大语言模型之十七-QA-LoRA
由于基座模型通常需要海量的数据和算力内存,这一巨大的成本往往只有巨头公司会投入,所以一些优秀的大语言模型要么是大公司开源的,要么是背后有大公司身影公司开源的,如何从优秀的开源基座模型针对特定场景fine-tune模型具有广大的前景,从数据开源、到基座模型到新方法的迭代升级使得个人都有机会践行fine-tune这一过程。
为了使得基座模型能够迁移到不同的任务应用场景中,Fine-tune是最为使用的方法之一,为了减少fine-tune阶段需要的算力内存开销,当前主要有PEFT(parameter-efficient fine-tuning)和参数量化两类方向,PEFT(parameter-efficient fine-tuning)核心思想是重新训练对新任务影响较大的少部分参数,而基座模型大部分参数保持不变,量化的核心思想是通过模型参数位宽(量化)的减少降低内存消耗,将二者结合使用能够进一步减少资源消耗,如何高效的使用量化、PEFT等技术在减少算力的需求的前提下减少准确性损失是当前主流研究方向。
本篇博客讨论当前高效训练和推理LLM的PEFT和量化相关技术,PEFT技术仅介绍使用较广的LoRA。
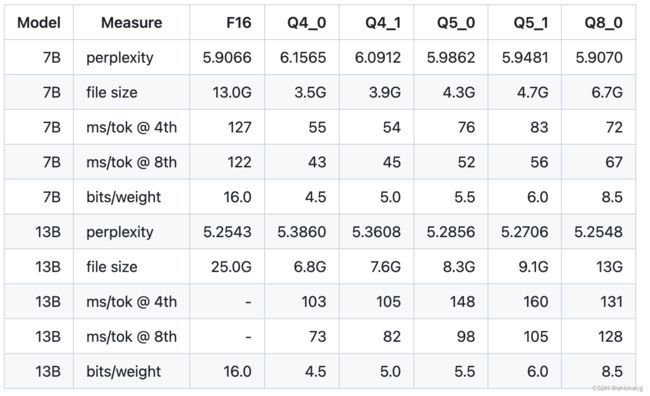
量化的目的是提高芯片计算吞吐量和减少内存占用,当前8-bit和4-bit量化已经在商业上可以在消费级硬件上运行模型,量化(GPTQ、GGUF)+开源LLama+PEFT(LoRA, QLoRA)+开源数据集的组合极大降低了大模型的门槛,这一闭环的生态是的训练和部署都可以以较低的成本进行,这里讨论QLoRA、GPTQ以及GGUF三种量化方法,基座模型训练的时候采用的是单精度浮点32bit位宽,推理的时候如果将32-bit位宽的数据变成8-bit,甚至4bit那么内存的需求量将大大减少,但是量化也会劣化模型的表现。
QLoRA
LoRA技术在《大语言模型之十四-PEFT的LoRA》和《大语言模型之十六-基于LongLoRA的长文本上下文微调Llama-2》,因而LoRA基础思想和实现方法本篇博客不再介绍。
QLoRA的全称是Quantized and Low-Rank Adapters,这里的and表示的意义是量化和LoRA方法的组合,量化的意思是将32-bit单精度浮点数量化为8-bit/4-bit/2-bit等方法以减少内存的消耗,采用低秩分解的方法降低fine-tune的参数量,二者思想相组合即为这里的QLoRA。
QLoRA将存储数据类型和计算数据类型相分离,存储数据类型通常为4-bit NormalFloat类型,计算数据类型是16-bit BrainFloat类型。在前向计算loss和反向根据梯度更新权重参数的时候,将存储的数据类型转为计算数据类型,但仅在计算LoRA参数的权重梯度时才使用16-bit BrainFloat。
4-bit NormalFloat(NF4)数据类型
4-bit NormalFloat先经过Normalization,将模型的权重参数归一化,即变成零均值单位方差的权重参数,这是为了确保权重参数集中在0附近很小的范围以便用很少的比特位量化。
对于32-bit单精度浮点数表示的网络权重0.5678,再用4-bit float量化时,首先假设4-bit整数表示16个间隔分布的范围[-1, 1],即:
[-1.0, -0.8667, -0.7333, -0.6, -0.4667, -0.3333, -.02, -0.0667, 0.0667, 0.2, 0.3333, 0.4667, 0.6, 0.7333, 0.8667, 1.0],
1)首先将原始32-bit单精度数0.5678量化为0.6,因为0.5678距离0.6比0.4667近,
2)4bit可以表示的无符号数为0~15,有符号数为-8~7,这里以无符号表示,则15对应于1.0,则0.6对应于12,所以权重参数按4-bit整数存储为12而不是单精度的0.5678(也不是0.6)
3)在计算的时候,前向计算loss或者反向根据梯度更新权重参数的时候,首先将12转为0.6(量化逆过程)表示的浮点数参与运算,而0.6和0.5678之间差值是逆量化误差。
量化到8-bit可以减少量化误差,fine-tune过程和4bit类似,但是存储的内存增加一倍。
量化误差会影响模型的准确性,这可以通过混合精度训练在准确性和速度/内存使用上平衡。
这里总结一下QLoRA的方法,首先将32-bit单精度参数模型以4-bit的方式加载到内存中,也有使用DQ(Double quantization)对量化残差再使用4-bit量化,进一步减少精度带来模型准确性损失,然后配置LoRA参数,针对特定层(如1%的参数了,仍然使用32-bit单精度)作为权重,但是由于进行了低秩分解,因而相比原始参数量也是大大减少的,在训练的时候,前向计算时,首先将内存中freeze的NF4格式数据转为浮点数,参与loss计算,对于LoRA注入层则使用单精度计算(这是没有量化,因而无量化误差),计算loss之后,反向梯度更新的时候,只更新LoRA注入层影响的权重参数,freeze的NF4数据不受影响。
QALoRA
QALoRA论文显示,QA-LoRA和QLoRA在MMLU数据集上不同量化比特位数的准确度对比情况,由此可以看到同量化比特位数情况下QA-LoRA准确性最高。QALoRA官方 github工程
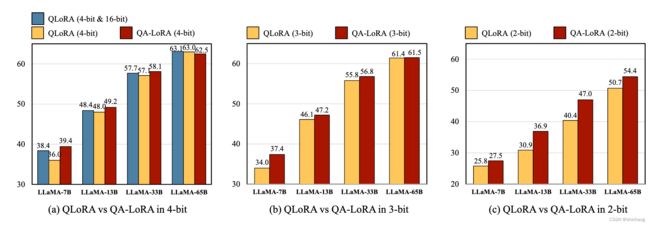
图1 QLoRA vs QA-LoRA score
从上面的测试情况来看,QA-LoRA方法在同比特情况下得分最高。未来QA-LoRA极有可能是成为主流,相比QLoRA,QALoRA方法提供了更高的精度。
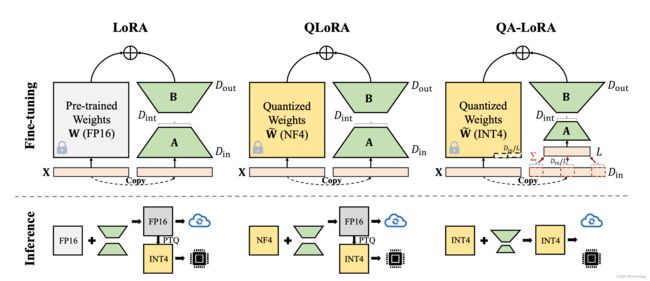
图 2 LoRA vs QLoRA vs QA-LoRA
LoRA方法在《大语言模型之十五-预训练和监督微调中文LLama-2》已有涉及,QLoRA方法在《大语言模型之七- Llama-2单GPU微调SFT》使用了。
Fine-tune的时候,LoRA方法是依然使用FP16比特类型数据,而QLoRA则使用NF4类型格式数据,而QA-LoRA则使用INT4类型数据格式,
在推理的时候,QA-LoRA也是直接使用INT4类型的数据格式。

图3 QA-LoRA
因为当前介绍QA-LoRA方法的资料比较少,毕竟是github工程两周前才公布的,这里以《大语言模型之四-LlaMA-2从模型到应用》插图3为例说明。
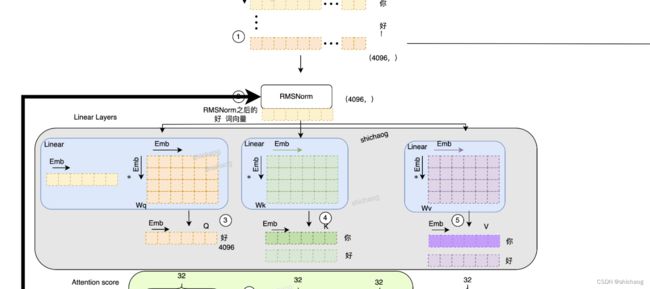
图4 大语言模型之四-LlaMA-2从模型到应用插图3部分
这里收入token的每个维度是4096,对应于上述公式的D_in即输入token Embedding维度。这里的Wq,Wk,Wv对应于图2中pre-trained weight。图2中输入X都是4096维Embedding数。
QA-LoRA的方法是将Embedding 4096分组,假设是组L=128,则Group=Emb/L=4096/32=128,这样A就变成了32x64,B变成了644096,A和B相乘结果AB=324096,和group后的输入相乘即[132][AB]=14096,这样就得到了和LoRA和QLoRA一样的结果,即图4中圈3、圈4、圈5对应的QKV(1*4096)。
在图3的公式中还有pre-quantization函数,这一函数的作用是对浮点数量化,然后将量化值在转为浮点数,这样做的目的是在训练的过程中感知量化。
GPTQ
GPTQ对训练好的模型首先对参数进行标量量化,然后对残差进行向量量化,向量量化的思想和方法可以参考《编解码》,这种被称之为Post-training量化,这种方法压缩效率高、算力需求也会降低。GPTQ方法使得模型可以在消费级显卡GPU上运行。在推理上GGUF已经超过了GPTQ方法。
GGUF
GGUF是ggml的后继者,GGUF已经支持cuBLAS、MPI、BLAS、BLIS、Intel MKL等库支持,在GPU、CPU上都可以高效实现推理运算,ggml是专为CPU推理而实现的c++库,由于影响力比较大,所以blas、mkl以及GPU也都支持了,升级为了GGUF,我们在推理的时候已经见到过了,这是基于c++的推理,使用了ggml向量计算库,因而模型的参数是需要转换为GGUF格式的,GGUF官网说明是为了Llama模型能够使用4-bit整型量化以便在MacBook上实现推理。除了量化也使用了硬件加速SIMD指令和GPU的一些支持。quantize详见github