil, &net.UDPAddr{
IP: net.IPv4(0, 0, 0, 0),
Port: 30000,
})
if err != nil {
fmt.Println("连接服务端失败,err:", err)
return
}
defer socket.Close()
for {
sendData := []byte("Hello server")
_, err = socket.Write(sendData) // 发送数据
if err != nil {
fmt.Println("发送数据失败,err:", err)
return
}
data := make([]byte, 4096)
n, remoteAddr, err := socket.ReadFromUDP(data) // 接收数据
if err != nil {
fmt.Println("接收数据失败,err:", err)
return
}
fmt.Printf("recv:%v addr:%v count:%v\n", string(data[:n]), remoteAddr, n)
time.Sleep(2 * time.Second)
}
}
TCP粘包
server
package main
import (
"bufio"
"fmt"
"io"
"net"
)
func process1(conn net.Conn) {
defer conn.Close()
reader := bufio.NewReader(conn)
var buf [1024]byte
for {
n, err := reader.Read(buf[:])
if err == io.EOF {
break
}
if err != nil {
fmt.Println("read from client failed, err:", err)
break
}
recvStr := string(buf[:n])
fmt.Println("收到client发来的数据:", recvStr)
}
}
func main() {
listen, err := net.Listen("tcp", "127.0.0.1:30000")
if err != nil {
fmt.Println("listen failed, err:", err)
return
}
defer listen.Close()
for {
conn, err := listen.Accept()
if err != nil {
fmt.Println("accept failed, err:", err)
continue
}
go process1(conn)
}
}
client
package main
import (
"fmt"
"net"
)
func main() {
conn, err := net.Dial("tcp", "127.0.0.1:30000")
if err != nil {
fmt.Println("dial failed, err", err)
return
}
defer conn.Close()
for i := 0; i < 20; i++ {
msg := `Hello, Hello. How are you?`
conn.Write([]byte(msg))
}
}
此时服务端的显示:
收到client发来的数据: Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. Hou?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. Hou?Hello, Hello. How are you?Hello, Hello. How are you?
出现了粘包
修改后的:
server
package main
import (
"bufio"
"bytes"
"encoding/binary"
"fmt"
"io"
"net"
)
func process1(conn net.Conn) {
defer conn.Close()
reader := bufio.NewReader(conn)
for {
msg, err := Decode(reader)
if err == io.EOF {
return
}
if err != nil {
fmt.Println("decode msg failed, err:", err)
return
}
fmt.Println("收到client发来的数据:", msg)
}
}
func main() {
listen, err := net.Listen("tcp", "127.0.0.1:30000")
if err != nil {
fmt.Println("listen failed, err:", err)
return
}
defer listen.Close()
for {
conn, err := listen.Accept()
if err != nil {
fmt.Println("accept failed, err:", err)
continue
}
go process1(conn)
}
}
// Decode 解码消息
func Decode(reader *bufio.Reader) (string, error) {
// 读取消息的长度
lengthByte, _ := reader.Peek(4) // 读取前4个字节的数据
lengthBuff := bytes.NewBuffer(lengthByte)
var length int32
err := binary.Read(lengthBuff, binary.LittleEndian, &length)
if err != nil {
return "", err
}
// Buffered返回缓冲中现有的可读取的字节数。
if int32(reader.Buffered()) < length+4 {
return "", err
}
// 读取真正的消息数据
pack := make([]byte, int(4+length))
_, err = reader.Read(pack)
if err != nil {
return "", err
}
return string(pack[4:]), nil
}
client
package main
import (
"bytes"
"encoding/binary"
"fmt"
"net"
)
func main() {
conn, err := net.Dial("tcp", "127.0.0.1:30000")
if err != nil {
fmt.Println("dial failed, err", err)
return
}
defer conn.Close()
for i := 0; i < 20; i++ {
msg := `Hello, Hello. How are you?`
data, err := Encode(msg)
if err != nil {
fmt.Println("encode msg failed, err:", err)
return
}
conn.Write(data)
}
}
// Encode 将消息编码
func Encode(message string) ([]byte, error) {
// 读取消息的长度,转换成int32类型(占4个字节)
var length = int32(len(message))
var pkg = new(bytes.Buffer)
// 写入消息头
err := binary.Write(pkg, binary.LittleEndian, length)
if err != nil {
return nil, err
}
// 写入消息实体
err = binary.Write(pkg, binary.LittleEndian, []byte(message))
if err != nil {
return nil, err
}
return pkg.Bytes(), nil
}
结果:
收到client发来的数据: Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?