使用pytorch搭建自己的网络之VGG
一、introduction
VGG网络是2014年ILSVRC2014比赛分类项目的第二名(其中第一名是GoogLeNet)。论文发表于2015年的ICLR,其主要贡献是使用多个较小的卷积核(如3 X 3)替代大卷积核,降低了卷积核的尺寸,增加了网络深度。证明了不断加深网络深度可以提高网络的性能。
二、网络结构
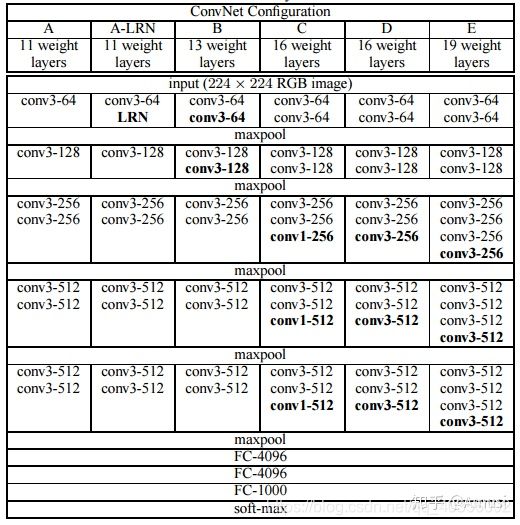
网上比较流行的网络结构如上图所示,通过对网络结构的评估,最终证明16层和19层的网络结构能够取得较好的识别精度。
具体代码如下:
import torch
from torch import nn
#输入通道数和类别数
in_channels = 3
classes=1000
#铺平
class Flatten(nn.Module):
def __init__(self):
super(Flatten, self).__init__()
def forward(self, input):
return input.view(input.size(0), -1)
def vgg_block(num_convs, in_channels, out_channels):
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*blk)
def vgg(conv_arch, fc_features, fc_hidden_units=4096):
net = nn.Sequential()
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
net.add_module("vgg_block_" + str(i + 1), vgg_block(num_convs, in_channels, out_channels))
net.add_module("fc",nn.Sequential(
Flatten(),
nn.Linear(fc_features, fc_hidden_units), #FC-4096
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units), #FC-4096
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, classes)
))
return net
conv_arch = ((1, in_channels, 64), (1, 64, 128), (2, 128, 256), (2, 256, 512), (2, 512, 512))
fc_features = 512 * 7 * 7
fc_hidden_units = 4096
net = vgg(conv_arch, fc_features, fc_hidden_units)
if __name__ == '__main__':
X = torch.rand(16, 3, 224, 224)
for name, blk in net.named_children():
X = blk(X)
print(name, 'output shape: ', X.shape)
通过对代码进行分析可以看到,VGG的主体结构非常简单,主要由大量的卷积模块conv_arch 和三层全连接层组成。
VGG结构中共有5个卷积块,每个卷积块连续使⽤多个填充为1、卷积核为 3 X 3 的卷积层,然后接上一个步幅为2、窗⼝形状为 2 X 2的最⼤池化层。卷积层保持输⼊的⾼和宽不变,⽽池化层则对其减半。所以整个卷积池化层对图片进行了5次放缩操作,输入的224 X 224 RGB image经过卷积池化操作之后图片大小为(112 X 112),(56 X 56),(28 X 28),(14 X 14),(7 X 7)。
我们使用vgg_block这个函数来实现每一个基础的卷积块操作,其中三个参数num_convs, in_channels, out_channels分别表示该卷积块中卷积层数量,输入的通道数,输出的通道数。
全连接层一共有三个,经过全连接层后输出大小分别是(512 X 7 X 7,4096),(4096,4096),(4096,classes)。其中classes为输出的类别数。在第一个和第二个全连接层后还加入了ReLU()激活函数和Dropout()以防止过拟合。
三、实现不同的VGG网络
通过对下面这行代码进行修改即可实现不同结构的VGG网络。
A 11 weight layers:conv_arch = ((1, in_channels, 64), (1, 64, 128), (2, 128, 256), (2, 256, 512), (2, 512, 512))
B 13 weight layers:conv_arch = ((2, in_channels, 64), (2, 64, 128), (2, 128, 256), (2, 256, 512), (2, 512, 512))
D 16 weight layers:conv_arch = ((2, in_channels, 64), (2, 64, 128), (3, 128, 256), (3, 256, 512), (3, 512, 512))
E 19 weight layers:conv_arch = ((2, in_channels, 64), (2, 64, 128), (4, 128, 256), (4, 256, 512), (4, 512, 512))
其中A-LRN结构是在第二个卷积块中添加了LRN层,D结构是在第2、3、4卷积块的最后一个卷积层中加入了一个1X1的卷积层。如果想要实现的话自己再重新写一个vgg_block函数即可。
四、调用pytorch自带的VGG模型
1、头文件from torchvision.models import vgg16
在pycharm中可以使用Ctrl+鼠标左键查看源代码vgg.py,该文件提供了多种VGG的模型,这里我们使用VGG16模型。
2、调用模型并加载训练好的参数,这里既可以使用本地的预训练模型,也可以使用vgg.py文件中提供的训练模型path。
def VGG16():
if pretrained_model:
model = vgg16(pretrained=False)
model.load_state_dict(torch.load(pretrained_model_path))
else:
model = vgg16(pretrained=True)
#加载VGG16模型,除了最后一层
features = list(model.features)[:-1]
#冻结前十层
for layer in features[:10]:
for p in layer.parameters():
p.requires_grad = False
return nn.Sequential(*features)
需要注意的是,model.features包含了网络结构中的BN层和relu层,在计算层数的时候需要特别注意,如果不确定可以去源文件里面查看。
五、writing in the end
VGG的网络结构提出至今已经五六年的时间了,深度学习领域近几年的发展也是日新月异的,到现在已经有大量的卷积神经网络模型被提出来用于解决各种问题。而且在17、18年很多模型中仍然能看到VGG的影子,复现这个代码对我们学习CNN也有比较好的帮助。