CentOS8 安装 kafka1.0.0 集群,kafka集群连接zookeeper集群
一、下载地址
http://kafka.apachecn.org/downloads.html

二、文档
http://kafka.apachecn.org/
http://kafka.apachecn.org/quickstart.html
http://kafka.apachecn.org/documentation.html
http://kafka.apache.org/documentation/
三、安装
本教程假定您是一只小白,没有Kafka 或ZooKeeper 方面的经验。 Kafka控制脚本在Unix和Windows平台有所不同,在Windows平台,请使用 bin\windows\ 而不是bin/, 并将脚本扩展名改为.bat.
Step 1: 下载代码
下载 1.0.0版本并解压缩。.
| 1 2 |
|
Step 2: 启动服务器
Kafka 使用 ZooKeeper 如果你还没有ZooKeeper服务器,你需要先启动一个ZooKeeper服务器。 您可以通过与kafka打包在一起的便捷脚本来快速简单地创建一个单节点ZooKeeper实例。
| 1 2 3 |
|
现在启动Kafka服务器:
| 1 2 3 4 |
|
Step 3: 创建一个 topic
让我们创建一个名为“test”的topic,它有一个分区和一个副本:
| 1 |
|
现在我们可以运行list(列表)命令来查看这个topic:
| 1 2 |
|
或者,您也可将代理配置为:在发布的topic不存在时,自动创建topic,而不是手动创建。
Step 4: 发送一些消息
Kafka自带一个命令行客户端,它从文件或标准输入中获取输入,并将其作为message(消息)发送到Kafka集群。默认情况下,每行将作为单独的message发送。
运行 producer,然后在控制台输入一些消息以发送到服务器。
| 1 2 3 |
|
Step 5: 启动一个 consumer
Kafka 还有一个命令行consumer(消费者),将消息转储到标准输出。
| 1 2 3 |
|
如果您将上述命令在不同的终端中运行,那么现在就可以将消息输入到生产者终端中,并将它们在消费终端中显示出来。
所有的命令行工具都有其他选项;运行不带任何参数的命令将显示更加详细的使用信息。
Step 6: 设置多代理集群
到目前为止,我们一直在使用单个代理,这并不好玩。对 Kafka来说,单个代理只是一个大小为一的集群,除了启动更多的代理实例外,没有什么变化。 为了深入了解它,让我们把集群扩展到三个节点(仍然在本地机器上)。
首先,为每个代理创建一个配置文件 (在Windows上使用copy 命令来代替):
| 1 2 |
|
现在编辑这些新文件并设置如下属性:
| 1 2 3 4 5 6 7 8 9 |
|
broker.id属性是集群中每个节点的名称,这一名称是唯一且永久的。我们必须重写端口和日志目录,因为我们在同一台机器上运行这些,我们不希望所有的代理尝试在同一个端口注册,或者覆盖彼此的数据。
我们已经建立Zookeeper和一个单节点了,现在我们只需要启动两个新的节点:
| 1 2 3 4 |
|
现在创建一个副本为3的新topic:
| 1 |
|
Good,现在我们有一个集群,但是我们怎么才能知道那些代理在做什么呢?运行"describe topics"命令来查看:
| 1 2 3 |
|
以下是对输出信息的解释。第一行给出了所有分区的摘要,下面的每行都给出了一个分区的信息。因为我们只有一个分区,所以只有一行。
- “leader”是负责给定分区所有读写操作的节点。每个节点都是随机选择的部分分区的领导者。
- “replicas”是复制分区日志的节点列表,不管这些节点是leader还是仅仅活着。
- “isr”是一组“同步”replicas,是replicas列表的子集,它活着并被指到leader。
请注意,在示例中,节点1是该主题中唯一分区的领导者。
我们可以在已创建的原始主题上运行相同的命令来查看它的位置:
| 1 2 3 |
|
这没什么大不了,原来的主题没有副本且在服务器0上。我们创建集群时,这是唯一的服务器。
让我们发表一些信息给我们的新topic:
| 1 2 3 4 5 |
|
现在我们来消费这些消息:
| 1 2 3 4 5 |
|
让我们来测试一下容错性。 Broker 1 现在是 leader,让我们来杀了它:
| 1 2 3 |
|
在 Windows 上用:
| 1 2 3 4 |
|
领导权已经切换到一个从属节点,而且节点1也不在同步副本集中了:
| 1 2 3 |
|
不过,即便原先写入消息的leader已经不在,这些消息仍可用于消费:
| 1 2 3 4 5 |
|
Step 7: 使用Kafka Connect来导入/导出数据
从控制台读出数据并将其写回是十分方便操作的,但你可能需要使用其他来源的数据或将数据从Kafka导出到其他系统。针对这些系统, 你可以使用Kafka Connect来导入或导出数据,而不是写自定义的集成代码。
Kafka Connect是Kafka的一个工具,它可以将数据导入和导出到Kafka。它是一种可扩展工具,通过运行connectors(连接器), 使用自定义逻辑来实现与外部系统的交互。 在本文中,我们将看到如何使用简单的connectors来运行Kafka Connect,这些connectors 将文件中的数据导入到Kafka topic中,并从中导出数据到一个文件。
首先,我们将创建一些种子数据来进行测试:
| 1 |
|
在Windows系统使用:
| 1 2 |
|
接下来,我们将启动两个standalone(独立)运行的连接器,这意味着它们各自运行在一个单独的本地专用 进程上。 我们提供三个配置文件。首先是Kafka Connect的配置文件,包含常用的配置,如Kafka brokers连接方式和数据的序列化格式。 其余的配置文件均指定一个要创建的连接器。这些文件包括连接器的唯一名称,类的实例,以及其他连接器所需的配置。
| 1 |
|
这些包含在Kafka中的示例配置文件使用您之前启动的默认本地群集配置,并创建两个连接器: 第一个是源连接器,用于从输入文件读取行,并将其输入到 Kafka topic。 第二个是接收器连接器,它从Kafka topic中读取消息,并在输出文件中生成一行。
在启动过程中,你会看到一些日志消息,包括一些连接器正在实例化的指示。 一旦Kafka Connect进程启动,源连接器就开始从 test.txt 读取行并且 将它们生产到主题 connect-test 中,同时接收器连接器也开始从主题 connect-test 中读取消息, 并将它们写入文件 test.sink.txt 中。我们可以通过检查输出文件的内容来验证数据是否已通过整个pipeline进行交付:
| 1 2 3 |
|
请注意,数据存储在Kafka topic connect-test 中,因此我们也可以运行一个console consumer(控制台消费者)来查看 topic 中的数据(或使用custom consumer(自定义消费者)代码进行处理):
| 1 2 3 4 |
|
连接器一直在处理数据,所以我们可以将数据添加到文件中,并看到它在pipeline 中移动:
| 1 |
|
您应该可以看到这一行出现在控制台用户输出和接收器文件中。
Step 8:使用 Kafka Streams 来处理数据
Kafka Streams是用于构建实时关键应用程序和微服务的客户端库,输入与输出数据存储在Kafka集群中。 Kafka Streams把客户端能够轻便地编写部署标准Java和Scala应用程序的优势与Kafka服务器端集群技术相结合,使这些应用程序具有高度伸缩性、弹性、容错性、分布式等特性。 本快速入门示例将演示如何运行一个基于该库编程的流式应用程序。
停止kafka(停止单机集群)
[root@dev1 kafka_2.11-1.0.0]# bin/kafka-server-stop.sh
四、replication-factor说明
复制因子,topic存储几份副本(一份副本包含1到多个partition)。副本要放到broker中存储。
创建topic时,replication-factor数不能大于broker,
如果replication-factor等于broker,一个broker上存一份副本,这一份副本包含1到多个partition
如果replication-factor小于broker,有的副本的多个partition可能存在多个broker中。
[root@dev1 kafka_2.11-1.0.0]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 4 --partitions 1 --topic my-replicated-topic
Error while executing topic command : Replication factor: 4 larger than available brokers: 3.
[2020-04-04 18:19:35,069] ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 4 larger than available brokers: 3.
(kafka.admin.TopicCommand$)
[root@dev1 kafka_2.11-1.0.0]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
Created topic "my-replicated-topic".
[root@dev1 kafka_2.11-1.0.0]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 2 --topic my-replicated-topic2
Created topic "my-replicated-topic2".
[root@dev1 kafka_2.11-1.0.0]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 5 --topic my-replicated-topic5
Created topic "my-replicated-topic5".
broker0

broker1
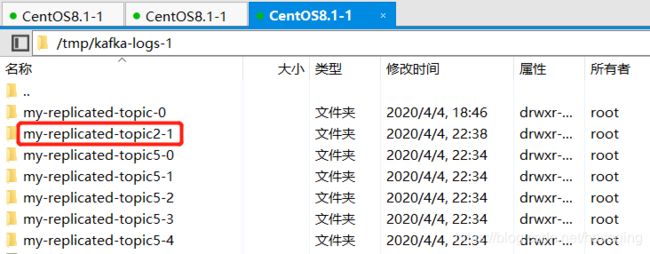
broker2
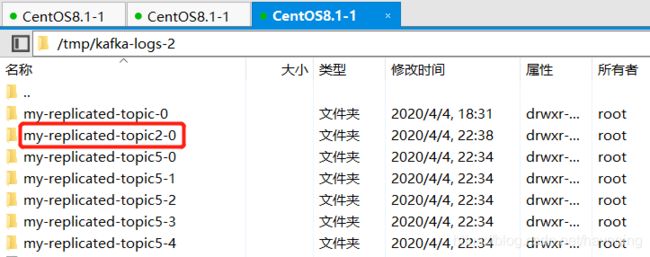
my-replicated-topic,1个分区,3个副本,存储在3个broker
my-replicated-topic2,2个分区,2个副本,broker0存储了2个分区,broker1存储了1个分区,broker2存储了一个分区。
my-replicated-topic5,5个分区,3个副本,存储在3个broker
五、kafka集群连接zookeeper集群
CentOS8 安装配置zookeeper3.6,单机版,集群版
分别修改kafka配置文件
修改kafka配置文件server.properties,加上主机名或IP
#listeners=PLAINTEXT://:9092
listeners=PLAINTEXT://192.168.0.201:9092否则生产者和消费者连接使用会报错
WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 3 : {test=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
另外两台端口是9093,9094
修改zookeeper连接地址
zookeeper.connect=192.168.0.201:2181,192.168.0.201:2182,192.168.0.201:2183因为zookeeper装的是单机伪集群,所以端口不一样,一般真集群端口是一样的:2181,IP不一样
分别启动kafka服务
[root@dev1 kafka_2.11-1.0.0]# bin/kafka-server-start.sh config/server.properties &
[root@dev1 kafka_2.11-1.0.0]# bin/kafka-server-start.sh config/server-1.properties &
[root@dev1 kafka_2.11-1.0.0]# bin/kafka-server-start.sh config/server-2.properties &
kafka启动,如果报这个错
Will not attempt to authenticate using SASL (unknown error) (org.apache.zookeeper.ClientCnxn)
可能是zookeeper集群没有启动,(或着zookeeper监听主机名或IP的问题)
测试
因为kafka集群是单机伪集群,所有端口不一样,一般真集群端口是一样的:9092,IP不一样
[root@dev1 kafka_2.11-1.0.0]# bin/kafka-console-producer.sh --broker-list 192.168.0.201:9092,192.168.0.201:9093,192.168.0.201:9094 --topic test
>oh my god
>my cluster
[root@dev1 kafka_2.11-1.0.0]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.0.201:9092,192.168.0.201:9093,192.168.0.201:9094 --topic test --from-beginning
oh my god
my cluster
其他
--from-beginning 参数说明
如果使用者尚未确定要使用的偏移量,请从日志中出现的最早消息而不是最新消息开始。
不指定这参数,就读最新的消息了。
log.dirs应该修改一下吧,不应放在/tmp下
log.dirs:以逗号分隔的存储日志文件的目录列表
Kafka是把所有消息都保存在在磁盘上,存放目录即通过该参数指定的。可以配置多个,逗号分隔开,同个分区的数据会保存在同个路径下,分配原则是最少使用原则,即哪个路径分区数目少,broker就优先往这个路径新增分区
可以指到不同磁盘上,提高性能。